 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Distribution Learning for Unsupervised Text-to-Image Generation
Mar 28, 2023



We propose a text-to-image generation algorithm based on deep neural networks when text captions for images are unavailable during training. In this work, instead of simply generating pseudo-ground-truth sentences of training images using existing image captioning methods, we employ a pretrained CLIP model, which is capable of properly aligning embeddings of images and corresponding texts in a joint space and, consequently, works well on zero-shot recognition tasks. We optimize a text-to-image generation model by maximizing the data log-likelihood conditioned on pairs of image-text CLIP embeddings. To better align data in the two domains, we employ a principled way based on a variational inference, which efficiently estimates an approximate posterior of the hidden text embedding given an image and its CLIP feature. Experimental results validate that the proposed framework outperforms existing approaches by large margins under unsupervised and semi-supervised text-to-image generation settings.
Information-Theoretic GAN Compression with Variational Energy-based Model
Mar 28, 2023



We propose an information-theoretic knowledge distillation approach for the compression of generative adversarial networks, which aims to maximize the mutual information between teacher and student networks via a variational optimization based on an energy-based model. Because the direct computation of the mutual information in continuous domains is intractable, our approach alternatively optimizes the student network by maximizing the variational lower bound of the mutual information. To achieve a tight lower bound, we introduce an energy-based model relying on a deep neural network to represent a flexible variational distribution that deals with high-dimensional images and consider spatial dependencies between pixels, effectively. Since the proposed method is a generic optimization algorithm, it can be conveniently incorporated into arbitrary generative adversarial networks and even dense prediction networks, e.g., image enhancement models. We demonstrate that the proposed algorithm achieves outstanding performance in model compression of generative adversarial networks consistently when combined with several existing models.
Online Backfilling with No Regret for Large-Scale Image Retrieval
Jan 10, 2023Backfilling is the process of re-extracting all gallery embeddings from upgraded models in image retrieval systems. It inevitably requires a prohibitively large amount of computational cost and even entails the downtime of the service. Although backward-compatible learning sidesteps this challenge by tackling query-side representations, this leads to suboptimal solutions in principle because gallery embeddings cannot benefit from model upgrades. We address this dilemma by introducing an online backfilling algorithm, which enables us to achieve a progressive performance improvement during the backfilling process while not sacrificing the final performance of new model after the completion of backfilling. To this end, we first propose a simple distance rank merge technique for online backfilling. Then, we incorporate a reverse transformation module for more effective and efficient merging, which is further enhanced by adopting a metric-compatible contrastive learning approach. These two components help to make the distances of old and new models compatible, resulting in desirable merge results during backfilling with no extra computational overhead. Extensive experiments show the effectiveness of our framework on four standard benchmarks in various settings.
Towards Sequence-Level Training for Visual Tracking
Aug 11, 2022
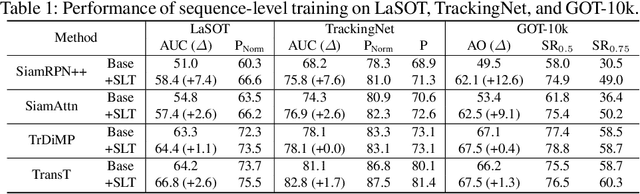
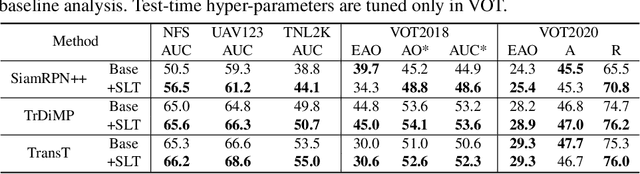

Despite the extensive adoption of machine learning on the task of visual object tracking, recent learning-based approaches have largely overlooked the fact that visual tracking is a sequence-level task in its nature; they rely heavily on frame-level training, which inevitably induces inconsistency between training and testing in terms of both data distributions and task objectives. This work introduces a sequence-level training strategy for visual tracking based on reinforcement learning and discusses how a sequence-level design of data sampling, learning objectives, and data augmentation can improve the accuracy and robustness of tracking algorithms. Our experiments on standard benchmarks including LaSOT, TrackingNet, and GOT-10k demonstrate that four representative tracking models, SiamRPN++, SiamAttn, TransT, and TrDiMP, consistently improve by incorporating the proposed methods in training without modifying architectures.
