 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Information Bottleneck with Invertible Neural Networks: Getting the Best of Discriminative and Generative Modeling
Jan 20, 2020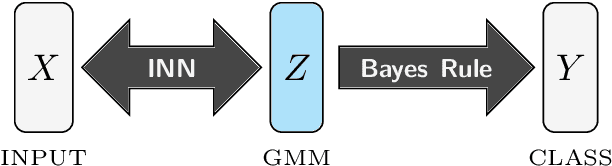

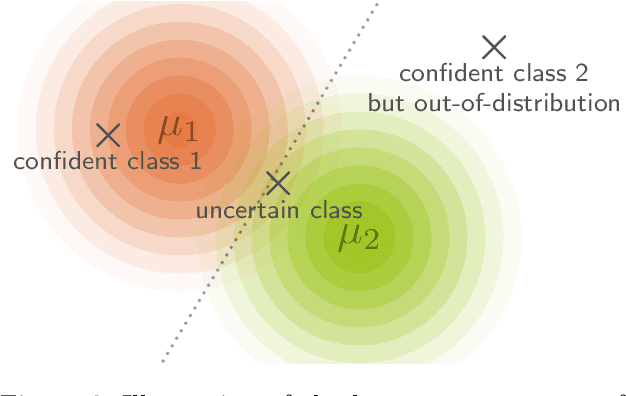
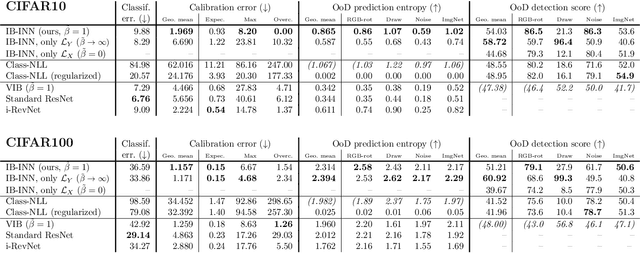
The Information Bottleneck (IB) principle offers a unified approach to many learning and prediction problems. Although optimal in an information-theoretic sense, practical applications of IB are hampered by a lack of accurate high-dimensional estimators of mutual information, its main constituent. We propose to combine IB with invertible neural networks (INNs), which for the first time allows exact calculation of the required mutual information. Applied to classification, our proposed method results in a generative classifier we call IB-INN. It accurately models the class conditional likelihoods, generalizes well to unseen data and reliably recognizes out-of-distribution examples. In contrast to existing generative classifiers, these advantages incur only minor reductions in classification accuracy in comparison to corresponding discriminative methods such as feed-forward networks. Furthermore, we provide insight into why IB-INNs are superior to other generative architectures and training procedures and show experimentally that our method outperforms alternative models of comparable complexity.
Disentanglement by Nonlinear ICA with General Incompressible-flow Networks (GIN)
Jan 14, 2020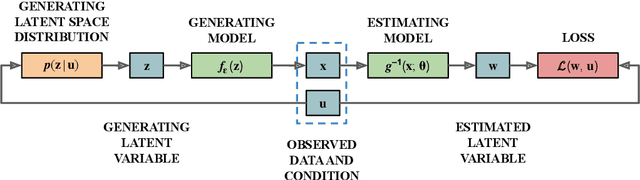

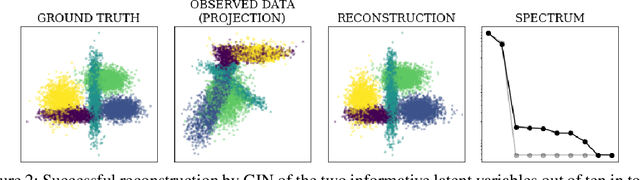

A central question of representation learning asks under which conditions it is possible to reconstruct the true latent variables of an arbitrarily complex generative process. Recent breakthrough work by Khemakhem et al. (2019) on nonlinear ICA has answered this question for a broad class of conditional generative processes. We extend this important result in a direction relevant for application to real-world data. First, we generalize the theory to the case of unknown intrinsic problem dimension and prove that in some special (but not very restrictive) cases, informative latent variables will be automatically separated from noise by an estimating model. Furthermore, the recovered informative latent variables will be in one-to-one correspondence with the true latent variables of the generating process, up to a trivial component-wise transformation. Second, we introduce a modification of the RealNVP invertible neural network architecture (Dinh et al. (2016)) which is particularly suitable for this type of problem: the General Incompressible-flow Network (GIN). Experiments on artificial data and EMNIST demonstrate that theoretical predictions are indeed verified in practice. In particular, we provide a detailed set of exactly 22 informative latent variables extracted from EMNIST.
