 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Language Assistant as a Laboratory for Alignment
Dec 09, 2021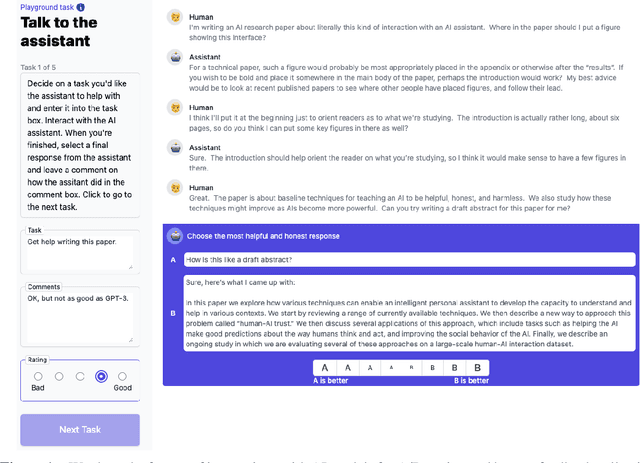
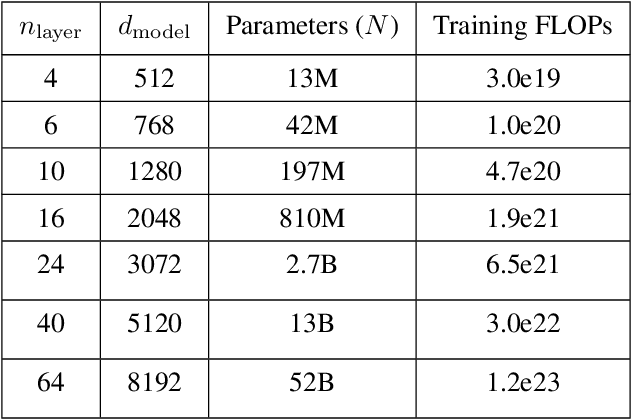
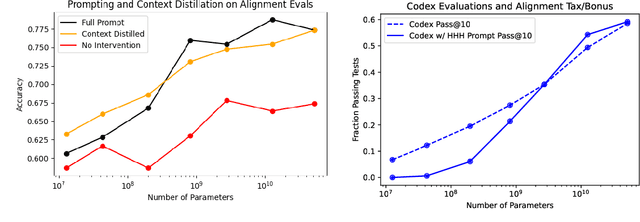
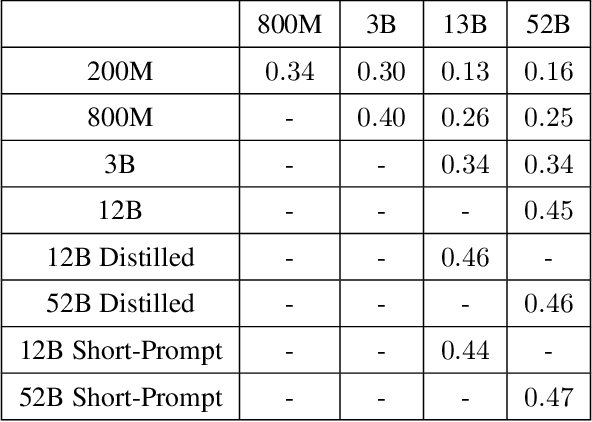
Given the broad capabilities of large language models, it should be possible to work towards a general-purpose, text-based assistant that is aligned with human values, meaning that it is helpful, honest, and harmless. As an initial foray in this direction we study simple baseline techniques and evaluations, such as prompting. We find that the benefits from modest interventions increase with model size, generalize to a variety of alignment evaluations, and do not compromise the performance of large models. Next we investigate scaling trends for several training objectives relevant to alignment, comparing imitation learning, binary discrimination, and ranked preference modeling. We find that ranked preference modeling performs much better than imitation learning, and often scales more favorably with model size. In contrast, binary discrimination typically performs and scales very similarly to imitation learning. Finally we study a `preference model pre-training' stage of training, with the goal of improving sample efficiency when finetuning on human preferences.
