 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDictionary learning for Kernel EDMD
Apr 28, 2026Studying nonlinear dynamical systems through their state space behavior can be challenging, and one possible alternative is to analyze them via their associated Koopman operator. This turns the nonlinear problem into a linear, infinite-dimensional one. To approximate the operator in finite dimensions, extended dynamic mode decomposition (EDMD) is a commonly used algorithm. It requires a finite list of functionals and a set of snapshots from the system to compute an approximation of the operator and its corresponding spectrum. Instead of choosing the list of functionals directly, it can be implicitly defined via kernels, a method known as kernel extended dynamic mode decomposition (kEDMD). However, one still needs to define the kernel and choose its parameter values. In this paper, we aim to streamline this process by extending dictionary learning for EDMD to kernel learning in kEDMD. By simplifying kEDMD we show how to perform gradient-based optimization over the learnable kernel parameters, and demonstrate that this method leads to useful kernels for the original kEDMD. The focus of our work is a method that takes a weighted list of kernels with randomly initialized values as input and outputs a list of kernels and parameter values suitable for approximating the Koopman operator of the underlying system. We demonstrate that unimportant kernels can be removed from the list by analyzing the weights in the weighted sum. We evaluate the method across several experiments, including the Duffing oscillator and the Kuramoto-Sivashinsky PDE, showcasing the method's different strengths.
Adaptive Kernel Selection for Kernelized Diffusion Maps
Apr 20, 2026Selecting an appropriate kernel is a central challenge in kernel-based spectral methods. In \emph{Kernelized Diffusion Maps} (KDM), the kernel determines the accuracy of the RKHS estimator of a diffusion-type operator and hence the quality and stability of the recovered eigenfunctions. We introduce two complementary approaches to adaptive kernel selection for KDM. First, we develop a variational outer loop that learns continuous kernel parameters, including bandwidths and mixture weights, by differentiating through the Cholesky-reduced KDM eigenproblem with an objective combining eigenvalue maximization, subspace orthonormality, and RKHS regularization. Second, we propose an unsupervised cross-validation pipeline that selects kernel families and bandwidths using an eigenvalue-sum criterion together with random Fourier features for scalability. Both methods share a common theoretical foundation: we prove Lipschitz dependence of KDM operators on kernel weights, continuity of spectral projectors under a gap condition, a residual-control theorem certifying proximity to the target eigenspace, and exponential consistency of the cross-validation selector over a finite kernel dictionary.
Kernel Methods for Stochastic Dynamical Systems with Application to Koopman Eigenfunctions: Feynman-Kac Representations and RKHS Approximation
Mar 01, 2026We extend the unified kernel framework for transport equations and Koopman eigenfunctions, developed in previous work by the authors for deterministic systems, to stochastic differential equations (SDEs). In the deterministic setting, three analytically grounded constructions-Lions-type variational principles, Green's function convolution, and resolvent operators along characteristic flows--were shown to yield identical reproducing kernels. For stochastic systems, the Koopman generator includes a second-order diffusion term, transforming the first-order hyperbolic transport equation into a second-order elliptic-parabolic PDE. This fundamental change necessitates replacing the method of characteristics with probabilistic representations based on the Feynman--Kac formula. Our main contributions include: (i) extension of all three kernel constructions to stochastic systems via Feynman--Kac path-integral representations; (ii) proof of kernel equivalence under uniform ellipticity assumptions; (iii) a collocation-based computational framework incorporating second-order differential operators; (iv) error bounds separating RKHS approximation error from Monte Carlo sampling error; (v) analysis of how diffusion affects numerical conditioning; and (vi) connections to generator EDMD, diffusion maps, and kernel analog forecasting. Numerical experiments on Ornstein--Uhlenbeck processes, nonlinear SDEs with varying diffusion strength, and multi-dimensional systems validate the theoretical developments and demonstrate that moderate diffusion can improve numerical stability through elliptic regularization.
Kernel Methods for the Approximation of the Eigenfunctions of the Koopman Operator
Dec 21, 2024



The Koopman operator provides a linear framework to study nonlinear dynamical systems. Its spectra offer valuable insights into system dynamics, but the operator can exhibit both discrete and continuous spectra, complicating direct computations. In this paper, we introduce a kernel-based method to construct the principal eigenfunctions of the Koopman operator without explicitly computing the operator itself. These principal eigenfunctions are associated with the equilibrium dynamics, and their eigenvalues match those of the linearization of the nonlinear system at the equilibrium point. We exploit the structure of the principal eigenfunctions by decomposing them into linear and nonlinear components. The linear part corresponds to the left eigenvector of the system's linearization at the equilibrium, while the nonlinear part is obtained by solving a partial differential equation (PDE) using kernel methods. Our approach avoids common issues such as spectral pollution and spurious eigenvalues, which can arise in previous methods. We demonstrate the effectiveness of our algorithm through numerical examples.
Kernel Sum of Squares for Data Adapted Kernel Learning of Dynamical Systems from Data: A global optimization approach
Aug 12, 2024