CONSAC: Robust Multi-Model Fitting by Conditional Sample Consensus
Jan 08, 2020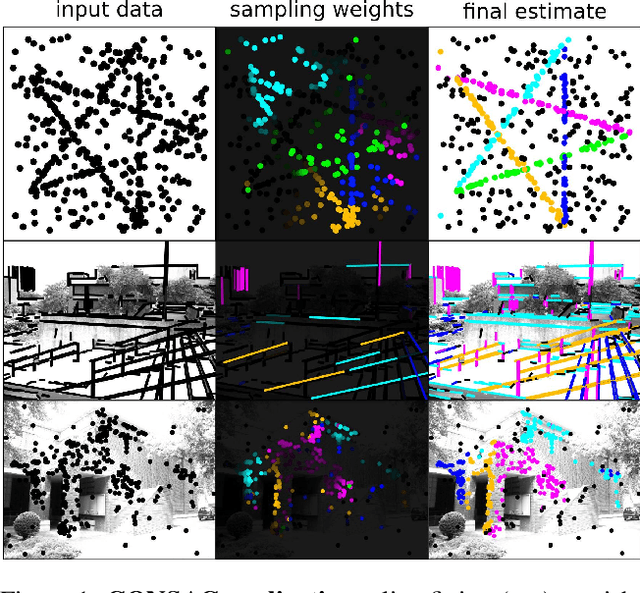
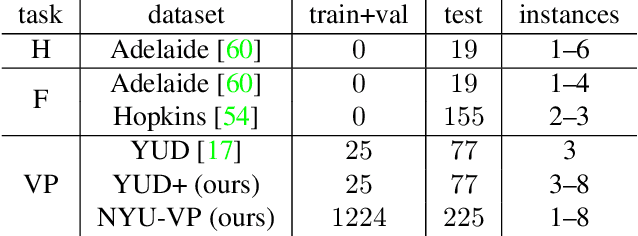
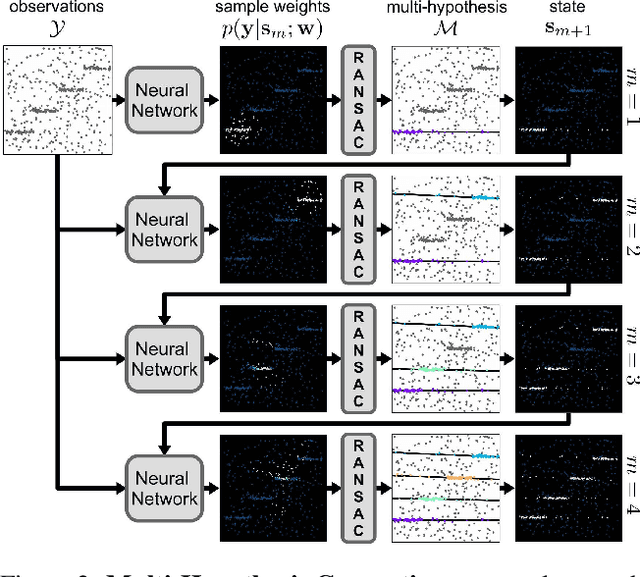
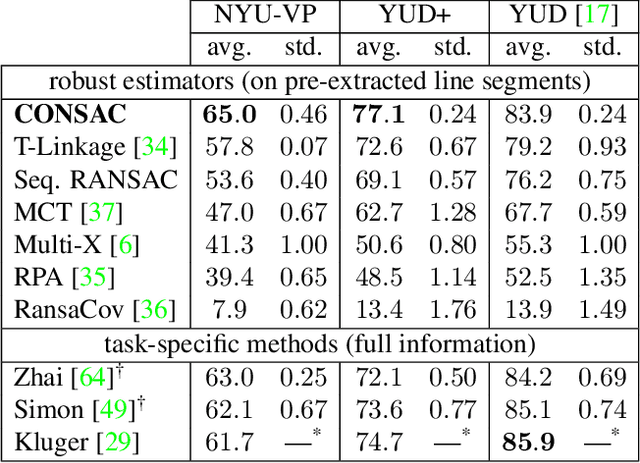
We present a robust estimator for fitting multiple parametric models of the same form to noisy measurements. Applications include finding multiple vanishing points in man-made scenes, fitting planes to architectural imagery, or estimating multiple rigid motions within the same sequence. In contrast to previous works, which resorted to hand-crafted search strategies for multiple model detection, we learn the search strategy from data. A neural network conditioned on previously detected models guides a RANSAC estimator to different subsets of all measurements, thereby finding model instances one after another. We train our method supervised as well as self-supervised. For supervised training of the search strategy, we contribute a new dataset for vanishing point estimation. Leveraging this dataset, the proposed algorithm is superior with respect to other robust estimators as well as to designated vanishing point estimation algorithms. For self-supervised learning of the search, we evaluate the proposed algorithm on multi-homography estimation and demonstrate an accuracy that is superior to state-of-the-art methods.
