 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Efficient Use of Demonstrations to Solve Hard Exploration Problems
Sep 03, 2019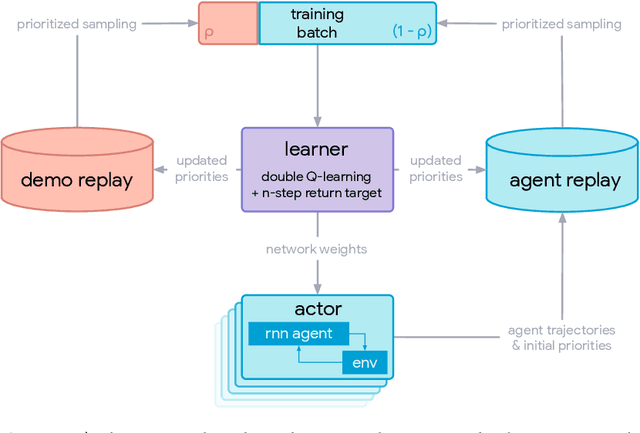
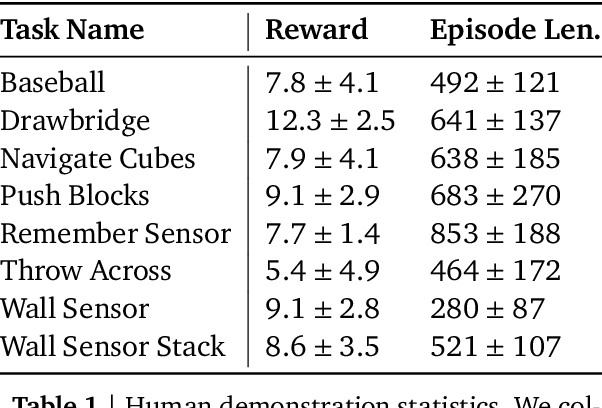
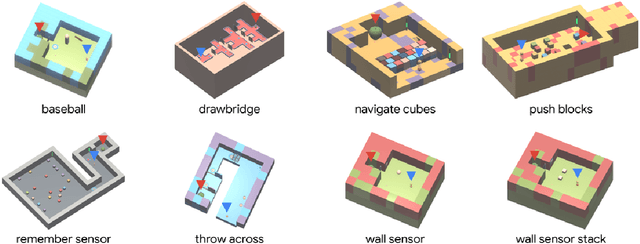
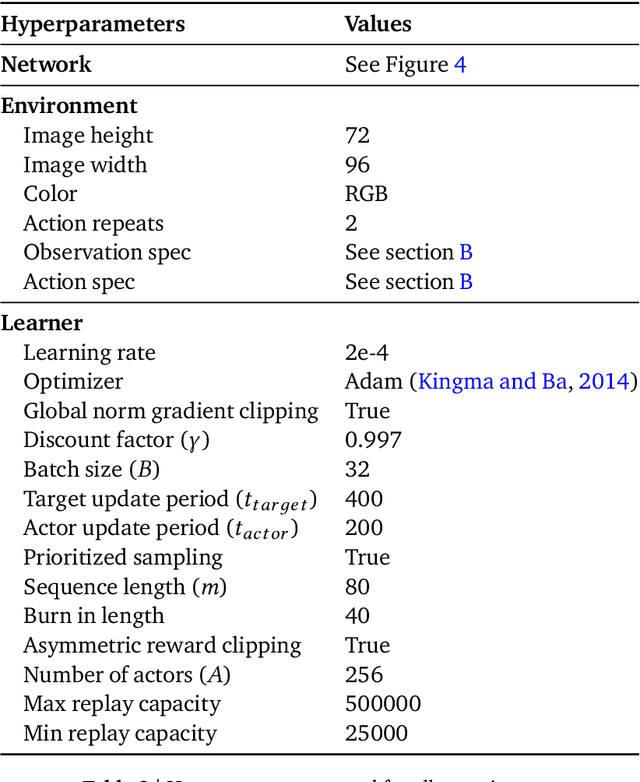
This paper introduces R2D3, an agent that makes efficient use of demonstrations to solve hard exploration problems in partially observable environments with highly variable initial conditions. We also introduce a suite of eight tasks that combine these three properties, and show that R2D3 can solve several of the tasks where other state of the art methods (both with and without demonstrations) fail to see even a single successful trajectory after tens of billions of steps of exploration.
