 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCueCAn: Cue Driven Contextual Attention For Identifying Missing Traffic Signs on Unconstrained Roads
Mar 05, 2023



Unconstrained Asian roads often involve poor infrastructure, affecting overall road safety. Missing traffic signs are a regular part of such roads. Missing or non-existing object detection has been studied for locating missing curbs and estimating reasonable regions for pedestrians on road scene images. Such methods involve analyzing task-specific single object cues. In this paper, we present the first and most challenging video dataset for missing objects, with multiple types of traffic signs for which the cues are visible without the signs in the scenes. We refer to it as the Missing Traffic Signs Video Dataset (MTSVD). MTSVD is challenging compared to the previous works in two aspects i) The traffic signs are generally not present in the vicinity of their cues, ii) The traffic signs cues are diverse and unique. Also, MTSVD is the first publicly available missing object dataset. To train the models for identifying missing signs, we complement our dataset with 10K traffic sign tracks, with 40 percent of the traffic signs having cues visible in the scenes. For identifying missing signs, we propose the Cue-driven Contextual Attention units (CueCAn), which we incorporate in our model encoder. We first train the encoder to classify the presence of traffic sign cues and then train the entire segmentation model end-to-end to localize missing traffic signs. Quantitative and qualitative analysis shows that CueCAn significantly improves the performance of base models.
A Fine-Grained Vehicle Detection Dataset for Unconstrained Roads
Dec 30, 2022



The previous fine-grained datasets mainly focus on classification and are often captured in a controlled setup, with the camera focusing on the objects. We introduce the first Fine-Grained Vehicle Detection (FGVD) dataset in the wild, captured from a moving camera mounted on a car. It contains 5502 scene images with 210 unique fine-grained labels of multiple vehicle types organized in a three-level hierarchy. While previous classification datasets also include makes for different kinds of cars, the FGVD dataset introduces new class labels for categorizing two-wheelers, autorickshaws, and trucks. The FGVD dataset is challenging as it has vehicles in complex traffic scenarios with intra-class and inter-class variations in types, scale, pose, occlusion, and lighting conditions. The current object detectors like yolov5 and faster RCNN perform poorly on our dataset due to a lack of hierarchical modeling. Along with providing baseline results for existing object detectors on FGVD Dataset, we also present the results of a combination of an existing detector and the recent Hierarchical Residual Network (HRN) classifier for the FGVD task. Finally, we show that FGVD vehicle images are the most challenging to classify among the fine-grained datasets.
Towards Robust Handwritten Text Recognition with On-the-fly User Participation
Dec 17, 2022Long-term OCR services aim to provide high-quality output to their users at competitive costs. It is essential to upgrade the models because of the complex data loaded by the users. The service providers encourage the users who provide data where the OCR model fails by rewarding them based on data complexity, readability, and available budget. Hitherto, the OCR works include preparing the models on standard datasets without considering the end-users. We propose a strategy of consistently upgrading an existing Handwritten Hindi OCR model three times on the dataset of 15 users. We fix the budget of 4 users for each iteration. For the first iteration, the model directly trains on the dataset from the first four users. For the rest iteration, all remaining users write a page each, which service providers later analyze to select the 4 (new) best users based on the quality of predictions on the human-readable words. Selected users write 23 more pages for upgrading the model. We upgrade the model with Curriculum Learning (CL) on the data available in the current iteration and compare the subset from previous iterations. The upgraded model is tested on a held-out set of one page each from all 23 users. We provide insights into our investigations on the effect of CL, user selection, and especially the data from unseen writing styles. Our work can be used for long-term OCR services in crowd-sourcing scenarios for the service providers and end users.
Enhancing Indic Handwritten Text Recognition Using Global Semantic Information
Dec 15, 2022Handwritten Text Recognition (HTR) is more interesting and challenging than printed text due to uneven variations in the handwriting style of the writers, content, and time. HTR becomes more challenging for the Indic languages because of (i) multiple characters combined to form conjuncts which increase the number of characters of respective languages, and (ii) near to 100 unique basic Unicode characters in each Indic script. Recently, many recognition methods based on the encoder-decoder framework have been proposed to handle such problems. They still face many challenges, such as image blur and incomplete characters due to varying writing styles and ink density. We argue that most encoder-decoder methods are based on local visual features without explicit global semantic information. In this work, we enhance the performance of Indic handwritten text recognizers using global semantic information. We use a semantic module in an encoder-decoder framework for extracting global semantic information to recognize the Indic handwritten texts. The semantic information is used in both the encoder for supervision and the decoder for initialization. The semantic information is predicted from the word embedding of a pre-trained language model. Extensive experiments demonstrate that the proposed framework achieves state-of-the-art results on handwritten texts of ten Indic languages.
Information Retrieval from the Digitized Books
Dec 02, 2022



