 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Forecasting by Simulation Alone
Jan 02, 2026Zero-shot time-series forecasting holds great promise, but is still in its infancy, hindered by limited and biased data corpora, leakage-prone evaluation, and privacy and licensing constraints. Motivated by these challenges, we propose the first practical univariate time series simulation pipeline which is simultaneously fast enough for on-the-fly data generation and enables notable zero-shot forecasting performance on M-Series and GiftEval benchmarks that capture trend/seasonality/intermittency patterns, typical of industrial forecasting applications across a variety of domains. Our simulator, which we call SarSim0 (SARIMA Simulator for Zero-Shot Forecasting), is based off of a seasonal autoregressive integrated moving average (SARIMA) model as its core data source. Due to instability in the autoregressive component, naive SARIMA simulation often leads to unusable paths. Instead, we follow a three-step procedure: (1) we sample well-behaved trajectories from its characteristic polynomial stability region; (2) we introduce a superposition scheme that combines multiple paths into rich multi-seasonality traces; and (3) we add rate-based heavy-tailed noise models to capture burstiness and intermittency alongside seasonalities and trends. SarSim0 is orders of magnitude faster than kernel-based generators, and it enables training on circa 1B unique purely simulated series, generated on the fly; after which well-established neural network backbones exhibit strong zero-shot generalization, surpassing strong statistical forecasters and recent foundation baselines, while operating under strict zero-shot protocol. Notably, on GiftEval we observe a "student-beats-teacher" effect: models trained on our simulations exceed the forecasting accuracy of the AutoARIMA generating processes.
SKOLR: Structured Koopman Operator Linear RNN for Time-Series Forecasting
Jun 17, 2025Koopman operator theory provides a framework for nonlinear dynamical system analysis and time-series forecasting by mapping dynamics to a space of real-valued measurement functions, enabling a linear operator representation. Despite the advantage of linearity, the operator is generally infinite-dimensional. Therefore, the objective is to learn measurement functions that yield a tractable finite-dimensional Koopman operator approximation. In this work, we establish a connection between Koopman operator approximation and linear Recurrent Neural Networks (RNNs), which have recently demonstrated remarkable success in sequence modeling. We show that by considering an extended state consisting of lagged observations, we can establish an equivalence between a structured Koopman operator and linear RNN updates. Building on this connection, we present SKOLR, which integrates a learnable spectral decomposition of the input signal with a multilayer perceptron (MLP) as the measurement functions and implements a structured Koopman operator via a highly parallel linear RNN stack. Numerical experiments on various forecasting benchmarks and dynamical systems show that this streamlined, Koopman-theory-based design delivers exceptional performance.
Enhanced N-BEATS for Mid-Term Electricity Demand Forecasting
Dec 02, 2024This paper presents an enhanced N-BEATS model, N-BEATS*, for improved mid-term electricity load forecasting (MTLF). Building on the strengths of the original N-BEATS architecture, which excels in handling complex time series data without requiring preprocessing or domain-specific knowledge, N-BEATS* introduces two key modifications. (1) A novel loss function -- combining pinball loss based on MAPE with normalized MSE, the new loss function allows for a more balanced approach by capturing both L1 and L2 loss terms. (2) A modified block architecture -- the internal structure of the N-BEATS blocks is adjusted by introducing a destandardization component to harmonize the processing of different time series, leading to more efficient and less complex forecasting tasks. Evaluated on real-world monthly electricity consumption data from 35 European countries, N-BEATS* demonstrates superior performance compared to its predecessor and other established forecasting methods, including statistical, machine learning, and hybrid models. N-BEATS* achieves the lowest MAPE and RMSE, while also exhibiting the lowest dispersion in forecast errors.
Dynamic layer selection in decoder-only transformers
Oct 26, 2024The vast size of Large Language Models (LLMs) has prompted a search to optimize inference. One effective approach is dynamic inference, which adapts the architecture to the sample-at-hand to reduce the overall computational cost. We empirically examine two common dynamic inference methods for natural language generation (NLG): layer skipping and early exiting. We find that a pre-trained decoder-only model is significantly more robust to layer removal via layer skipping, as opposed to early exit. We demonstrate the difficulty of using hidden state information to adapt computation on a per-token basis for layer skipping. Finally, we show that dynamic computation allocation on a per-sequence basis holds promise for significant efficiency gains by constructing an oracle controller. Remarkably, we find that there exists an allocation which achieves equal performance to the full model using only 23.3% of its layers on average.
MODL: Multilearner Online Deep Learning
May 28, 2024



Online deep learning solves the problem of learning from streams of data, reconciling two opposing objectives: learn fast and learn deep. Existing work focuses almost exclusively on exploring pure deep learning solutions, which are much better suited to handle the "deep" than the "fast" part of the online learning equation. In our work, we propose a different paradigm, based on a hybrid multilearner approach. First, we develop a fast online logistic regression learner. This learner does not rely on backpropagation. Instead, it uses closed form recursive updates of model parameters, handling the fast learning part of the online learning problem. We then analyze the existing online deep learning theory and show that the widespread ODL approach, currently operating at complexity $O(L^2)$ in terms of the number of layers $L$, can be equivalently implemented in $O(L)$ complexity. This further leads us to the cascaded multilearner design, in which multiple shallow and deep learners are co-trained to solve the online learning problem in a cooperative, synergistic fashion. We show that this approach achieves state-of-the-art results on common online learning datasets, while also being able to handle missing features gracefully. Our code is publicly available at https://github.com/AntonValk/MODL.
