 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation
Jan 02, 2021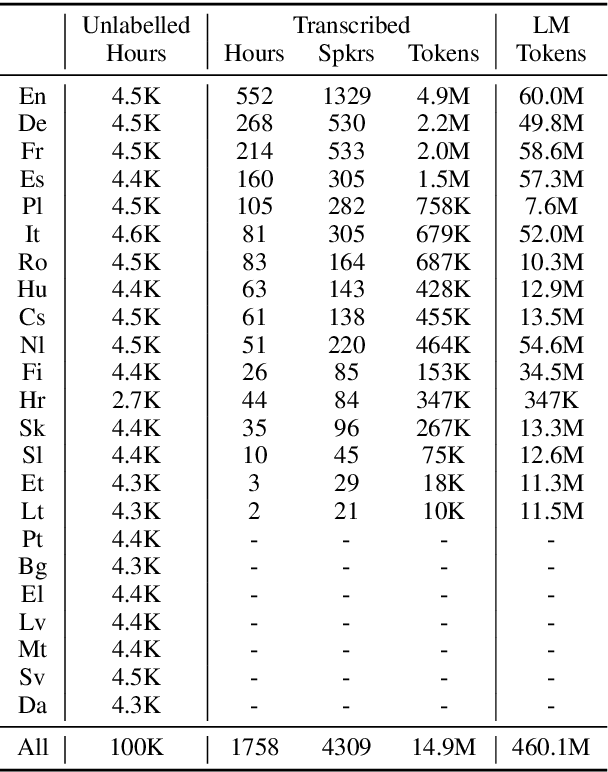
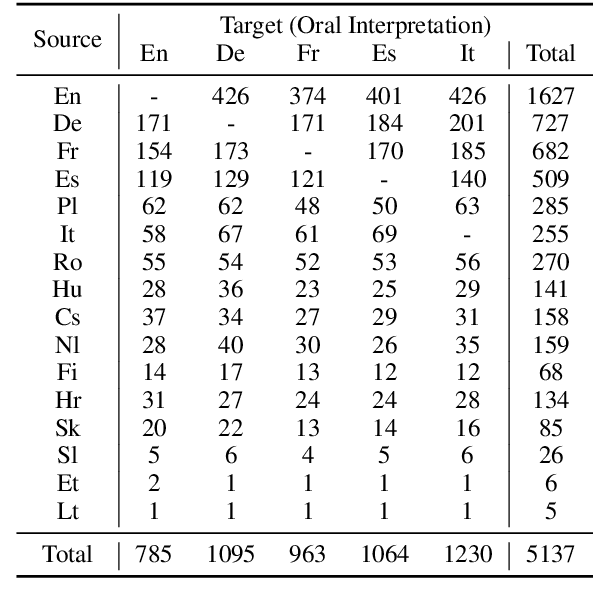

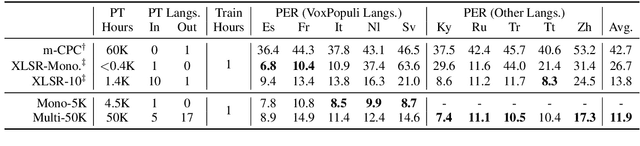
We introduce VoxPopuli, a large-scale multilingual corpus providing 100K hours of unlabelled speech data in 23 languages. It is the largest open data to date for unsupervised representation learning as well as semi-supervised learning. VoxPopuli also contains 1.8K hours of transcribed speeches in 16 languages and their aligned oral interpretations into 5 other languages totaling 5.1K hours. We provide speech recognition baselines and validate the versatility of VoxPopuli unlabelled data in semi-supervised learning under challenging out-of-domain settings. We will release the corpus at https://github.com/facebookresearch/voxpopuli under an open license.
