 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Networks as Point Estimates for Deep Gaussian Processes
May 10, 2021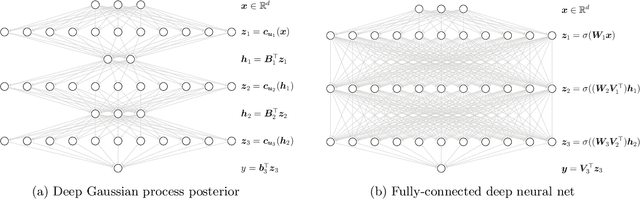
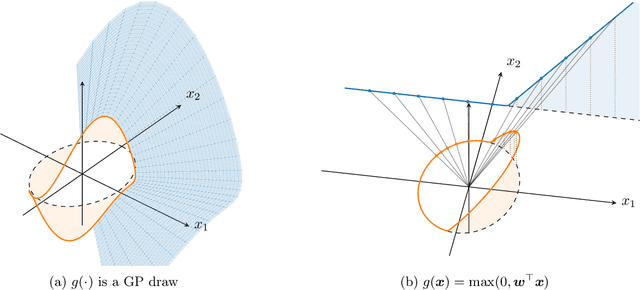
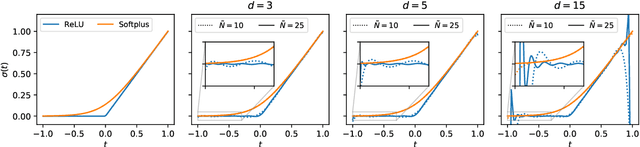
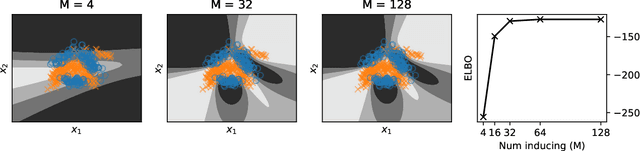
Deep Gaussian processes (DGPs) have struggled for relevance in applications due to the challenges and cost associated with Bayesian inference. In this paper we propose a sparse variational approximation for DGPs for which the approximate posterior mean has the same mathematical structure as a Deep Neural Network (DNN). We make the forward pass through a DGP equivalent to a ReLU DNN by finding an interdomain transformation that represents the GP posterior mean as a sum of ReLU basis functions. This unification enables the initialisation and training of the DGP as a neural network, leveraging the well established practice in the deep learning community, and so greatly aiding the inference task. The experiments demonstrate improved accuracy and faster training compared to current DGP methods, while retaining favourable predictive uncertainties.
Black-box density function estimation using recursive partitioning
Oct 26, 2020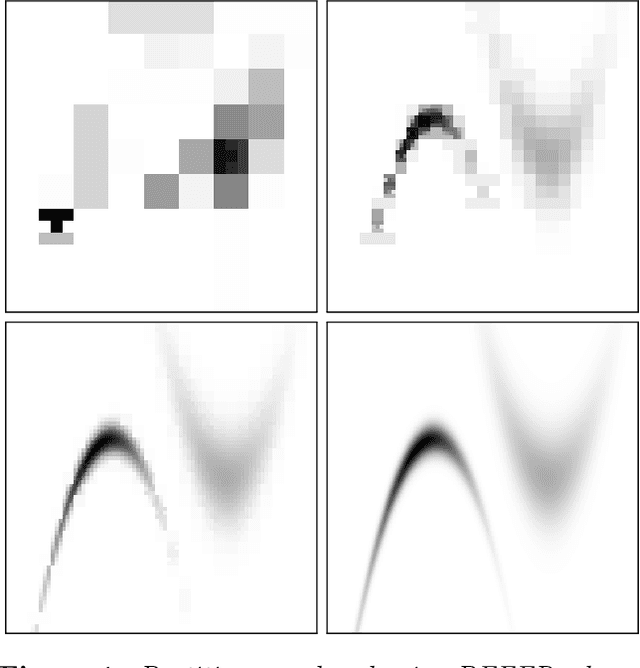
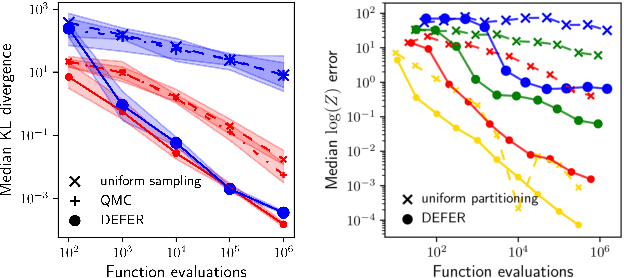
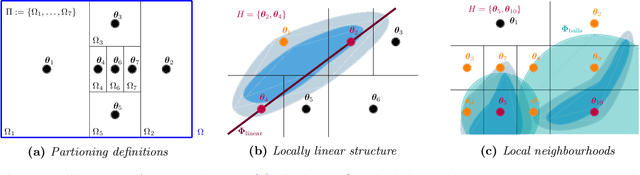

We present a novel approach to Bayesian inference and general Bayesian computation that is defined through a recursive partitioning of the sample space. It does not rely on gradients, nor require any problem-specific tuning, and is asymptotically exact for any density