 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan You Make It Sound Like You? Post-Editing LLM-Generated Text for Personal Style
Apr 27, 2026Despite the growing use of large language models (LLMs) for writing tasks, users may hesitate to rely on LLMs when personal style is important. Post-editing LLM-generated drafts or translations is a common collaborative writing strategy, but it remains unclear whether users can effectively reshape LLM-generated text to reflect their personal style. We conduct a pre-registered online study ($n=81$) in which participants post-edit LLM-generated drafts for writing tasks where personal style matters to them. Using embedding-based style similarity metrics, we find that post-editing increases stylistic similarity to participants' unassisted writing and reduces similarity to fully LLM-generated output. However, post-edited text still remains stylistically closer in style to LLM text than to participants' unassisted control text, and it exhibits reduced stylistic diversity compared to unassisted human text. We find a gap between perceived stylistic authenticity and model-measured stylistic similarity, with post-edited text often perceived as representative of participants' personal style despite remaining detectable LLM stylistic traces.
Should We be Pedantic About Reasoning Errors in Machine Translation?
Apr 10, 2026Across multiple language pairings (English $\to$ \{Spanish, French, German, Mandarin, Japanese, Urdu, Cantonese\}), we find reasoning errors in translation. To quantify how often these reasoning errors occur, we leverage an automated annotation protocol for reasoning evaluation wherein the goal is to detect if a reasoning step is any of three error categories: (1) source sentence-misaligned, (2) model hypothesis-misaligned, or (3) reasoning trace-misaligned. We probe the reasoning model with perturbed traces correcting for these identified reasoning errors using an array of weak-to-strong interventions: hedging, removal, re-reasoning after removal, hindsight, and oracle interventions. Experimenting with interventions on the reasoning traces suggests that small corrections to the reasoning have little impact on translation quality, but stronger interventions yield the highest resolution rates, despite translation quality gains being mixed. We find ultimately that reasoning errors in MT can be identified with high precision in Urdu but lower precision in Spanish, but that removing these reasoning errors does not resolve the initial errors significantly, suggesting limited reasoning faithfulness for machine translation.
Keep It Private: Unsupervised Privatization of Online Text
May 16, 2024



Authorship obfuscation techniques hold the promise of helping people protect their privacy in online communications by automatically rewriting text to hide the identity of the original author. However, obfuscation has been evaluated in narrow settings in the NLP literature and has primarily been addressed with superficial edit operations that can lead to unnatural outputs. In this work, we introduce an automatic text privatization framework that fine-tunes a large language model via reinforcement learning to produce rewrites that balance soundness, sense, and privacy. We evaluate it extensively on a large-scale test set of English Reddit posts by 68k authors composed of short-medium length texts. We study how the performance changes among evaluative conditions including authorial profile length and authorship detection strategy. Our method maintains high text quality according to both automated metrics and human evaluation, and successfully evades several automated authorship attacks.
Guided Hyperparameter Tuning Through Visualization and Inference
May 24, 2021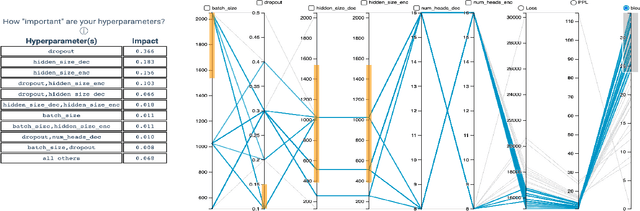
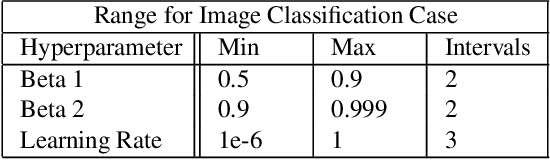
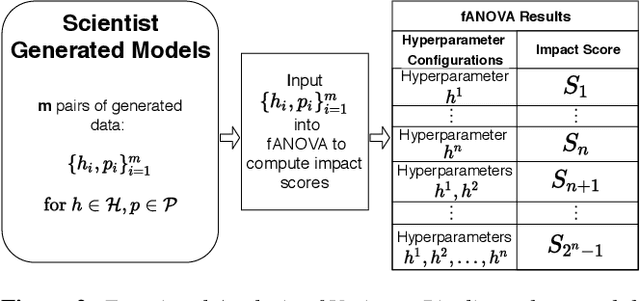
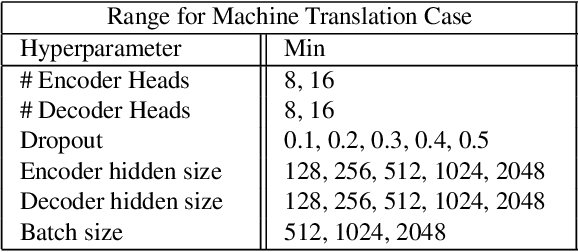
For deep learning practitioners, hyperparameter tuning for optimizing model performance can be a computationally expensive task. Though visualization can help practitioners relate hyperparameter settings to overall model performance, significant manual inspection is still required to guide the hyperparameter settings in the next batch of experiments. In response, we present a streamlined visualization system enabling deep learning practitioners to more efficiently explore, tune, and optimize hyperparameters in a batch of experiments. A key idea is to directly suggest more optimal hyperparameter values using a predictive mechanism. We then integrate this mechanism with current visualization practices for deep learning. Moreover, an analysis on the variance in a selected performance metric in the context of the model hyperparameters shows the impact that certain hyperparameters have on the performance metric. We evaluate the tool with a user study on deep learning model builders, finding that our participants have little issue adopting the tool and working with it as part of their workflow.