Facebook AI's WMT20 News Translation Task Submission
Nov 16, 2020

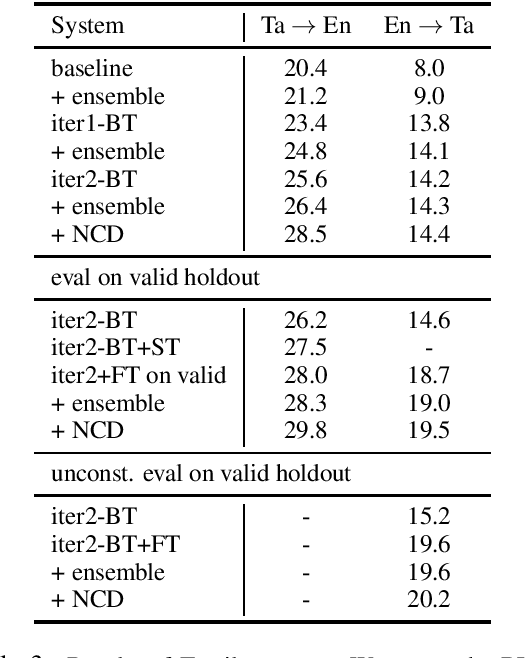
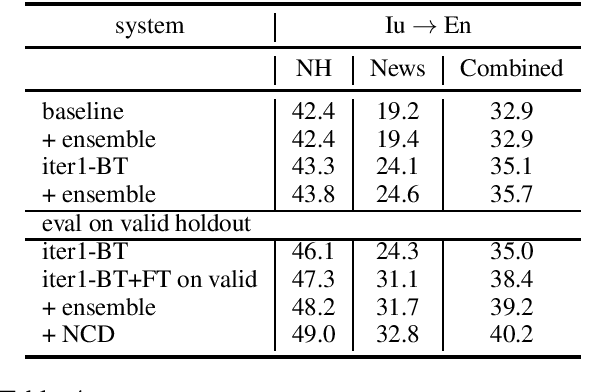
This paper describes Facebook AI's submission to WMT20 shared news translation task. We focus on the low resource setting and participate in two language pairs, Tamil <-> English and Inuktitut <-> English, where there are limited out-of-domain bitext and monolingual data. We approach the low resource problem using two main strategies, leveraging all available data and adapting the system to the target news domain. We explore techniques that leverage bitext and monolingual data from all languages, such as self-supervised model pretraining, multilingual models, data augmentation, and reranking. To better adapt the translation system to the test domain, we explore dataset tagging and fine-tuning on in-domain data. We observe that different techniques provide varied improvements based on the available data of the language pair. Based on the finding, we integrate these techniques into one training pipeline. For En->Ta, we explore an unconstrained setup with additional Tamil bitext and monolingual data and show that further improvement can be obtained. On the test set, our best submitted systems achieve 21.5 and 13.7 BLEU for Ta->En and En->Ta respectively, and 27.9 and 13.0 for Iu->En and En->Iu respectively.
Dual-decoder Transformer for Joint Automatic Speech Recognition and Multilingual Speech Translation
Nov 02, 2020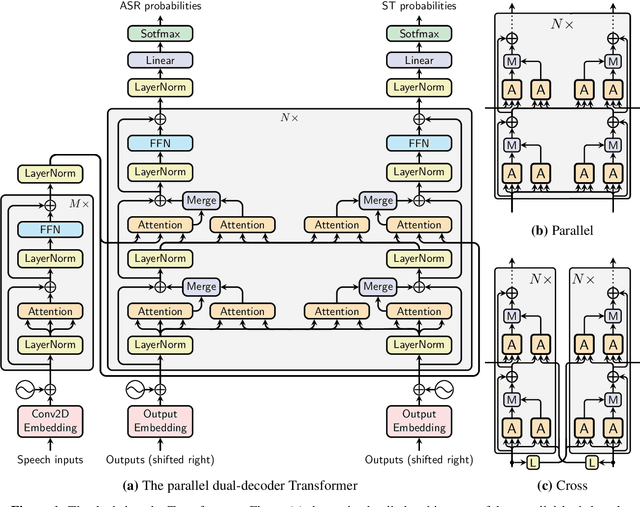
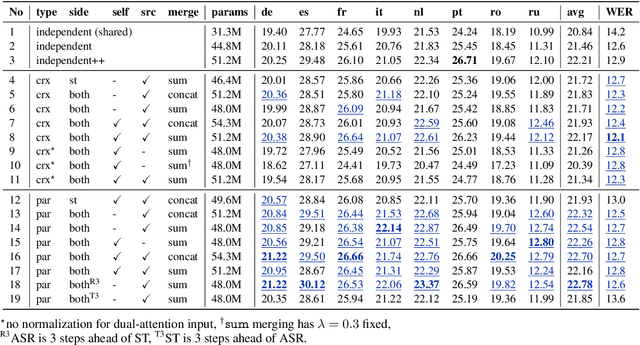
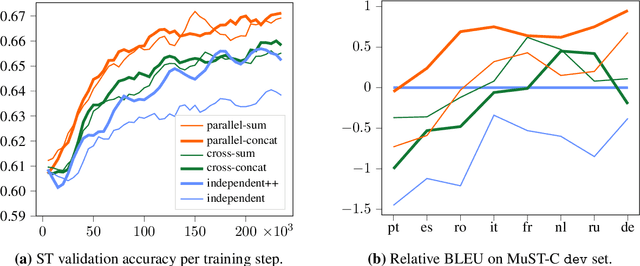
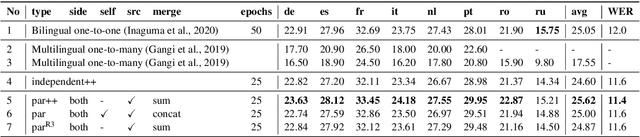
We introduce dual-decoder Transformer, a new model architecture that jointly performs automatic speech recognition (ASR) and multilingual speech translation (ST). Our models are based on the original Transformer architecture (Vaswani et al., 2017) but consist of two decoders, each responsible for one task (ASR or ST). Our major contribution lies in how these decoders