function with a bounded domain. The output is an approximation to the whole density function including the normalization constant, via partitions organized in efficient data structures. This allows for evidence estimation, as well as approximate posteriors that allow for fast sampling and fast evaluations of the density. It shows competitive performance to recent state-of-the-art methods on synthetic and real-world problem examples including parameter inference for gravitational-wave physics.
Bayesian nonparametric shared multi-sequence time series segmentation
Jan 27, 2020
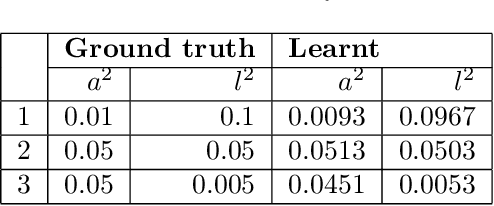
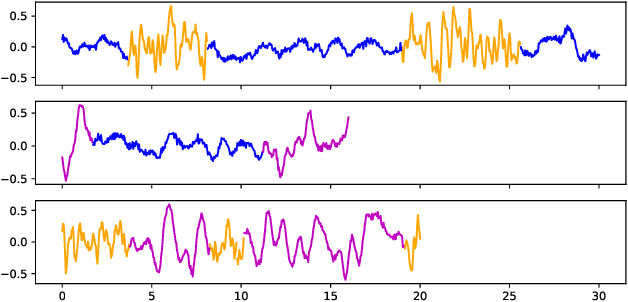
In this paper, we introduce a method for segmenting time series data using tools from Bayesian nonparametrics. We consider the task of temporal segmentation of a set of time series data into representative stationary segments. We use Gaussian process (GP) priors to impose our knowledge about the characteristics of the underlying stationary segments, and use a nonparametric distribution to partition the sequences into such segments, formulated in terms of a prior distribution on segment length. Given the segmentation, the model can be viewed as a variant of a Gaussian mixture model where the mixture components are described using the covariance function of a GP. We demonstrate the effectiveness of our model on synthetic data as well as on real time-series data of heartbeats where the task is to segment the indicative types of beats and to classify the heartbeat recordings into classes that correspond to healthy and abnormal heart sounds.