Reinforced Feature Points: Optimizing Feature Detection and Description for a High-Level Task
Dec 02, 2019
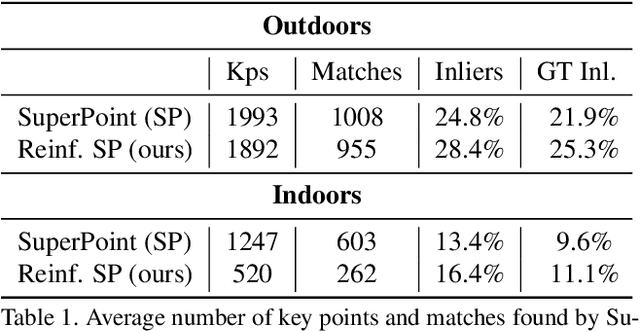
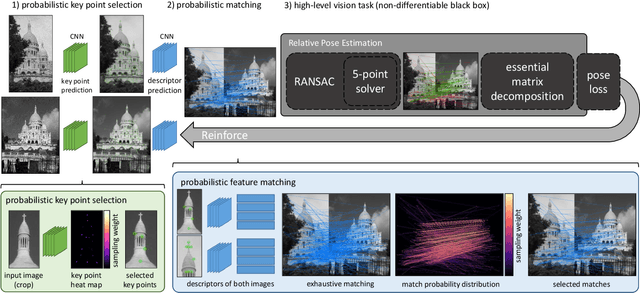
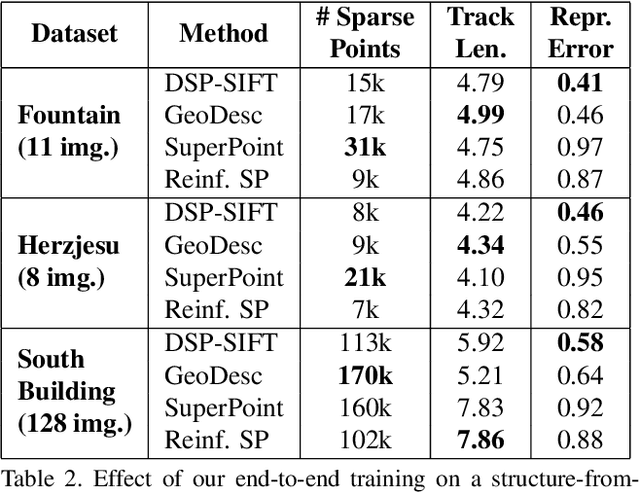
We address a core problem of computer vision: Detection and description of 2D feature points for image matching. For a long time, hand-crafted designs, like the seminal SIFT algorithm, were unsurpassed in accuracy and efficiency. Recently, learned feature detectors emerged that implement detection and description using neural networks. Training these networks usually resorts to optimizing low-level matching scores, often pre-defining sets of image patches which should or should not match, or which should or should not contain key points. Unfortunately, increased accuracy for these low-level matching scores does not necessarily translate to better performance in high-level vision tasks. We propose a new training methodology which embeds the feature detector in a complete vision pipeline, and where the learnable parameters are trained in an end-to-end fashion. We overcome the discrete nature of key point selection and descriptor matching using principles from reinforcement learning. As an example, we address the task of relative pose estimation between a pair of images. We demonstrate that the accuracy of a state-of-the-art learning-based feature detector can be increased when trained for the task it is supposed to solve at test time. Our training methodology poses little restrictions on the task to learn, and works for any architecture which predicts key point heat maps, and descriptors for key point locations.