interact with each other: one decoder can attend to different information sources from the other via a dual-attention mechanism. We propose two variants of these architectures corresponding to two different levels of dependencies between the decoders, called the parallel and cross dual-decoder Transformers, respectively. Extensive experiments on the MuST-C dataset show that our models outperform the previously-reported highest translation performance in the multilingual settings, and outperform as well bilingual one-to-one results. Furthermore, our parallel models demonstrate no trade-off between ASR and ST compared to the vanilla multi-task architecture. Our code and pre-trained models are available at https://github.com/formiel/speech-translation.
* Accepted at COLING 2020 (Oral)
Cross-Modal Transfer Learning for Multilingual Speech-to-Text Translation
Oct 24, 2020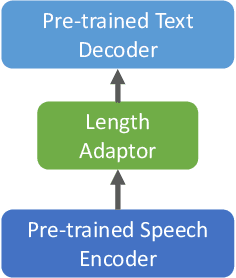
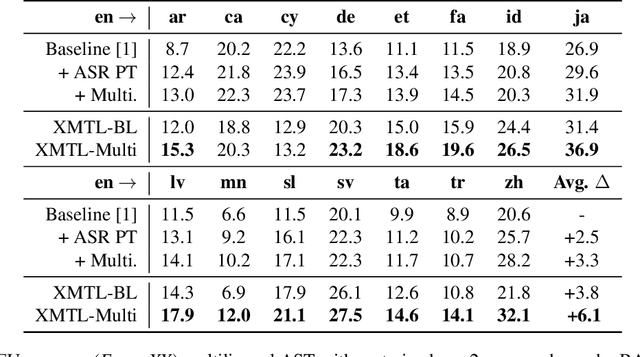
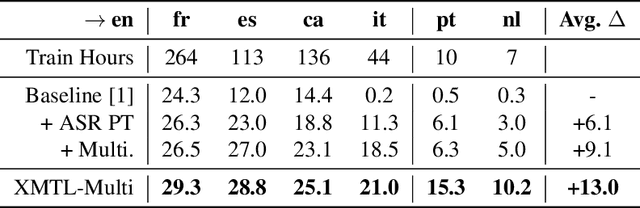

We propose an effective approach to utilize pretrained speech and text models to perform speech-to-text translation (ST). Our recipe to achieve cross-modal and cross-lingual transfer learning (XMTL) is simple and generalizable: using an adaptor module to bridge the modules pretrained in different modalities, and an efficient finetuning step which leverages the knowledge from pretrained modules yet making it work on a drastically different downstream task. With this approach, we built a multilingual speech-to-text translation model with pretrained audio encoder (wav2vec) and multilingual text decoder (mBART), which achieves new state-of-the-art on CoVoST 2 ST benchmark [1] for English into 15 languages as well as 6 Romance languages into English with on average +2.8 BLEU and +3.9 BLEU, respectively. On low-resource languages (with less than 10 hours training data), our approach significantly improves the quality of speech-to-text translation with +9.0 BLEU on Portuguese-English and +5.2 BLEU on Dutch-English.
