 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Budgeted Learning for Classifier Induction
Mar 13, 2019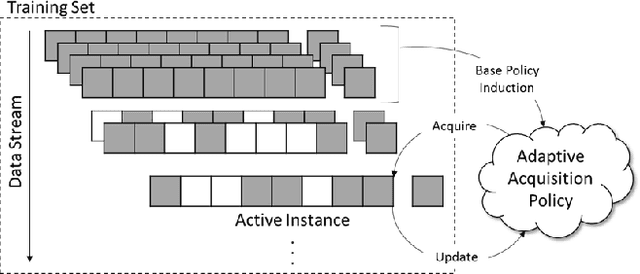
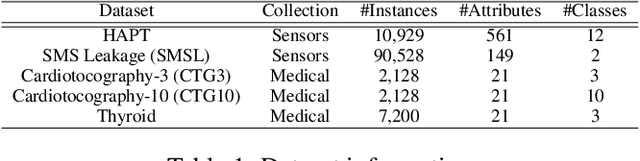
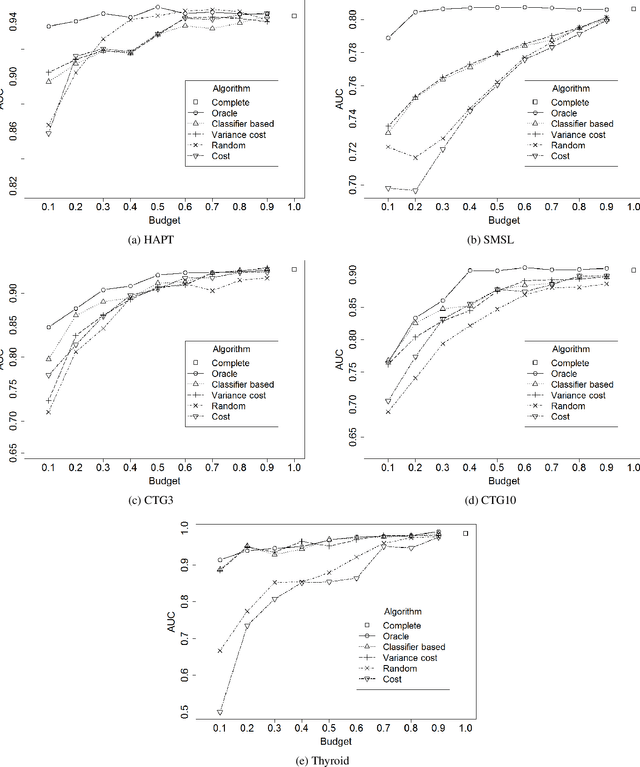
In real-world machine learning applications, there is a cost associated with sampling of different features. Budgeted learning can be used to select which feature-values to acquire from each instance in a dataset, such that the best model is induced under a given constraint. However, this approach is not possible in the domain of online learning since one may not retroactively acquire feature-values from past instances. In online learning, the challenge is to find the optimum set of features to be acquired from each instance upon arrival from a data stream. In this paper we introduce the issue of online budgeted learning and describe a general framework for addressing this challenge. We propose two types of feature value acquisition policies based on the multi-armed bandit problem: random and adaptive. Adaptive policies perform online adjustments according to new information coming from a data stream, while random policies are not sensitive to the information that arrives from the data stream. Our comparative study on five real-world datasets indicates that adaptive policies outperform random policies for most budget limitations and datasets. Furthermore, we found that in some cases adaptive policies achieve near-optimal results.