Which Learning Algorithms Can Generalize Identity-Based Rules to Novel Inputs?
May 12, 2016
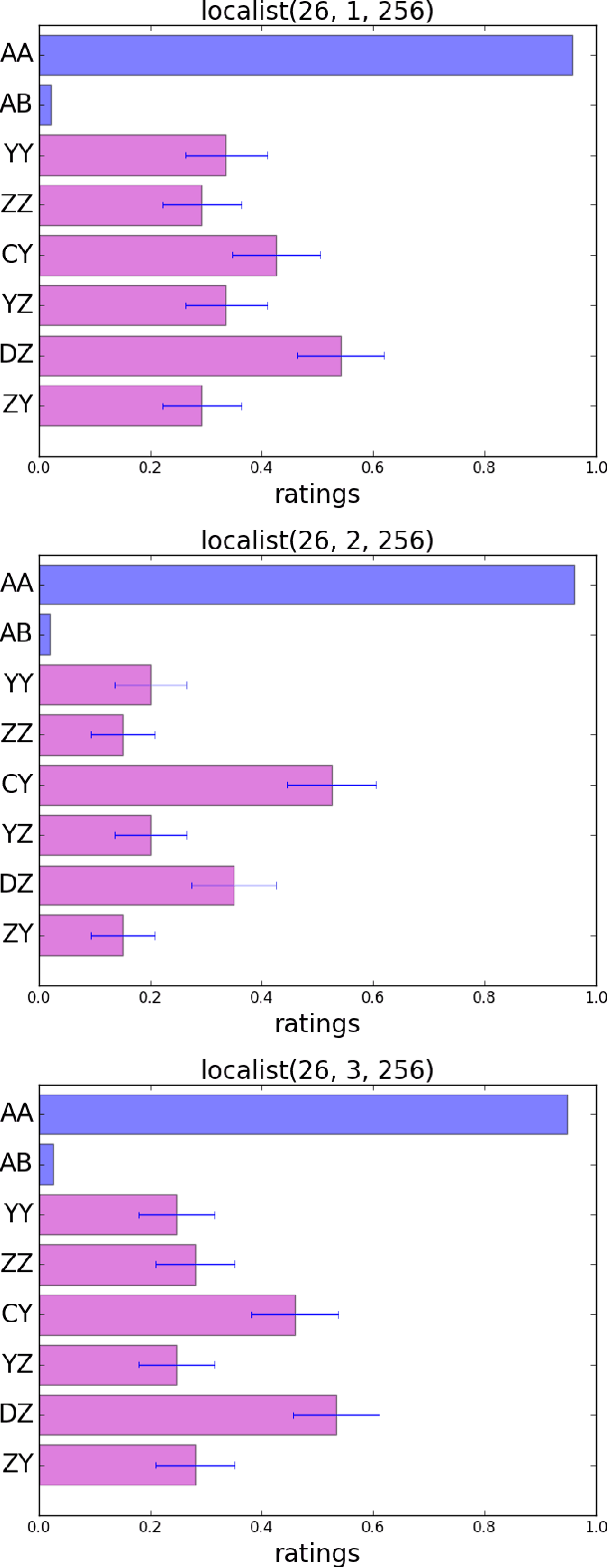
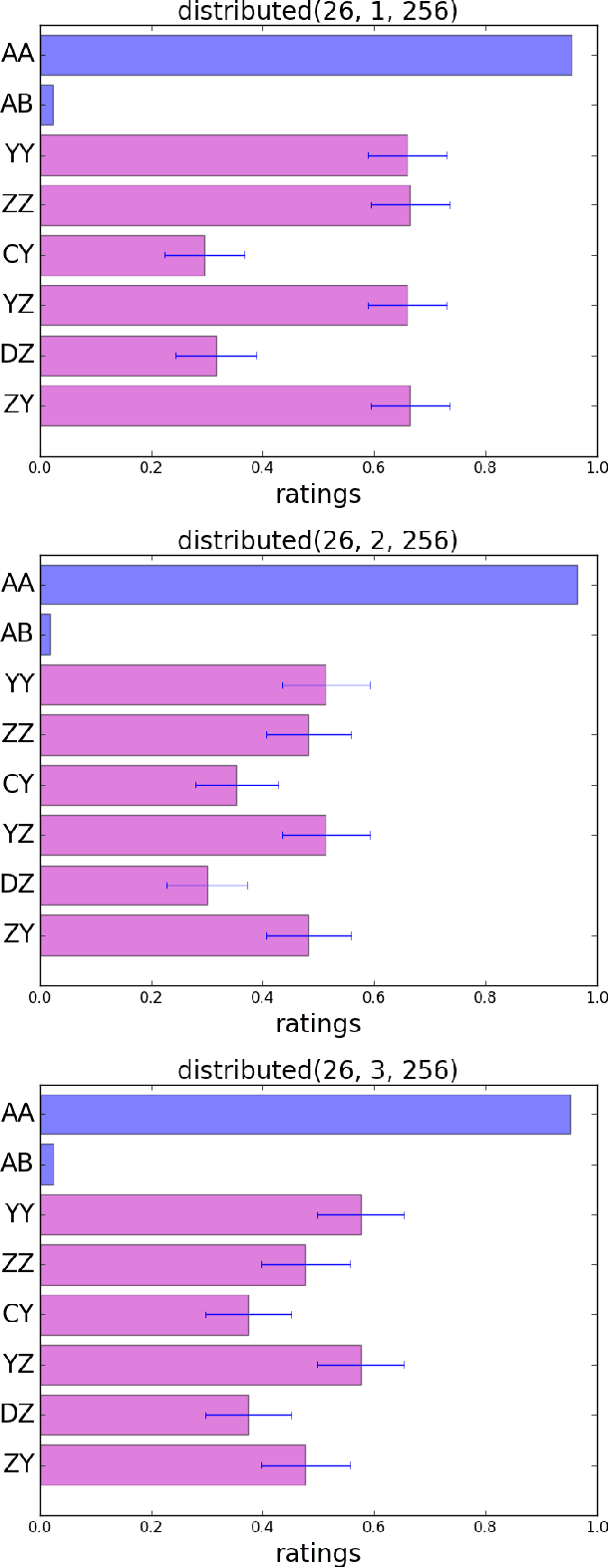
We propose a novel framework for the analysis of learning algorithms that allows us to say when such algorithms can and cannot generalize certain patterns from training data to test data. In particular we focus on situations where the rule that must be learned concerns two components of a stimulus being identical. We call such a basis for discrimination an identity-based rule. Identity-based rules have proven to be difficult or impossible for certain types of learning algorithms to acquire from limited datasets. This is in contrast to human behaviour on similar tasks. Here we provide a framework for rigorously establishing which learning algorithms will fail at generalizing identity-based rules to novel stimuli. We use this framework to show that such algorithms are unable to generalize identity-based rules to novel inputs unless trained on virtually all possible inputs. We demonstrate these results computationally with a multilayer feedforward neural network.
