 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
May 06, 2022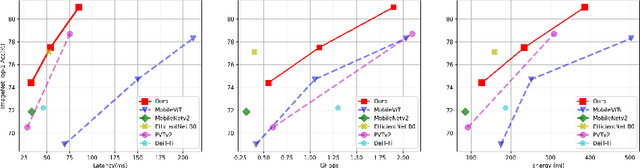
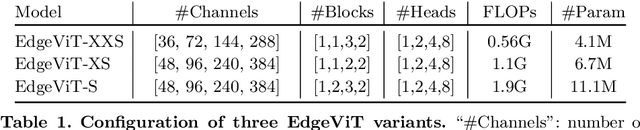
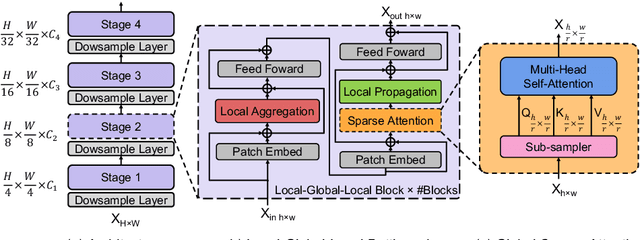
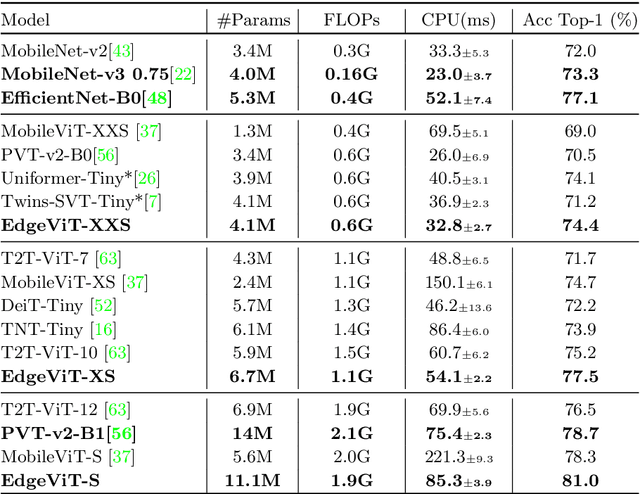
Self-attention based models such as vision transformers (ViTs) have emerged as a very competitive architecture alternative to convolutional neural networks (CNNs) in computer vision. Despite increasingly stronger variants with ever-higher recognition accuracies, due to the quadratic complexity of self-attention, existing ViTs are typically demanding in computation and model size. Although several successful design choices (e.g., the convolutions and hierarchical multi-stage structure) of prior CNNs have been reintroduced into recent ViTs, they are still not sufficient to meet the limited resource requirements of mobile devices. This motivates a very recent attempt to develop light ViTs based on the state-of-the-art MobileNet-v2, but still leaves a performance gap behind. In this work, pushing further along this under-studied direction we introduce EdgeViTs, a new family of light-weight ViTs that, for the first time, enable attention-based vision models to compete with the best light-weight CNNs in the tradeoff between accuracy and on-device efficiency. This is realized by introducing a highly cost-effective local-global-local (LGL) information exchange bottleneck based on optimal integration of self-attention and convolutions. For device-dedicated evaluation, rather than relying on inaccurate proxies like the number of FLOPs or parameters, we adopt a practical approach of focusing directly on on-device latency and, for the first time, energy efficiency. Specifically, we show that our models are Pareto-optimal when both accuracy-latency and accuracy-energy trade-offs are considered, achieving strict dominance over other ViTs in almost all cases and competing with the most efficient CNNs.
