 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Min-Max Complexity of Distributed Stochastic Convex Optimization with Intermittent Communication
Feb 02, 2021We resolve the min-max complexity of distributed stochastic convex optimization (up to a log factor) in the intermittent communication setting, where $M$ machines work in parallel over the course of $R$ rounds of communication to optimize the objective, and during each round of communication, each machine may sequentially compute $K$ stochastic gradient estimates. We present a novel lower bound with a matching upper bound that establishes an optimal algorithm.
Implicit Bias in Deep Linear Classification: Initialization Scale vs Training Accuracy
Jul 13, 2020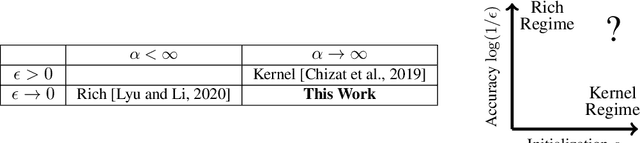
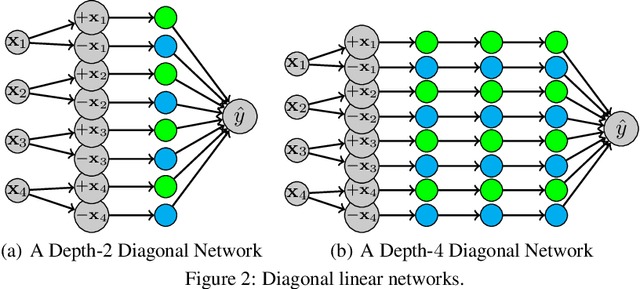
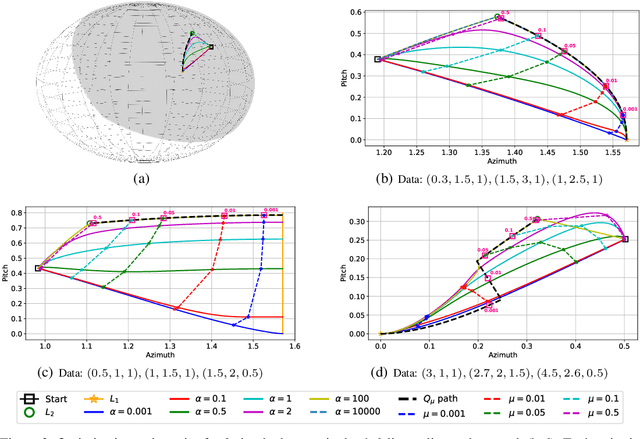
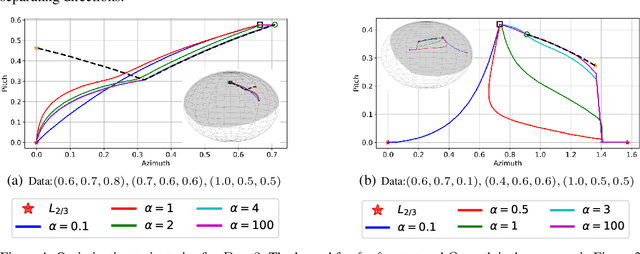
We provide a detailed asymptotic study of gradient flow trajectories and their implicit optimization bias when minimizing the exponential loss over "diagonal linear networks". This is the simplest model displaying a transition between "kernel" and non-kernel ("rich" or "active") regimes. We show how the transition is controlled by the relationship between the initialization scale and how accurately we minimize the training loss. Our results indicate that some limit behaviors of gradient descent only kick in at ridiculous training accuracies (well beyond $10^{-100}$). Moreover, the implicit bias at reasonable initialization scales and training accuracies is more complex and not captured by these limits.