Compositional uncertainty in deep Gaussian processes
Sep 17, 2019
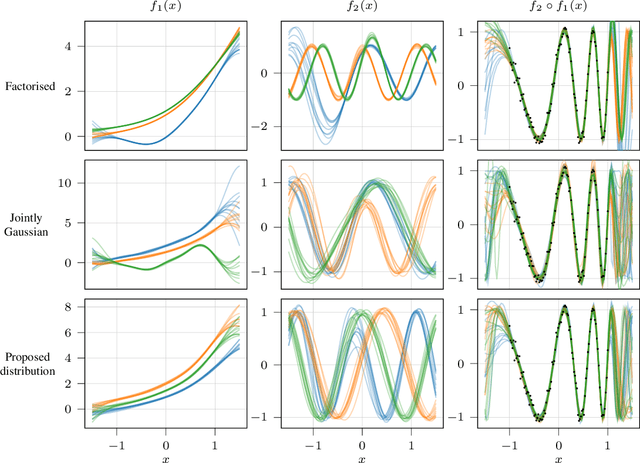
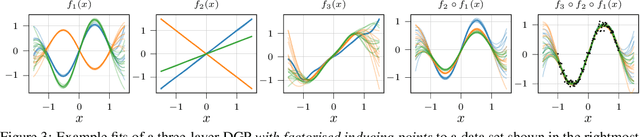
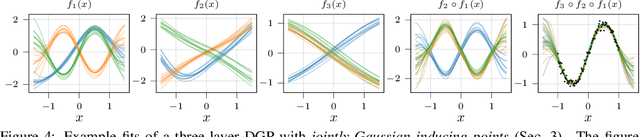
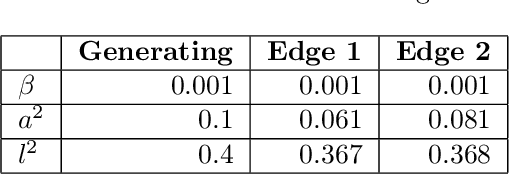
Gaussian processes (GPs) are nonparametric priors over functions, and fitting a GP to the data implies computing the posterior distribution of the functions consistent with the observed data. Similarly, deep Gaussian processes (DGPs) [Damianou:2013] should allow us to compute the posterior distribution of compositions of multiple functions giving rise to the observations. However, exact Bayesian inference is usually intractable for DGPs, motivating the use of various approximations. We show that the simplifying assumptions for a common type of Variational inference approximation imply that all but one layer of a DGP collapse to a deterministic transformation. We argue that such an inference scheme is suboptimal, not taking advantage of the potential of the model to discover the compositional structure in the data, and propose possible modifications addressing this issue.
Interpretable Dynamics Models for Data-Efficient Reinforcement Learning
Jul 10, 2019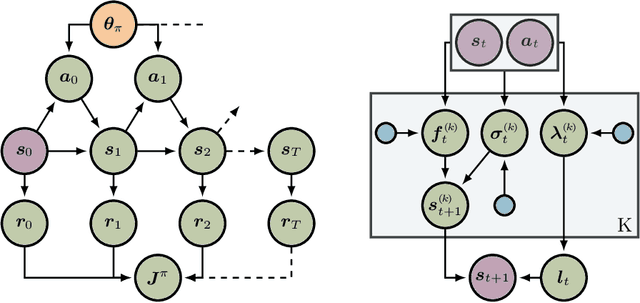
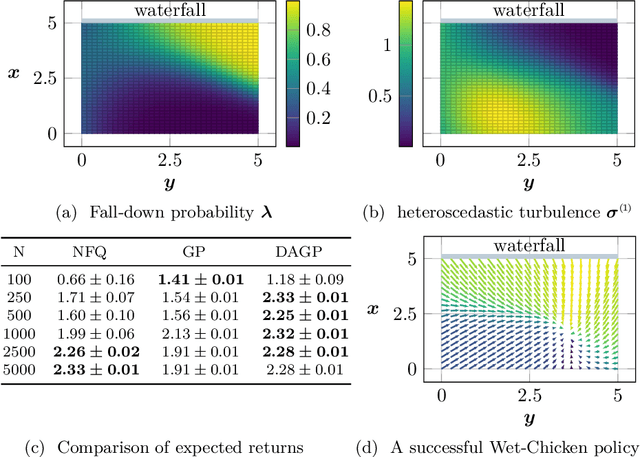
In this paper, we present a Bayesian view on model-based reinforcement learning. We use expert knowledge to impose structure on the transition model and present an efficient learning scheme based on variational inference. This scheme is applied to a heteroskedastic and bimodal benchmark problem on which we compare our results to NFQ and show how our approach yields human-interpretable insight about the underlying dynamics while also increasing data-efficiency.