SOS! Self-supervised Learning Over Sets Of Handled Objects In Egocentric Action Recognition
Apr 10, 2022
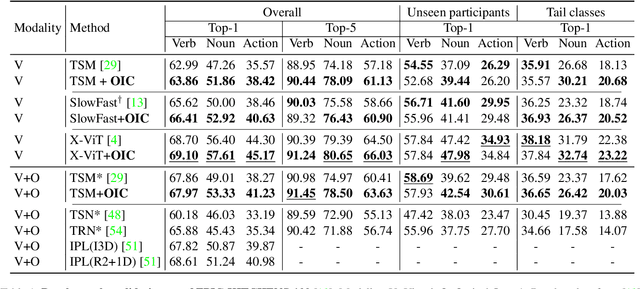

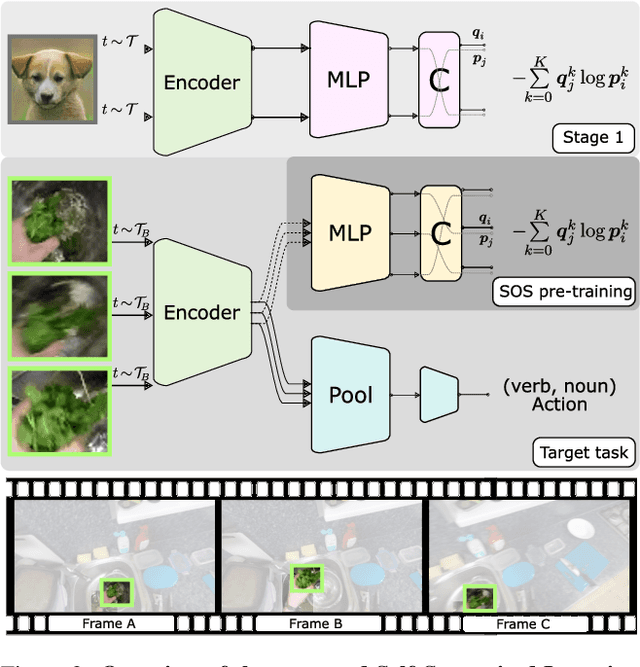
Learning an egocentric action recognition model from video data is challenging due to distractors (e.g., irrelevant objects) in the background. Further integrating object information into an action model is hence beneficial. Existing methods often leverage a generic object detector to identify and represent the objects in the scene. However, several important issues remain. Object class annotations of good quality for the target domain (dataset) are still required for learning good object representation. Besides, previous methods deeply couple the existing action models and need to retrain them jointly with object representation, leading to costly and inflexible integration. To overcome both limitations, we introduce Self-Supervised Learning Over Sets (SOS), an approach to pre-train a generic Objects In Contact (OIC) representation model from video object regions detected by an off-the-shelf hand-object contact detector. Instead of augmenting object regions individually as in conventional self-supervised learning, we view the action process as a means of natural data transformations with unique spatio-temporal continuity and exploit the inherent relationships among per-video object sets. Extensive experiments on two datasets, EPIC-KITCHENS-100 and EGTEA, show that our OIC significantly boosts the performance of multiple state-of-the-art video classification models.
SAIC_Cambridge-HuPBA-FBK Submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021
Oct 06, 2021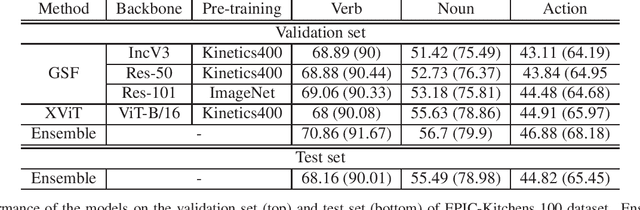
This report presents the technical details of our submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021. To participate in the challenge we deployed spatio-temporal feature extraction and aggregation models we have developed recently: GSF and XViT. GSF is an efficient spatio-temporal feature extracting module that can be plugged into 2D CNNs for video action recognition. XViT is a convolution free video feature extractor based on transformer architecture. We design an ensemble of GSF and XViT model families with different backbones and pretraining to generate the prediction scores. Our submission, visible on the public leaderboard, achieved a top-1 action recognition accuracy of 44.82%, using only RGB.
