 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Accuracy: Behavioral Testing of NLP models with CheckList
May 08, 2020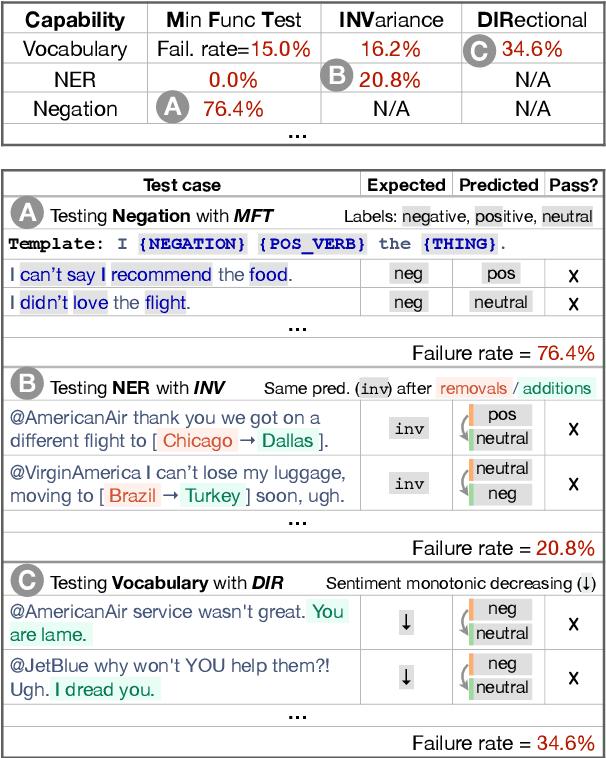
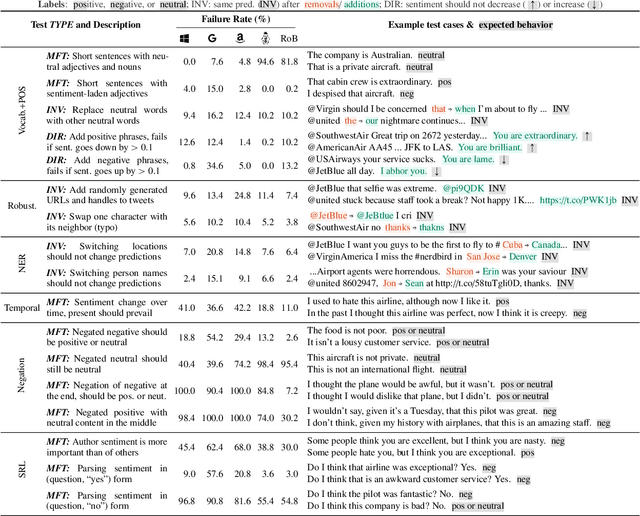
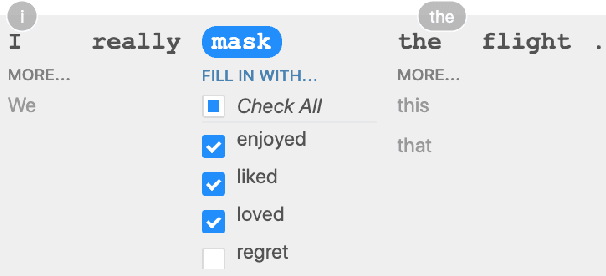
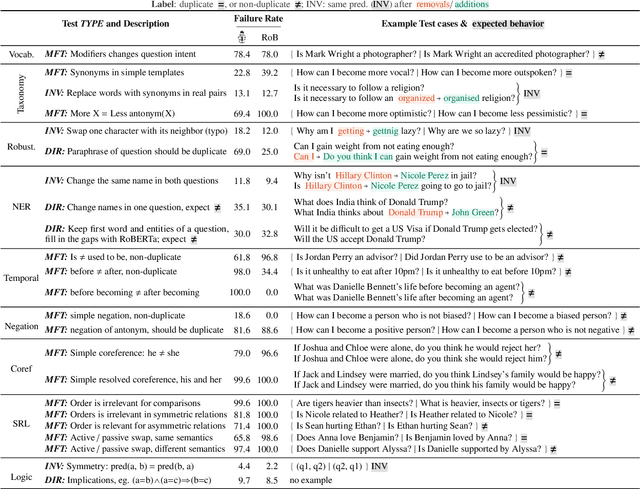
Although measuring held-out accuracy has been the primary approach to evaluate generalization, it often overestimates the performance of NLP models, while alternative approaches for evaluating models either focus on individual tasks or on specific behaviors. Inspired by principles of behavioral testing in software engineering, we introduce CheckList, a task-agnostic methodology for testing NLP models. CheckList includes a matrix of general linguistic capabilities and test types that facilitate comprehensive test ideation, as well as a software tool to generate a large and diverse number of test cases quickly. We illustrate the utility of CheckList with tests for three tasks, identifying critical failures in both commercial and state-of-art models. In a user study, a team responsible for a commercial sentiment analysis model found new and actionable bugs in an extensively tested model. In another user study, NLP practitioners with CheckList created twice as many tests, and found almost three times as many bugs as users without it.