Personal Dynamic Cost-Aware Sensing for Latent Context Detection
Mar 13, 2019

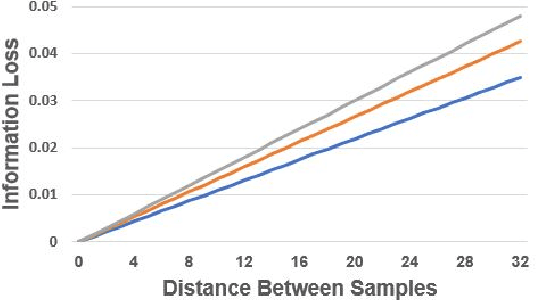
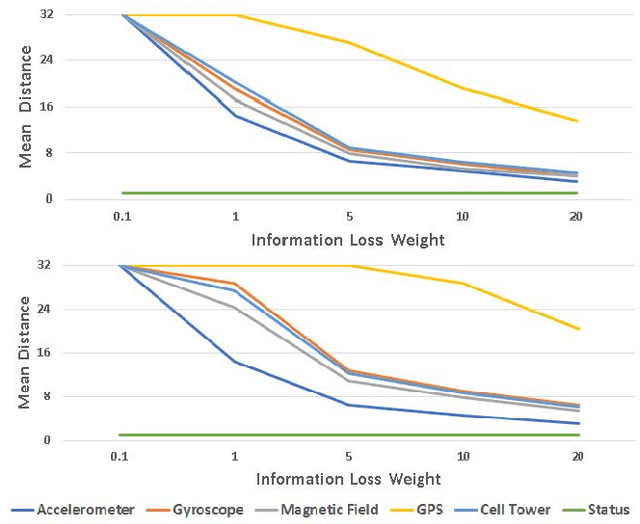
In the past decade, the usage of mobile devices has gone far beyond simple activities like calling and texting. Today, smartphones contain multiple embedded sensors and are able to collect useful sensing data about the user and infer the user's context. The more frequent the sensing, the more accurate the context. However, continuous sensing results in huge energy consumption, decreasing the battery's lifetime. We propose a novel approach for cost-aware sensing when performing continuous latent context detection. The suggested method dynamically determines user's sensors sampling policy based on three factors: (1) User's last known context; (2) Predicted information loss using KL-Divergence; and (3) Sensors' sampling costs. The objective function aims at minimizing both sampling cost and information loss. The method is based on various machine learning techniques including autoencoder neural networks for latent context detection, linear regression for information loss prediction, and convex optimization for determining the optimal sampling policy. To evaluate the suggested method, we performed a series of tests on real-world data recorded at a high-frequency rate; the data was collected from six mobile phone sensors of twenty users over the course of a week. Results show that by applying a dynamic sampling policy, our method naturally balances information loss and energy consumption and outperforms the static approach.% We compared the performance of our method with another state of the art dynamic sampling method and demonstrate its consistent superiority in various measures. %Our methods outperformed, and were able to improve we achieved better results in either sampling cost or information loss, and in some cases we improved both.
Detecting drug-drug interactions using artificial neural networks and classic graph similarity measures
Mar 11, 2019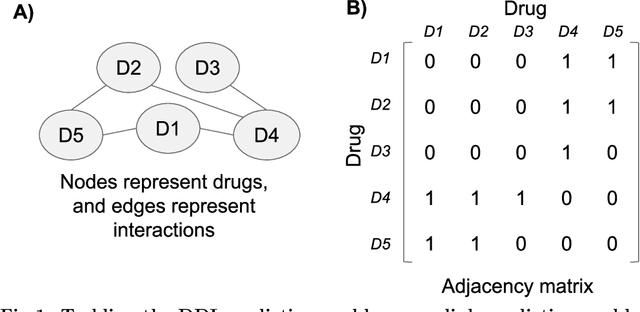
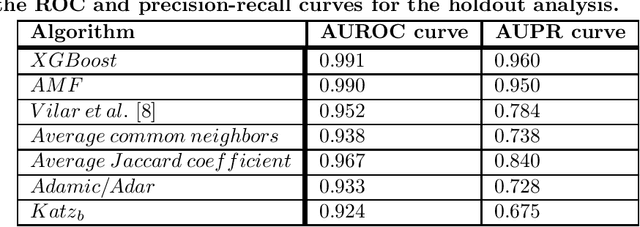

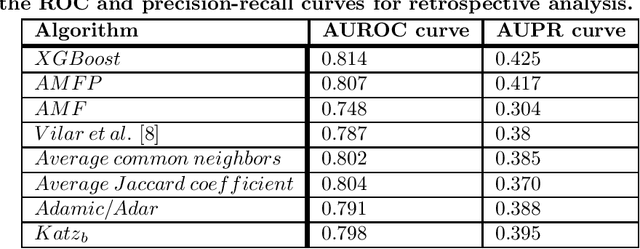
Drug-drug interactions are preventable causes of medical injuries and often result in doctor and emergency room visits. Computational techniques can be used to predict potential drug-drug interactions. We approach the drug-drug interaction prediction problem as a link prediction problem and present two novel methods for drug-drug interaction prediction based on artificial neural networks and factor propagation