Multi-Level Branched Regularization for Federated Learning
Jul 14, 2022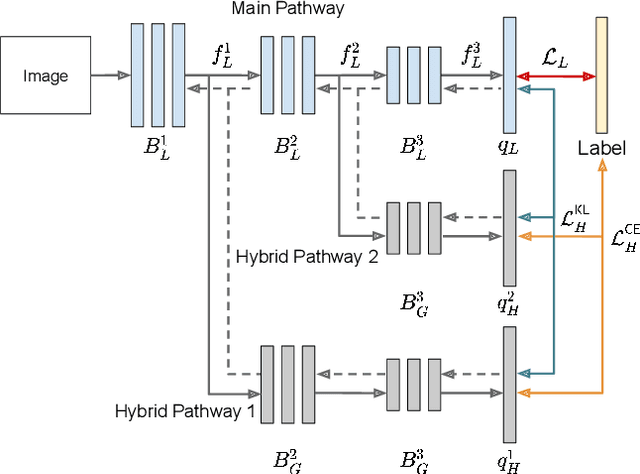
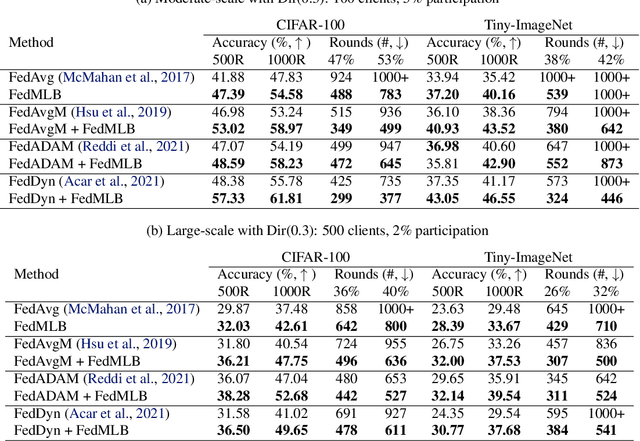
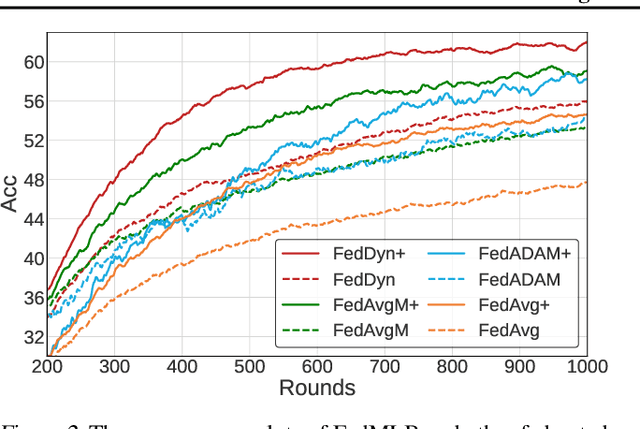
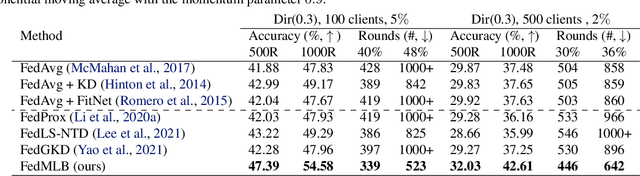
A critical challenge of federated learning is data heterogeneity and imbalance across clients, which leads to inconsistency between local networks and unstable convergence of global models. To alleviate the limitations, we propose a novel architectural regularization technique that constructs multiple auxiliary branches in each local model by grafting local and global subnetworks at several different levels and that learns the representations of the main pathway in the local model congruent to the auxiliary hybrid pathways via online knowledge distillation. The proposed technique is effective to robustify the global model even in the non-iid setting and is applicable to various federated learning frameworks conveniently without incurring extra communication costs. We perform comprehensive empirical studies and demonstrate remarkable performance gains in terms of accuracy and efficiency compared to existing methods. The source code is available at our project page.