Minibatch vs Local SGD for Heterogeneous Distributed Learning
Jun 18, 2020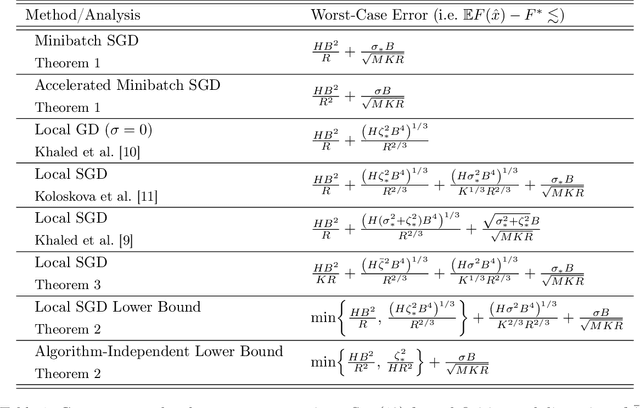
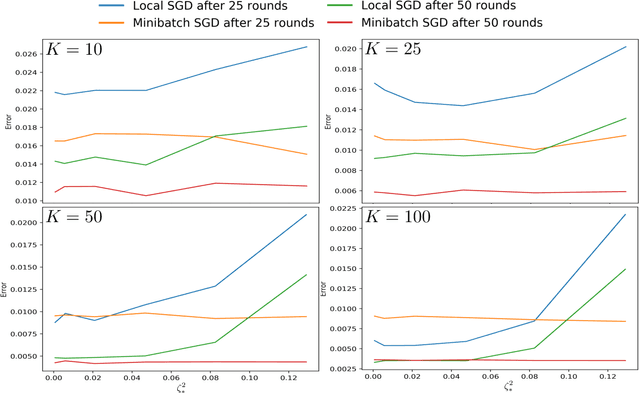
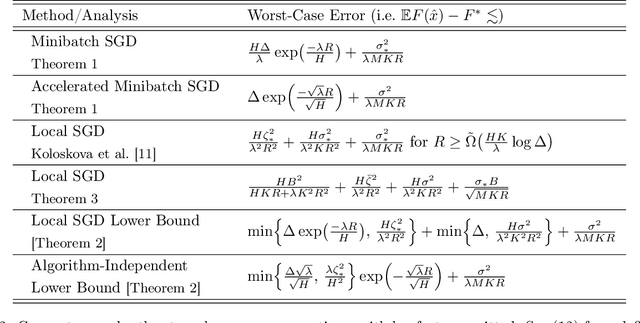
We analyze Local SGD (aka parallel or federated SGD) and Minibatch SGD in the heterogeneous distributed setting, where each machine has access to stochastic gradient estimates for a different, machine-specific, convex objective; the goal is to optimize w.r.t. the average objective; and machines can only communicate intermittently. We argue that, (i) Minibatch SGD (even without acceleration) dominates all existing analysis of Local SGD in this setting, (ii) accelerated Minibatch SGD is optimal when the heterogeneity is high, and (iii) present the first upper bound for Local SGD that improves over Minibatch SGD in a non-homogeneous regime.
Mirrorless Mirror Descent: A More Natural Discretization of Riemannian Gradient Flow
Apr 24, 2020We present a direct (primal only) derivation of Mirror Descent as a "partial" discretization of gradient flow on a Riemannian manifold where the metric tensor is the Hessian of the Mirror Descent potential function. We argue that this discretization is more faithful to the geometry than Natural Gradient Descent, which is obtained by a "full" forward Euler discretization. This view helps shed light on the relationship between the methods and allows generalizing Mirror Descent to any Riemannian geometry, even when the metric tensor is not a Hessian, and thus there is no "dual."
Kernel and Rich Regimes in Overparametrized Models
Feb 24, 2020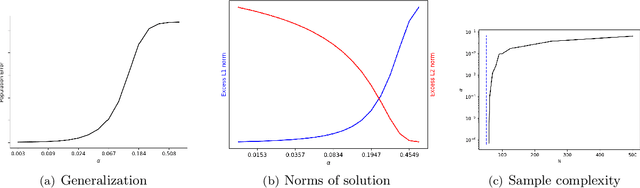
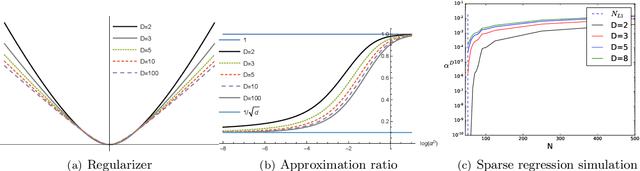
A recent line of work studies overparametrized neural networks in the "kernel regime," i.e. when the network behaves during training as a kernelized linear predictor, and thus training with gradient descent has the effect of finding the minimum RKHS norm solution. This stands in contrast to other studies which demonstrate how gradient descent on overparametrized multilayer networks can induce rich implicit biases that are not RKHS norms. Building on an observation by Chizat and Bach, we show how the scale of the initialization controls the transition between the "kernel" (aka lazy) and "rich" (aka active) regimes and affects generalization properties in multilayer homogeneous models. We also highlight an interesting role for the width of a model in the case that the predictor is not identically zero at initialization. We provide a complete and detailed analysis for a family of simple depth-$D$ models that already exhibit an interesting and meaningful transition between the kernel and rich regimes, and we also demonstrate this transition empirically for more complex matrix factorization models and multilayer non-linear networks.