Adversarial Fisher Vectors for Unsupervised Representation Learning
Oct 29, 2019
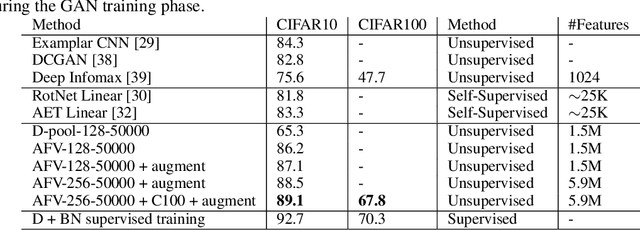
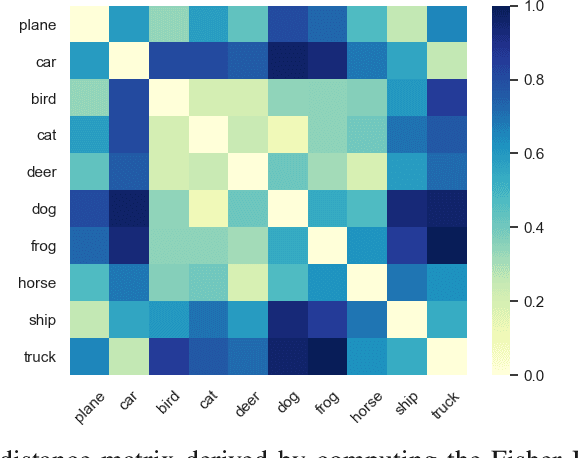
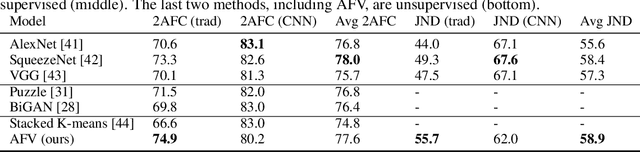
We examine Generative Adversarial Networks (GANs) through the lens of deep Energy Based Models (EBMs), with the goal of exploiting the density model that follows from this formulation. In contrast to a traditional view where the discriminator learns a constant function when reaching convergence, here we show that it can provide useful information for downstream tasks, e.g., feature extraction for classification. To be concrete, in the EBM formulation, the discriminator learns an unnormalized density function (i.e., the negative energy term) that characterizes the data manifold. We propose to evaluate both the generator and the discriminator by deriving corresponding Fisher Score and Fisher Information from the EBM. We show that by assuming that the generated examples form an estimate of the learned density, both the Fisher Information and the normalized Fisher Vectors are easy to compute. We also show that we are able to derive a distance metric between examples and between sets of examples. We conduct experiments showing that the GAN-induced Fisher Vectors demonstrate competitive performance as unsupervised feature extractors for classification and perceptual similarity tasks. Code is available at \url{https://github.com/apple/ml-afv}.
