 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Pretty Isn't Useful: Investigating Why Modern Text-to-Image Models Fail as Reliable Training Data Generators
Feb 24, 2026Recent text-to-image (T2I) diffusion models produce visually stunning images and demonstrate excellent prompt following. But do they perform well as synthetic vision data generators? In this work, we revisit the promise of synthetic data as a scalable substitute for real training sets and uncover a surprising performance regression. We generate large-scale synthetic datasets using state-of-the-art T2I models released between 2022 and 2025, train standard classifiers solely on this synthetic data, and evaluate them on real test data. Despite observable advances in visual fidelity and prompt adherence, classification accuracy on real test data consistently declines with newer T2I models as training data generators. Our analysis reveals a hidden trend: These models collapse to a narrow, aesthetic-centric distribution that undermines diversity and label-image alignment. Overall, our findings challenge a growing assumption in vision research, namely that progress in generative realism implies progress in data realism. We thus highlight an urgent need to rethink the capabilities of modern T2I models as reliable training data generators.
ForAug: Recombining Foregrounds and Backgrounds to Improve Vision Transformer Training with Bias Mitigation
Mar 12, 2025Transformers, particularly Vision Transformers (ViTs), have achieved state-of-the-art performance in large-scale image classification. However, they often require large amounts of data and can exhibit biases that limit their robustness and generalizability. This paper introduces ForAug, a novel data augmentation scheme that addresses these challenges and explicitly includes inductive biases, which commonly are part of the neural network architecture, into the training data. ForAug is constructed by using pretrained foundation models to separate and recombine foreground objects with different backgrounds, enabling fine-grained control over image composition during training. It thus increases the data diversity and effective number of training samples. We demonstrate that training on ForNet, the application of ForAug to ImageNet, significantly improves the accuracy of ViTs and other architectures by up to 4.5 percentage points (p.p.) on ImageNet and 7.3 p.p. on downstream tasks. Importantly, ForAug enables novel ways of analyzing model behavior and quantifying biases. Namely, we introduce metrics for background robustness, foreground focus, center bias, and size bias and show that training on ForNet substantially reduces these biases compared to training on ImageNet. In summary, ForAug provides a valuable tool for analyzing and mitigating biases, enabling the development of more robust and reliable computer vision models. Our code and dataset are publicly available at https://github.com/tobna/ForAug.
FedAD-Bench: A Unified Benchmark for Federated Unsupervised Anomaly Detection in Tabular Data
Aug 08, 2024



The emergence of federated learning (FL) presents a promising approach to leverage decentralized data while preserving privacy. Furthermore, the combination of FL and anomaly detection is particularly compelling because it allows for detecting rare and critical anomalies (usually also rare in locally gathered data) in sensitive data from multiple sources, such as cybersecurity and healthcare. However, benchmarking the performance of anomaly detection methods in FL environments remains an underexplored area. This paper introduces FedAD-Bench, a unified benchmark for evaluating unsupervised anomaly detection algorithms within the context of FL. We systematically analyze and compare the performance of recent deep learning anomaly detection models under federated settings, which were typically assessed solely in centralized settings. FedAD-Bench encompasses diverse datasets and metrics to provide a holistic evaluation. Through extensive experiments, we identify key challenges such as model aggregation inefficiencies and metric unreliability. We present insights into FL's regularization effects, revealing scenarios in which it outperforms centralized approaches due to its inherent ability to mitigate overfitting. Our work aims to establish a standardized benchmark to guide future research and development in federated anomaly detection, promoting reproducibility and fair comparison across studies.
DartsReNet: Exploring new RNN cells in ReNet architectures
Apr 11, 2023We present new Recurrent Neural Network (RNN) cells for image classification using a Neural Architecture Search (NAS) approach called DARTS. We are interested in the ReNet architecture, which is a RNN based approach presented as an alternative for convolutional and pooling steps. ReNet can be defined using any standard RNN cells, such as LSTM and GRU. One limitation is that standard RNN cells were designed for one dimensional sequential data and not for two dimensions like it is the case for image classification. We overcome this limitation by using DARTS to find new cell designs. We compare our results with ReNet that uses GRU and LSTM cells. Our found cells outperform the standard RNN cells on CIFAR-10 and SVHN. The improvements on SVHN indicate generalizability, as we derived the RNN cell designs from CIFAR-10 without performing a new cell search for SVHN.