Pooling Revisited: Your Receptive Field is Suboptimal
May 30, 2022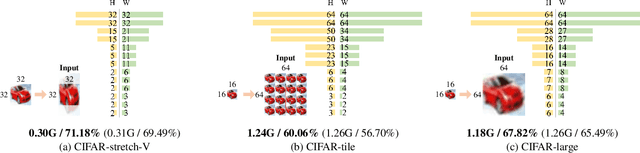
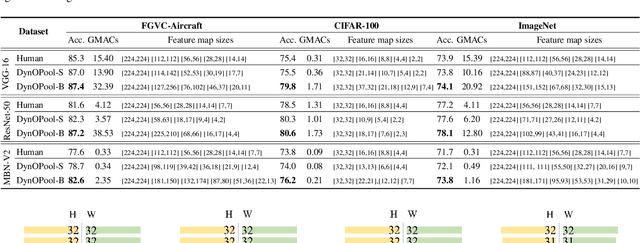
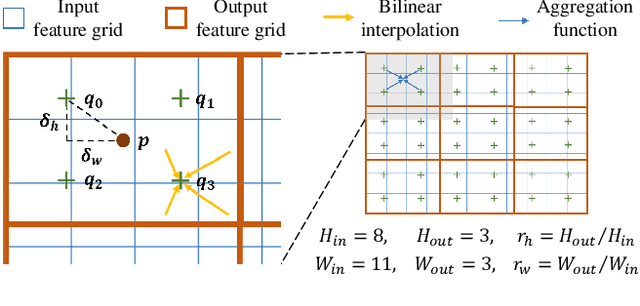
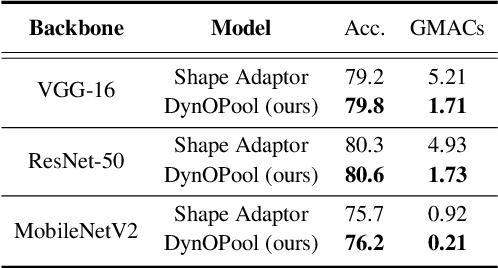
The size and shape of the receptive field determine how the network aggregates local information and affect the overall performance of a model considerably. Many components in a neural network, such as kernel sizes and strides for convolution and pooling operations, influence the configuration of a receptive field. However, they still rely on hyperparameters, and the receptive fields of existing models result in suboptimal shapes and sizes. Hence, we propose a simple yet effective Dynamically Optimized Pooling operation, referred to as DynOPool, which optimizes the scale factors of feature maps end-to-end by learning the desirable size and shape of its receptive field in each layer. Any kind of resizing modules in a deep neural network can be replaced by the operations with DynOPool at a minimal cost. Also, DynOPool controls the complexity of a model by introducing an additional loss term that constrains computational cost. Our experiments show that the models equipped with the proposed learnable resizing module outperform the baseline networks on multiple datasets in image classification and semantic segmentation.
Online Hybrid Lightweight Representations Learning: Its Application to Visual Tracking
May 23, 2022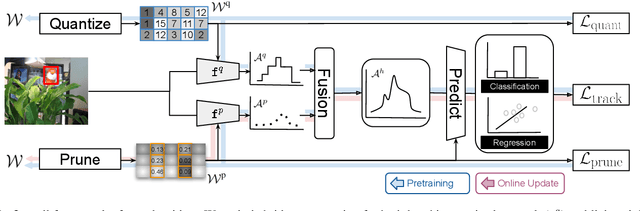
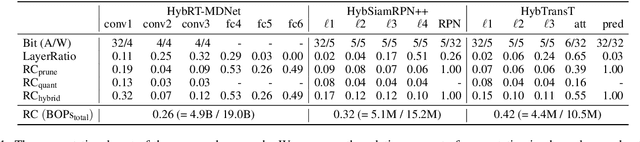
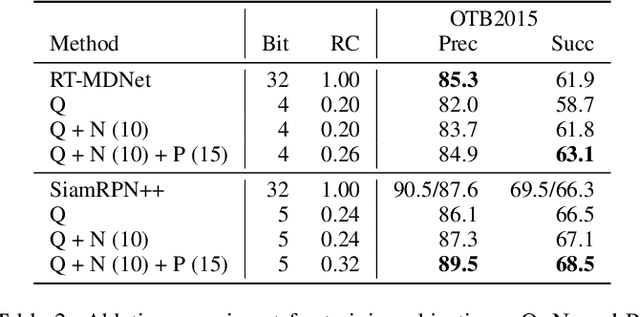
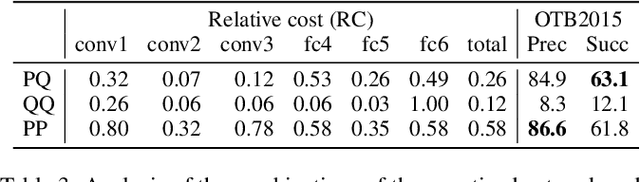
This paper presents a novel hybrid representation learning framework for streaming data, where an image frame in a video is modeled by an ensemble of two distinct deep neural networks; one is a low-bit quantized network and the other is a lightweight full-precision network. The former learns coarse primary information with low cost while the latter conveys residual information for high fidelity to original representations. The proposed parallel architecture is effective to maintain complementary information since fixed-point arithmetic can be utilized in the quantized network and the lightweight model provides precise representations given by a compact channel-pruned network. We incorporate the hybrid representation technique into an online visual tracking task, where deep neural networks need to handle temporal variations of target appearances in real-time. Compared to the state-of-the-art real-time trackers based on conventional deep neural networks, our tracking algorithm demonstrates competitive accuracy on the standard benchmarks with a small fraction of computational cost and memory footprint.