Extracting the relevant information out of a large number of documents is a challenging and tedious task. The quality of results generated by the traditionally available full-text search engine and text-based image retrieval systems is not optimal. Information retrieval (IR) tasks become more challenging with the nontraditional language scripts, as in the case of Indic scripts. The authors have developed OCR (Optical Character Recognition) Search Engine to make an Information Retrieval & Extraction (IRE) system that replicates the current state-of-the-art methods using the IRE and Natural Language Processing (NLP) techniques. Here we have presented the study of the methods used for performing search and retrieval tasks. The details of this system, along with the statistics of the dataset (source: National Digital Library of India or NDLI), is also presented. Additionally, the ideas to further explore and add value to research in IRE are also discussed.
Watching the News: Towards VideoQA Models that can Read
Nov 10, 2022



Video Question Answering methods focus on commonsense reasoning and visual cognition of objects or persons and their interactions over time. Current VideoQA approaches ignore the textual information present in the video. Instead, we argue that textual information is complementary to the action and provides essential contextualisation cues to the reasoning process. To this end, we propose a novel VideoQA task that requires reading and understanding the text in the video. To explore this direction, we focus on news videos and require QA systems to comprehend and answer questions about the topics presented by combining visual and textual cues in the video. We introduce the ``NewsVideoQA'' dataset that comprises more than $8,600$ QA pairs on $3,000+$ news videos obtained from diverse news channels from around the world. We demonstrate the limitations of current Scene Text VQA and VideoQA methods and propose ways to incorporate scene text information into VideoQA methods.
INR-V: A Continuous Representation Space for Video-based Generative Tasks
Oct 29, 2022



Generating videos is a complex task that is accomplished by generating a set of temporally coherent images frame-by-frame. This limits the expressivity of videos to only image-based operations on the individual video frames needing network designs to obtain temporally coherent trajectories in the underlying image space. We propose INR-V, a video representation network that learns a continuous space for video-based generative tasks. INR-V parameterizes videos using implicit neural representations (INRs), a multi-layered perceptron that predicts an RGB value for each input pixel location of the video. The INR is predicted using a meta-network which is a hypernetwork trained on neural representations of multiple video instances. Later, the meta-network can be sampled to generate diverse novel videos enabling many downstream video-based generative tasks. Interestingly, we find that conditional regularization and progressive weight initialization play a crucial role in obtaining INR-V. The representation space learned by INR-V is more expressive than an image space showcasing many interesting properties not possible with the existing works. For instance, INR-V can smoothly interpolate intermediate videos between known video instances (such as intermediate identities, expressions, and poses in face videos). It can also in-paint missing portions in videos to recover temporally coherent full videos. In this work, we evaluate the space learned by INR-V on diverse generative tasks such as video interpolation, novel video generation, video inversion, and video inpainting against the existing baselines. INR-V significantly outperforms the baselines on several of these demonstrated tasks, clearly showcasing the potential of the proposed representation space.
Unsupervised Audio-Visual Lecture Segmentation
Oct 29, 2022



