 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervising 3D Talking Head Avatars with Analysis-by-Audio-Synthesis
Apr 18, 2025



In order to be widely applicable, speech-driven 3D head avatars must articulate their lips in accordance with speech, while also conveying the appropriate emotions with dynamically changing facial expressions. The key problem is that deterministic models produce high-quality lip-sync but without rich expressions, whereas stochastic models generate diverse expressions but with lower lip-sync quality. To get the best of both, we seek a stochastic model with accurate lip-sync. To that end, we develop a new approach based on the following observation: if a method generates realistic 3D lip motions, it should be possible to infer the spoken audio from the lip motion. The inferred speech should match the original input audio, and erroneous predictions create a novel supervision signal for training 3D talking head avatars with accurate lip-sync. To demonstrate this effect, we propose THUNDER (Talking Heads Under Neural Differentiable Elocution Reconstruction), a 3D talking head avatar framework that introduces a novel supervision mechanism via differentiable sound production. First, we train a novel mesh-to-speech model that regresses audio from facial animation. Then, we incorporate this model into a diffusion-based talking avatar framework. During training, the mesh-to-speech model takes the generated animation and produces a sound that is compared to the input speech, creating a differentiable analysis-by-audio-synthesis supervision loop. Our extensive qualitative and quantitative experiments demonstrate that THUNDER significantly improves the quality of the lip-sync of talking head avatars while still allowing for generation of diverse, high-quality, expressive facial animations.
Towards Scalable Multi-View Reconstruction of Geometry and Materials
Jun 06, 2023In this paper, we propose a novel method for joint recovery of camera pose, object geometry and spatially-varying Bidirectional Reflectance Distribution Function (svBRDF) of 3D scenes that exceed object-scale and hence cannot be captured with stationary light stages. The input are high-resolution RGB-D images captured by a mobile, hand-held capture system with point lights for active illumination. Compared to previous works that jointly estimate geometry and materials from a hand-held scanner, we formulate this problem using a single objective function that can be minimized using off-the-shelf gradient-based solvers. To facilitate scalability to large numbers of observation views and optimization variables, we introduce a distributed optimization algorithm that reconstructs 2.5D keyframe-based representations of the scene. A novel multi-view consistency regularizer effectively synchronizes neighboring keyframes such that the local optimization results allow for seamless integration into a globally consistent 3D model. We provide a study on the importance of each component in our formulation and show that our method compares favorably to baselines. We further demonstrate that our method accurately reconstructs various objects and materials and allows for expansion to spatially larger scenes. We believe that this work represents a significant step towards making geometry and material estimation from hand-held scanners scalable.
SMD-Nets: Stereo Mixture Density Networks
Apr 08, 2021
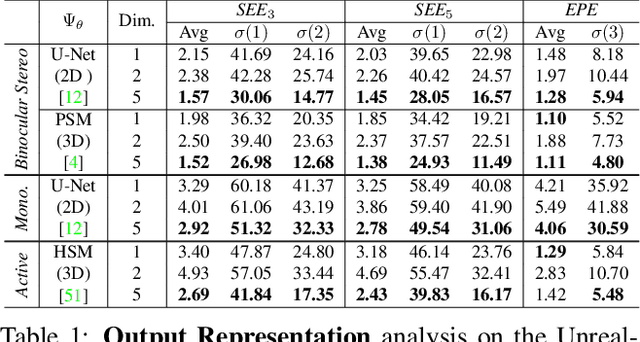
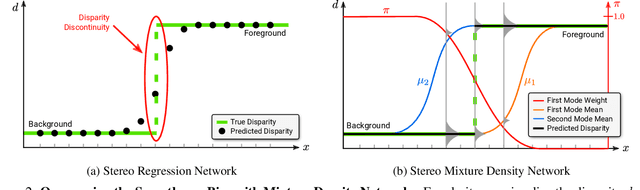
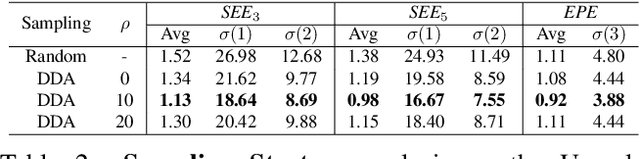
Despite stereo matching accuracy has greatly improved by deep learning in the last few years, recovering sharp boundaries and high-resolution outputs efficiently remains challenging. In this paper, we propose Stereo Mixture Density Networks (SMD-Nets), a simple yet effective learning framework compatible with a wide class of 2D and 3D architectures which ameliorates both issues. Specifically, we exploit bimodal mixture densities as output representation and show that this allows for sharp and precise disparity estimates near discontinuities while explicitly modeling the aleatoric uncertainty inherent in the observations. Moreover, we formulate disparity estimation as a continuous problem in the image domain, allowing our model to query disparities at arbitrary spatial precision. We carry out comprehensive experiments on a new high-resolution and highly realistic synthetic stereo dataset, consisting of stereo pairs at 8Mpx resolution, as well as on real-world stereo datasets. Our experiments demonstrate increased depth accuracy near object boundaries and prediction of ultra high-resolution disparity maps on standard GPUs. We demonstrate the flexibility of our technique by improving the performance of a variety of stereo backbones.
