 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCN: Table Convolutional Network for Web Table Interpretation
Feb 17, 2021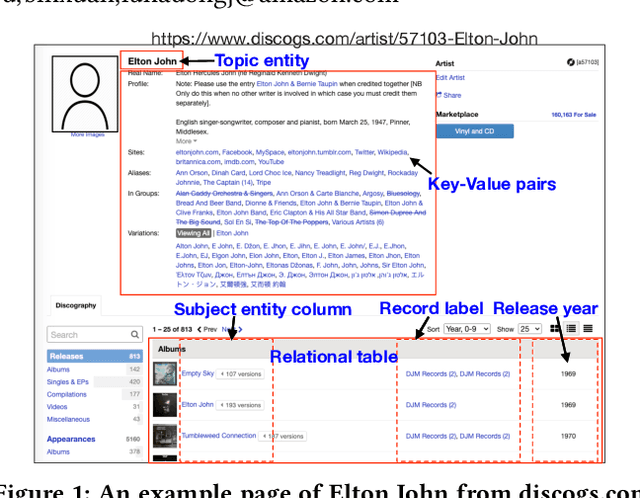
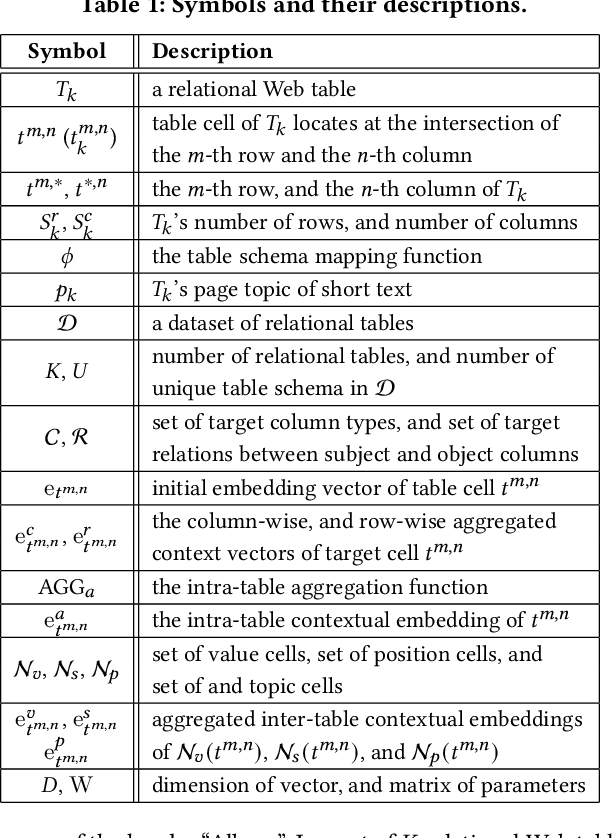
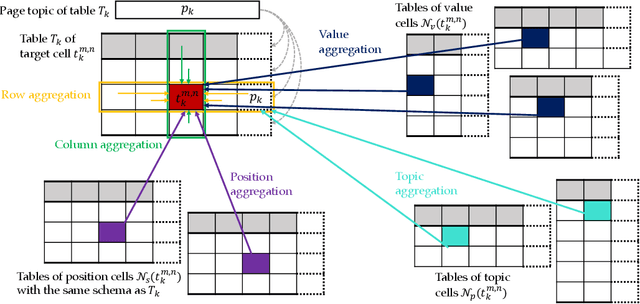
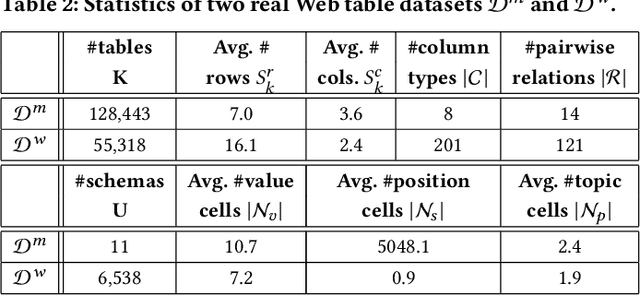
Information extraction from semi-structured webpages provides valuable long-tailed facts for augmenting knowledge graph. Relational Web tables are a critical component containing additional entities and attributes of rich and diverse knowledge. However, extracting knowledge from relational tables is challenging because of sparse contextual information. Existing work linearize table cells and heavily rely on modifying deep language models such as BERT which only captures related cells information in the same table. In this work, we propose a novel relational table representation learning approach considering both the intra- and inter-table contextual information. On one hand, the proposed Table Convolutional Network model employs the attention mechanism to adaptively focus on the most informative intra-table cells of the same row or column; and, on the other hand, it aggregates inter-table contextual information from various types of implicit connections between cells across different tables. Specifically, we propose three novel aggregation modules for (i) cells of the same value, (ii) cells of the same schema position, and (iii) cells linked to the same page topic. We further devise a supervised multi-task training objective for jointly predicting column type and pairwise column relation, as well as a table cell recovery objective for pre-training. Experiments on real Web table datasets demonstrate our method can outperform competitive baselines by +4.8% of F1 for column type prediction and by +4.1% of F1 for pairwise column relation prediction.