Class-Incremental Learning by Knowledge Distillation with Adaptive Feature Consolidation
Apr 02, 2022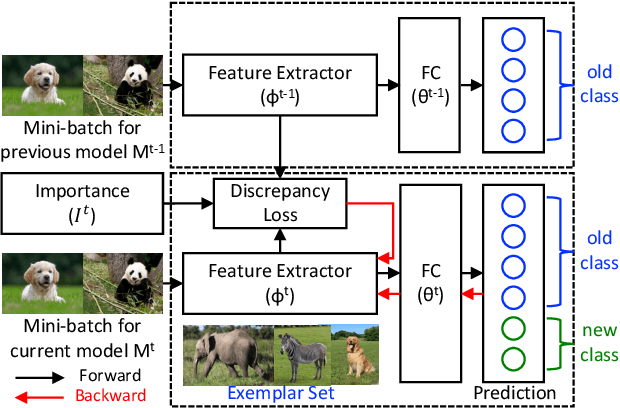
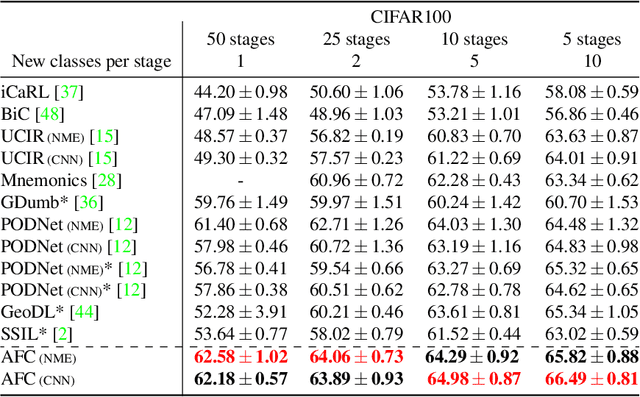
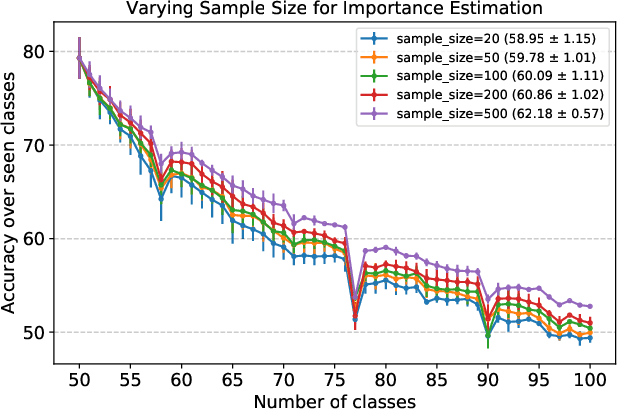
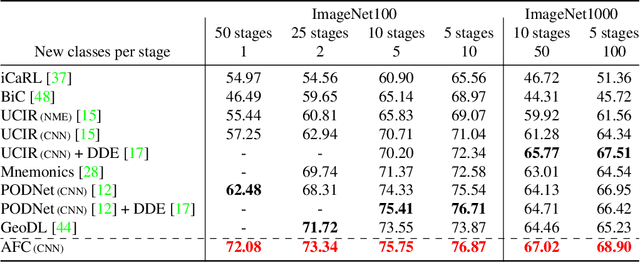
We present a novel class incremental learning approach based on deep neural networks, which continually learns new tasks with limited memory for storing examples in the previous tasks. Our algorithm is based on knowledge distillation and provides a principled way to maintain the representations of old models while adjusting to new tasks effectively. The proposed method estimates the relationship between the representation changes and the resulting loss increases incurred by model updates. It minimizes the upper bound of the loss increases using the representations, which exploits the estimated importance of each feature map within a backbone model. Based on the importance, the model restricts updates of important features for robustness while allowing changes in less critical features for flexibility. This optimization strategy effectively alleviates the notorious catastrophic forgetting problem despite the limited accessibility of data in the previous tasks. The experimental results show significant accuracy improvement of the proposed algorithm over the existing methods on the standard datasets. Code is available.
