 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCINEMAE: Leveraging Frozen Masked Autoencoders for Cross-Generator AI Image Detection
Nov 09, 2025While context-based detectors have achieved strong generalization for AI-generated text by measuring distributional inconsistencies, image-based detectors still struggle with overfitting to generator-specific artifacts. We introduce CINEMAE, a novel paradigm for AIGC image detection that adapts the core principles of text detection methods to the visual domain. Our key insight is that Masked AutoEncoder (MAE), trained to reconstruct masked patches conditioned on visible context, naturally encodes semantic consistency expectations. We formalize this reconstruction process probabilistically, computing conditional Negative Log-Likelihood (NLL, p(masked | visible)) to quantify local semantic anomalies. By aggregating these patch-level statistics with global MAE features through learned fusion, CINEMAE achieves strong cross-generator generalization. Trained exclusively on Stable Diffusion v1.4, our method achieves over 95% accuracy on all eight unseen generators in the GenImage benchmark, substantially outperforming state-of-the-art detectors. This demonstrates that context-conditional reconstruction uncertainty provides a robust, transferable signal for AIGC detection.
Refusal-Feature-guided Teacher for Safe Finetuning via Data Filtering and Alignment Distillation
Jun 09, 2025Recently, major AI service providers such as Google and OpenAI have introduced Finetuning-as-a-Service, which enables users to customize Large Language Models (LLMs) for specific downstream tasks using their own data. However, this service is vulnerable to degradation of LLM safety-alignment when user data contains harmful prompts. While some prior works address this issue, fundamentally filtering harmful data from user data remains unexplored. Motivated by our observation that a directional representation reflecting refusal behavior (called the refusal feature) obtained from safety-aligned LLMs can inherently distinguish between harmful and harmless prompts, we propose the Refusal-Feature-guided Teacher (ReFT). Our ReFT model is trained to identify harmful prompts based on the similarity between input prompt features and its refusal feature. During finetuning, the ReFT model serves as a teacher that filters harmful prompts from user data and distills alignment knowledge into the base model. Extensive experiments demonstrate that our ReFT-based finetuning strategy effectively minimizes harmful outputs and enhances finetuning accuracy for user-specific tasks, offering a practical solution for secure and reliable deployment of LLMs in Finetuning-as-a-Service.
Benign-to-Toxic Jailbreaking: Inducing Harmful Responses from Harmless Prompts
May 26, 2025Optimization-based jailbreaks typically adopt the Toxic-Continuation setting in large vision-language models (LVLMs), following the standard next-token prediction objective. In this setting, an adversarial image is optimized to make the model predict the next token of a toxic prompt. However, we find that the Toxic-Continuation paradigm is effective at continuing already-toxic inputs, but struggles to induce safety misalignment when explicit toxic signals are absent. We propose a new paradigm: Benign-to-Toxic (B2T) jailbreak. Unlike prior work, we optimize adversarial images to induce toxic outputs from benign conditioning. Since benign conditioning contains no safety violations, the image alone must break the model's safety mechanisms. Our method outperforms prior approaches, transfers in black-box settings, and complements text-based jailbreaks. These results reveal an underexplored vulnerability in multimodal alignment and introduce a fundamentally new direction for jailbreak approaches.
VideoRFSplat: Direct Scene-Level Text-to-3D Gaussian Splatting Generation with Flexible Pose and Multi-View Joint Modeling
Mar 20, 2025We propose VideoRFSplat, a direct text-to-3D model leveraging a video generation model to generate realistic 3D Gaussian Splatting (3DGS) for unbounded real-world scenes. To generate diverse camera poses and unbounded spatial extent of real-world scenes, while ensuring generalization to arbitrary text prompts, previous methods fine-tune 2D generative models to jointly model camera poses and multi-view images. However, these methods suffer from instability when extending 2D generative models to joint modeling due to the modality gap, which necessitates additional models to stabilize training and inference. In this work, we propose an architecture and a sampling strategy to jointly model multi-view images and camera poses when fine-tuning a video generation model. Our core idea is a dual-stream architecture that attaches a dedicated pose generation model alongside a pre-trained video generation model via communication blocks, generating multi-view images and camera poses through separate streams. This design reduces interference between the pose and image modalities. Additionally, we propose an asynchronous sampling strategy that denoises camera poses faster than multi-view images, allowing rapidly denoised poses to condition multi-view generation, reducing mutual ambiguity and enhancing cross-modal consistency. Trained on multiple large-scale real-world datasets (RealEstate10K, MVImgNet, DL3DV-10K, ACID), VideoRFSplat outperforms existing text-to-3D direct generation methods that heavily depend on post-hoc refinement via score distillation sampling, achieving superior results without such refinement.