RayNet: Learning Volumetric 3D Reconstruction with Ray Potentials
Jan 06, 2019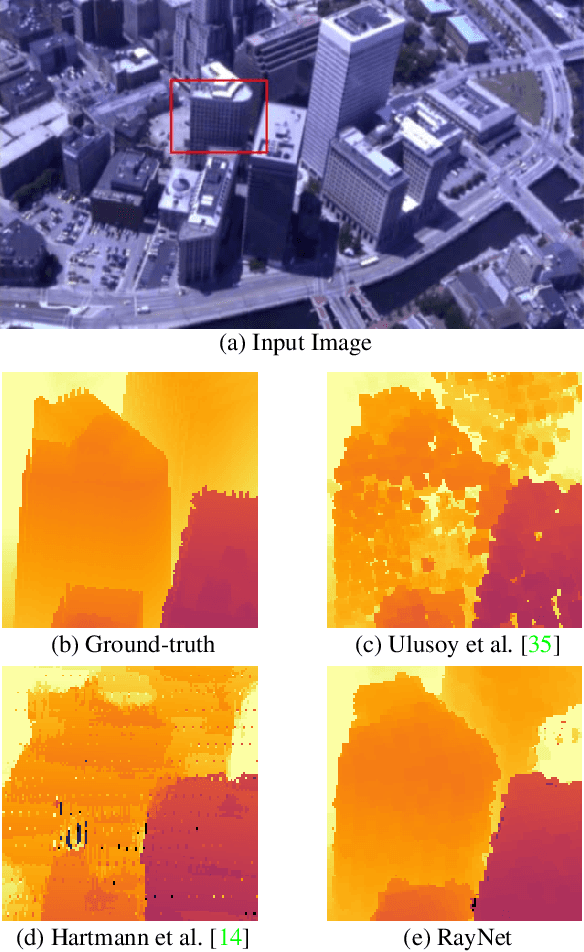
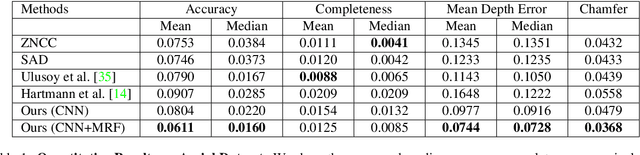
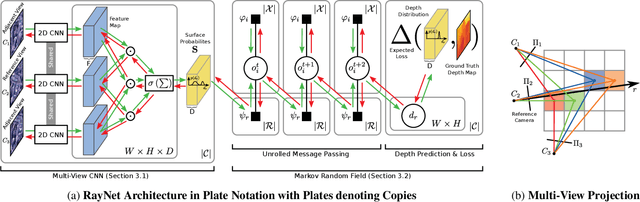
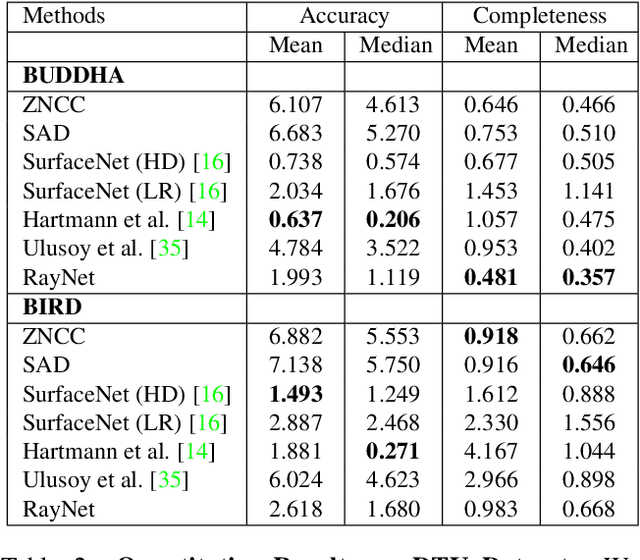
In this paper, we consider the problem of reconstructing a dense 3D model using images captured from different views. Recent methods based on convolutional neural networks (CNN) allow learning the entire task from data. However, they do not incorporate the physics of image formation such as perspective geometry and occlusion. Instead, classical approaches based on Markov Random Fields (MRF) with ray-potentials explicitly model these physical processes, but they cannot cope with large surface appearance variations across different viewpoints. In this paper, we propose RayNet, which combines the strengths of both frameworks. RayNet integrates a CNN that learns view-invariant feature representations with an MRF that explicitly encodes the physics of perspective projection and occlusion. We train RayNet end-to-end using empirical risk minimization. We thoroughly evaluate our approach on challenging real-world datasets and demonstrate its benefits over a piece-wise trained baseline, hand-crafted models as well as other learning-based approaches.