Space-time Mixing Attention for Video Transformer
Jun 11, 2021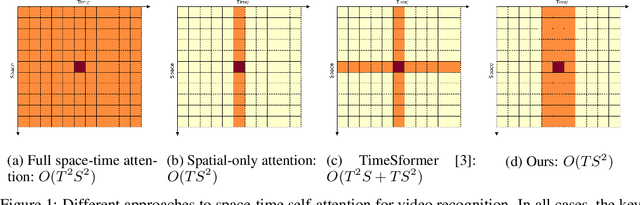
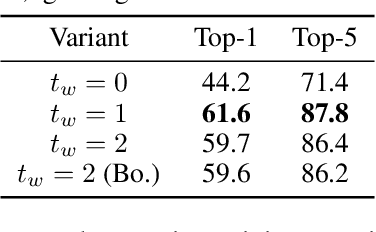
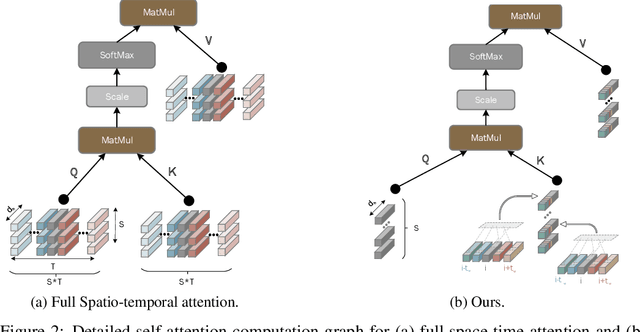
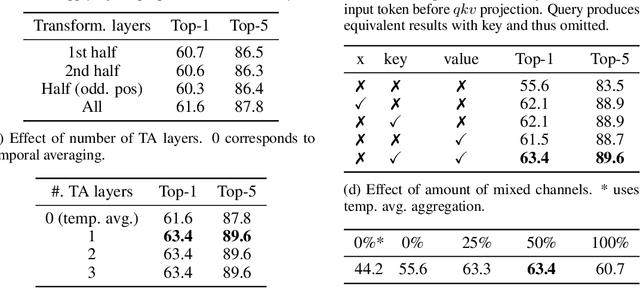
This paper is on video recognition using Transformers. Very recent attempts in this area have demonstrated promising results in terms of recognition accuracy, yet they have been also shown to induce, in many cases, significant computational overheads due to the additional modelling of the temporal information. In this work, we propose a Video Transformer model the complexity of which scales linearly with the number of frames in the video sequence and hence induces no overhead compared to an image-based Transformer model. To achieve this, our model makes two approximations to the full space-time attention used in Video Transformers: (a) It restricts time attention to a local temporal window and capitalizes on the Transformer's depth to obtain full temporal coverage of the video sequence. (b) It uses efficient space-time mixing to attend jointly spatial and temporal locations without inducing any additional cost on top of a spatial-only attention model. We also show how to integrate 2 very lightweight mechanisms for global temporal-only attention which provide additional accuracy improvements at minimal computational cost. We demonstrate that our model produces very high recognition accuracy on the most popular video recognition datasets while at the same time being significantly more efficient than other Video Transformer models. Code will be made available.
Low-Fidelity End-to-End Video Encoder Pre-training for Temporal Action Localization
Mar 30, 2021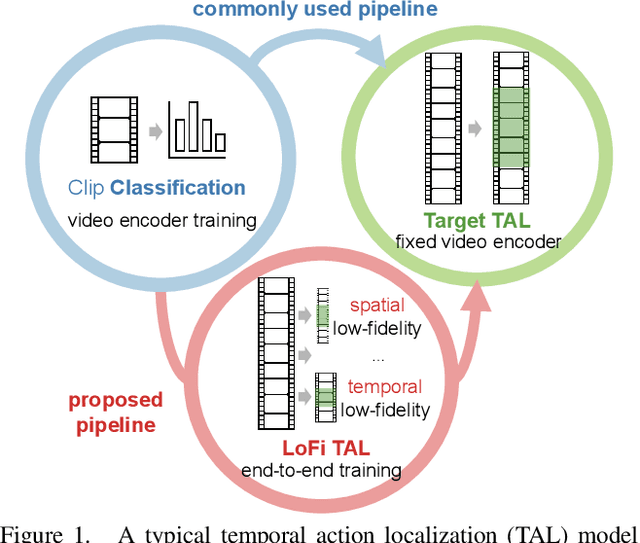
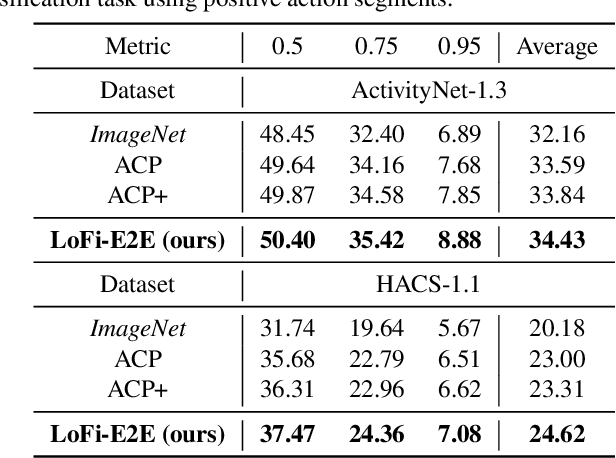
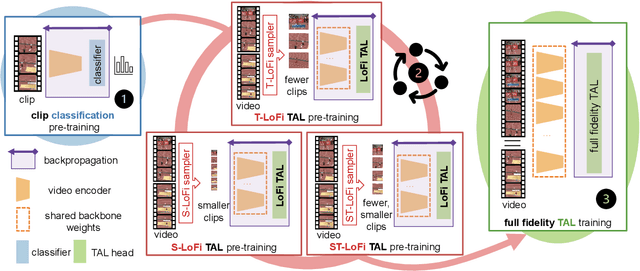
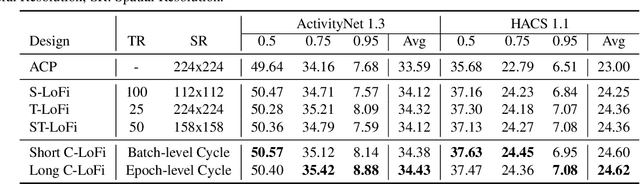