Unbounded Bayesian Optimization via Regularization
Aug 14, 2015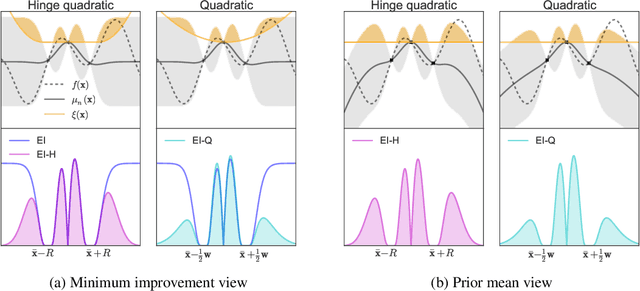
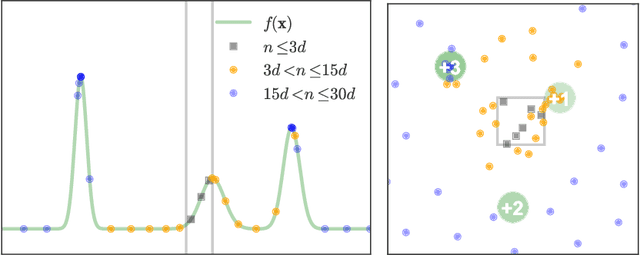
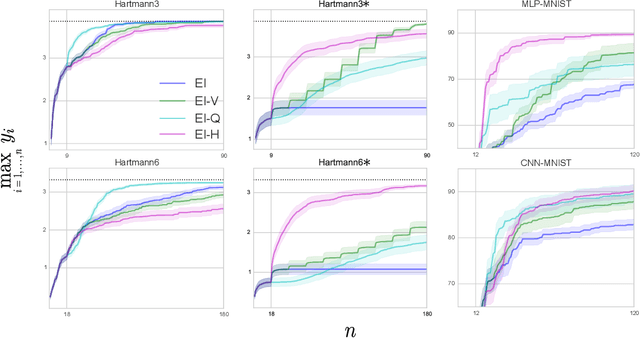
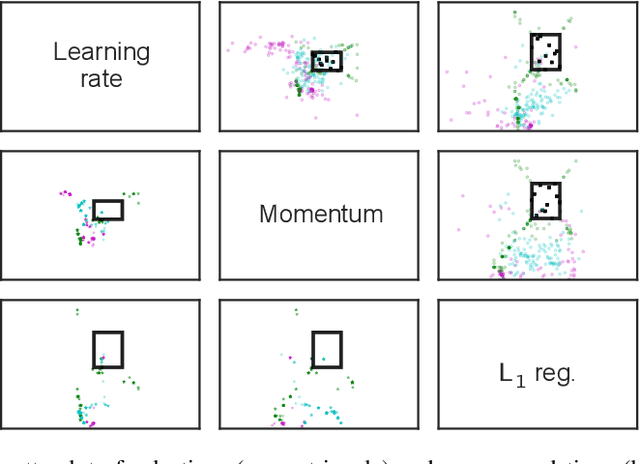
Bayesian optimization has recently emerged as a popular and efficient tool for global optimization and hyperparameter tuning. Currently, the established Bayesian optimization practice requires a user-defined bounding box which is assumed to contain the optimizer. However, when little is known about the probed objective function, it can be difficult to prescribe such bounds. In this work we modify the standard Bayesian optimization framework in a principled way to allow automatic resizing of the search space. We introduce two alternative methods and compare them on two common synthetic benchmarking test functions as well as the tasks of tuning the stochastic gradient descent optimizer of a multi-layered perceptron and a convolutional neural network on MNIST.
An Entropy Search Portfolio for Bayesian Optimization
Mar 04, 2015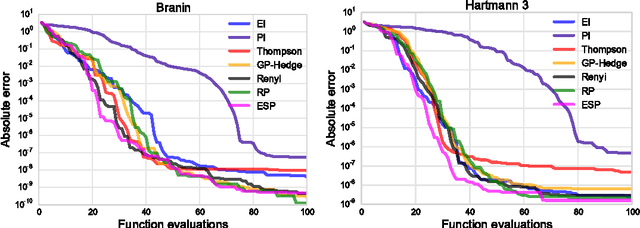
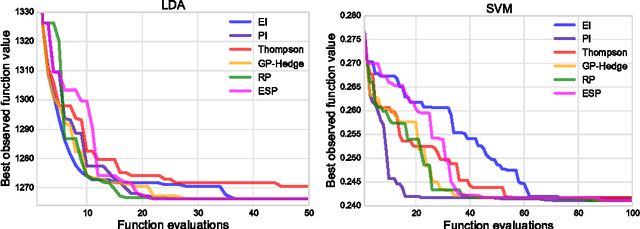