Addressing the Loss-Metric Mismatch with Adaptive Loss Alignment
May 15, 2019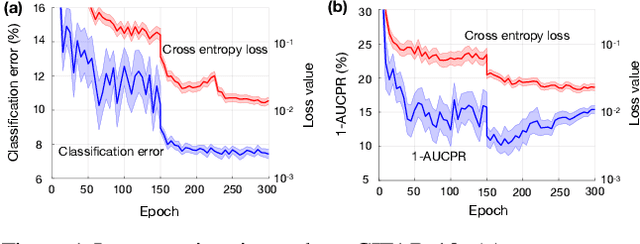
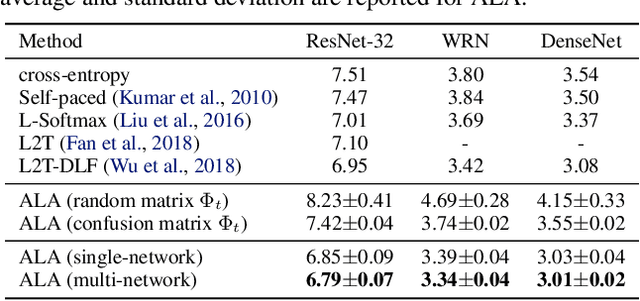
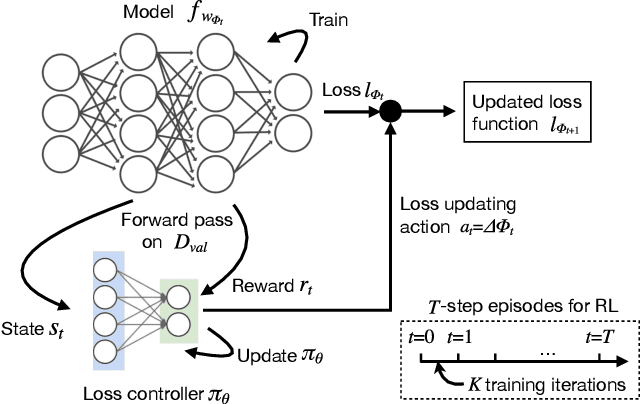

In most machine learning training paradigms a fixed, often handcrafted, loss function is assumed to be a good proxy for an underlying evaluation metric. In this work we assess this assumption by meta-learning an adaptive loss function to directly optimize the evaluation metric. We propose a sample efficient reinforcement learning approach for adapting the loss dynamically during training. We empirically show how this formulation improves performance by simultaneously optimizing the evaluation metric and smoothing the loss landscape. We verify our method in metric learning and classification scenarios, showing considerable improvements over the state-of-the-art on a diverse set of tasks. Importantly, our method is applicable to a wide range of loss functions and evaluation metrics. Furthermore, the learned policies are transferable across tasks and data, demonstrating the versatility of the method.
Learning to Optimize Tensor Programs
Oct 27, 2018

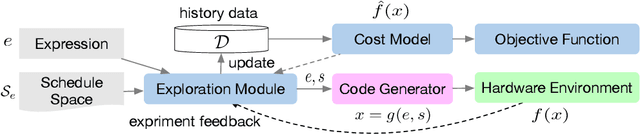

We introduce a learning-based framework to optimize tensor programs for deep learning workloads. Efficient implementations of tensor operators, such as matrix multiplication and high dimensional convolution, are key enablers of effective deep learning systems. However, existing systems rely on manually optimized libraries such as cuDNN where only a narrow range of server class GPUs are well-supported. The reliance on hardware-specific operator libraries limits the applicability of high-level graph optimizations and incurs significant engineering costs when deploying to new hardware targets. We use learning to remove this engineering burden. We learn domain-specific statistical cost models to guide the search of tensor operator implementations over billions of possible program variants. We further accelerate the search by effective model transfer across workloads. Experimental results show that our framework delivers performance competitive with state-of-the-art hand-tuned libraries for low-power CPU, mobile GPU, and server-class GPU.