Waving Goodbye to Low-Res: A Diffusion-Wavelet Approach for Image Super-Resolution
Apr 05, 2023



This paper presents a novel Diffusion-Wavelet (DiWa) approach for Single-Image Super-Resolution (SISR). It leverages the strengths of Denoising Diffusion Probabilistic Models (DDPMs) and Discrete Wavelet Transformation (DWT). By enabling DDPMs to operate in the DWT domain, our DDPM models effectively hallucinate high-frequency information for super-resolved images on the wavelet spectrum, resulting in high-quality and detailed reconstructions in image space. Quantitatively, we outperform state-of-the-art diffusion-based SISR methods, namely SR3 and SRDiff, regarding PSNR, SSIM, and LPIPS on both face (8x scaling) and general (4x scaling) SR benchmarks. Meanwhile, using DWT enabled us to use fewer parameters than the compared models: 92M parameters instead of 550M compared to SR3 and 9.3M instead of 12M compared to SRDiff. Additionally, our method outperforms other state-of-the-art generative methods on classical general SR datasets while saving inference time. Finally, our work highlights its potential for various applications.
Hitchhiker's Guide to Super-Resolution: Introduction and Recent Advances
Sep 27, 2022
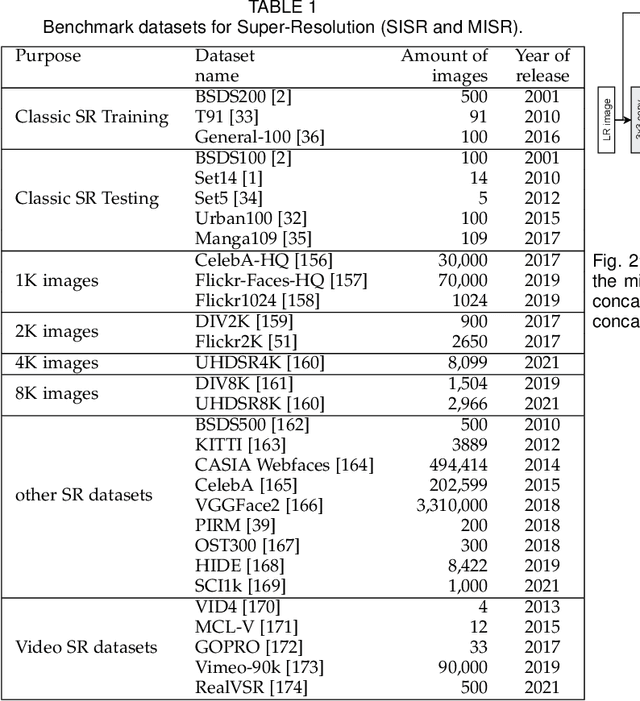
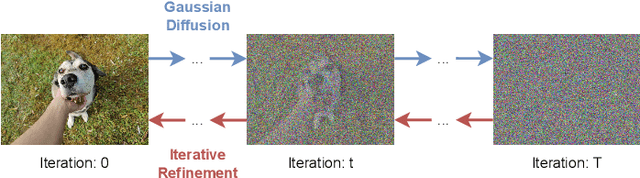
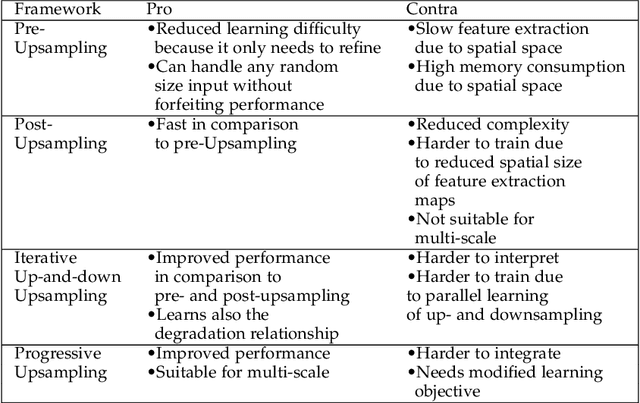
With the advent of Deep Learning (DL), Super-Resolution (SR) has also become a thriving research area. However, despite promising results, the field still faces challenges that require further research e.g., allowing flexible upsampling, more effective loss functions, and better evaluation metrics. We review the domain of SR in light of recent advances, and examine state-of-the-art models such as diffusion (DDPM) and transformer-based SR models. We present a critical discussion on contemporary strategies used in SR, and identify promising yet unexplored research directions. We complement previous surveys by incorporating the latest developments in the field such as uncertainty-driven losses, wavelet networks, neural architecture search, novel normalization methods, and the latests evaluation techniques. We also include several visualizations for the models and methods throughout each chapter in order to facilitate a global understanding of the trends in the field. This review is ultimately aimed at helping researchers to push the boundaries of DL applied to SR.