Out of distribution detection for intra-operative functional imaging
Nov 05, 2019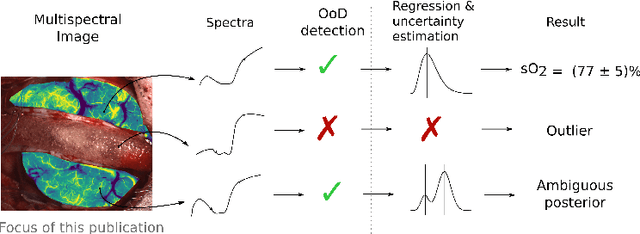
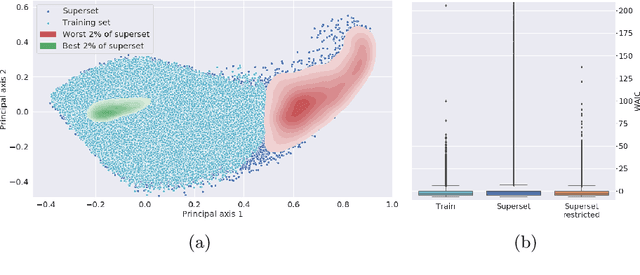
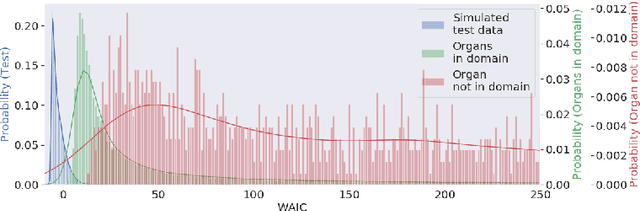
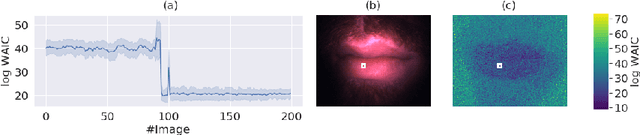
Multispectral optical imaging is becoming a key tool in the operating room. Recent research has shown that machine learning algorithms can be used to convert pixel-wise reflectance measurements to tissue parameters, such as oxygenation. However, the accuracy of these algorithms can only be guaranteed if the spectra acquired during surgery match the ones seen during training. It is therefore of great interest to detect so-called out of distribution (OoD) spectra to prevent the algorithm from presenting spurious results. In this paper we present an information theory based approach to OoD detection based on the widely applicable information criterion (WAIC). Our work builds upon recent methodology related to invertible neural networks (INN). Specifically, we make use of an ensemble of INNs as we need their tractable Jacobians in order to compute the WAIC. Comprehensive experiments with in silico, and in vivo multispectral imaging data indicate that our approach is well-suited for OoD detection. Our method could thus be an important step towards reliable functional imaging in the operating room.