Discover Your Social Identity from What You Tweet: a Content Based Approach
Mar 03, 2020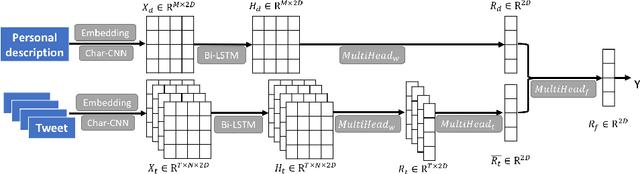


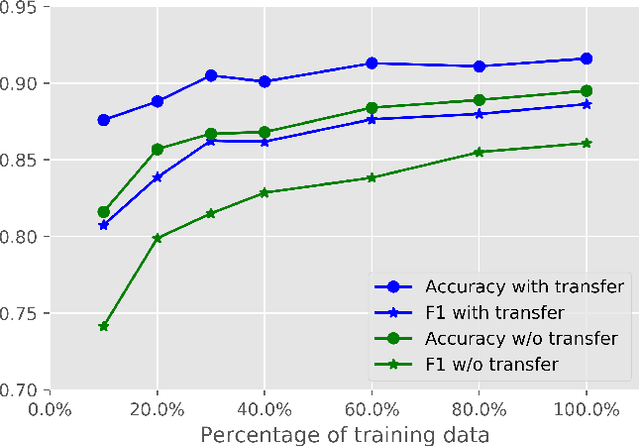
An identity denotes the role an individual or a group plays in highly differentiated contemporary societies. In this paper, our goal is to classify Twitter users based on their role identities. We first collect a coarse-grained public figure dataset automatically, then manually label a more fine-grained identity dataset. We propose a hierarchical self-attention neural network for Twitter user role identity classification. Our experiments demonstrate that the proposed model significantly outperforms multiple baselines. We further propose a transfer learning scheme that improves our model's performance by a large margin. Such transfer learning also greatly reduces the need for a large amount of human labeled data.
A Hierarchical Location Prediction Neural Network for Twitter User Geolocation
Oct 28, 2019Accurate estimation of user location is important for many online services. Previous neural network based methods largely ignore the hierarchical structure among locations. In this paper, we propose a hierarchical location prediction neural network for Twitter user geolocation. Our model first predicts the home country for a user, then uses the country result to guide the city-level prediction. In addition, we employ a character-aware word embedding layer to overcome the noisy information in tweets. With the feature fusion layer, our model can accommodate various feature combinations and achieves state-of-the-art results over three commonly used benchmarks under different feature settings. It not only improves the prediction accuracy but also greatly reduces the mean error distance.