over graph nodes: adjacency matrix factorization (AMF) and adjacency matrix factorization with propagation (AMFP). We conduct a retrospective analysis by training our models on a previous release of the DrugBank database with 1,141 drugs and 45,296 drug-drug interactions and evaluate the results on a later version of DrugBank with 1,440 drugs and 248,146 drug-drug interactions. Additionally, we perform a holdout analysis using DrugBank. We report an area under the receiver operating characteristic curve score of 0.807 and 0.990 for the retrospective and holdout analyses respectively. Finally, we create an ensemble-based classifier using AMF, AMFP, and existing link prediction methods and obtain an area under the receiver operating characteristic curve of 0.814 and 0.991 for the retrospective and the holdout analyses. We demonstrate that AMF and AMFP provide state of the art results compared to existing methods and that the ensemble-based classifier improves the performance by combining various predictors. These results suggest that AMF, AMFP, and the proposed ensemble-based classifier can provide important information during drug development and regarding drug prescription given only partial or noisy data. These methods can also be used to solve other link prediction problems. Drug embeddings (compressed representations) created when training our models using the interaction network have been made public.
Attack Graph Obfuscation
Mar 06, 2019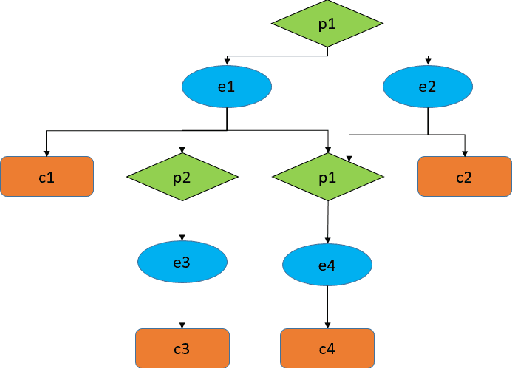
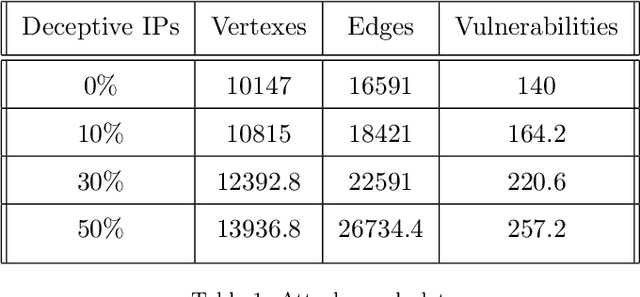
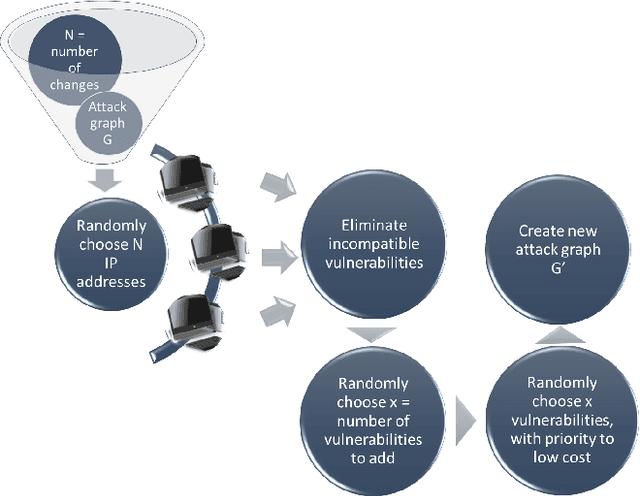
Before executing an attack, adversaries usually explore the victim's network in an attempt to infer the network topology and identify vulnerabilities in the victim's servers and personal computers. Falsifying the information collected by the adversary post penetration may significantly slower lateral movement and increase the amount of noise generated within the victim's network. We investigate the effect of fake vulnerabilities within a real enterprise network on the attacker performance. We use the attack graphs to model the path of an attacker making its way towards a target in a given network. We use combinatorial optimization in order to find the optimal assignments of fake vulnerabilities. We demonstrate the feasibility of our deception-based defense by presenting results of experiments with a large scale real network. We show that adding fake vulnerabilities forces the adversary to invest a significant amount of effort, in terms of time and exploitability cost.