* The final authenticated version is available online at https://doi.org/10.1007/978-3-030-32689-0_8
Learning to Think Outside the Box: Wide-Baseline Light Field Depth Estimation with EPI-Shift
Sep 19, 2019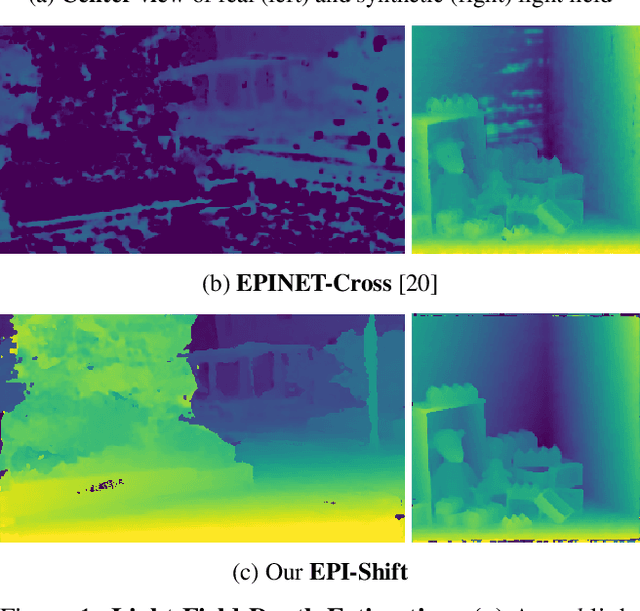


We propose a method for depth estimation from light field data, based on a fully convolutional neural network architecture. Our goal is to design a pipeline which achieves highly accurate results for small- and wide-baseline light fields. Since light field training data is scarce, all learning-based approaches use a small receptive field and operate on small disparity ranges. In order to work with wide-baseline light fields, we introduce the idea of EPI-Shift: To virtually shift the light field stack which enables to retain a small receptive field, independent of the disparity range. In this way, our approach "learns to think outside the box of the receptive field". Our network performs joint classification of integer disparities and regression of disparity-offsets. A U-Net component provides excellent long-range smoothing. EPI-Shift considerably outperforms the state-of-the-art learning-based approaches and is on par with hand-crafted methods. We demonstrate this on a publicly available, synthetic, small-baseline benchmark and on large-baseline real-world recordings.
Benchmarking the Robustness of Semantic Segmentation Models
Aug 14, 2019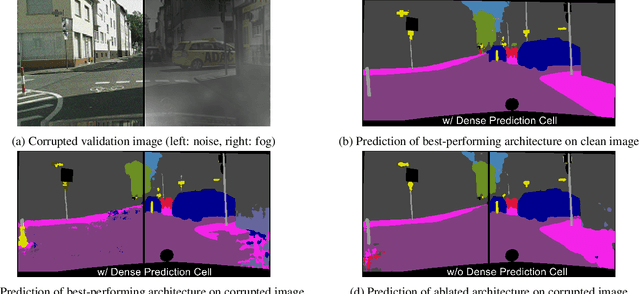


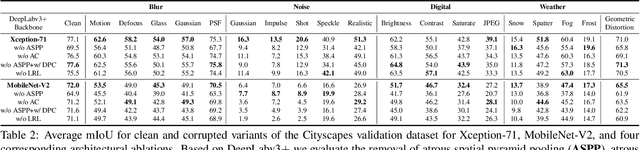
When designing a semantic segmentation module for a practical application, such as autonomous driving, it is crucial to understand the robustness of the module with respect to a wide range of image corruptions. While there are recent robustness studies for full-image classification, we are the first to present an exhaustive study for semantic segmentation, based on the state-of-the-art model DeepLabv3$+$. To increase the realism of our study, we utilize almost 200,000 images generated from Cityscapes and PASCAL VOC 2012, and we furthermore present a realistic noise model, imitating HDR camera noise. Based on the benchmark study we gain several new insights. Firstly, model robustness increases with model performance, in most cases. Secondly, some architecture properties affect robustness significantly, such as a Dense Prediction Cell which was designed to maximize performance on clean data only. Thirdly, to achieve good generalization with respect to various types of image noise, it is recommended to train DeepLabv3+ with our realistic noise model.