Parameterized Convolutional Neural Networks for Aspect Level Sentiment Classification
Sep 13, 2019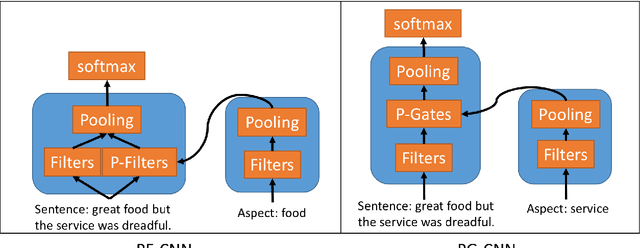
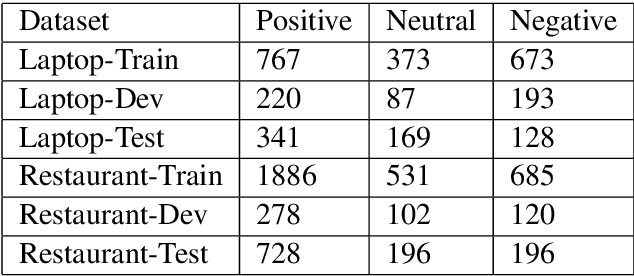
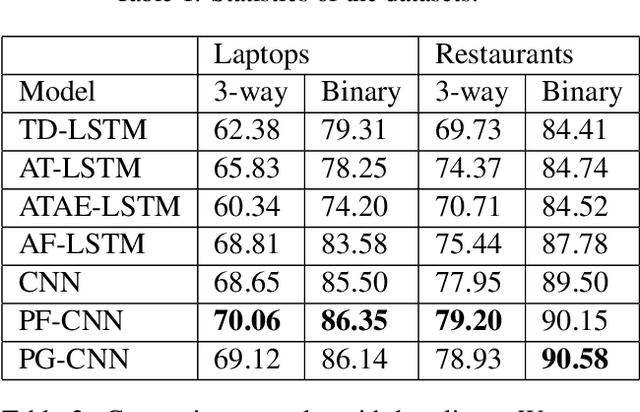
We introduce a novel parameterized convolutional neural network for aspect level sentiment classification. Using parameterized filters and parameterized gates, we incorporate aspect information into convolutional neural networks (CNN). Experiments demonstrate that our parameterized filters and parameterized gates effectively capture the aspect-specific features, and our CNN-based models achieve excellent results on SemEval 2014 datasets.
Syntax-Aware Aspect Level Sentiment Classification with Graph Attention Networks
Sep 05, 2019
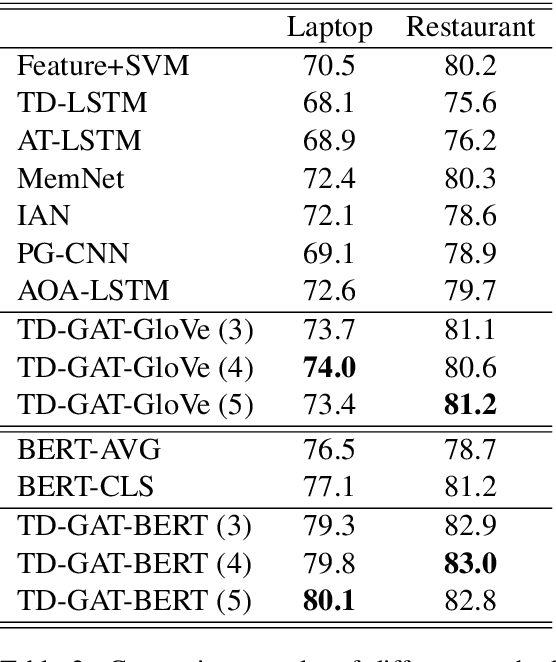
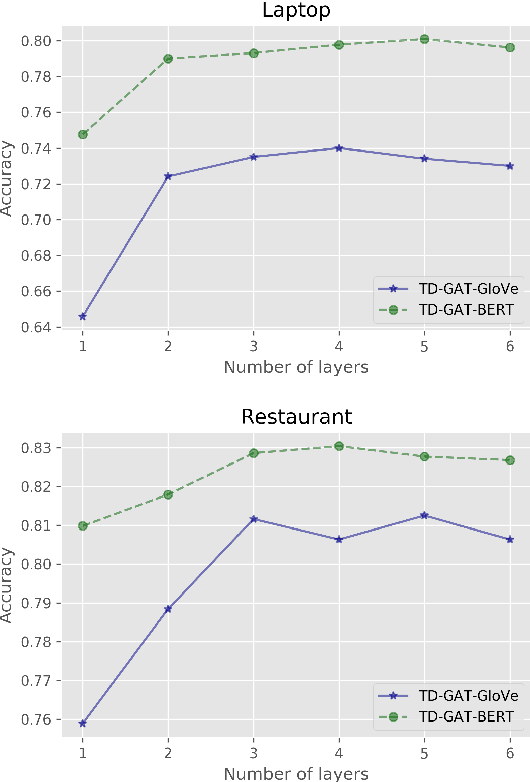
Aspect level sentiment classification aims to identify the sentiment expressed towards an aspect given a context sentence. Previous neural network based methods largely ignore the syntax structure in one sentence. In this paper, we propose a novel target-dependent graph attention network (TD-GAT) for aspect level sentiment classification, which explicitly utilizes the dependency relationship among words. Using the dependency graph, it propagates sentiment features directly from the syntactic context of an aspect target. In our experiments, we show our method outperforms multiple baselines with GloVe embeddings. We also demonstrate that using BERT representations further substantially boosts the performance.