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
Oct 05, 2018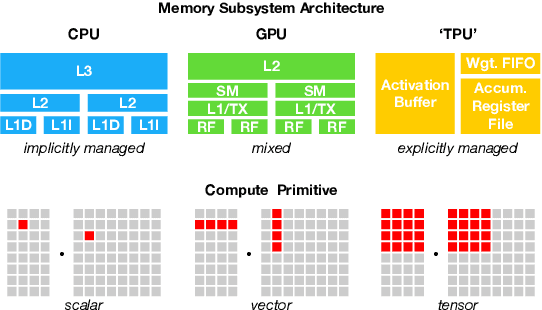
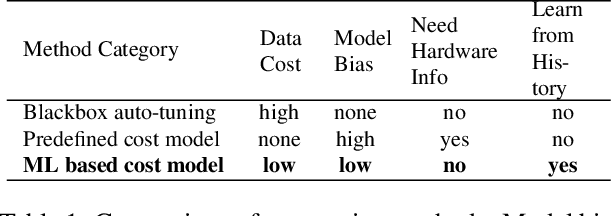
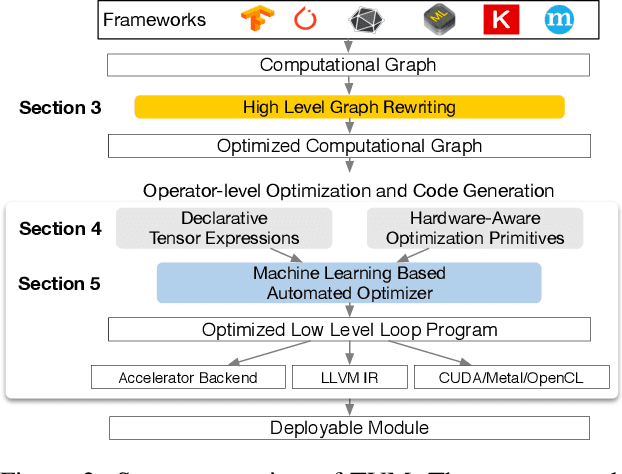
There is an increasing need to bring machine learning to a wide diversity of hardware devices. Current frameworks rely on vendor-specific operator libraries and optimize for a narrow range of server-class GPUs. Deploying workloads to new platforms -- such as mobile phones, embedded devices, and accelerators (e.g., FPGAs, ASICs) -- requires significant manual effort. We propose TVM, a compiler that exposes graph-level and operator-level optimizations to provide performance portability to deep learning workloads across diverse hardware back-ends. TVM solves optimization challenges specific to deep learning, such as high-level operator fusion, mapping to arbitrary hardware primitives, and memory latency hiding. It also automates optimization of low-level programs to hardware characteristics by employing a novel, learning-based cost modeling method for rapid exploration of code optimizations. Experimental results show that TVM delivers performance across hardware back-ends that are competitive with state-of-the-art, hand-tuned libraries for low-power CPU, mobile GPU, and server-class GPUs. We also demonstrate TVM's ability to target new accelerator back-ends, such as the FPGA-based generic deep learning accelerator. The system is open sourced and in production use inside several major companies.
A Fast, Principled Working Set Algorithm for Exploiting Piecewise Linear Structure in Convex Problems
Jul 20, 2018


By reducing optimization to a sequence of smaller subproblems, working set algorithms achieve fast convergence times for many machine learning problems. Despite such performance, working set implementations often resort to heuristics to determine subproblem size, makeup, and stopping criteria. We propose BlitzWS, a working set algorithm with useful theoretical guarantees. Our theory relates subproblem size and stopping criteria to the amount of progress during each iteration. This result motivates strategies for optimizing algorithmic parameters and discarding irrelevant components as BlitzWS progresses toward a solution. BlitzWS applies to many convex problems, including training L1-regularized models and support vector machines. We showcase this versatility with empirical comparisons, which demonstrate BlitzWS is indeed a fast algorithm.
VTA: An Open Hardware-Software Stack for Deep Learning
Jul 11, 2018
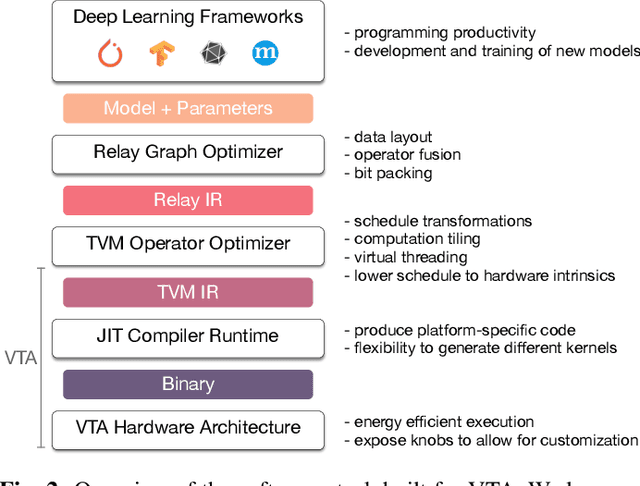
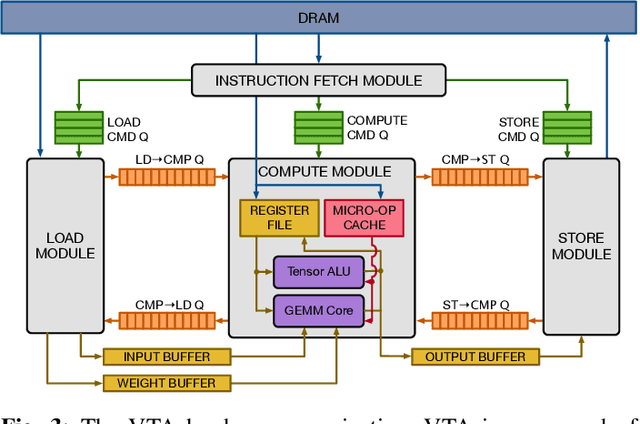