A General Multi-Task Learning Framework to Leverage Text Data for Speech to Text Tasks
Oct 21, 2020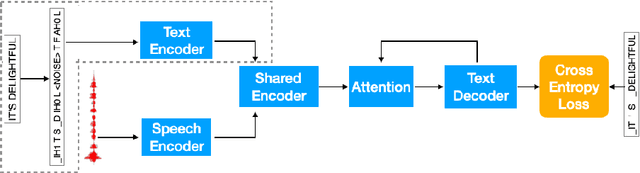
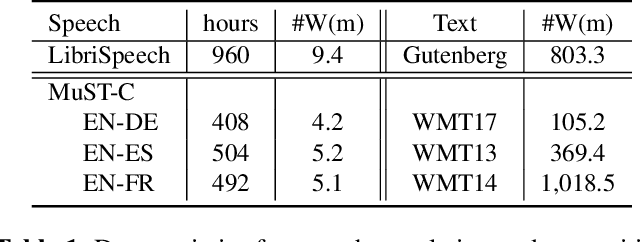
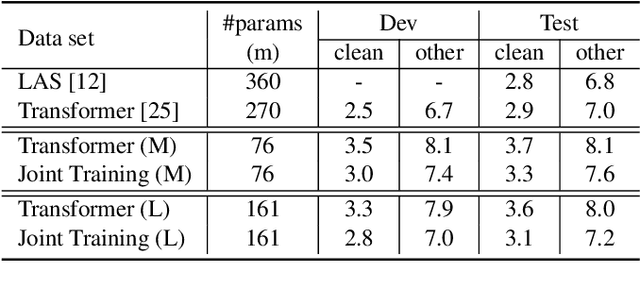
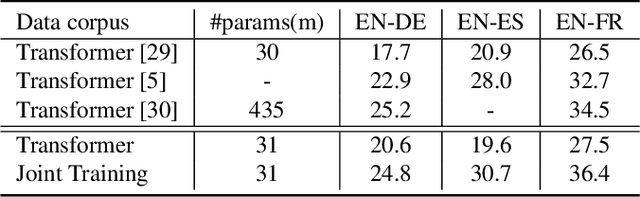
Attention-based sequence-to-sequence modeling provides a powerful and elegant solution for applications that need to map one sequence to a different sequence. Its success heavily relies on the availability of large amounts of training data. This presents a challenge for speech applications where labelled speech data is very expensive to obtain, such as automatic speech recognition (ASR) and speech translation (ST). In this study, we propose a general multi-task learning framework to leverage text data for ASR and ST tasks. Two auxiliary tasks, a denoising autoencoder task and machine translation task, are proposed to be co-trained with ASR and ST tasks respectively. We demonstrate that representing text input as phoneme sequences can reduce the difference between speech and text inputs, and enhance the knowledge transfer from text corpora to the speech to text tasks. Our experiments show that the proposed method achieves a relative 10~15% word error rate reduction on the English Librispeech task, and improves the speech translation quality on the MuST-C tasks by 4.2~11.1 BLEU.