This paper examines the application of the Kernel Sum of Squares (KSOS) method for enhancing kernel learning from data, particularly in the context of dynamical systems. Traditional kernel-based methods, despite their theoretical soundness and numerical efficiency, frequently struggle with selecting optimal base kernels and parameter tuning, especially with gradient-based methods prone to local optima. KSOS mitigates these issues by leveraging a global optimization framework with kernel-based surrogate functions, thereby achieving more reliable and precise learning of dynamical systems. Through comprehensive numerical experiments on the Logistic Map, Henon Map, and Lorentz System, KSOS is shown to consistently outperform gradient descent in minimizing the relative-$\rho$ metric and improving kernel accuracy. These results highlight KSOS's effectiveness in predicting the behavior of chaotic dynamical systems, demonstrating its capability to adapt kernels to underlying dynamics and enhance the robustness and predictive power of kernel-based approaches, making it a valuable asset for time series analysis in various scientific fields.
Simplicity bias, algorithmic probability, and the random logistic map
Dec 31, 2023


Simplicity bias is an intriguing phenomenon prevalent in various input-output maps, characterized by a preference for simpler, more regular, or symmetric outputs. Notably, these maps typically feature high-probability outputs with simple patterns, whereas complex patterns are exponentially less probable. This bias has been extensively examined and attributed to principles derived from algorithmic information theory and algorithmic probability. In a significant advancement, it has been demonstrated that the renowned logistic map $x_{k+1}=\mu x_k(1-x_k)$, and other one-dimensional maps exhibit simplicity bias when conceptualized as input-output systems. Building upon this foundational work, our research delves into the manifestations of simplicity bias within the random logistic map, specifically focusing on scenarios involving additive noise. This investigation is driven by the overarching goal of formulating a comprehensive theory for the prediction and analysis of time series.Our primary contributions are multifaceted. We discover that simplicity bias is observable in the random logistic map for specific ranges of $\mu$ and noise magnitudes. Additionally, we find that this bias persists even with the introduction of small measurement noise, though it diminishes as noise levels increase. Our studies also revisit the phenomenon of noise-induced chaos, particularly when $\mu=3.83$, revealing its characteristics through complexity-probability plots. Intriguingly, we employ the logistic map to underscore a paradoxical aspect of data analysis: more data adhering to a consistent trend can occasionally lead to reduced confidence in extrapolation predictions, challenging conventional wisdom.We propose that adopting a probability-complexity perspective in analyzing dynamical systems could significantly enrich statistical learning theories related to series prediction.
Bridging Algorithmic Information Theory and Machine Learning: A New Approach to Kernel Learning
Nov 21, 2023Machine Learning (ML) and Algorithmic Information Theory (AIT) look at Complexity from different points of view. We explore the interface between AIT and Kernel Methods (that are prevalent in ML) by adopting an AIT perspective on the problem of learning kernels from data, in kernel ridge regression, through the method of Sparse Kernel Flows. In particular, by looking at the differences and commonalities between Minimal Description Length (MDL) and Regularization in Machine Learning (RML), we prove that the method of Sparse Kernel Flows is the natural approach to adopt to learn kernels from data. This paper shows that it is not necessary to use the statistical route to derive Sparse Kernel Flows and that one can directly work with code-lengths and complexities that are concepts that show up in AIT.
Learning Dynamical Systems from Data: A Simple Cross-Validation Perspective, Part V: Sparse Kernel Flows for 132 Chaotic Dynamical Systems
Jan 24, 2023



Regressing the vector field of a dynamical system from a finite number of observed states is a natural way to learn surrogate models for such systems. A simple and interpretable way to learn a dynamical system from data is to interpolate its vector-field with a data-adapted kernel which can be learned by using Kernel Flows. The method of Kernel Flows is a trainable machine learning method that learns the optimal parameters of a kernel based on the premise that a kernel is good if there is no significant loss in accuracy if half of the data is used. The objective function could be a short-term prediction or some other objective for other variants of Kernel Flows). However, this method is limited by the choice of the base kernel. In this paper, we introduce the method of \emph{Sparse Kernel Flows } in order to learn the ``best'' kernel by starting from a large dictionary of kernels. It is based on sparsifying a kernel that is a linear combination of elemental kernels. We apply this approach to a library of 132 chaotic systems.
One-Shot Learning of Stochastic Differential Equations with Computational Graph Completion
Sep 24, 2022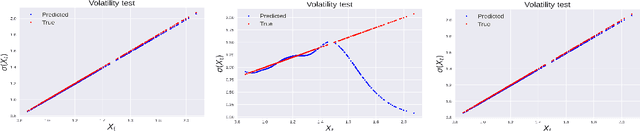