Modulated Bayesian Optimization using Latent Gaussian Process Models
Jun 26, 2019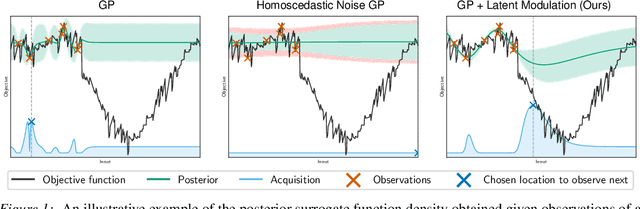
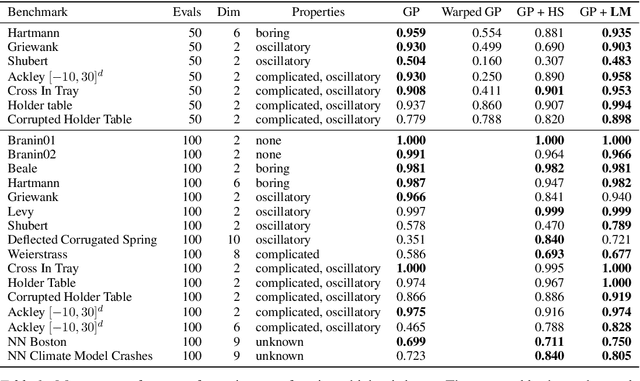
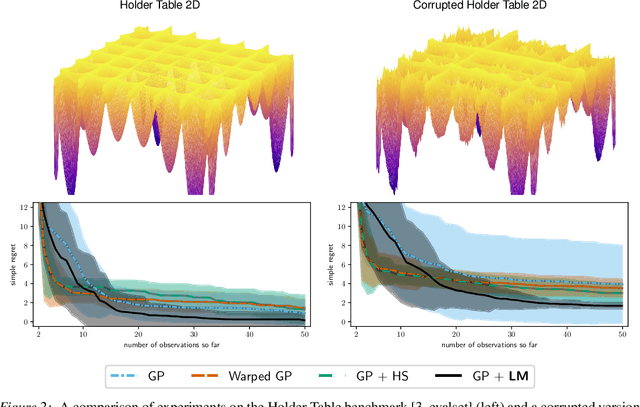
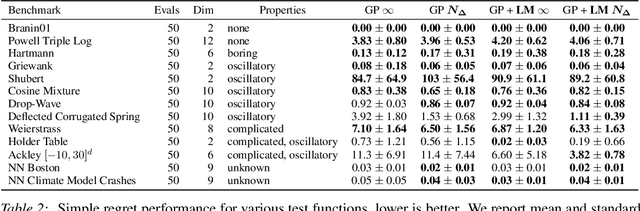
We present an approach to Bayesian Optimization that allows for robust search strategies over a large class of challenging functions. Our method is motivated by the belief that the trends useful to exploit in search of the optimum typically are a subset of the characteristics of the true objective function. At the core of our approach is the use of a Latent Gaussian Process Regression model that allows us to modulate the input domain with an orthogonal latent space. Using this latent space we can encapsulate local information about each observed data point that can be used to guide the search problem. We show experimentally that our method can be used to significantly improve performance on challenging benchmarks.
Monotonic Gaussian Process Flow
May 30, 2019

We propose a new framework of imposing monotonicity constraints in a Bayesian non-parametric setting. Our approach is based on numerical solutions of stochastic differential equations [Hedge, 2019]. We derive a non-parametric model of monotonic functions that allows for interpretable priors and principled quantification of hierarchical uncertainty. We demonstrate the efficacy of the proposed model by providing competitive results to other probabilistic models of monotonic functions on a number of benchmark functions. In addition, we consider the utility of a monotonic constraint in hierarchical probabilistic models, such as deep Gaussian processes. These typically suffer difficulties in modelling and propagating uncertainties throughout the hierarchy that can lead to hidden layers collapsing to point estimates. We address this by constraining hidden layers to be monotonic and present novel procedures for learning and inference that maintain uncertainty. We illustrate the capacity and versatility of the proposed framework on the task of temporal alignment of time-series data where it is beneficial to preserve the uncertainty in the temporal warpings.