Any-Quantile Probabilistic Forecasting of Short-Term Electricity Demand
Apr 26, 2024



Power systems operate under uncertainty originating from multiple factors that are impossible to account for deterministically. Distributional forecasting is used to control and mitigate risks associated with this uncertainty. Recent progress in deep learning has helped to significantly improve the accuracy of point forecasts, while accurate distributional forecasting still presents a significant challenge. In this paper, we propose a novel general approach for distributional forecasting capable of predicting arbitrary quantiles. We show that our general approach can be seamlessly applied to two distinct neural architectures leading to the state-of-the-art distributional forecasting results in the context of short-term electricity demand forecasting task. We empirically validate our method on 35 hourly electricity demand time-series for European countries. Our code is available here: https://github.com/boreshkinai/any-quantile.
3D Human Pose and Shape Estimation via HybrIK-Transformer
Feb 20, 2023HybrIK relies on a combination of analytical inverse kinematics and deep learning to produce more accurate 3D pose estimation from 2D monocular images. HybrIK has three major components: (1) pretrained convolution backbone, (2) deconvolution to lift 3D pose from 2D convolution features, (3) analytical inverse kinematics pass correcting deep learning prediction using learned distribution of plausible twist and swing angles. In this paper we propose an enhancement of the 2D to 3D lifting module, replacing deconvolution with Transformer, resulting in accuracy and computational efficiency improvement relative to the original HybrIK method. We demonstrate our results on commonly used H36M, PW3D, COCO and HP3D datasets. Our code is publicly available https://github.com/boreshkinai/hybrik-transformer.
SMPL-IK: Learned Morphology-Aware Inverse Kinematics for AI Driven Artistic Workflows
Aug 16, 2022
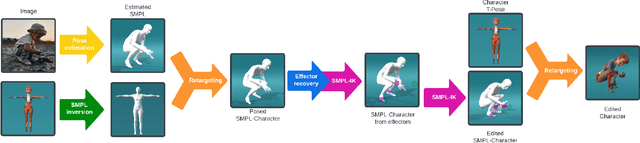


Inverse Kinematics (IK) systems are often rigid with respect to their input character, thus requiring user intervention to be adapted to new skeletons. In this paper we aim at creating a flexible, learned IK solver applicable to a wide variety of human morphologies. We extend a state-of-the-art machine learning IK solver to operate on the well known Skinned Multi-Person Linear model (SMPL). We call our model SMPL-IK, and show that when integrated into real-time 3D software, this extended system opens up opportunities for defining novel AI-assisted animation workflows. For example, pose authoring can be made more flexible with SMPL-IK by allowing users to modify gender and body shape while posing a character. Additionally, when chained with existing pose estimation algorithms, SMPL-IK accelerates posing by allowing users to bootstrap 3D scenes from 2D images while allowing for further editing. Finally, we propose a novel SMPL Shape Inversion mechanism (SMPL-SI) to map arbitrary humanoid characters to the SMPL space, allowing artists to leverage SMPL-IK on custom characters. In addition to qualitative demos showing proposed tools, we present quantitative SMPL-IK baselines on the H36M and AMASS datasets.