Temporal action localization (TAL) is a fundamental yet challenging task in video understanding. Existing TAL methods rely on pre-training a video encoder through action classification supervision. This results in a task discrepancy problem for the video encoder -- trained for action classification, but used for TAL. Intuitively, end-to-end model optimization is a good solution. However, this is not operable for TAL subject to the GPU memory constraints, due to the prohibitive computational cost in processing long untrimmed videos. In this paper, we resolve this challenge by introducing a novel low-fidelity end-to-end (LoFi) video encoder pre-training method. Instead of always using the full training configurations for TAL learning, we propose to reduce the mini-batch composition in terms of temporal, spatial or spatio-temporal resolution so that end-to-end optimization for the video encoder becomes operable under the memory conditions of a mid-range hardware budget. Crucially, this enables the gradient to flow backward through the video encoder from a TAL loss supervision, favourably solving the task discrepancy problem and providing more effective feature representations. Extensive experiments show that the proposed LoFi pre-training approach can significantly enhance the performance of existing TAL methods. Encouragingly, even with a lightweight ResNet18 based video encoder in a single RGB stream, our method surpasses two-stream ResNet50 based alternatives with expensive optical flow, often by a good margin.
Few-shot Action Recognition with Prototype-centered Attentive Learning
Feb 03, 2021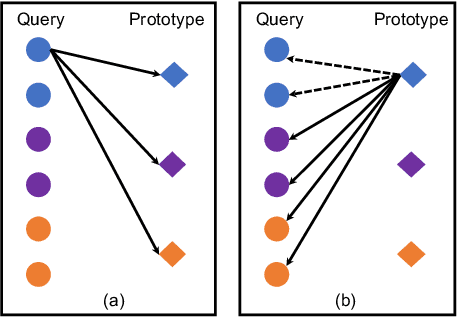
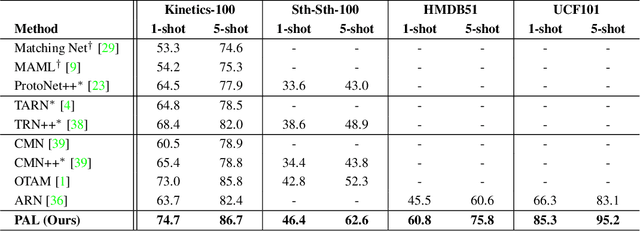
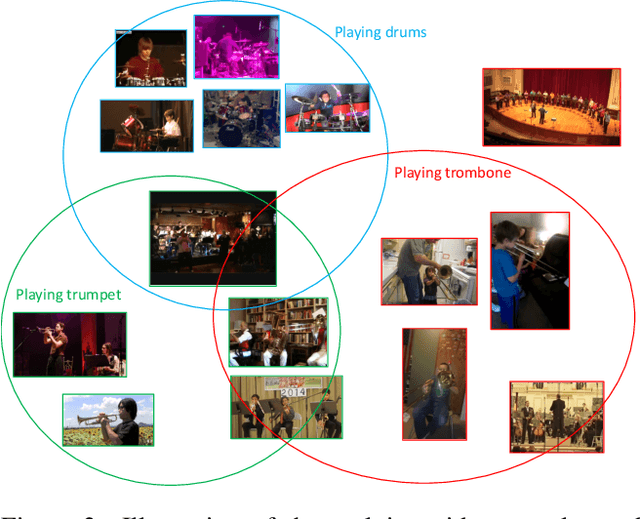
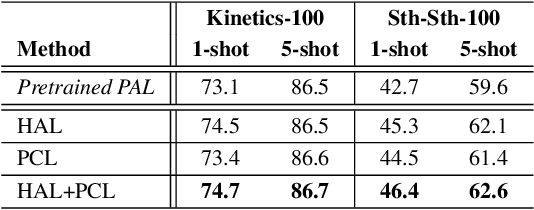
Few-shot action recognition aims to recognize action classes with few training samples. Most existing methods adopt a meta-learning approach with episodic training. In each episode, the few samples in a meta-training task are split into support and query sets. The former is used to build a classifier, which is then evaluated on the latter using a query-centered loss for model updating. There are however two major limitations: lack of data efficiency due to the query-centered only loss design and inability to deal with the support set outlying samples and inter-class distribution overlapping problems. In this