fairseq S2T: Fast Speech-to-Text Modeling with fairseq
Oct 11, 2020
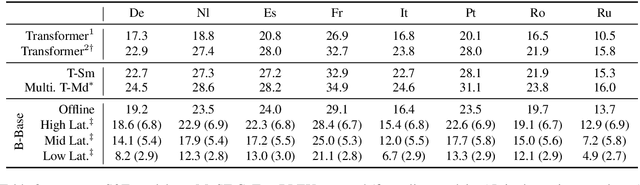

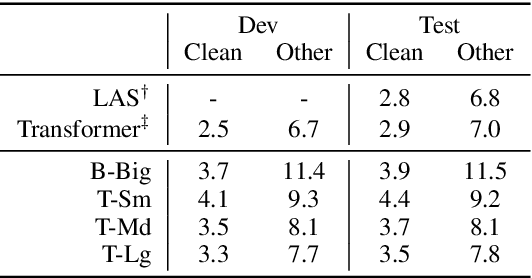
We introduce fairseq S2T, a fairseq extension for speech-to-text (S2T) modeling tasks such as end-to-end speech recognition and speech-to-text translation. It follows fairseq's careful design for scalability and extensibility. We provide end-to-end workflows from data pre-processing, model training to offline (online) inference. We implement state-of-the-art RNN-based as well as Transformer-based models and open-source detailed training recipes. Fairseq's machine translation models and language models can be seamlessly integrated into S2T workflows for multi-task learning or transfer learning. Fairseq S2T documentation and examples are available at https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text.
CoVoST 2 and Massively Multilingual Speech-to-Text Translation
Aug 20, 2020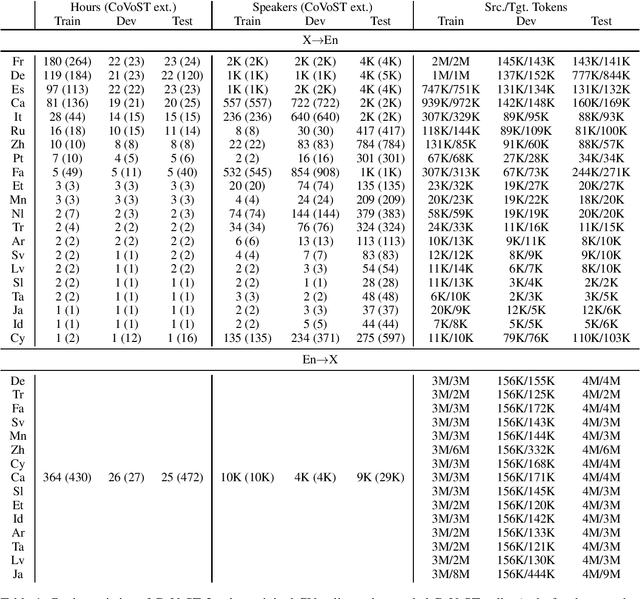
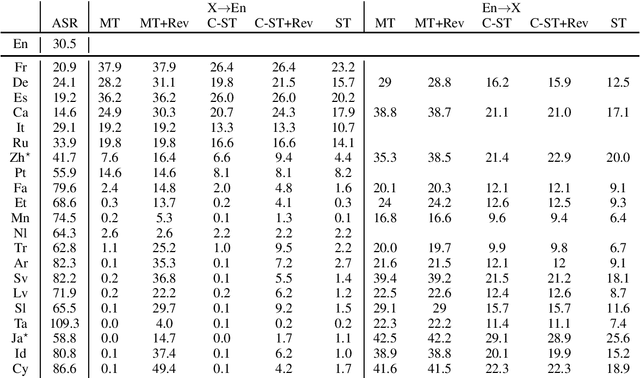
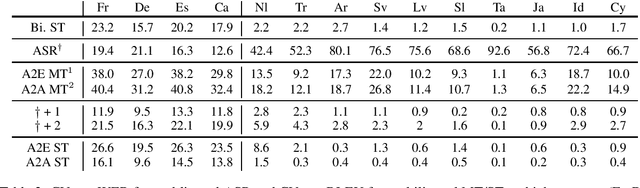
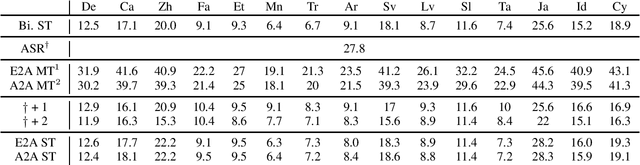
Speech translation has recently become an increasingly popular topic of research, partly due to the development of benchmark datasets. Nevertheless, current datasets cover a limited number of languages. With the aim to foster research in massive multilingual speech translation and speech translation for low resource language pairs, we release CoVoST 2, a large-scale multilingual speech translation corpus covering translations from 21 languages into English and from English into 15 languages. This represents the largest open dataset available to date from total volume and language coverage perspective. Data sanity checks provide evidence about the quality of the data, which is released under CC0 license. We also provide extensive speech recognition, bilingual and multilingual machine translation and speech translation baselines.