Explaining Anomalies Detected by Autoencoders Using SHAP
Mar 06, 2019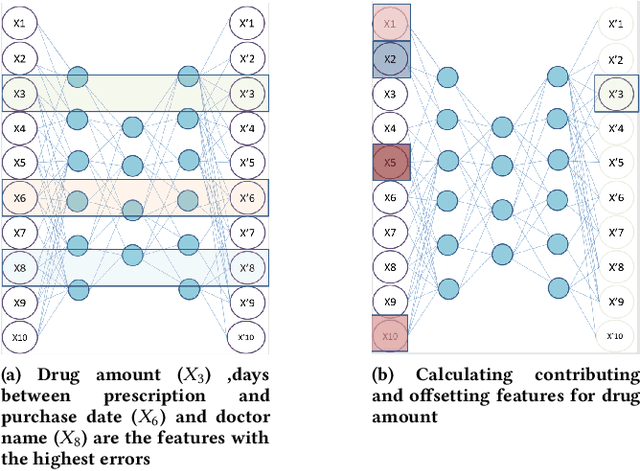



Anomaly detection algorithms are often thought to be limited because they don't facilitate the process of validating results performed by domain experts. In Contrast, deep learning algorithms for anomaly detection, such as autoencoders, point out the outliers, saving experts the time-consuming task of examining normal cases in order to find anomalies. Most outlier detection algorithms output a score for each instance in the database. The top-k most intense outliers are returned to the user for further inspection; however the manual validation of results becomes challenging without additional clues. An explanation of why an instance is anomalous enables the experts to focus their investigation on most important anomalies and may increase their trust in the algorithm. Recently, a game theory-based framework known as SHapley Additive exPlanations (SHAP) has been shown to be effective in explaining various supervised learning models. In this research, we extend SHAP to explain anomalies detected by an autoencoder, an unsupervised model. The proposed method extracts and visually depicts both the features that most contributed to the anomaly and those that offset it. A preliminary experimental study using real world data demonstrates the usefulness of the proposed method in assisting the domain experts to understand the anomaly and filtering out the uninteresting anomalies, aiming at minimizing the false positive rate of detected anomalies.