paper, we overcome both limitations by proposing a new Prototype-centered Attentive Learning (PAL) model composed of two novel components. First, a prototype-centered contrastive learning loss is introduced to complement the conventional query-centered learning objective, in order to make full use of the limited training samples in each episode. Second, PAL further integrates a hybrid attentive learning mechanism that can minimize the negative impacts of outliers and promote class separation. Extensive experiments on four standard few-shot action benchmarks show that our method clearly outperforms previous state-of-the-art methods, with the improvement particularly significant (10+\%) on the most challenging fine-grained action recognition benchmark.
Boundary-sensitive Pre-training for Temporal Localization in Videos
Nov 24, 2020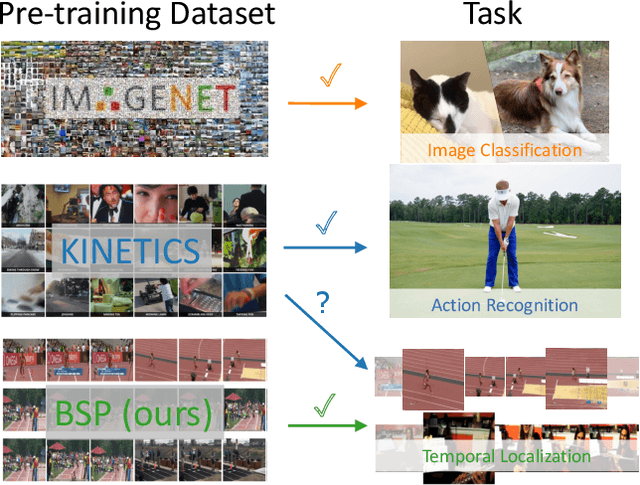
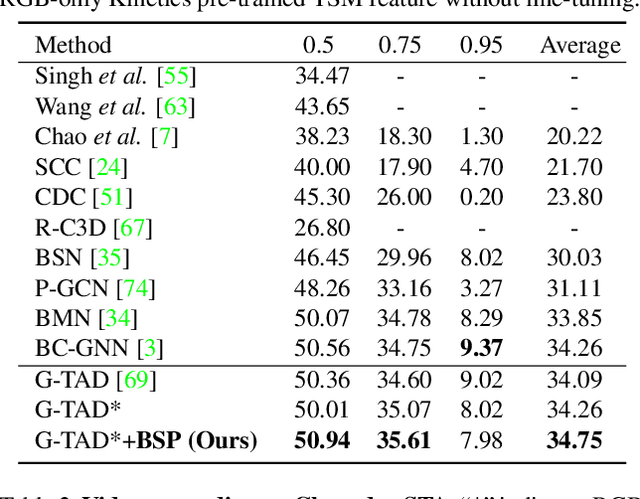

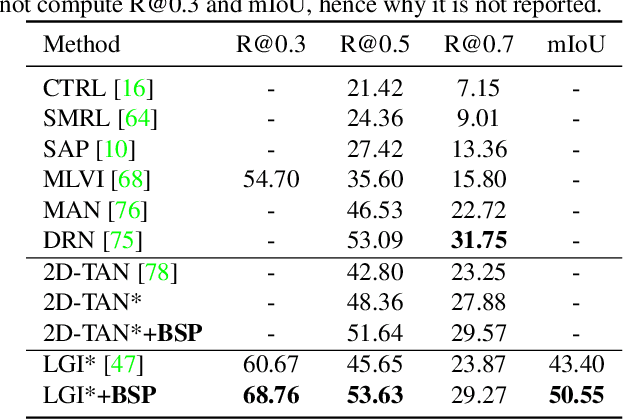
Many video analysis tasks require temporal localization thus detection of content changes. However, most existing models developed for these tasks are pre-trained on general video action classification tasks. This is because large scale annotation of temporal boundaries in untrimmed videos is expensive. Therefore no suitable datasets exist for temporal boundary-sensitive pre-training. In this paper for the first time, we investigate model pre-training for temporal localization by introducing a novel boundary-sensitive pretext (BSP) task. Instead of relying on costly manual annotations of temporal boundaries, we propose to synthesize temporal boundaries in existing video action classification datasets. With the synthesized boundaries, BSP can be simply conducted via classifying the boundary types. This enables the learning of video representations that are much more transferable to downstream temporal localization tasks. Extensive experiments show that the proposed BSP is superior and complementary to the existing action classification based pre-training counterpart, and achieves new state-of-the-art performance on several temporal localization tasks.