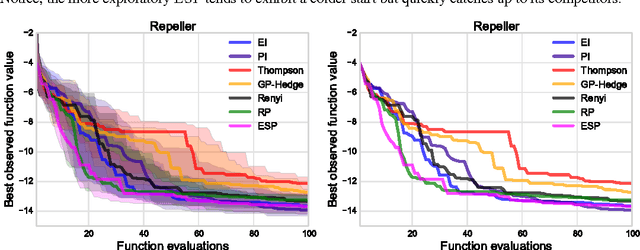
Bayesian optimization is a sample-efficient method for black-box global optimization. How- ever, the performance of a Bayesian optimization method very much depends on its exploration strategy, i.e. the choice of acquisition function, and it is not clear a priori which choice will result in superior performance. While portfolio methods provide an effective, principled way of combining a collection of acquisition functions, they are often based on measures of past performance which can be misleading. To address this issue, we introduce the Entropy Search Portfolio (ESP): a novel approach to portfolio construction which is motivated by information theoretic considerations. We show that ESP outperforms existing portfolio methods on several real and synthetic problems, including geostatistical datasets and simulated control tasks. We not only show that ESP is able to offer performance as good as the best, but unknown, acquisition function, but surprisingly it often gives better performance. Finally, over a wide range of conditions we find that ESP is robust to the inclusion of poor acquisition functions.