Is Local SGD Better than Minibatch SGD?
Feb 18, 2020
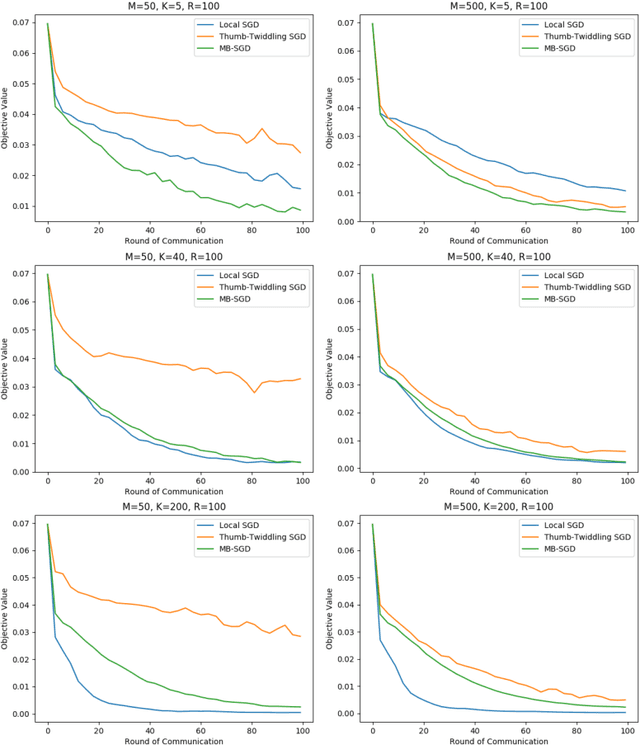

We study local SGD (also known as parallel SGD and federated averaging), a natural and frequently used stochastic distributed optimization method. Its theoretical foundations are currently lacking and we highlight how all existing error guarantees in the convex setting are dominated by a simple baseline, minibatch SGD. (1) For quadratic objectives we prove that local SGD strictly dominates minibatch SGD and that accelerated local SGD is minimax optimal for quadratics; (2) For general convex objectives we provide the first guarantee that at least sometimes improves over minibatch SGD; (3) We show that indeed local SGD does not dominate minibatch SGD by presenting a lower bound on the performance of local SGD that is worse than the minibatch SGD guarantee.
Lower Bounds for Non-Convex Stochastic Optimization
Dec 05, 2019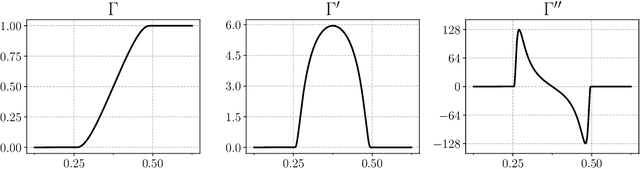
We lower bound the complexity of finding $\epsilon$-stationary points (with gradient norm at most $\epsilon$) using stochastic first-order methods. In a well-studied model where algorithms access smooth, potentially non-convex functions through queries to an unbiased stochastic gradient oracle with bounded variance, we prove that (in the worst case) any algorithm requires at least $\epsilon^{-4}$ queries to find an $\epsilon$ stationary point. The lower bound is tight, and establishes that stochastic gradient descent is minimax optimal in this model. In a more restrictive model where the noisy gradient estimates satisfy a mean-squared smoothness property, we prove a lower bound of $\epsilon^{-3}$ queries, establishing the optimality of recently proposed variance reduction techniques.