Dota 2 with Large Scale Deep Reinforcement Learning
Dec 13, 2019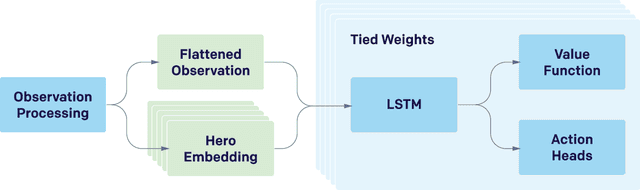
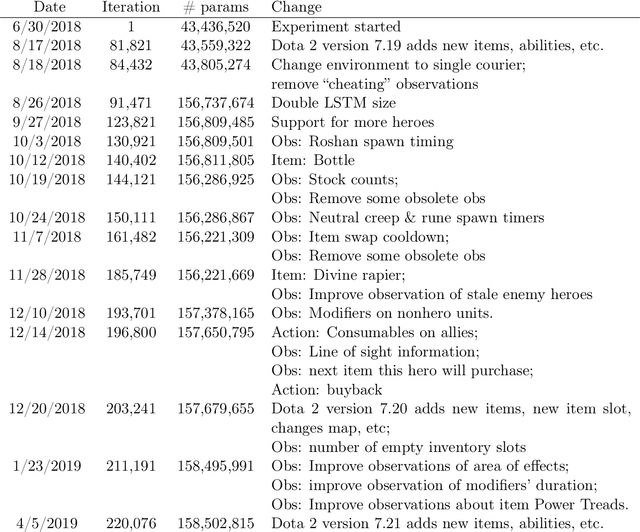
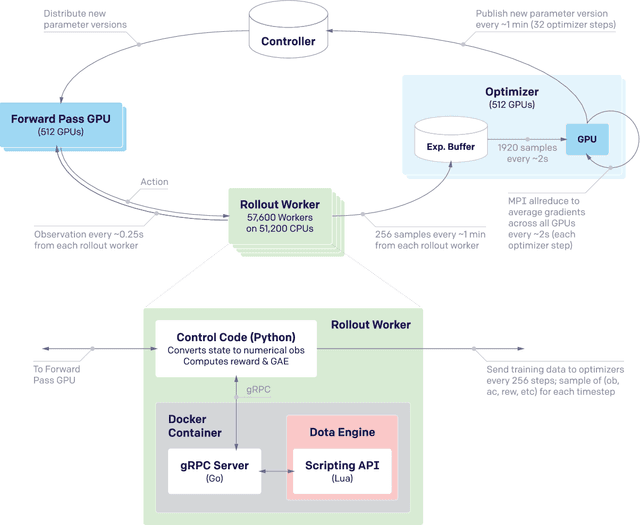
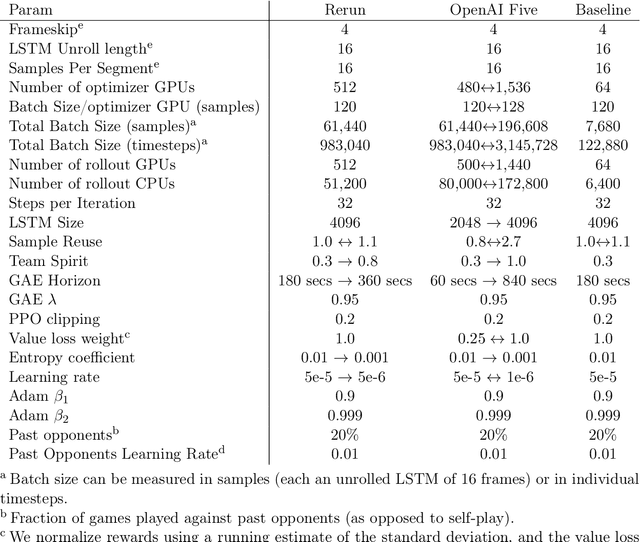
On April 13th, 2019, OpenAI Five became the first AI system to defeat the world champions at an esports game. The game of Dota 2 presents novel challenges for AI systems such as long time horizons, imperfect information, and complex, continuous state-action spaces, all challenges which will become increasingly central to more capable AI systems. OpenAI Five leveraged existing reinforcement learning techniques, scaled to learn from batches of approximately 2 million frames every 2 seconds. We developed a distributed training system and tools for continual training which allowed us to train OpenAI Five for 10 months. By defeating the Dota 2 world champion (Team OG), OpenAI Five demonstrates that self-play reinforcement learning can achieve superhuman performance on a difficult task.