Heteroscedastic Treed Bayesian Optimisation
Mar 04, 2015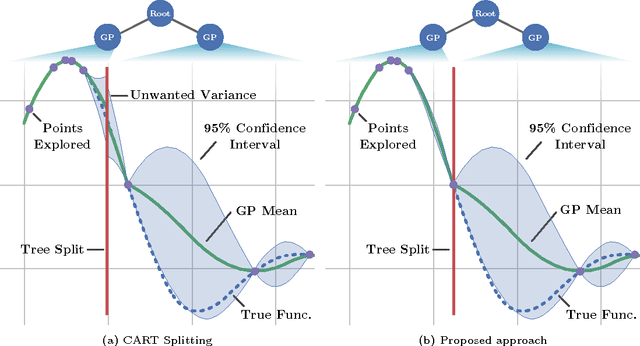
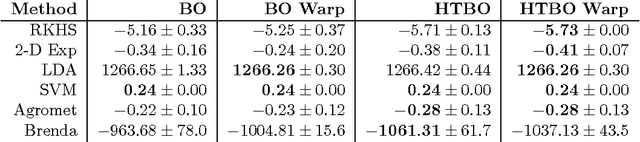
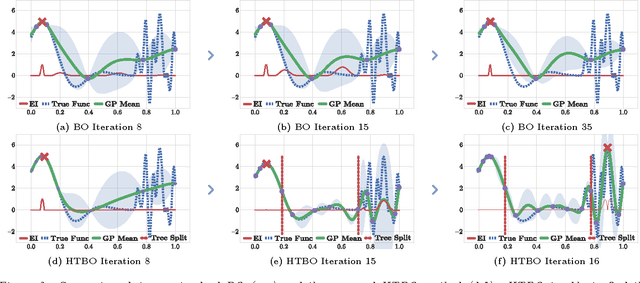
Optimising black-box functions is important in many disciplines, such as tuning machine learning models, robotics, finance and mining exploration. Bayesian optimisation is a state-of-the-art technique for the global optimisation of black-box functions which are expensive to evaluate. At the core of this approach is a Gaussian process prior that captures our belief about the distribution over functions. However, in many cases a single Gaussian process is not flexible enough to capture non-stationarity in the objective function. Consequently, heteroscedasticity negatively affects performance of traditional Bayesian methods. In this paper, we propose a novel prior model with hierarchical parameter learning that tackles the problem of non-stationarity in Bayesian optimisation. Our results demonstrate substantial improvements in a wide range of applications, including automatic machine learning and mining exploration.