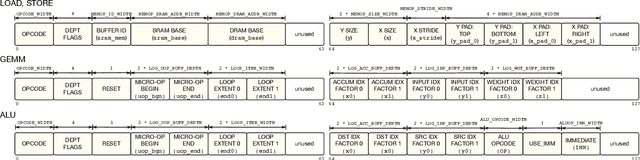
Hardware acceleration is an enabler for ubiquitous and efficient deep learning. With hardware accelerators being introduced in datacenter and edge devices, it is time to acknowledge that hardware specialization is central to the deep learning system stack. This technical report presents the Versatile Tensor Accelerator (VTA), an open, generic, and customizable deep learning accelerator design. VTA is a programmable accelerator that exposes a RISC-like programming abstraction to describe operations at the tensor level. We designed VTA to expose the most salient and common characteristics of mainstream deep learning accelerators, such as tensor operations, DMA load/stores, and explicit compute/memory arbitration. VTA is more than a standalone accelerator design: it's an end-to-end solution that includes drivers, a JIT runtime, and an optimizing compiler stack based on TVM. The current release of VTA includes a behavioral hardware simulator, as well as the infrastructure to deploy VTA on low-cost FPGA development boards for fast prototyping. By extending the TVM stack with a customizable, and open source deep learning hardware accelerator design, we are exposing a transparent end-to-end deep learning stack from the high-level deep learning framework, down to the actual hardware design and implementation. This forms a truly end-to-end, from software-to-hardware open source stack for deep learning systems.
Compact Factorization of Matrices Using Generalized Round-Rank
May 01, 2018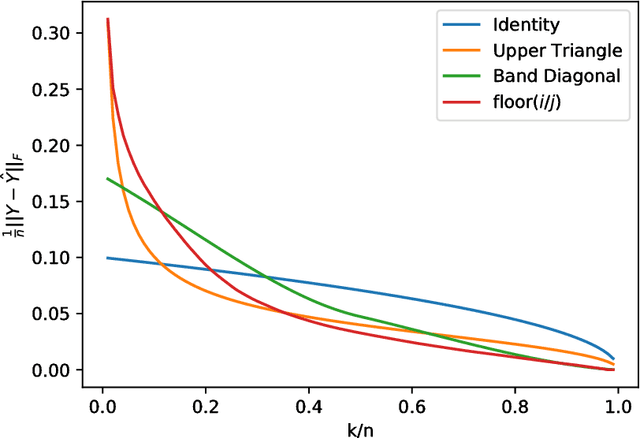
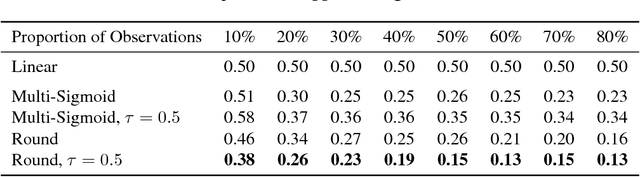
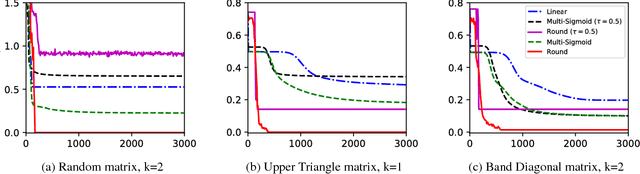
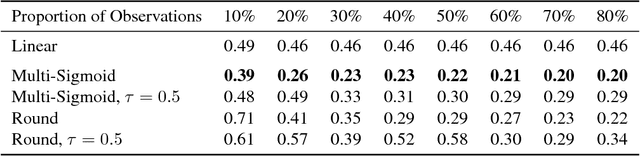
Matrix factorization is a well-studied task in machine learning for compactly representing large, noisy data. In our approach, instead of using the traditional concept of matrix rank, we define a new notion of link-rank based on a non-linear link function used within factorization. In particular, by applying the round function on a factorization to obtain ordinal-valued matrices, we introduce generalized round-rank (GRR). We show that not only are there many full-rank matrices that are low GRR, but further, that these matrices cannot be approximated well by low-rank linear factorization. We provide uniqueness conditions of this formulation and provide gradient descent-based algorithms. Finally, we present experiments on real-world datasets to demonstrate that the GRR-based factorization is significantly more accurate than linear factorization, while converging faster and using lower rank representations.