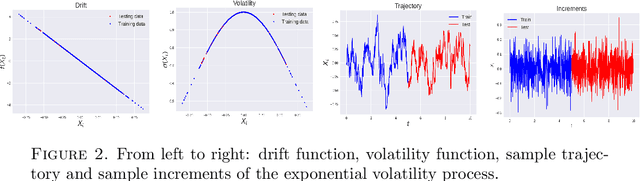

We consider the problem of learning Stochastic Differential Equations of the form $dX_t = f(X_t)dt+\sigma(X_t)dW_t $ from one sample trajectory. This problem is more challenging than learning deterministic dynamical systems because one sample trajectory only provides indirect information on the unknown functions $f$, $\sigma$, and stochastic process $dW_t$ representing the drift, the diffusion, and the stochastic forcing terms, respectively. We propose a simple kernel-based solution to this problem that can be decomposed as follows: (1) Represent the time-increment map $X_t \rightarrow X_{t+dt}$ as a Computational Graph in which $f$, $\sigma$ and $dW_t$ appear as unknown functions and random variables. (2) Complete the graph (approximate unknown functions and random variables) via Maximum a Posteriori Estimation (given the data) with Gaussian Process (GP) priors on the unknown functions. (3) Learn the covariance functions (kernels) of the GP priors from data with randomized cross-validation. Numerical experiments illustrate the efficacy, robustness, and scope of our method.
Learning dynamical systems from data: A simple cross-validation perspective, part III: Irregularly-Sampled Time Series
Nov 25, 2021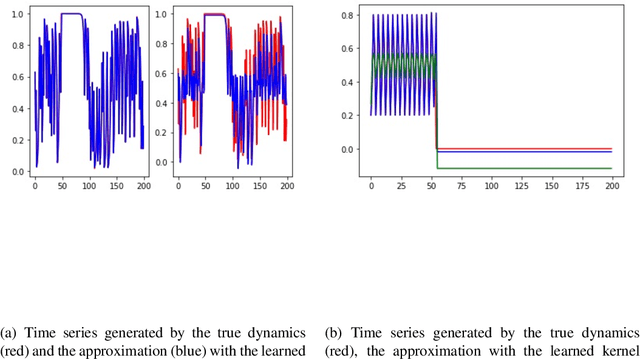
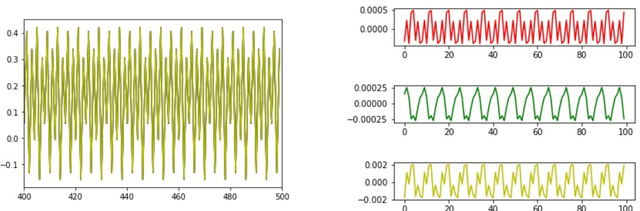
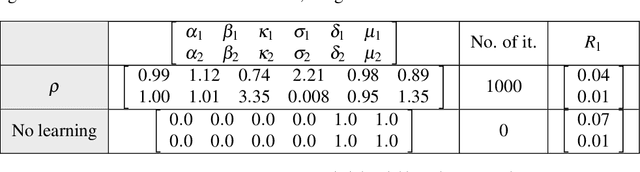

A simple and interpretable way to learn a dynamical system from data is to interpolate its vector-field with a kernel. In particular, this strategy is highly efficient (both in terms of accuracy and complexity) when the kernel is data-adapted using Kernel Flows (KF)~\cite{Owhadi19} (which uses gradient-based optimization to learn a kernel based on the premise that a kernel is good if there is no significant loss in accuracy if half of the data is used for interpolation). Despite its previous successes, this strategy (based on interpolating the vector field driving the dynamical system) breaks down when the observed time series is not regularly sampled in time. In this work, we propose to address this problem by directly approximating the vector field of the dynamical system by incorporating time differences between observations in the (KF) data-adapted kernels. We compare our approach with the classical one over different benchmark dynamical systems and show that it significantly improves the forecasting accuracy while remaining simple, fast, and robust.