High-Capacity Expert Binary Networks
Oct 07, 2020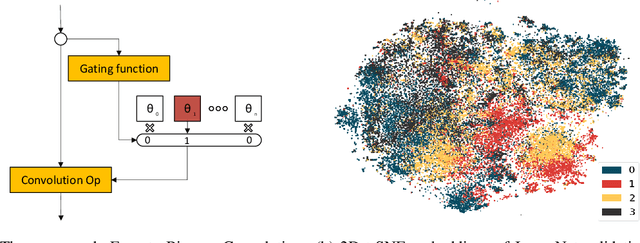
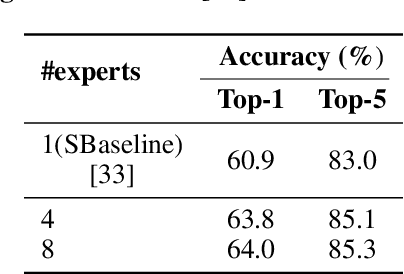
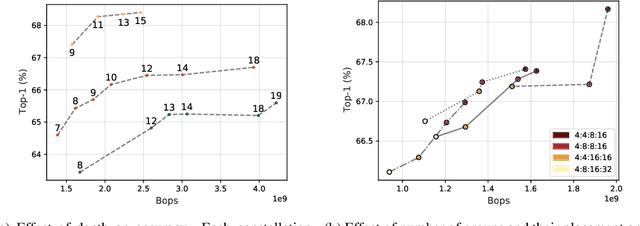
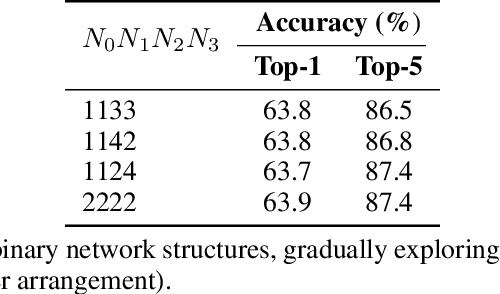
Network binarization is a promising hardware-aware direction for creating efficient deep models. Despite its memory and computational advantages, reducing the accuracy gap between such models and their real-valued counterparts remains an unsolved challenging research problem. To this end, we make the following 3 contributions: (a) To increase model capacity, we propose Expert Binary Convolution, which, for the first time, tailors conditional computing to binary networks by learning to select one data-specific expert binary filter at a time conditioned on input features. (b) To increase representation capacity, we propose to address the inherent information bottleneck in binary networks by introducing an efficient width expansion mechanism which keeps the binary operations within the same budget. (c) To improve network design, we propose a principled binary network growth mechanism that unveils a set of network topologies of favorable properties. Overall, our method improves upon prior work, with no increase in computational cost by ~6%, reaching a groundbreaking ~71% on ImageNet classification.