Less is More: Proxy Datasets in NAS approaches
Mar 14, 2022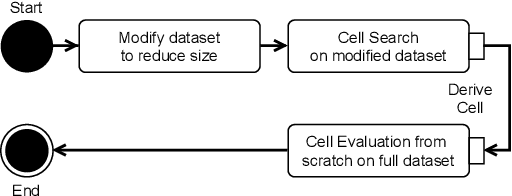
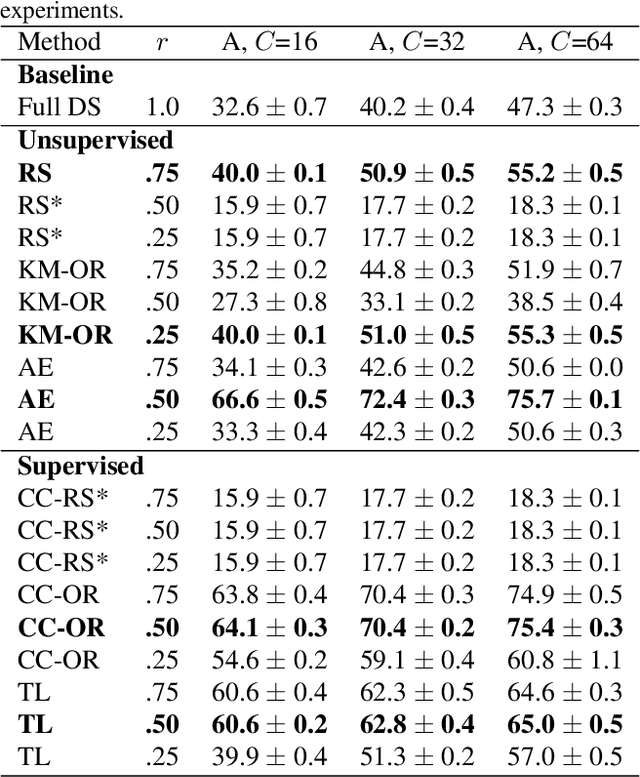
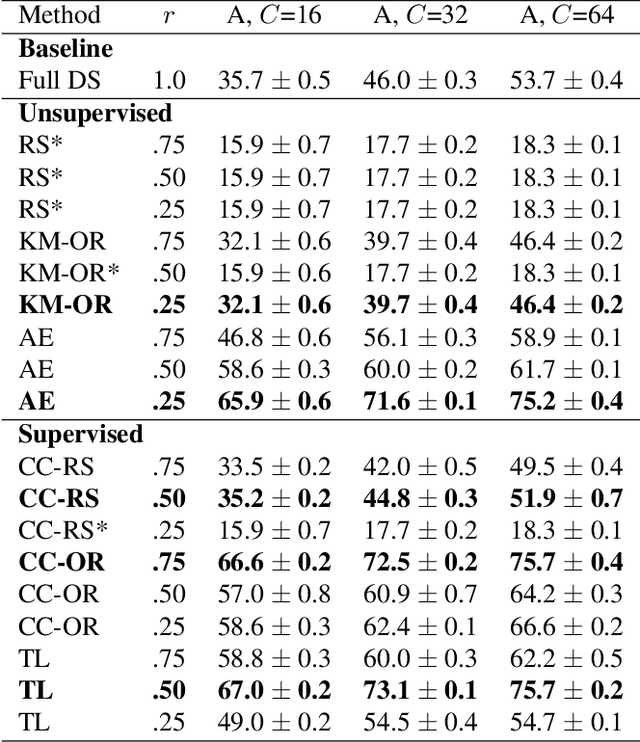
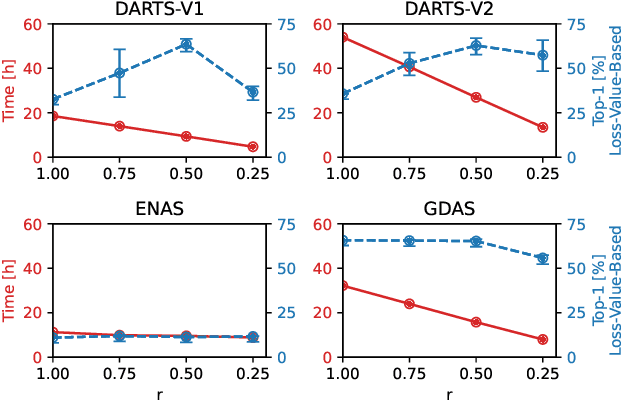
Neural Architecture Search (NAS) defines the design of Neural Networks as a search problem. Unfortunately, NAS is computationally intensive because of various possibilities depending on the number of elements in the design and the possible connections between them. In this work, we extensively analyze the role of the dataset size based on several sampling approaches for reducing the dataset size (unsupervised and supervised cases) as an agnostic approach to reduce search time. We compared these techniques with four common NAS approaches in NAS-Bench-201 in roughly 1,400 experiments on CIFAR-100. One of our surprising findings is that in most cases we can reduce the amount of training data to 25\%, consequently reducing search time to 25\%, while at the same time maintaining the same accuracy as if training on the full dataset. Additionally, some designs derived from subsets out-perform designs derived from the full dataset by up to 22 p.p. accuracy.