Recurrent U-net: Deep learning to predict daily summertime ozone in the United States
Aug 16, 2019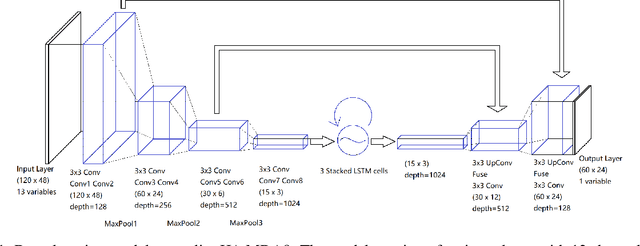
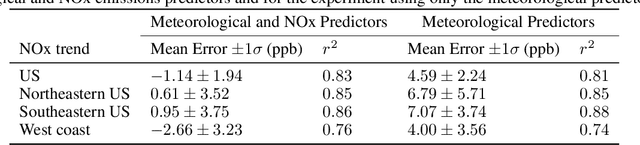
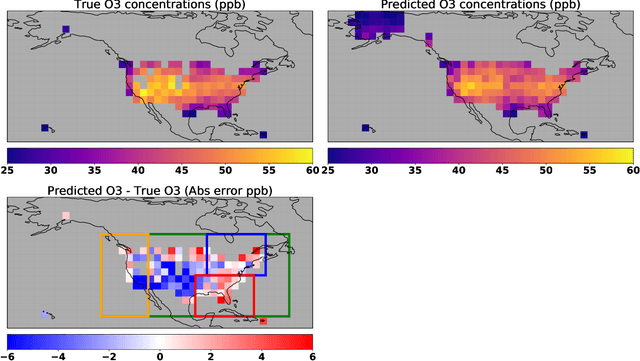

We use a hybrid deep learning model to predict June-July-August (JJA) daily maximum 8-h average (MDA8) surface ozone concentrations in the US. A set of meteorological fields from the ERA-Interim reanalysis as well as monthly mean NO$_x$ emissions from the Community Emissions Data System (CEDS) inventory are selected as predictors. Ozone measurements from the US Environmental Protection Agency (EPA) Air Quality System (AQS) from 1980 to 2009 are used to train the model, whereas data from 2010 to 2014 are used to evaluate the performance of the model. The model captures well daily, seasonal and interannual variability in MDA8 ozone across the US. Feature maps show that the model captures teleconnections between MDA8 ozone and the meteorological fields, which are responsible for driving the ozone dynamics. We used the model to evaluate recent trends in NO$_x$ emissions in the US and found that the trend in the EPA emission inventory produced the largest negative bias in MDA8 ozone between 2010-2016. The top-down emission trends from the Tropospheric Chemistry Reanalysis (TCR-2), which is based on satellite observations, produced predictions in best agreement with observations. In urban regions, the trend in AQS NO$_2$ observations provided ozone predictions in agreement with observations, whereas in rural regions the satellite-derived trends produced the best agreement. In both rural and urban regions the EPA trend resulted in the largest negative bias in predicted ozone. Our results suggest that the EPA inventory is overestimating the reductions in NO$_x$ emissions and that the satellite-derived trend reflects the influence of reductions in NO$_x$ emissions as well as changes in background NO$_x$. Our results demonstrate the significantly greater predictive capability that the deep learning model provides over conventional atmospheric chemical transport models for air quality analyses.