Towards practical lipreading with distilled and efficient models
Jul 13, 2020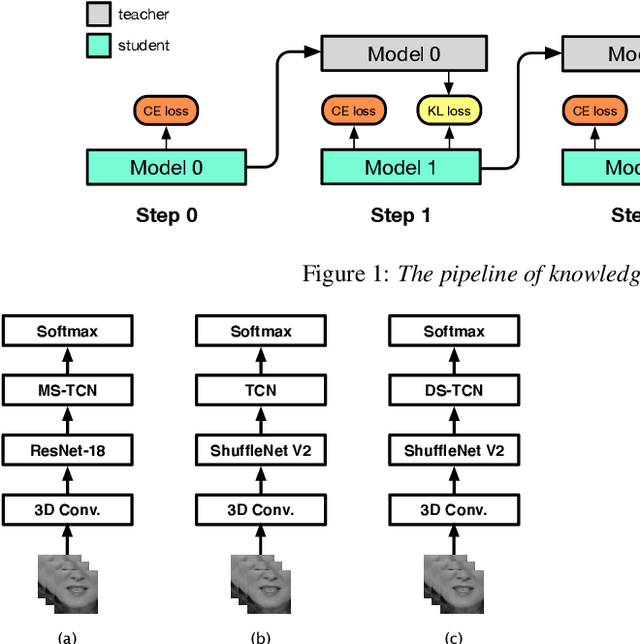
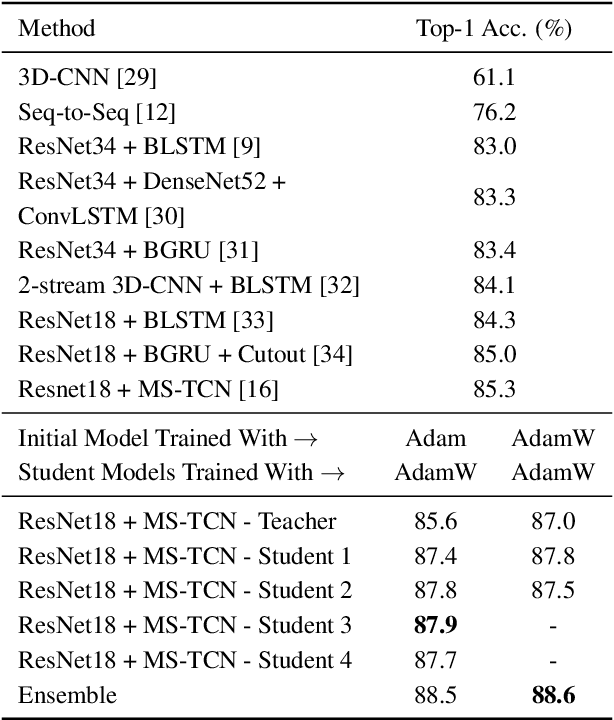
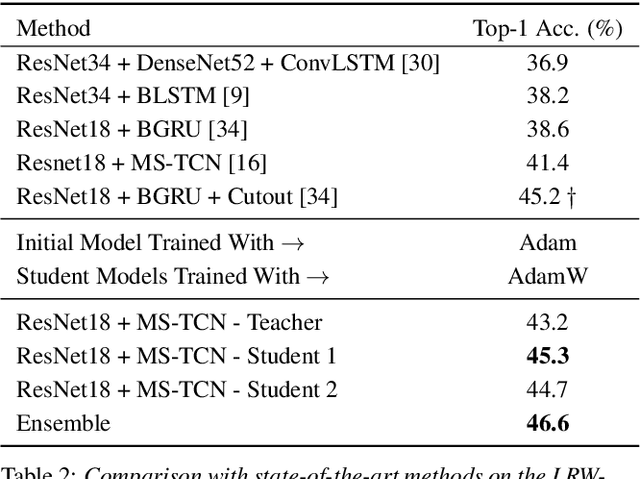
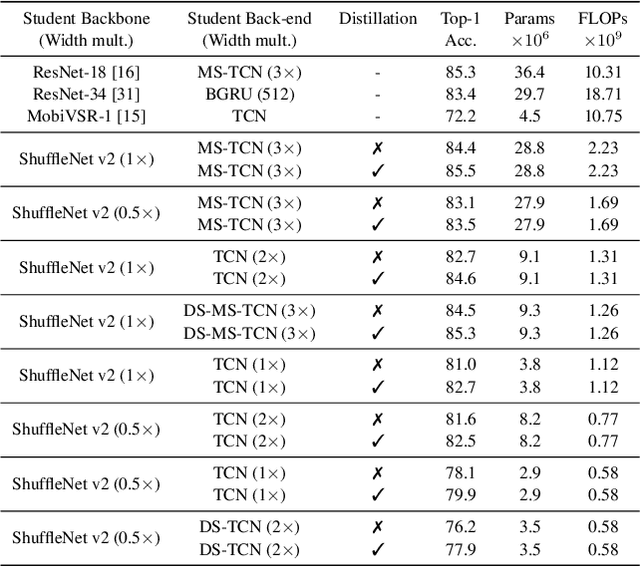
Lipreading has witnessed a lot of progress due to the resurgence of neural networks. Recent work has placed emphasis on aspects such as improving performance by finding the optimal architecture or improving generalization. However, there is still a significant gap between the current methodologies and the requirements for an effective deployment of lipreading in practical scenarios. In this work, we propose a series of innovations that significantly bridge that gap: first, we raise the state-of-the-art performance by a wide margin on LRW and LRW-1000 to 88.6% and 46.6%, respectively, through careful optimization. Secondly, we propose a series of architectural changes, including a novel depthwise-separable TCN head, that slashes the computational cost to a fraction of the (already quite efficient) original model. Thirdly, we show that knowledge distillation is a very effective tool for recovering performance of the lightweight models. This results in a range of models with different accuracy-efficiency trade-offs. However, our most promising lightweight models are on par with the current state-of-the-art while showing a reduction of 8 and 4x in terms of computational cost and number of parameters, respectively, which we hope will enable the deployment of lipreading models in practical applications.