SteerX: Creating Any Camera-Free 3D and 4D Scenes with Geometric Steering
Mar 15, 2025Recent progress in 3D/4D scene generation emphasizes the importance of physical alignment throughout video generation and scene reconstruction. However, existing methods improve the alignment separately at each stage, making it difficult to manage subtle misalignments arising from another stage. Here, we present SteerX, a zero-shot inference-time steering method that unifies scene reconstruction into the generation process, tilting data distributions toward better geometric alignment. To this end, we introduce two geometric reward functions for 3D/4D scene generation by using pose-free feed-forward scene reconstruction models. Through extensive experiments, we demonstrate the effectiveness of SteerX in improving 3D/4D scene generation.
Long-tailed Adversarial Training with Self-Distillation
Mar 09, 2025Adversarial training significantly enhances adversarial robustness, yet superior performance is predominantly achieved on balanced datasets. Addressing adversarial robustness in the context of unbalanced or long-tailed distributions is considerably more challenging, mainly due to the scarcity of tail data instances. Previous research on adversarial robustness within long-tailed distributions has primarily focused on combining traditional long-tailed natural training with existing adversarial robustness methods. In this study, we provide an in-depth analysis for the challenge that adversarial training struggles to achieve high performance on tail classes in long-tailed distributions. Furthermore, we propose a simple yet effective solution to advance adversarial robustness on long-tailed distributions through a novel self-distillation technique. Specifically, this approach leverages a balanced self-teacher model, which is trained using a balanced dataset sampled from the original long-tailed dataset. Our extensive experiments demonstrate state-of-the-art performance in both clean and robust accuracy for long-tailed adversarial robustness, with significant improvements in tail class performance on various datasets. We improve the accuracy against PGD attacks for tail classes by 20.3, 7.1, and 3.8 percentage points on CIFAR-10, CIFAR-100, and Tiny-ImageNet, respectively, while achieving the highest robust accuracy.
Difficulty-aware Balancing Margin Loss for Long-tailed Recognition
Dec 20, 2024When trained with severely imbalanced data, deep neural networks often struggle to accurately recognize classes with only a few samples. Previous studies in long-tailed recognition have attempted to rebalance biased learning using known sample distributions, primarily addressing different classification difficulties at the class level. However, these approaches often overlook the instance difficulty variation within each class. In this paper, we propose a difficulty-aware balancing margin (DBM) loss, which considers both class imbalance and instance difficulty. DBM loss comprises two components: a class-wise margin to mitigate learning bias caused by imbalanced class frequencies, and an instance-wise margin assigned to hard positive samples based on their individual difficulty. DBM loss improves class discriminativity by assigning larger margins to more difficult samples. Our method seamlessly combines with existing approaches and consistently improves performance across various long-tailed recognition benchmarks.
FRIDAY: Mitigating Unintentional Facial Identity in Deepfake Detectors Guided by Facial Recognizers
Dec 19, 2024Previous Deepfake detection methods perform well within their training domains, but their effectiveness diminishes significantly with new synthesis techniques. Recent studies have revealed that detection models often create decision boundaries based on facial identity rather than synthetic artifacts, resulting in poor performance on cross-domain datasets. To address this limitation, we propose Facial Recognition Identity Attenuation (FRIDAY), a novel training method that mitigates facial identity influence using a face recognizer. Specifically, we first train a face recognizer using the same backbone as the Deepfake detector. The recognizer is then frozen and employed during the detector's training to reduce facial identity information. This is achieved by feeding input images into both the recognizer and the detector, and minimizing the similarity of their feature embeddings through our Facial Identity Attenuating loss. This process encourages the detector to generate embeddings distinct from the recognizer, effectively reducing the impact of facial identity. Extensive experiments demonstrate that our approach significantly enhances detection performance on both in-domain and cross-domain datasets.