Discriminator Rejection Sampling
Oct 18, 2018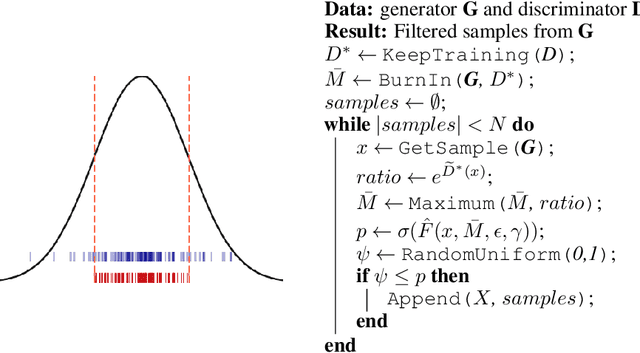

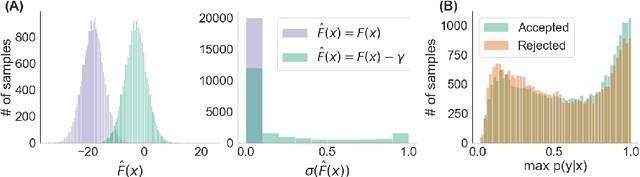

We propose a rejection sampling scheme using the discriminator of a GAN to approximately correct errors in the GAN generator distribution. We show that under quite strict assumptions, this will allow us to recover the data distribution exactly. We then examine where those strict assumptions break down and design a practical algorithm - called Discriminator Rejection Sampling (DRS) - that can be used on real data-sets. Finally, we demonstrate the efficacy of DRS on a mixture of Gaussians and on the SAGAN model, state-of-the-art in the image generation task at the time of developing this work. On ImageNet, we train an improved baseline that increases the Inception Score from 52.52 to 62.36 and reduces the Frechet Inception Distance from 18.65 to 14.79. We then use DRS to further improve on this baseline, improving the Inception Score to 76.08 and the FID to 13.75.
Unrestricted Adversarial Examples
Sep 22, 2018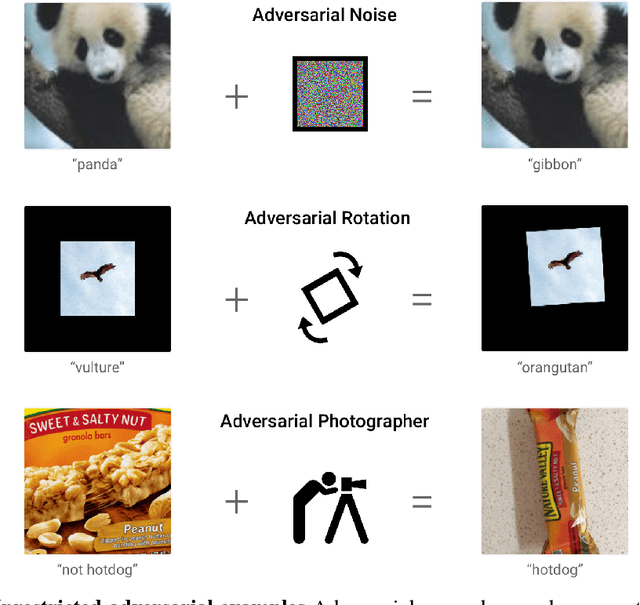

We introduce a two-player contest for evaluating the safety and robustness of machine learning systems, with a large prize pool. Unlike most prior work in ML robustness, which studies norm-constrained adversaries, we shift our focus to unconstrained adversaries. Defenders submit machine learning models, and try to achieve high accuracy and coverage on non-adversarial data while making no confident mistakes on adversarial inputs. Attackers try to subvert defenses by finding arbitrary unambiguous inputs where the model assigns an incorrect label with high confidence. We propose a simple unambiguous dataset ("bird-or- bicycle") to use as part of this contest. We hope this contest will help to more comprehensively evaluate the worst-case adversarial risk of machine learning models.