Egocentric Action Recognition by Video Attention and Temporal Context
Jul 03, 2020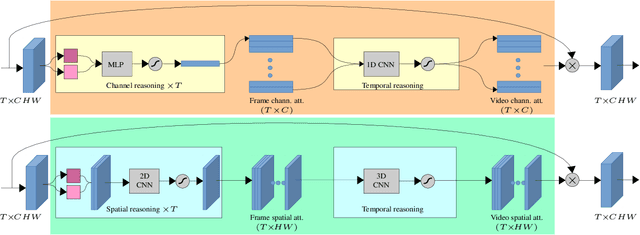
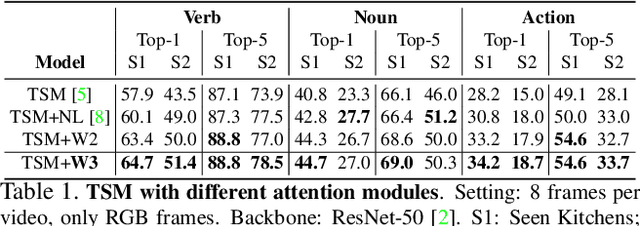
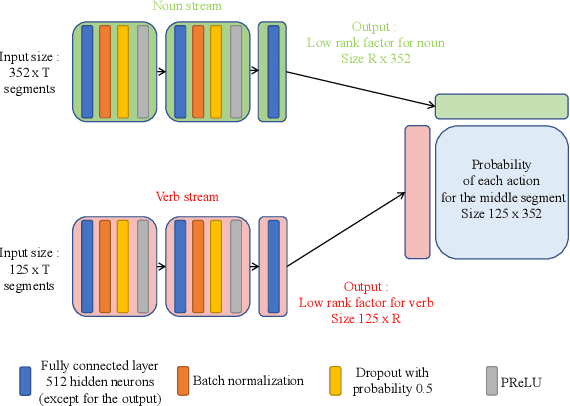
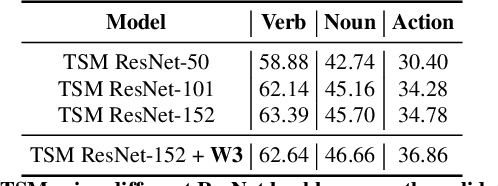
We present the submission of Samsung AI Centre Cambridge to the CVPR2020 EPIC-Kitchens Action Recognition Challenge. In this challenge, action recognition is posed as the problem of simultaneously predicting a single `verb' and `noun' class label given an input trimmed video clip. That is, a `verb' and a `noun' together define a compositional `action' class. The challenging aspects of this real-life action recognition task include small fast moving objects, complex hand-object interactions, and occlusions. At the core of our submission is a recently-proposed spatial-temporal video attention model, called `W3' (`What-Where-When') attention~\cite{perez2020knowing}. We further introduce a simple yet effective contextual learning mechanism to model `action' class scores directly from long-term temporal behaviour based on the `verb' and `noun' prediction scores. Our solution achieves strong performance on the challenge metrics without using object-specific reasoning nor extra training data. In particular, our best solution with multimodal ensemble achieves the 2$^{nd}$ best position for `verb', and 3$^{rd}$ best for `noun' and `action' on the Seen Kitchens test set.