SimulEval: An Evaluation Toolkit for Simultaneous Translation
Jul 31, 2020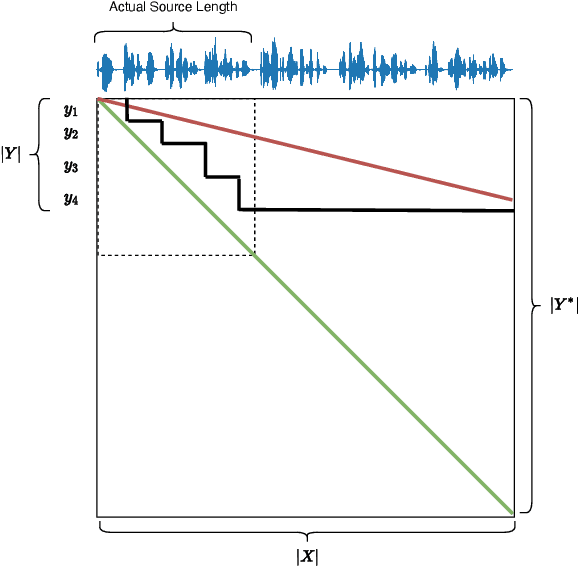

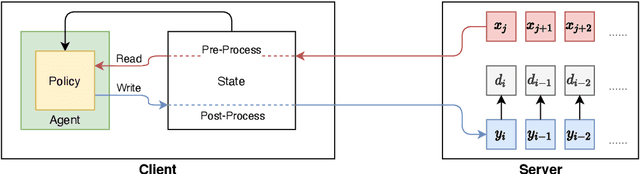
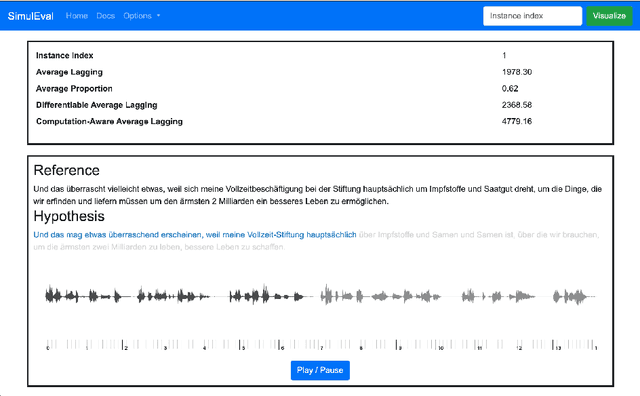
Simultaneous translation on both text and speech focuses on a real-time and low-latency scenario where the model starts translating before reading the complete source input. Evaluating simultaneous translation models is more complex than offline models because the latency is another factor to consider in addition to translation quality. The research community, despite its growing focus on novel modeling approaches to simultaneous translation, currently lacks a universal evaluation procedure. Therefore, we present SimulEval, an easy-to-use and general evaluation toolkit for both simultaneous text and speech translation. A server-client scheme is introduced to create a simultaneous translation scenario, where the server sends source input and receives predictions for evaluation and the client executes customized policies. Given a policy, it automatically performs simultaneous decoding and collectively reports several popular latency metrics. We also adapt latency metrics from text simultaneous translation to the speech task. Additionally, SimulEval is equipped with a visualization interface to provide better understanding of the simultaneous decoding process of a system. SimulEval has already been extensively used for the IWSLT 2020 shared task on simultaneous speech translation. Code will be released upon publication.