Skill Rating for Generative Models
Aug 14, 2018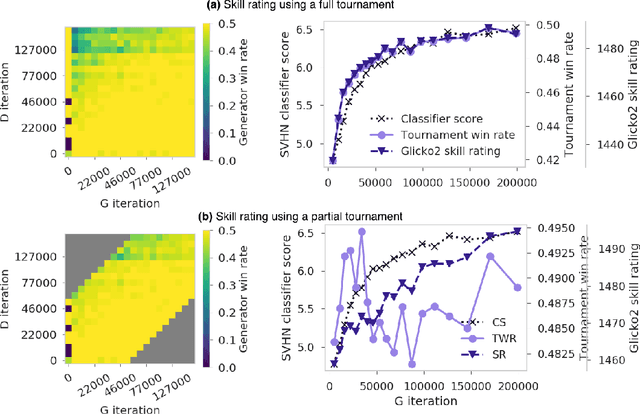
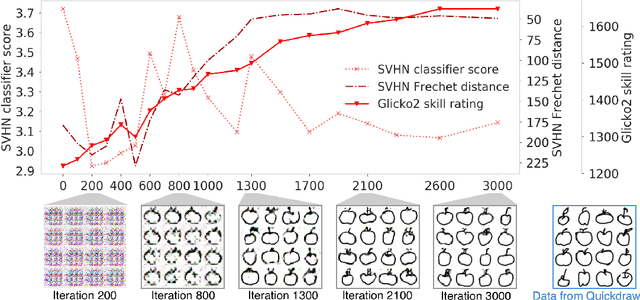
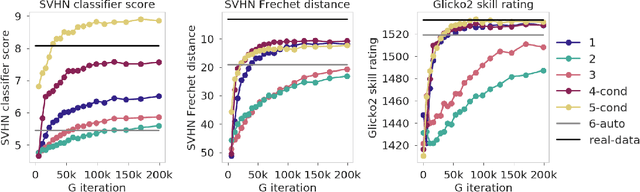

We explore a new way to evaluate generative models using insights from evaluation of competitive games between human players. We show experimentally that tournaments between generators and discriminators provide an effective way to evaluate generative models. We introduce two methods for summarizing tournament outcomes: tournament win rate and skill rating. Evaluations are useful in different contexts, including monitoring the progress of a single model as it learns during the training process, and comparing the capabilities of two different fully trained models. We show that a tournament consisting of a single model playing against past and future versions of itself produces a useful measure of training progress. A tournament containing multiple separate models (using different seeds, hyperparameters, and architectures) provides a useful relative comparison between different trained GANs. Tournament-based rating methods are conceptually distinct from numerous previous categories of approaches to evaluation of generative models, and have complementary advantages and disadvantages.
Is Generator Conditioning Causally Related to GAN Performance?
