 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting a Face to the Voice: Fusing Audio and Visual Signals Across a Video to Determine Speakers
May 31, 2017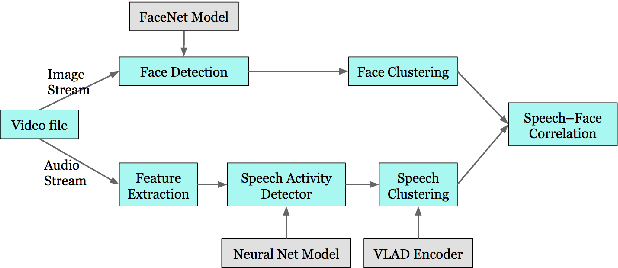
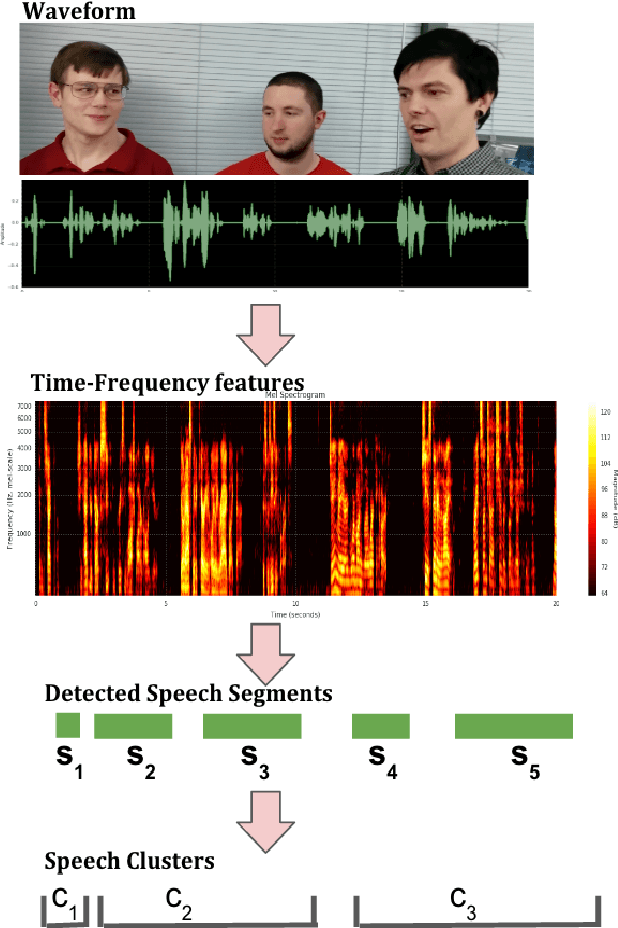
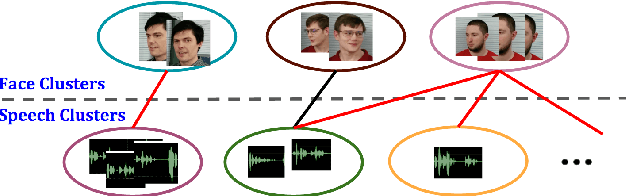
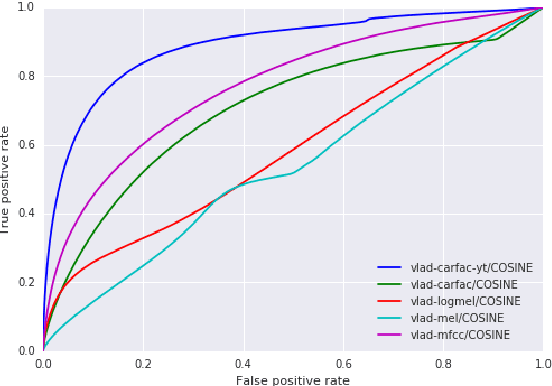
In this paper, we present a system that associates faces with voices in a video by fusing information from the audio and visual signals. The thesis underlying our work is that an extremely simple approach to generating (weak) speech clusters can be combined with visual signals to effectively associate faces and voices by aggregating statistics across a video. This approach does not need any training data specific to this task and leverages the natural coherence of information in the audio and visual streams. It is particularly applicable to tracking speakers in videos on the web where a priori information about the environment (e.g., number of speakers, spatial signals for beamforming) is not available. We performed experiments on a real-world dataset using this analysis framework to determine the speaker in a video. Given a ground truth labeling determined by human rater consensus, our approach had ~71% accuracy.