Implicit Dimension Identification in User-Generated Text with LSTM Networks
Feb 01, 2019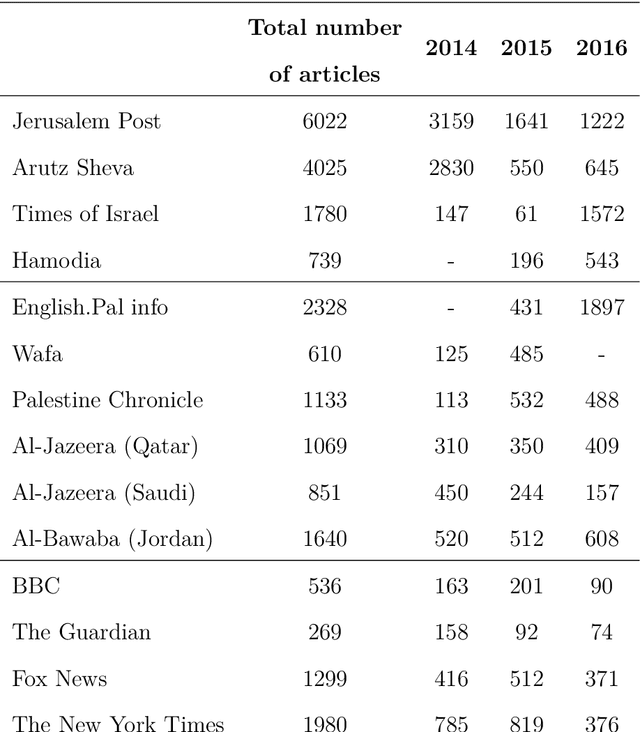


In the process of online storytelling, individual users create and consume highly diverse content that contains a great deal of implicit beliefs and not plainly expressed narrative. It is hard to manually detect these implicit beliefs, intentions and moral foundations of the writers. We study and investigate two different tasks, each of which reflect the difficulty of detecting an implicit user's knowledge, intent or belief that may be based on writer's moral foundation: 1) political perspective detection in news articles 2) identification of informational vs. conversational questions in community question answering (CQA) archives and. In both tasks we first describe new interesting annotated datasets and make the datasets publicly available. Second, we compare various classification algorithms, and show the differences in their performance on both tasks. Third, in political perspective detection task we utilize a narrative representation language of local press to identify perspective differences between presumably neutral American and British press.
Choosing the Right Word: Using Bidirectional LSTM Tagger for Writing Support Systems
Jan 08, 2019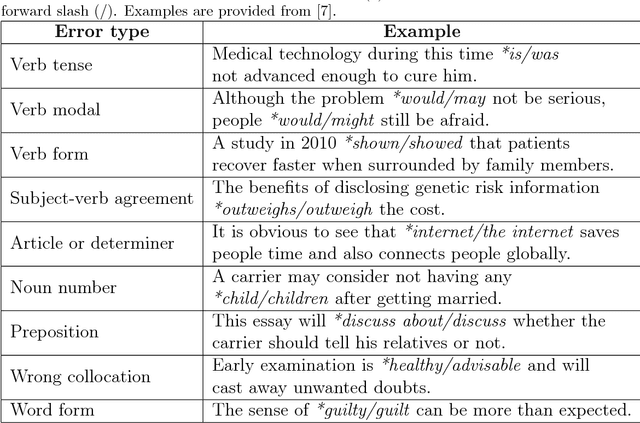
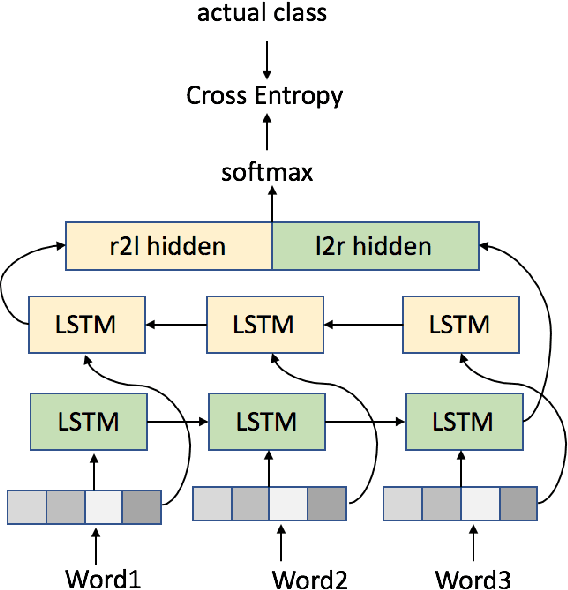
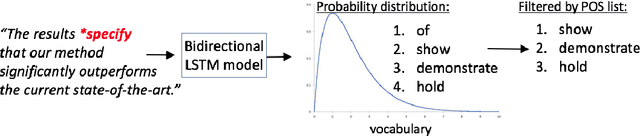
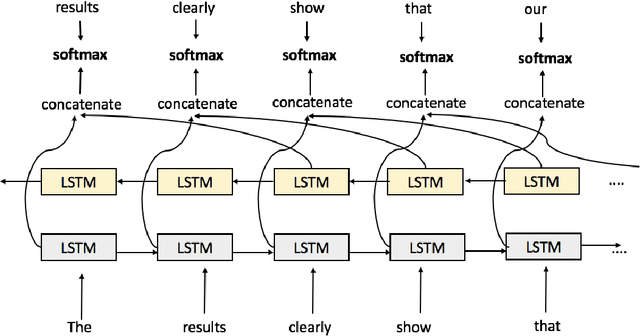
Scientific writing is difficult. It is even harder for those for whom English is a second language (ESL learners). Scholars around the world spend a significant amount of time and resources proofreading their work before submitting it for review or publication. In this paper we present a novel machine learning based application for proper word choice task. Proper word choice is a generalization the lexical