Class-Incremental Learning for Action Recognition in Videos
Mar 25, 2022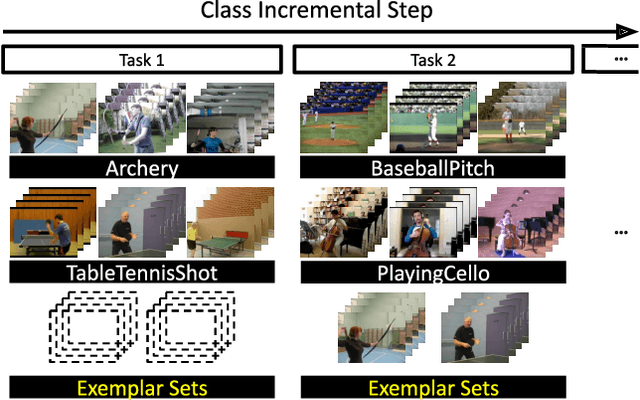
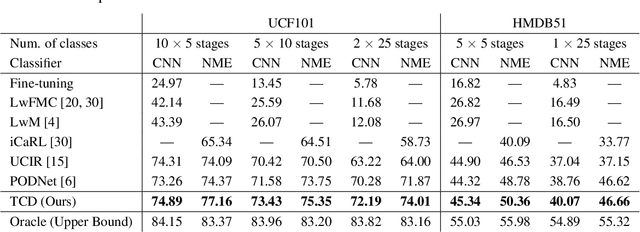

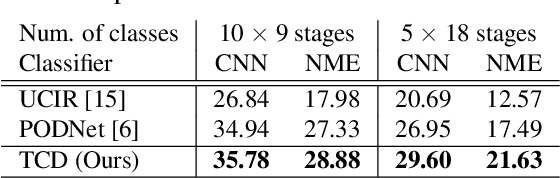
We tackle catastrophic forgetting problem in the context of class-incremental learning for video recognition, which has not been explored actively despite the popularity of continual learning. Our framework addresses this challenging task by introducing time-channel importance maps and exploiting the importance maps for learning the representations of incoming examples via knowledge distillation. We also incorporate a regularization scheme in our objective function, which encourages individual features obtained from different time steps in a video to be uncorrelated and eventually improves accuracy by alleviating catastrophic forgetting. We evaluate the proposed approach on brand-new splits of class-incremental action recognition benchmarks constructed upon the UCF101, HMDB51, and Something-Something V2 datasets, and demonstrate the effectiveness of our algorithm in comparison to the existing continual learning methods that are originally designed for image data.
Learning to Adapt to Unseen Abnormal Activities under Weak Supervision
Mar 25, 2022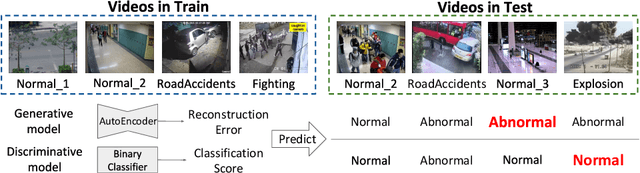

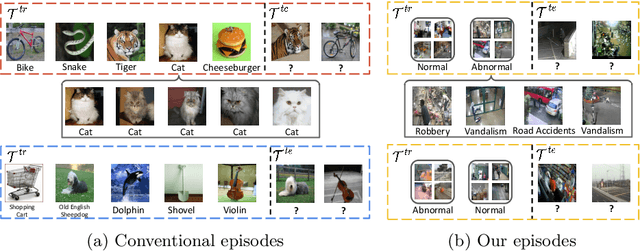
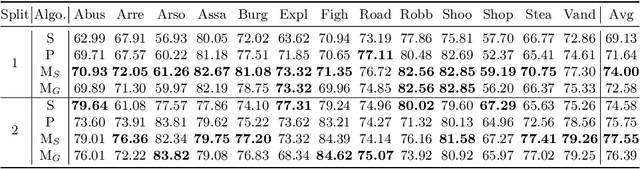
We present a meta-learning framework for weakly supervised anomaly detection in videos, where the detector learns to adapt to unseen types of abnormal activities effectively when only video-level annotations of binary labels are available. Our work is motivated by the fact that existing methods suffer from poor generalization to diverse unseen examples. We claim that an anomaly detector equipped with a meta-learning scheme alleviates the limitation by leading the model to an initialization point for better optimization. We evaluate the performance of our framework on two challenging datasets, UCF-Crime and ShanghaiTech. The experimental results demonstrate that our algorithm boosts the capability to localize unseen abnormal events in a weakly supervised setting. Besides the technical contributions, we perform the annotation of missing labels in the UCF-Crime dataset and make our task evaluated effectively.