Invariant Feature Mappings for Generalizing Affordance Understanding Using Regularized Metric Learning
Jan 30, 2019
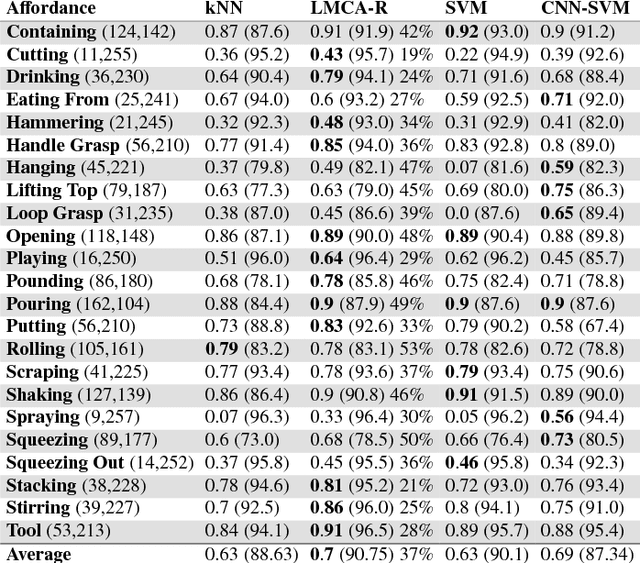
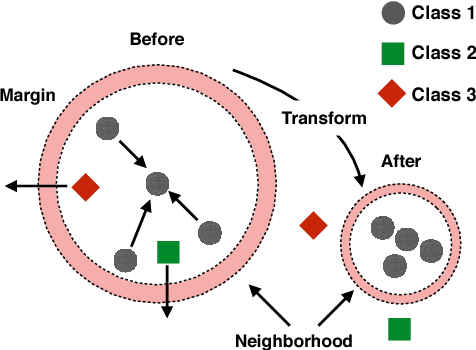
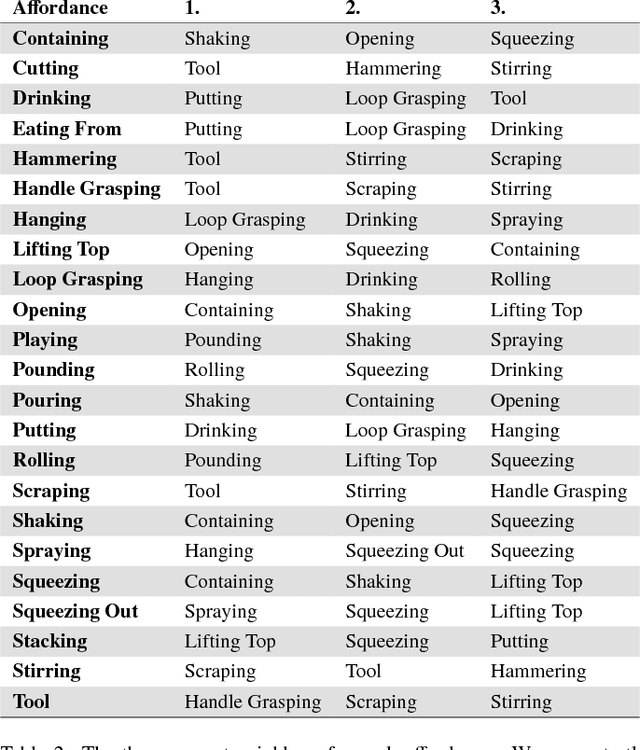
This paper presents an approach for learning invariant features for object affordance understanding. One of the major problems for a robotic agent acquiring a deeper understanding of affordances is finding sensory-grounded semantics. Being able to understand what in the representation of an object makes the object afford an action opens up for more efficient manipulation, interchange of objects that visually might not be similar, transfer learning, and robot to human communication. Our approach uses a metric learning algorithm that learns a feature transform that encourages objects that affords the same action to be close in the feature space. We regularize the learning, such that we penalize irrelevant features, allowing the agent to link what in the sensory input caused the object to afford the action. From this, we show how the agent can abstract the affordance and reason about the similarity between different affordances.