Inductive Graph Representation Learning with Recurrent Graph Neural Networks
May 07, 2019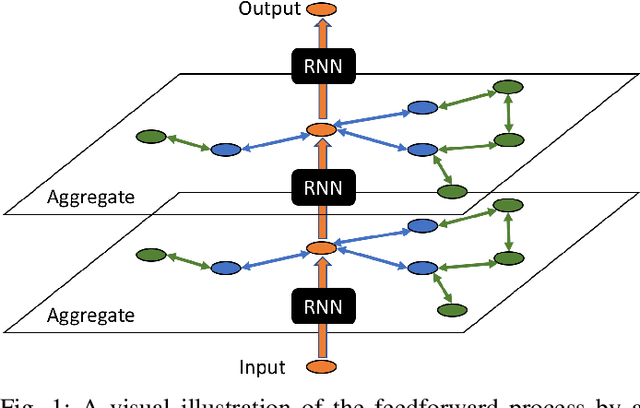
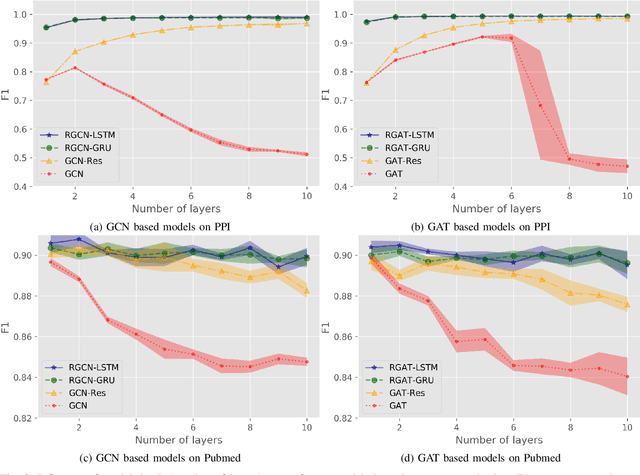
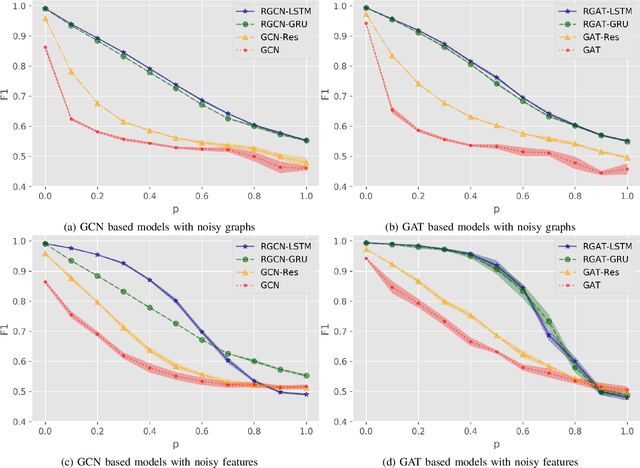
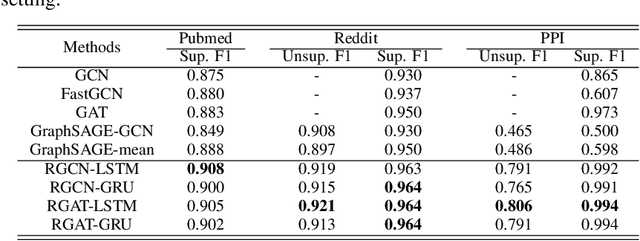
In this paper, we study the problem of node representation learning with graph neural networks. We present a graph neural network class named recurrent graph neural network (RGNN), that address the shortcomings of prior methods. By using recurrent units to capture the long-term dependency across layers, our methods can successfully identify important information during recursive neighborhood expansion. In our experiments, we show that our model class achieves state-of-the-art results on three benchmarks: the Pubmed, Reddit, and PPI network datasets. Our in-depth analyses also demonstrate that incorporating recurrent units is a simple yet effective method to prevent noisy information in graphs, which enables a deeper graph neural network.
Aspect Level Sentiment Classification with Attention-over-Attention Neural Networks
Apr 18, 2018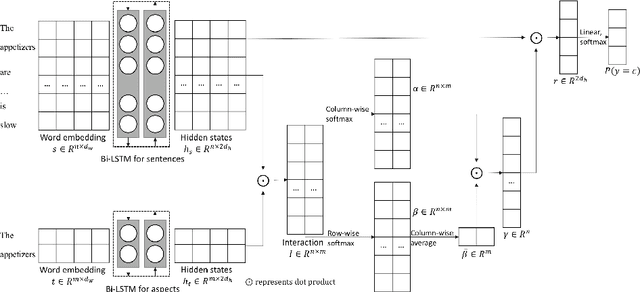


Aspect-level sentiment classification aims to identify the sentiment expressed towards some aspects given context sentences. In this paper, we introduce an attention-over-attention (AOA) neural network for aspect level sentiment classification. Our approach models aspects and sentences in a joint way and explicitly captures the interaction between aspects and context sentences. With the AOA module, our model jointly learns the representations for aspects and sentences, and automatically focuses on the important parts in sentences. Our experiments on laptop and restaurant datasets demonstrate our approach outperforms previous LSTM-based architectures.