Egocentric Field-of-View Localization Using First-Person Point-of-View Devices
Oct 07, 2015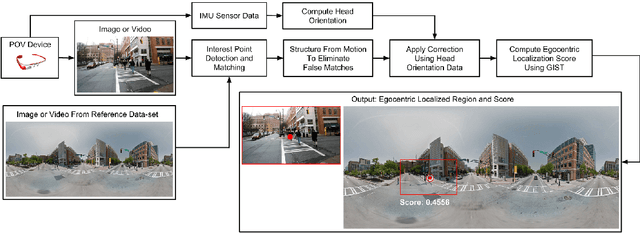
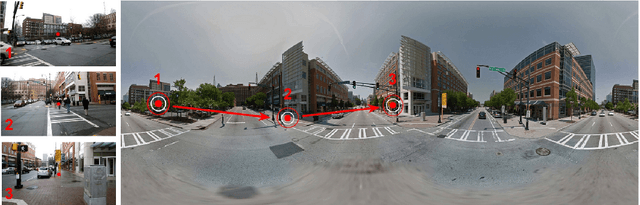


We present a technique that uses images, videos and sensor data taken from first-person point-of-view devices to perform egocentric field-of-view (FOV) localization. We define egocentric FOV localization as capturing the visual information from a person's field-of-view in a given environment and transferring this information onto a reference corpus of images and videos of the same space, hence determining what a person is attending to. Our method matches images and video taken from the first-person perspective with the reference corpus and refines the results using the first-person's head orientation information obtained using the device sensors. We demonstrate single and multi-user egocentric FOV localization in different indoor and outdoor environments with applications in augmented reality, event understanding and studying social interactions.
Pose Embeddings: A Deep Architecture for Learning to Match Human Poses
Jul 01, 2015


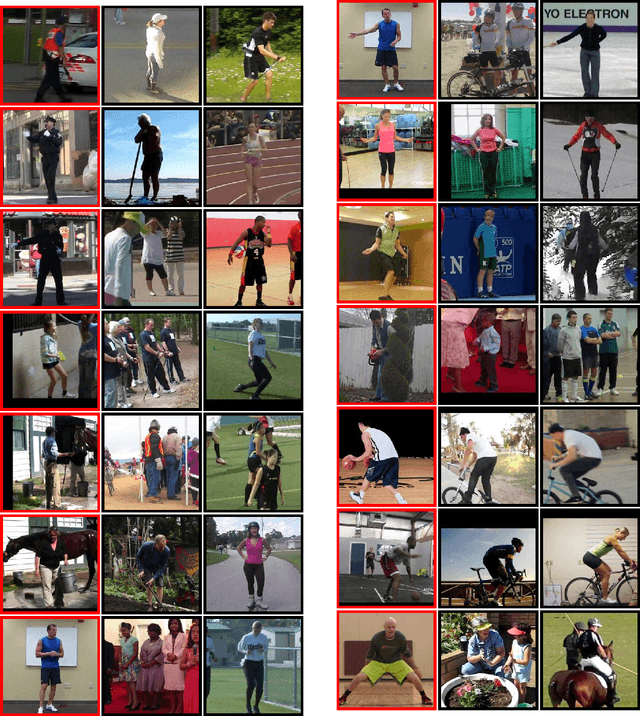
We present a method for learning an embedding that places images of humans in similar poses nearby. This embedding can be used as a direct method of comparing images based on human pose, avoiding potential challenges of estimating body joint positions. Pose embedding learning is formulated under a triplet-based distance criterion. A deep architecture is used to allow learning of a representation capable of making distinctions between different poses. Experiments on human pose matching and retrieval from video data demonstrate the potential of the method.