 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabTreeFormer: Tabular Data Generation Using Hybrid Tree-Transformer
Jan 07, 2025



Transformers have achieved remarkable success in tabular data generation. However, they lack domain-specific inductive biases which are critical to preserving the intrinsic characteristics of tabular data. Meanwhile, they suffer from poor scalability and efficiency due to quadratic computational complexity. In this paper, we propose TabTreeFormer, a hybrid transformer architecture that incorporates a tree-based model that retains tabular-specific inductive biases of non-smooth and potentially low-correlated patterns caused by discreteness and non-rotational invariance, and hence enhances the fidelity and utility of synthetic data. In addition, we devise a dual-quantization tokenizer to capture the multimodal continuous distribution and further facilitate the learning of numerical value distribution. Moreover, our proposed tokenizer reduces the vocabulary size and sequence length due to the limited complexity (e.g., dimension-wise semantic meaning) of tabular data, rendering a significant model size shrink without sacrificing the capability of the transformer model. We evaluate TabTreeFormer on 10 datasets against multiple generative models on various metrics; our experimental results show that TabTreeFormer achieves superior fidelity, utility, privacy, and efficiency. Our best model yields a 40% utility improvement with 1/16 of the baseline model size.
UIBDiffusion: Universal Imperceptible Backdoor Attack for Diffusion Models
Dec 16, 2024Recent studies show that diffusion models (DMs) are vulnerable to backdoor attacks. Existing backdoor attacks impose unconcealed triggers (e.g., a gray box and eyeglasses) that contain evident patterns, rendering remarkable attack effects yet easy detection upon human inspection and defensive algorithms. While it is possible to improve stealthiness by reducing the strength of the backdoor, doing so can significantly compromise its generality and effectiveness. In this paper, we propose UIBDiffusion, the universal imperceptible backdoor attack for diffusion models, which allows us to achieve superior attack and generation performance while evading state-of-the-art defenses. We propose a novel trigger generation approach based on universal adversarial perturbations (UAPs) and reveal that such perturbations, which are initially devised for fooling pre-trained discriminative models, can be adapted as potent imperceptible backdoor triggers for DMs. We evaluate UIBDiffusion on multiple types of DMs with different kinds of samplers across various datasets and targets. Experimental results demonstrate that UIBDiffusion brings three advantages: 1) Universality, the imperceptible trigger is universal (i.e., image and model agnostic) where a single trigger is effective to any images and all diffusion models with different samplers; 2) Utility, it achieves comparable generation quality (e.g., FID) and even better attack success rate (i.e., ASR) at low poison rates compared to the prior works; and 3) Undetectability, UIBDiffusion is plausible to human perception and can bypass Elijah and TERD, the SOTA defenses against backdoors for DMs. We will release our backdoor triggers and code.
Fully Attentional Networks with Self-emerging Token Labeling
Jan 08, 2024



Recent studies indicate that Vision Transformers (ViTs) are robust against out-of-distribution scenarios. In particular, the Fully Attentional Network (FAN) - a family of ViT backbones, has achieved state-of-the-art robustness. In this paper, we revisit the FAN models and improve their pre-training with a self-emerging token labeling (STL) framework. Our method contains a two-stage training framework. Specifically, we first train a FAN token labeler (FAN-TL) to generate semantically meaningful patch token labels, followed by a FAN student model training stage that uses both the token labels and the original class label. With the proposed STL framework, our best model based on FAN-L-Hybrid (77.3M parameters) achieves 84.8% Top-1 accuracy and 42.1% mCE on ImageNet-1K and ImageNet-C, and sets a new state-of-the-art for ImageNet-A (46.1%) and ImageNet-R (56.6%) without using extra data, outperforming the original FAN counterpart by significant margins. The proposed framework also demonstrates significantly enhanced performance on downstream tasks such as semantic segmentation, with up to 1.7% improvement in robustness over the counterpart model. Code is available at https://github.com/NVlabs/STL.
Class-Oriented Poisoning Attack
Jul 31, 2020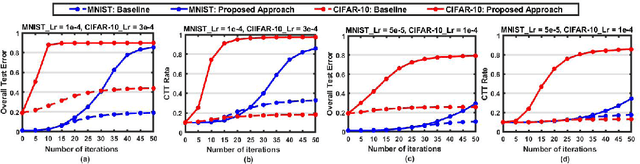

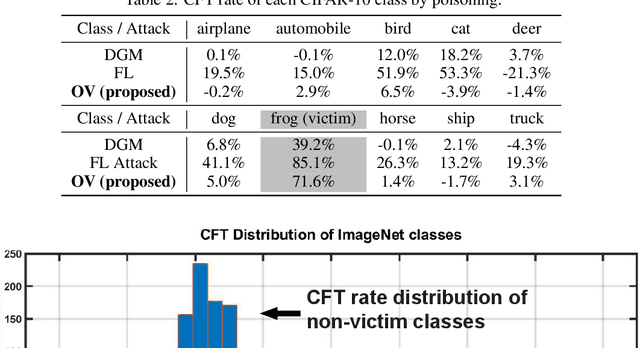
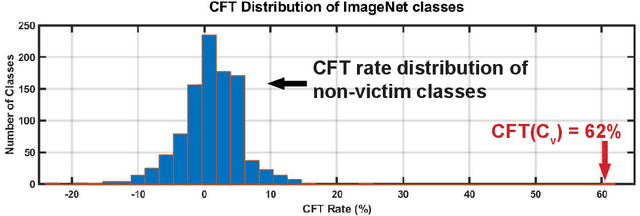
Poisoning attacks on machine learning systems compromise the model performance by deliberately injecting malicious samples in the training dataset to influence the training process. Prior works focus on either availability attacks (i.e., lowering the overall model accuracy) or integrity attacks (i.e., enabling specific instance based backdoor). In this paper, we advance the adversarial objectives of the availability attacks to a per-class basis, which we refer to as class-oriented poisoning attacks. We demonstrate that the proposed attack is capable of forcing the corrupted model to predict in two specific ways: (i) classify unseen new images to a targeted "supplanter" class, and (ii) misclassify images from a "victim" class while maintaining the classification accuracy on other non-victim classes. To maximize the adversarial effect, we propose a gradient-based framework that manipulates the logits to retain/eliminate the desired/undesired feature information in the generated poisoning images. Using newly defined metrics at the class level, we illustrate the effectiveness of the proposed class-oriented poisoning attacks on various models (e.g., LeNet-5, Vgg-9, and ResNet-50) over a wide range of datasets (e.g., MNIST, CIFAR-10, and ImageNet-ILSVRC2012).