A Probabilistic Framework for Location Inference from Social Media
Mar 01, 2017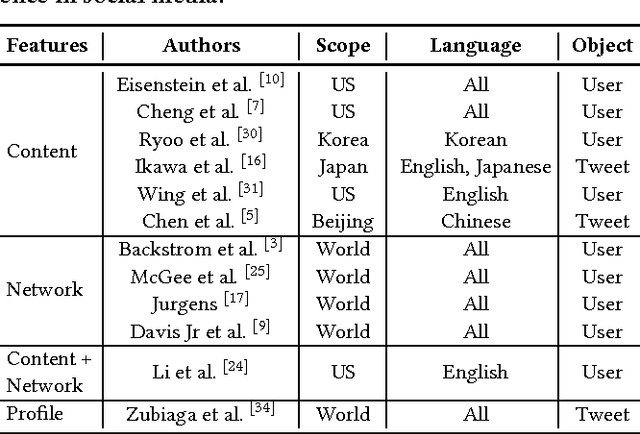
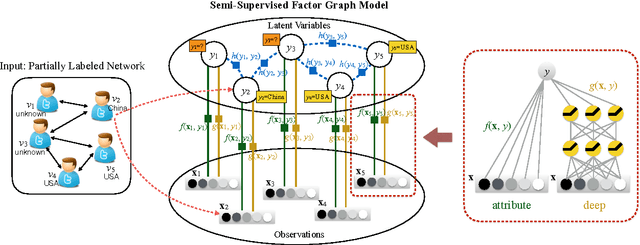
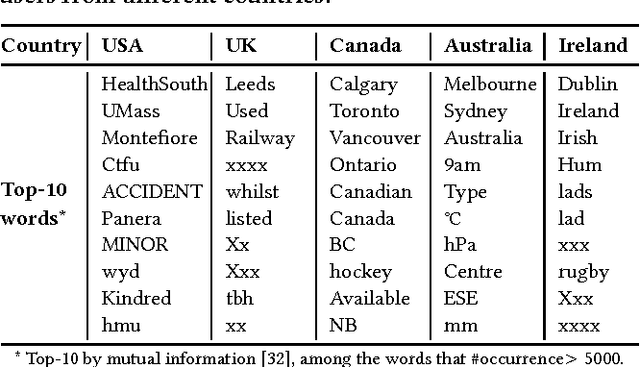
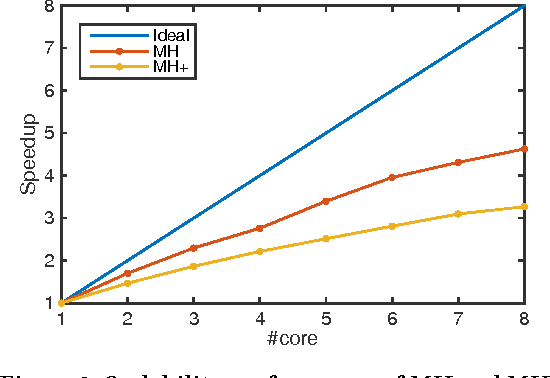
We study the extent to which we can infer users' geographical locations from social media. Location inference from social media can benefit many applications, such as disaster management, targeted advertising, and news content tailoring. In recent years, a number of algorithms have been proposed for identifying user locations on social media platforms such as Twitter and Facebook from message contents, friend networks, and interactions between users. In this paper, we propose a novel probabilistic model based on factor graphs for location inference that offers several unique advantages for this task. First, the model generalizes previous methods by incorporating content, network, and deep features learned from social context. The model is also flexible enough to support both supervised learning and semi-supervised learning. Second, we explore several learning algorithms for the proposed model, and present a Two-chain Metropolis-Hastings (MH+) algorithm, which improves the inference accuracy. Third, we validate the proposed model on three different genres of data - Twitter, Weibo, and Facebook - and demonstrate that the proposed model can substantially improve the inference accuracy (+3.3-18.5% by F1-score) over that of several state-of-the-art methods.