Expert Sample Consensus Applied to Camera Re-Localization
Aug 07, 2019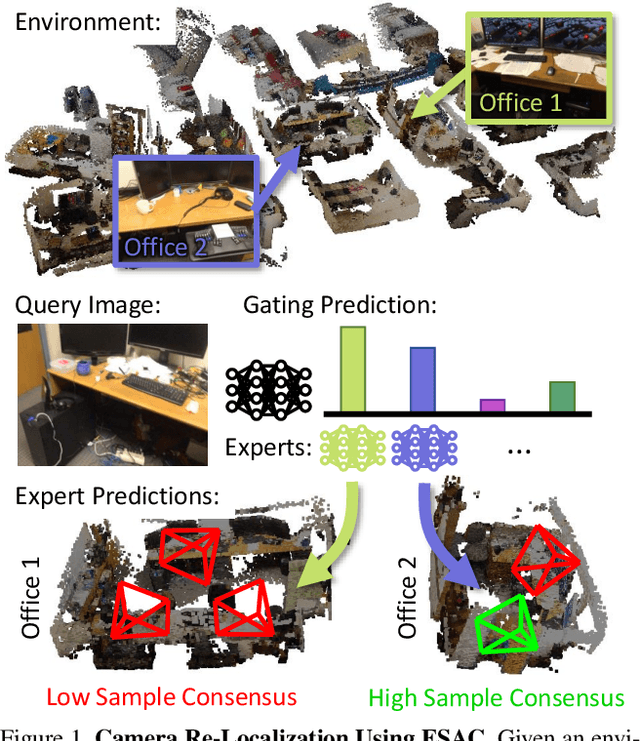
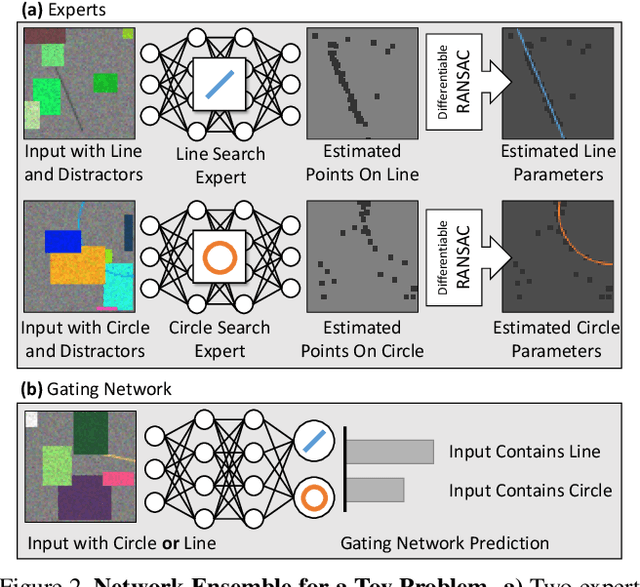
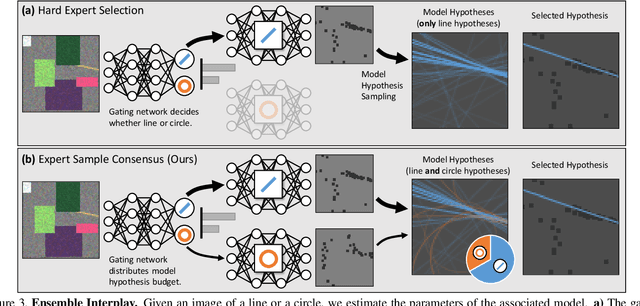
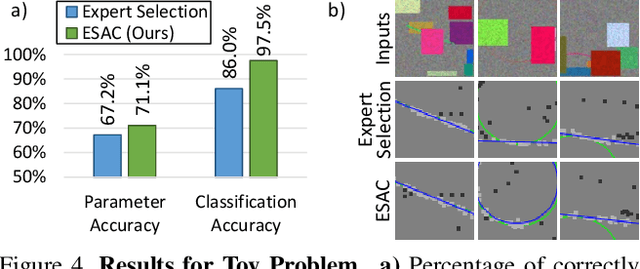
Fitting model parameters to a set of noisy data points is a common problem in computer vision. In this work, we fit the 6D camera pose to a set of noisy correspondences between the 2D input image and a known 3D environment. We estimate these correspondences from the image using a neural network. Since the correspondences often contain outliers, we utilize a robust estimator such as Random Sample Consensus (RANSAC) or Differentiable RANSAC (DSAC) to fit the pose parameters. When the problem domain, e.g. the space of all 2D-3D correspondences, is large or ambiguous, a single network does not cover the domain well. Mixture of Experts (MoE) is a popular strategy to divide a problem domain among an ensemble of specialized networks, so called experts, where a gating network decides which expert is responsible for a given input. In this work, we introduce Expert Sample Consensus (ESAC), which integrates DSAC in a MoE. Our main technical contribution is an efficient method to train ESAC jointly and end-to-end. We demonstrate experimentally that ESAC handles two real-world problems better than competing methods, i.e. scalability and ambiguity. We apply ESAC to fitting simple geometric models to synthetic images, and to camera re-localization for difficult, real datasets.