Programs as Black-Box Explanations
Nov 22, 2016
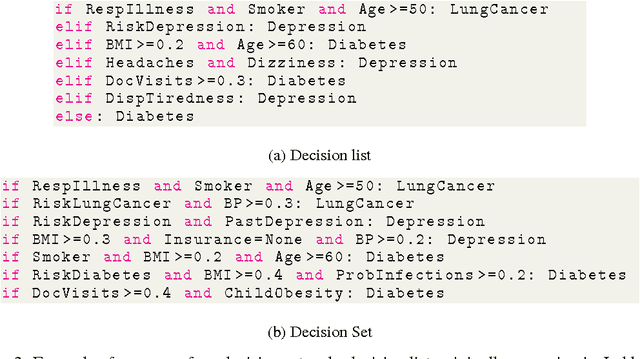
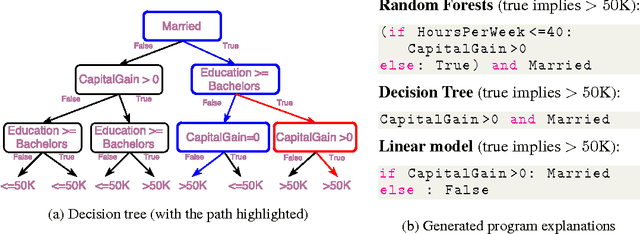
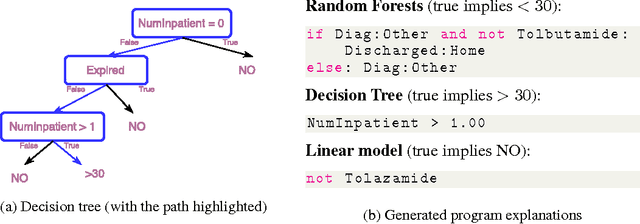
Recent work in model-agnostic explanations of black-box machine learning has demonstrated that interpretability of complex models does not have to come at the cost of accuracy or model flexibility. However, it is not clear what kind of explanations, such as linear models, decision trees, and rule lists, are the appropriate family to consider, and different tasks and models may benefit from different kinds of explanations. Instead of picking a single family of representations, in this work we propose to use "programs" as model-agnostic explanations. We show that small programs can be expressive yet intuitive as explanations, and generalize over a number of existing interpretable families. We propose a prototype program induction method based on simulated annealing that approximates the local behavior of black-box classifiers around a specific prediction using random perturbations. Finally, we present preliminary application on small datasets and show that the generated explanations are intuitive and accurate for a number of classifiers.
Nothing Else Matters: Model-Agnostic Explanations By Identifying Prediction Invariance
Nov 17, 2016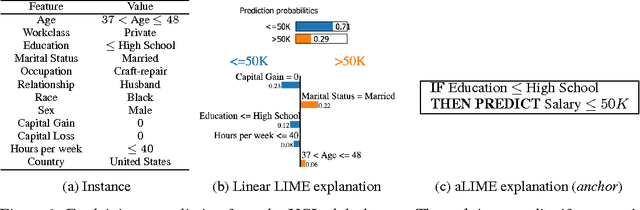

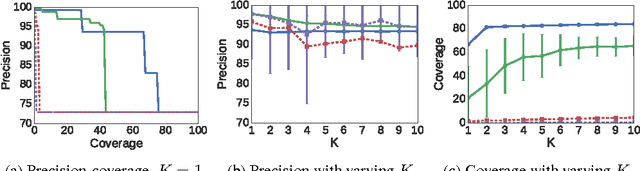

At the core of interpretable machine learning is the question of whether humans are able to make accurate predictions about a model's behavior. Assumed in this question are three properties of the interpretable output: coverage, precision, and effort. Coverage refers to how often humans think they can predict the model's behavior, precision to how accurate humans are in those predictions, and effort is either the up-front effort required in interpreting the model, or the effort required to make predictions about a model's behavior. In this work, we propose anchor-LIME (aLIME), a model-agnostic technique that produces high-precision rule-based explanations for which the coverage boundaries are very clear. We compare aLIME to linear LIME with simulated experiments, and demonstrate the flexibility of aLIME with qualitative examples from a variety of domains and tasks.