Self-Supervised Representations Improve End-to-End Speech Translation
Jun 22, 2020
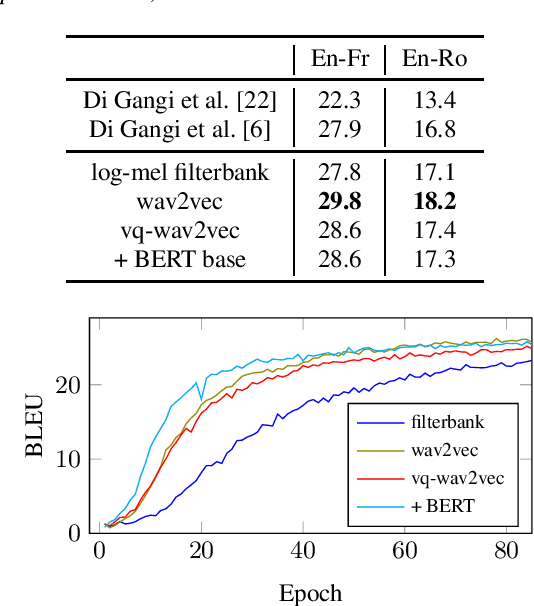
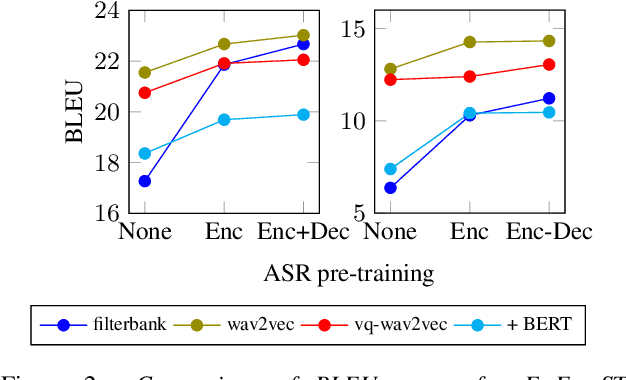
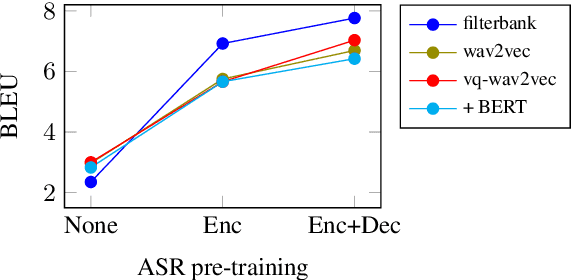
End-to-end speech-to-text translation can provide a simpler and smaller system but is facing the challenge of data scarcity. Pre-training methods can leverage unlabeled data and have been shown to be effective on data-scarce settings. In this work, we explore whether self-supervised pre-trained speech representations can benefit the speech translation task in both high- and low-resource settings, whether they can transfer well to other languages, and whether they can be effectively combined with other common methods that help improve low-resource end-to-end speech translation such as using a pre-trained high-resource speech recognition system. We demonstrate that self-supervised pre-trained features can consistently improve the translation performance, and cross-lingual transfer allows to extend to a variety of languages without or with little tuning.