Guided Image Generation with Conditional Invertible Neural Networks
Jul 10, 2019

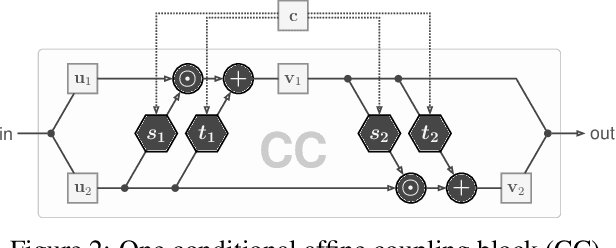
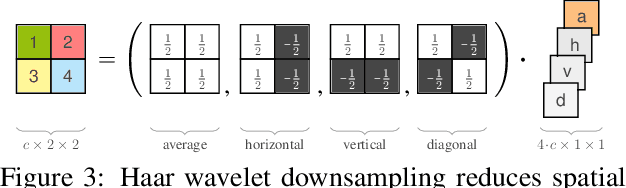
In this work, we address the task of natural image generation guided by a conditioning input. We introduce a new architecture called conditional invertible neural network (cINN). The cINN combines the purely generative INN model with an unconstrained feed-forward network, which efficiently preprocesses the conditioning input into useful features. All parameters of the cINN are jointly optimized with a stable, maximum likelihood-based training procedure. By construction, the cINN does not experience mode collapse and generates diverse samples, in contrast to e.g. cGANs. At the same time our model produces sharp images since no reconstruction loss is required, in contrast to e.g. VAEs. We demonstrate these properties for the tasks of MNIST digit generation and image colorization. Furthermore, we take advantage of our bi-directional cINN architecture to explore and manipulate emergent properties of the latent space, such as changing the image style in an intuitive way.
HINT: Hierarchical Invertible Neural Transport for General and Sequential Bayesian inference
May 25, 2019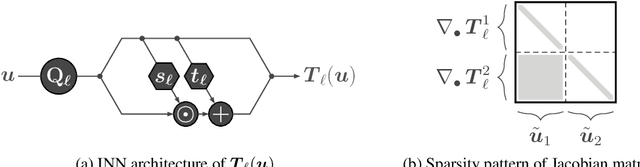
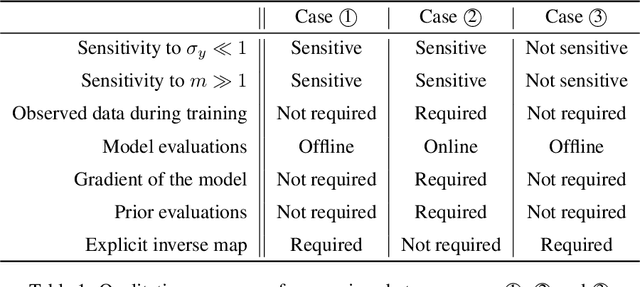
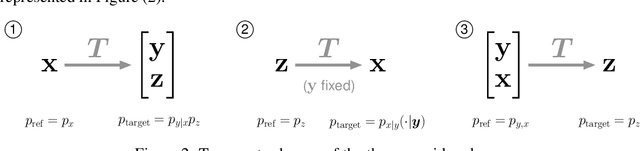
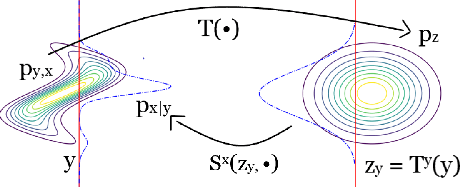
In this paper, we introduce Hierarchical Invertible Neural Transport (HINT), an algorithm that merges Invertible Neural Networks and optimal transport to sample from a posterior distribution in a Bayesian framework. This method exploits a hierarchical architecture to construct a Knothe-Rosenblatt transport map between an arbitrary density and the joint density of hidden variables and observations. After training the map, samples from the posterior can be immediately recovered for any contingent observation. Any underlying model evaluation can be performed fully offline from training without the need of a model-gradient. Furthermore, no analytical evaluation of the prior is necessary, which makes HINT an ideal candidate for sequential Bayesian inference. We demonstrate the efficacy of HINT on two numerical experiments.