The gradient complexity of linear regression
Nov 06, 2019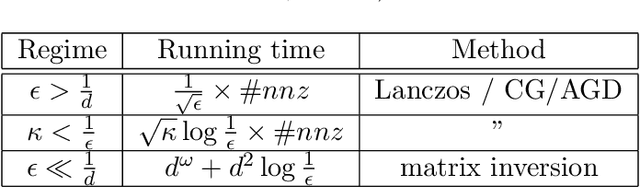
We investigate the computational complexity of several basic linear algebra primitives, including largest eigenvector computation and linear regression, in the computational model that allows access to the data via a matrix-vector product oracle. We show that for polynomial accuracy, $\Theta(d)$ calls to the oracle are necessary and sufficient even for a randomized algorithm. Our lower bound is based on a reduction to estimating the least eigenvalue of a random Wishart matrix. This simple distribution enables a concise proof, leveraging a few key properties of the random Wishart ensemble.
Open Problem: The Oracle Complexity of Convex Optimization with Limited Memory
Jul 01, 2019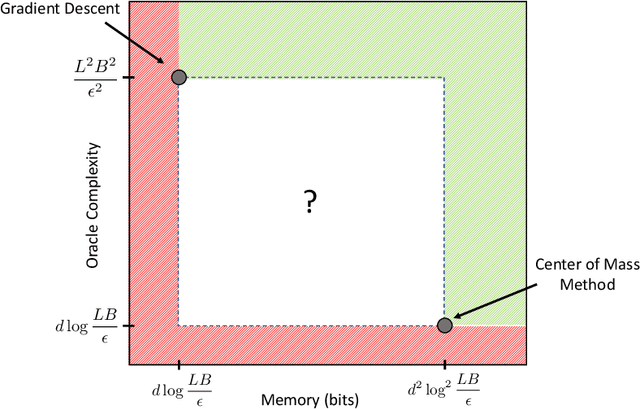
We note that known methods achieving the optimal oracle complexity for first order convex optimization require quadratic memory, and ask whether this is necessary, and more broadly seek to characterize the minimax number of first order queries required to optimize a convex Lipschitz function subject to a memory constraint.
Guaranteed Validity for Empirical Approaches to Adaptive Data Analysis
Jun 21, 2019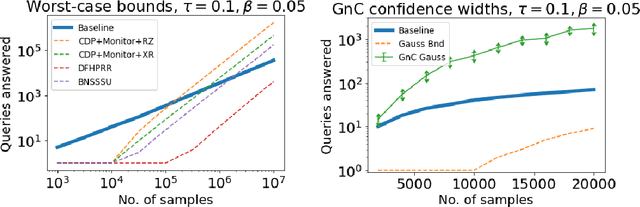
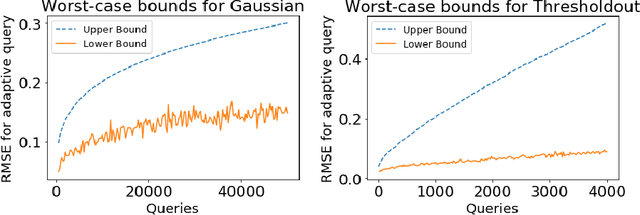
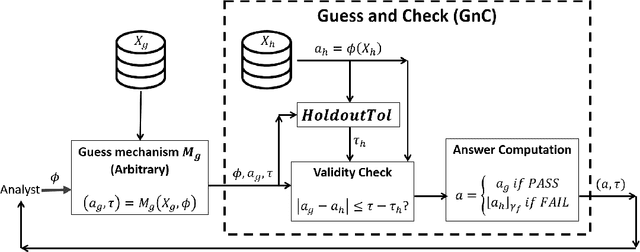
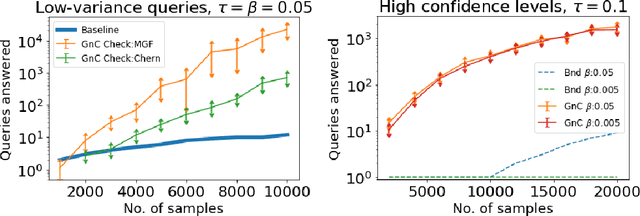
We design a general framework for answering adaptive statistical queries that focuses on providing explicit confidence intervals along with point estimates. Prior work in this area has either focused on providing tight confidence intervals for specific analyses, or providing general worst-case bounds for point estimates. Unfortunately, as we observe, these worst-case bounds are loose in many settings --- often not even beating simple baselines like sample splitting. Our main contribution is to design a framework for providing valid, instance-specific confidence intervals for point estimates that can be generated by heuristics. When paired with good heuristics, this method gives guarantees that are orders of magnitude better than the best worst-case bounds. We provide a Python library implementing our method.