Jun 19, 2018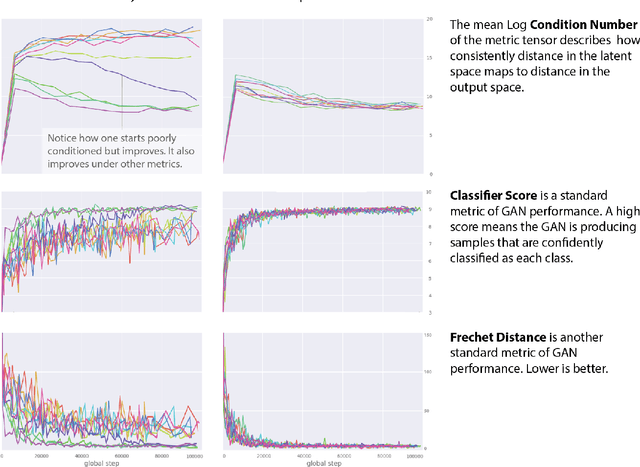
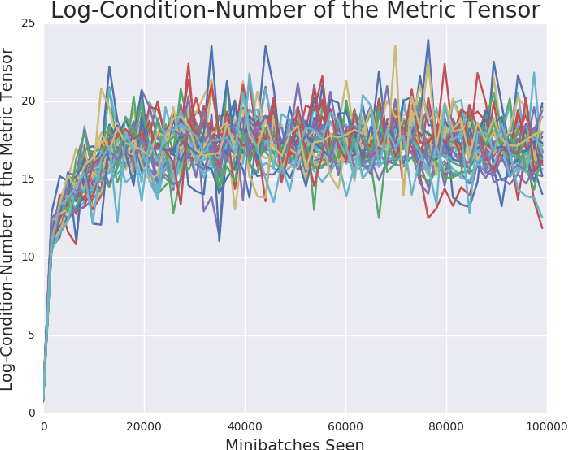
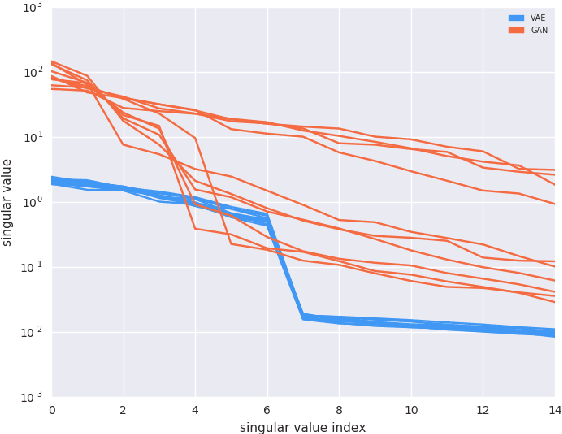
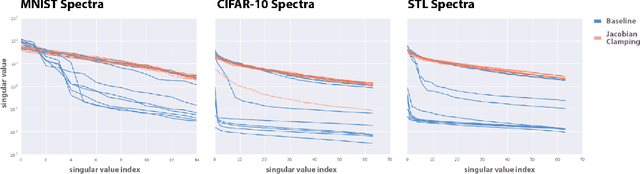
Recent work (Pennington et al, 2017) suggests that controlling the entire distribution of Jacobian singular values is an important design consideration in deep learning. Motivated by this, we study the distribution of singular values of the Jacobian of the generator in Generative Adversarial Networks (GANs). We find that this Jacobian generally becomes ill-conditioned at the beginning of training. Moreover, we find that the average (with z from p(z)) conditioning of the generator is highly predictive of two other ad-hoc metrics for measuring the 'quality' of trained GANs: the Inception Score and the Frechet Inception Distance (FID). We test the hypothesis that this relationship is causal by proposing a 'regularization' technique (called Jacobian Clamping) that softly penalizes the condition number of the generator Jacobian. Jacobian Clamping improves the mean Inception Score and the mean FID for GANs trained on several datasets. It also greatly reduces inter-run variance of the aforementioned scores, addressing (at least partially) one of the main criticisms of GANs.