SAFIRE: Segment Any Forged Image Region
Dec 11, 2024



Most techniques approach the problem of image forgery localization as a binary segmentation task, training neural networks to label original areas as 0 and forged areas as 1. In contrast, we tackle this issue from a more fundamental perspective by partitioning images according to their originating sources. To this end, we propose Segment Any Forged Image Region (SAFIRE), which solves forgery localization using point prompting. Each point on an image is used to segment the source region containing itself. This allows us to partition images into multiple source regions, a capability achieved for the first time. Additionally, rather than memorizing certain forgery traces, SAFIRE naturally focuses on uniform characteristics within each source region. This approach leads to more stable and effective learning, achieving superior performance in both the new task and the traditional binary forgery localization.
* Accepted at AAAI 2025. Code is available at: https://github.com/mjkwon2021/SAFIRE
Doubly-Universal Adversarial Perturbations: Deceiving Vision-Language Models Across Both Images and Text with a Single Perturbation
Dec 11, 2024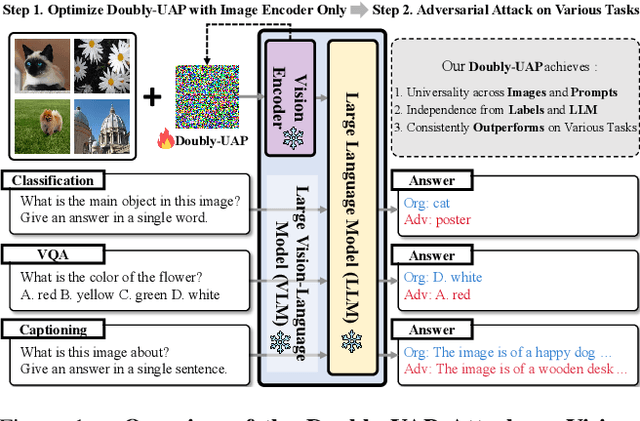
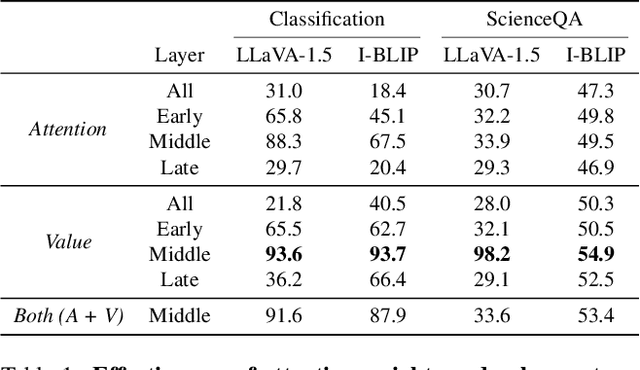
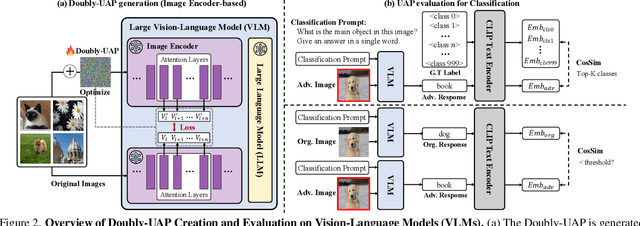

Large Vision-Language Models (VLMs) have demonstrated remarkable performance across multimodal tasks by integrating vision encoders with large language models (LLMs). However, these models remain vulnerable to adversarial attacks. Among such attacks, Universal Adversarial Perturbations (UAPs) are especially powerful, as a single optimized perturbation can mislead the model across various input images. In this work, we introduce a novel UAP specifically designed for VLMs: the Doubly-Universal Adversarial Perturbation (Doubly-UAP), capable of universally deceiving VLMs across both image and text inputs. To successfully disrupt the vision encoder's fundamental process, we analyze the core components of the attention mechanism. After identifying value vectors in the middle-to-late layers as the most vulnerable, we optimize Doubly-UAP in a label-free manner with a frozen model. Despite being developed as a black-box to the LLM, Doubly-UAP achieves high attack success rates on VLMs, consistently outperforming baseline methods across vision-language tasks. Extensive ablation studies and analyses further demonstrate the robustness of Doubly-UAP and provide insights into how it influences internal attention mechanisms.