N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting
Feb 02, 2022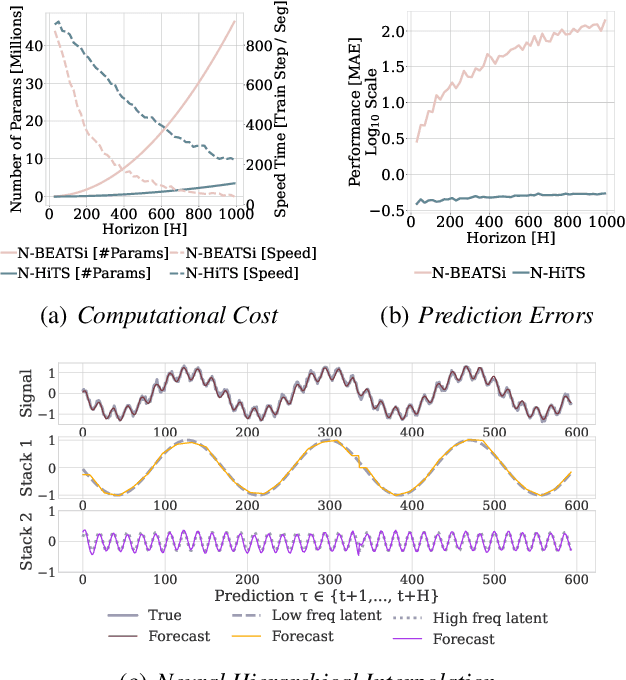
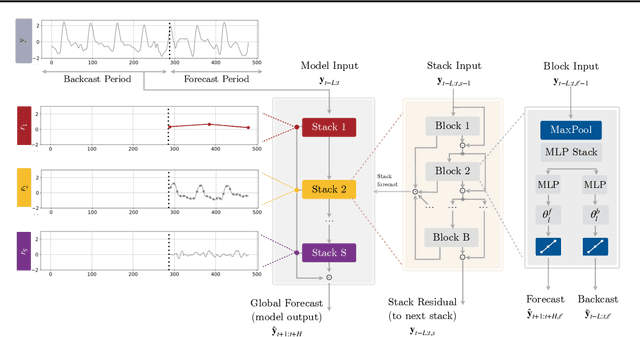
Recent progress in neural forecasting accelerated improvements in the performance of large-scale forecasting systems. Yet, long-horizon forecasting remains a very difficult task. Two common challenges afflicting long-horizon forecasting are the volatility of the predictions and their computational complexity. In this paper, we introduce N-HiTS, a model which addresses both challenges by incorporating novel hierarchical interpolation and multi-rate data sampling techniques. These techniques enable the proposed method to assemble its predictions sequentially, selectively emphasizing components with different frequencies and scales, while decomposing the input signal and synthesizing the forecast. We conduct an extensive empirical evaluation demonstrating the advantages of N-HiTS over the state-of-the-art long-horizon forecasting methods. On an array of multivariate forecasting tasks, the proposed method provides an average accuracy improvement of 25% over the latest Transformer architectures while reducing the computation time by an order of magnitude. Our code is available at https://github.com/cchallu/n-hits.
Motion Inbetweening via Deep $Δ$-Interpolator
Jan 27, 2022
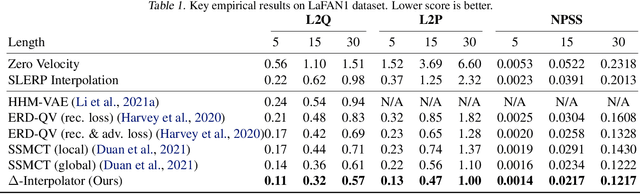
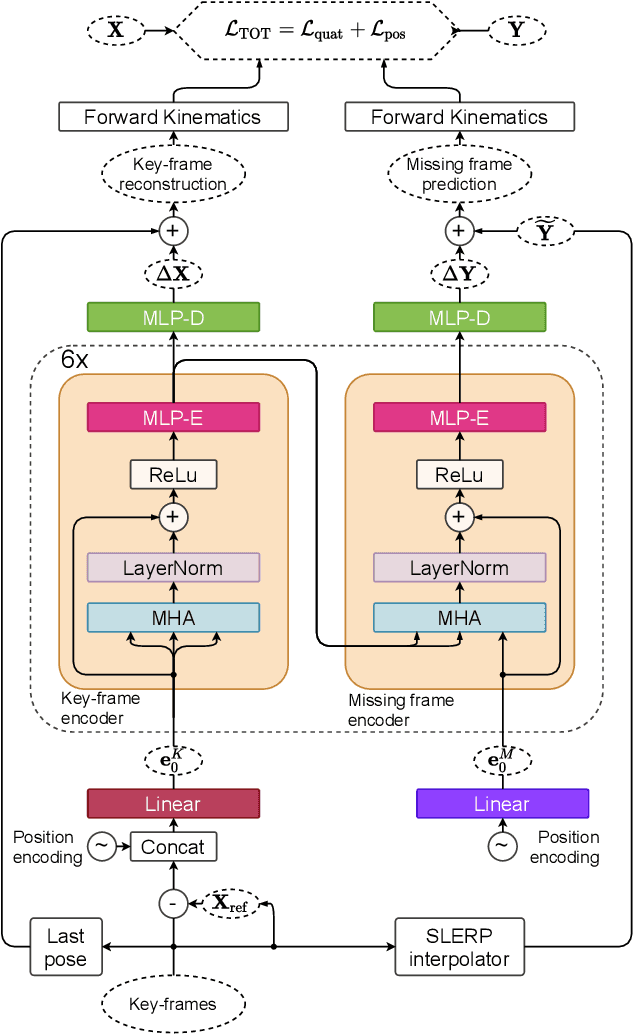
We show that the task of synthesizing missing middle frames, commonly known as motion in-betweening in the animation industry, can be solved more accurately and effectively if a deep learning interpolator operates in the delta mode, using the spherical linear interpolator as a baseline. We demonstrate our empirical findings on the publicly available LaFAN1 dataset. We further generalize this result by showing that the $\Delta$-regime is viable with respect to the reference of the last known frame (also known as the zero-velocity model). This supports the more general conclusion that deep in-betweening in the reference frame local to input frames is more accurate and robust than in-betweening in the global (world) reference frame advocated in previous work. Our code is publicly available at https://github.com/boreshkinai/delta-interpolator.