Gaussian Process Deep Belief Networks: A Smooth Generative Model of Shape with Uncertainty Propagation
Dec 13, 2018
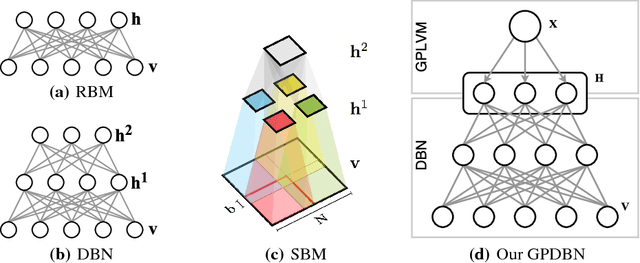
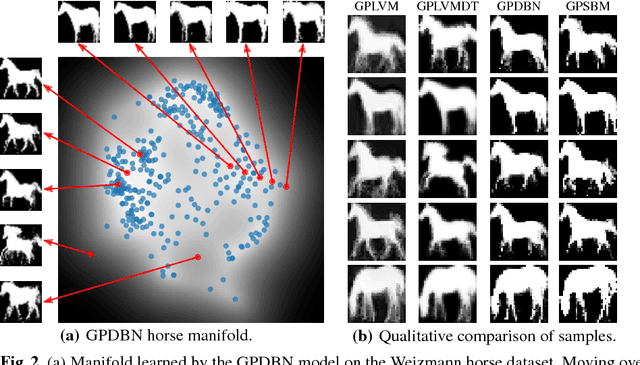

The shape of an object is an important characteristic for many vision problems such as segmentation, detection and tracking. Being independent of appearance, it is possible to generalize to a large range of objects from only small amounts of data. However, shapes represented as silhouette images are challenging to model due to complicated likelihood functions leading to intractable posteriors. In this paper we present a generative model of shapes which provides a low dimensional latent encoding which importantly resides on a smooth manifold with respect to the silhouette images. The proposed model propagates uncertainty in a principled manner allowing it to learn from small amounts of data and providing predictions with associated uncertainty. We provide experiments that show how our proposed model provides favorable quantitative results compared with the state-of-the-art while simultaneously providing a representation that resides on a low-dimensional interpretable manifold.
Sequence Alignment with Dirichlet Process Mixtures
Nov 26, 2018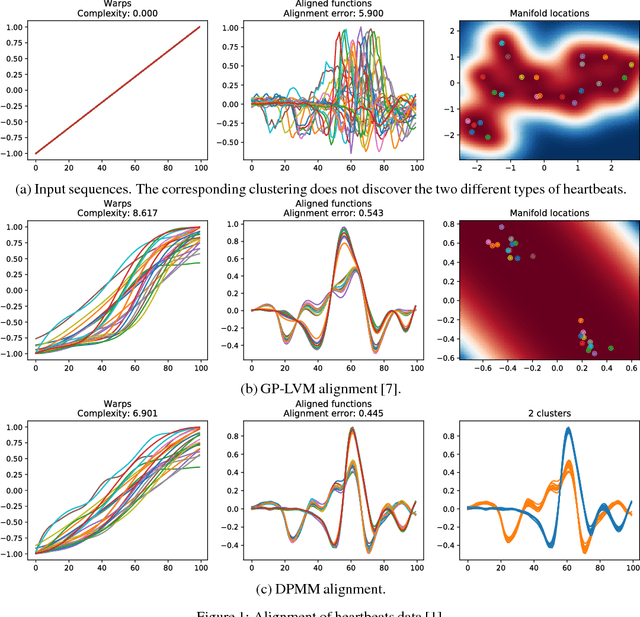
We present a probabilistic model for unsupervised alignment of high-dimensional time-warped sequences based on the Dirichlet Process Mixture Model (DPMM). We follow the approach introduced in (Kazlauskaite, 2018) of simultaneously representing each data sequence as a composition of a true underlying function and a time-warping, both of which are modelled using Gaussian processes (GPs) (Rasmussen, 2005), and aligning the underlying functions using an unsupervised alignment method. In (Kazlauskaite, 2018) the alignment is performed using the GP latent variable model (GP-LVM) (Lawrence, 2005) as a model of sequences, while our main contribution is extending this approach to using DPMM, which allows us to align the sequences temporally and cluster them at the same time. We show that the DPMM achieves competitive results in comparison to the GP-LVM on synthetic and real-world data sets, and discuss the different properties of the estimated underlying functions and the time-warps favoured by these models.