Exploiting correlation and budget constraints in Bayesian multi-armed bandit optimization
Nov 11, 2013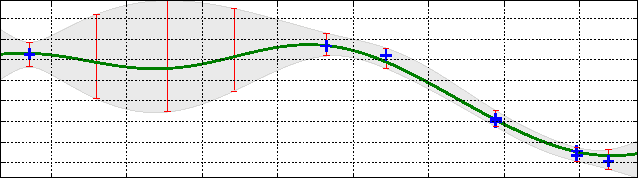
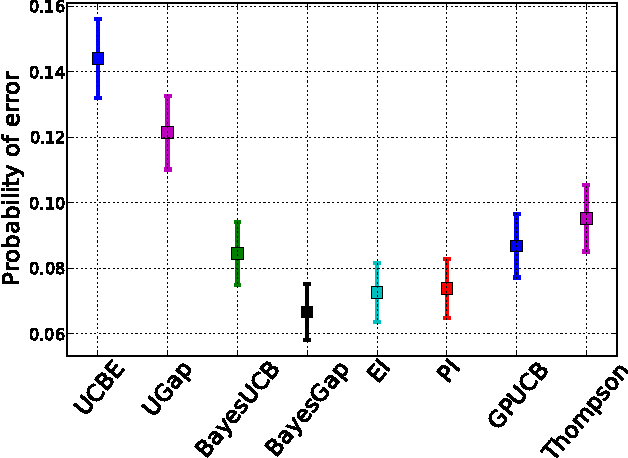
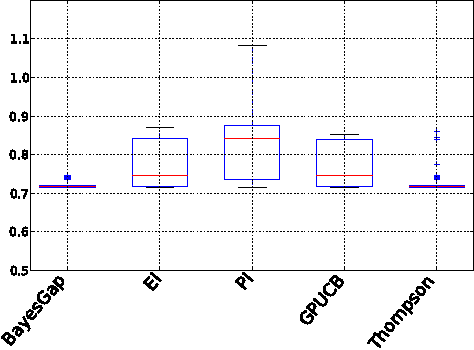
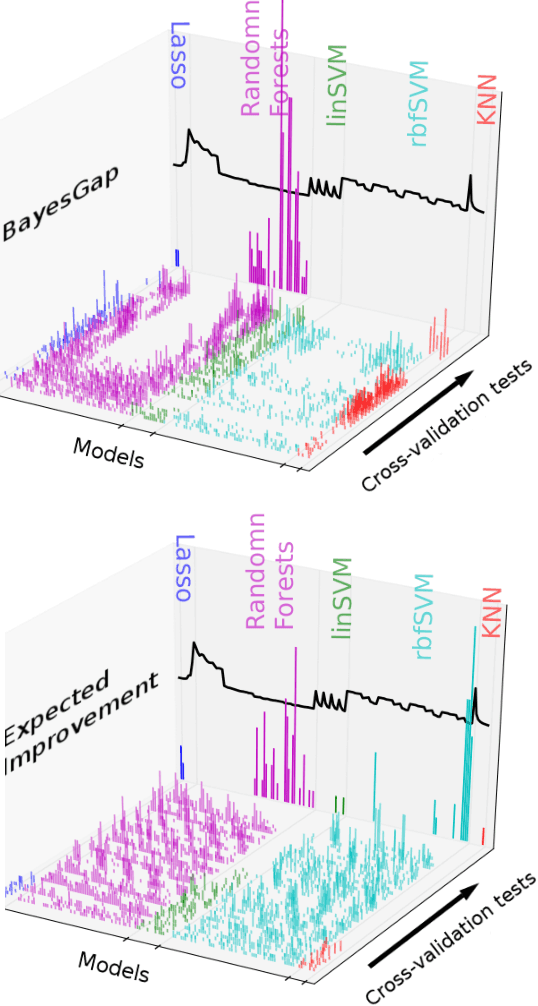
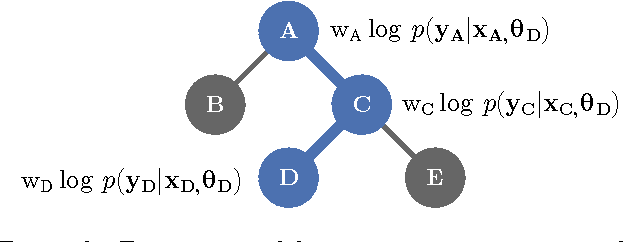
We address the problem of finding the maximizer of a nonlinear smooth function, that can only be evaluated point-wise, subject to constraints on the number of permitted function evaluations. This problem is also known as fixed-budget best arm identification in the multi-armed bandit literature. We introduce a Bayesian approach for this problem and show that it empirically outperforms both the existing frequentist counterpart and other Bayesian optimization methods. The Bayesian approach places emphasis on detailed modelling, including the modelling of correlations among the arms. As a result, it can perform well in situations where the number of arms is much larger than the number of allowed function evaluation, whereas the frequentist counterpart is inapplicable. This feature enables us to develop and deploy practical applications, such as automatic machine learning toolboxes. The paper presents comprehensive comparisons of the proposed approach, Thompson sampling, classical Bayesian optimization techniques, more recent Bayesian bandit approaches, and state-of-the-art best arm identification methods. This is the first comparison of many of these methods in the literature and allows us to examine the relative merits of their different features.