Over the last decade, online lecture videos have become increasingly popular and have experienced a meteoric rise during the pandemic. However, video-language research has primarily focused on instructional videos or movies, and tools to help students navigate the growing online lectures are lacking. Our first contribution is to facilitate research in the educational domain, by introducing AVLectures, a large-scale dataset consisting of 86 courses with over 2,350 lectures covering various STEM subjects. Each course contains video lectures, transcripts, OCR outputs for lecture frames, and optionally lecture notes, slides, assignments, and related educational content that can inspire a variety of tasks. Our second contribution is introducing video lecture segmentation that splits lectures into bite-sized topics that show promise in improving learner engagement. We formulate lecture segmentation as an unsupervised task that leverages visual, textual, and OCR cues from the lecture, while clip representations are fine-tuned on a pretext self-supervised task of matching the narration with the temporally aligned visual content. We use these representations to generate segments using a temporally consistent 1-nearest neighbor algorithm, TW-FINCH. We evaluate our method on 15 courses and compare it against various visual and textual baselines, outperforming all of them. Our comprehensive ablation studies also identify the key factors driving the success of our approach.
IDD-3D: Indian Driving Dataset for 3D Unstructured Road Scenes
Oct 23, 2022



Autonomous driving and assistance systems rely on annotated data from traffic and road scenarios to model and learn the various object relations in complex real-world scenarios. Preparation and training of deploy-able deep learning architectures require the models to be suited to different traffic scenarios and adapt to different situations. Currently, existing datasets, while large-scale, lack such diversities and are geographically biased towards mainly developed cities. An unstructured and complex driving layout found in several developing countries such as India poses a challenge to these models due to the sheer degree of variations in the object types, densities, and locations. To facilitate better research toward accommodating such scenarios, we build a new dataset, IDD-3D, which consists of multi-modal data from multiple cameras and LiDAR sensors with 12k annotated driving LiDAR frames across various traffic scenarios. We discuss the need for this dataset through statistical comparisons with existing datasets and highlight benchmarks on standard 3D object detection and tracking tasks in complex layouts. Code and data available at https://github.com/shubham1810/idd3d_kit.git
Grounded Video Situation Recognition
Oct 19, 2022
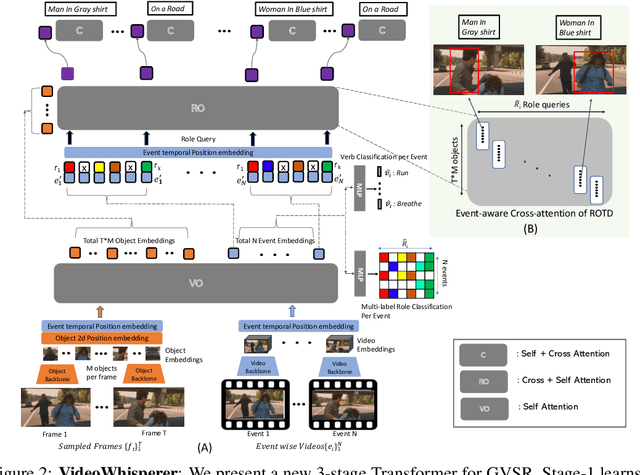


Dense video understanding requires answering several questions such as who is doing what to whom, with what, how, why, and where. Recently, Video Situation Recognition (VidSitu) is framed as a task for structured prediction of multiple events, their relationships, and actions and various verb-role pairs attached to descriptive entities. This task poses several challenges in identifying, disambiguating, and co-referencing entities across multiple verb-role pairs, but also faces some challenges of evaluation. In this work, we propose the addition of spatio-temporal grounding as an essential component of the structured prediction task in a weakly supervised setting, and present a novel three stage Transformer model, VideoWhisperer, that is empowered to make joint predictions. In stage one, we learn contextualised embeddings for video features in parallel with key objects that appear in the video clips to enable fine-grained spatio-temporal reasoning. The second stage sees verb-role queries attend and pool information from object embeddings, localising answers to questions posed about the action. The final stage generates these answers as captions to describe each verb-role pair present in the video. Our model operates on a group of events (clips) simultaneously and predicts verbs, verb-role pairs, their nouns, and their grounding on-the-fly. When evaluated on a grounding-augmented version of the VidSitu dataset, we observe a large improvement in entity captioning accuracy, as well as the ability to localize verb-roles without grounding annotations at training time.