Improving Cross-Lingual Transfer Learning for End-to-End Speech Recognition with Speech Translation
Jun 09, 2020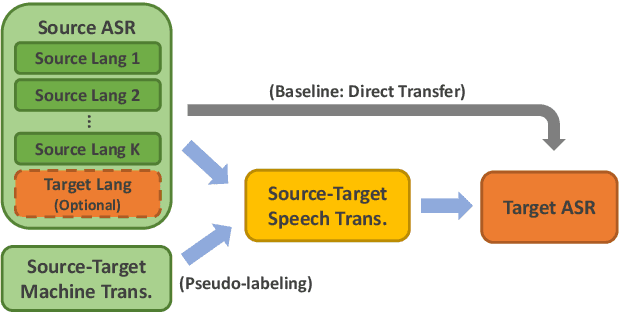
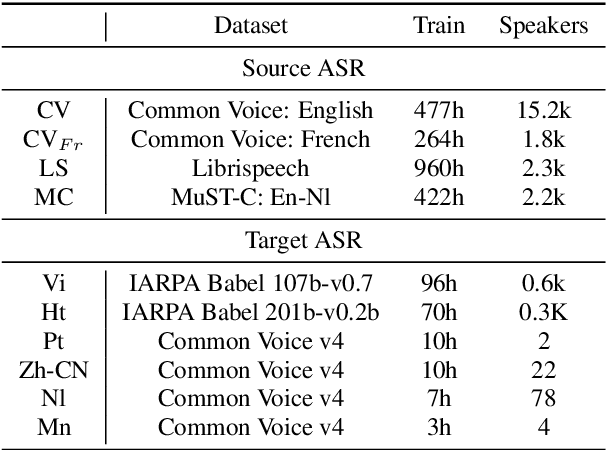
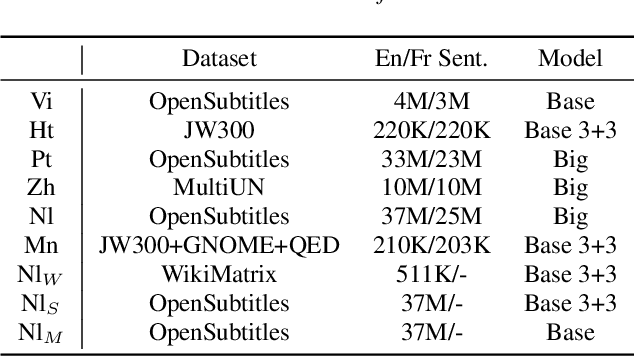
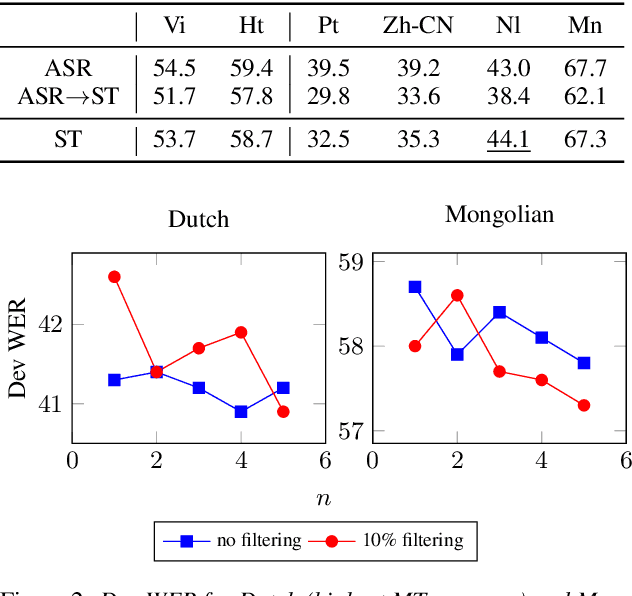
Transfer learning from high-resource languages is known to be an efficient way to improve end-to-end automatic speech recognition (ASR) for low-resource languages. Pre-trained or jointly trained encoder-decoder models, however, do not share the language modeling (decoder) for the same language, which is likely to be inefficient for distant target languages. We introduce speech-to-text translation (ST) as an auxiliary task to incorporate additional knowledge of the target language and enable transferring from that target language. Specifically, we first translate high-resource ASR transcripts into a target low-resource language, with which a ST model is trained. Both ST and target ASR share the same attention-based encoder-decoder architecture and vocabulary. The former task then provides a fully pre-trained model for the latter, bringing up to 24.6% word error rate (WER) reduction to the baseline (direct transfer from high-resource ASR). We show that training ST with human translations is not necessary. ST trained with machine translation (MT) pseudo-labels brings consistent gains. It can even outperform those using human labels when transferred to target ASR by leveraging only 500K MT examples. Even with pseudo-labels from low-resource MT (200K examples), ST-enhanced transfer brings up to 8.9% WER reduction to direct transfer.