substitution (LS) and grammatical error correction (GEC) tasks. We demonstrate and evaluate the usefulness of applying bidirectional Long Short Term Memory (LSTM) tagger, for this task. While state-of-the-art grammatical error correction uses error-specific classifiers and machine translation methods, we demonstrate an unsupervised method that is based solely on a high quality text corpus and does not require manually annotated data. We use a bidirectional Recurrent Neural Network (RNN) with LSTM for learning the proper word choice based on a word's sentential context. We demonstrate and evaluate our application on both a domain-specific (scientific), writing task and a general-purpose writing task. We show that our domain-specific and general-purpose models outperform state-of-the-art general context learning. As an additional contribution of this research, we also share our code, pre-trained models, and a new ESL learner test set with the research community.
Wikibook-Bot - Automatic Generation of a Wikipedia Book
Dec 28, 2018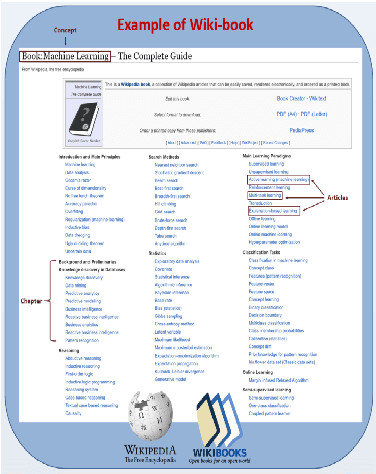

A Wikipedia book (known as Wikibook) is a collection of Wikipedia articles on a particular theme that is organized as a book. We propose Wikibook-Bot, a machine-learning based technique for automatically generating high quality Wikibooks based on a concept provided by the user. In order to create the Wikibook we apply machine learning algorithms to the different steps of the proposed technique. Firs, we need to decide whether an article belongs to a specific Wikibook - a classification task. Then, we need to divide the chosen articles into chapters - a clustering task - and finally, we deal with the ordering task which includes two subtasks: order articles within each chapter and order the chapters themselves. We propose a set of structural, text-based and unique Wikipedia features, and we show that by using these features, a machine learning classifier can successfully address the above challenges. The predictive performance of the proposed method is evaluated by comparing the auto-generated books to existing 407 Wikibooks which were manually generated by humans. For all the tasks we were able to obtain high and statistically significant results when comparing the Wikibook-bot books to books that were manually generated by Wikipedia contributors
Sampling High Throughput Data for Anomaly Detection of Data-Base Activity
Aug 14, 2017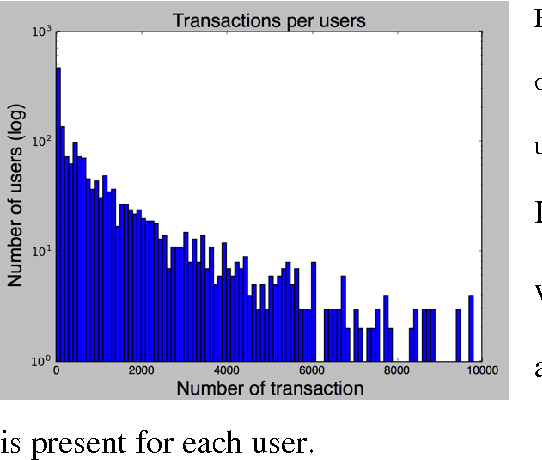
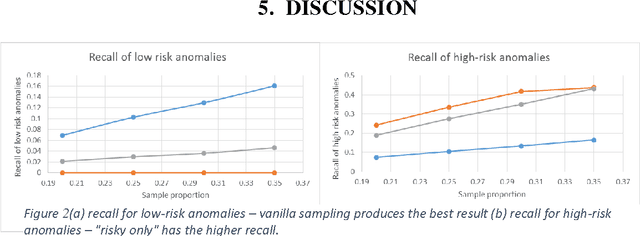
Data leakage and theft from databases is a dangerous threat to organizations. Data Security and Data Privacy protection systems (DSDP) monitor data access and usage to identify leakage or suspicious activities that should be investigated. Because of the high velocity nature of database systems, such systems audit only a portion of the vast number of transactions that take place. Anomalies are investigated by a Security Officer (SO) in order to choose the proper response. In this paper we investigate the effect of sampling methods based on the risk the transaction poses and propose a new method for "combined sampling" for capturing a more varied sample.
Language Models with Pre-Trained (GloVe) Word Embeddings
Feb 05, 2017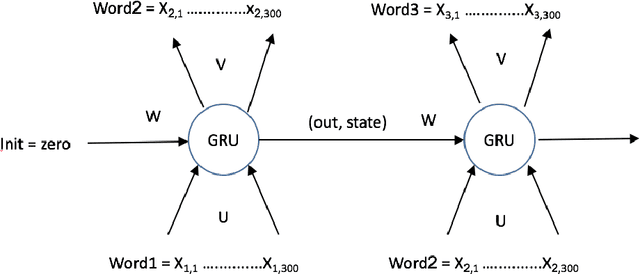
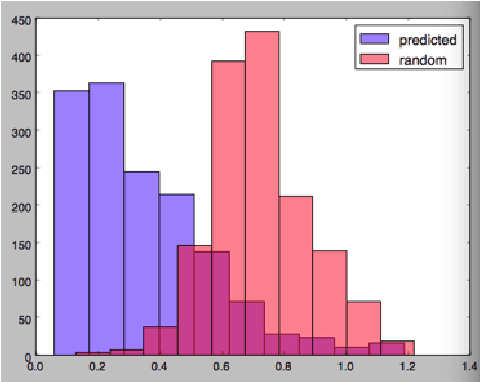
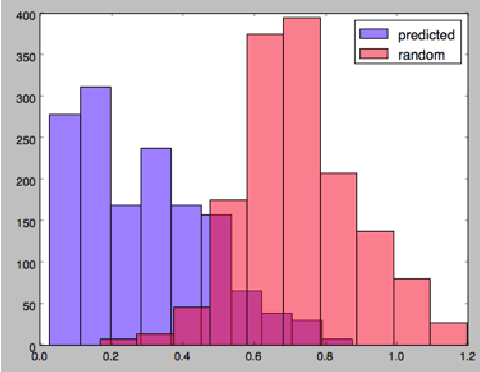
In this work we implement a training of a Language Model (LM), using Recurrent Neural Network (RNN) and GloVe word embeddings, introduced by Pennigton et al. in [1]. The implementation is following the general idea of training RNNs for LM tasks presented in [2], but is rather using Gated Recurrent Unit (GRU) [3] for a memory cell, and not the more commonly used LSTM [4].