 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Anomalous Sound Detection via Low-Rank Adaptation Fine-Tuning of Pre-Trained Audio Models
Sep 11, 2024



Anomalous Sound Detection (ASD) has gained significant interest through the application of various Artificial Intelligence (AI) technologies in industrial settings. Though possessing great potential, ASD systems can hardly be readily deployed in real production sites due to the generalization problem, which is primarily caused by the difficulty of data collection and the complexity of environmental factors. This paper introduces a robust ASD model that leverages audio pre-trained models. Specifically, we fine-tune these models using machine operation data, employing SpecAug as a data augmentation strategy. Additionally, we investigate the impact of utilizing Low-Rank Adaptation (LoRA) tuning instead of full fine-tuning to address the problem of limited data for fine-tuning. Our experiments on the DCASE2023 Task 2 dataset establish a new benchmark of 77.75% on the evaluation set, with a significant improvement of 6.48% compared with previous state-of-the-art (SOTA) models, including top-tier traditional convolutional networks and speech pre-trained models, which demonstrates the effectiveness of audio pre-trained models with LoRA tuning. Ablation studies are also conducted to showcase the efficacy of the proposed scheme.
Flow-TSVAD: Target-Speaker Voice Activity Detection via Latent Flow Matching
Sep 07, 2024



Speaker diarization is typically considered a discriminative task, using discriminative approaches to produce fixed diarization results. In this paper, we explore the use of neural network-based generative methods for speaker diarization for the first time. We implement a Flow-Matching (FM) based generative algorithm within the sequence-to-sequence target speaker voice activity detection (Seq2Seq-TSVAD) diarization system. Our experiments reveal that applying the generative method directly to the original binary label sequence space of the TS-VAD output is ineffective. To address this issue, we propose mapping the binary label sequence into a dense latent space before applying the generative algorithm and our proposed Flow-TSVAD method outperforms the Seq2Seq-TSVAD system. Additionally, we observe that the FM algorithm converges rapidly during the inference stage, requiring only two inference steps to achieve promising results. As a generative model, Flow-TSVAD allows for sampling different diarization results by running the model multiple times. Moreover, ensembling results from various sampling instances further enhances diarization performance.
Autoregressive Speech Synthesis without Vector Quantization
Jul 11, 2024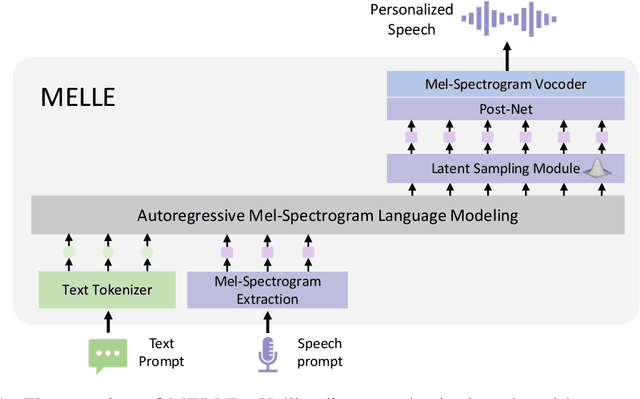



We present MELLE, a novel continuous-valued tokens based language modeling approach for text to speech synthesis (TTS). MELLE autoregressively generates continuous mel-spectrogram frames directly from text condition, bypassing the need for vector quantization, which are originally designed for audio compression and sacrifice fidelity compared to mel-spectrograms. Specifically, (i) instead of cross-entropy loss, we apply regression loss with a proposed spectrogram flux loss function to model the probability distribution of the continuous-valued tokens. (ii) we have incorporated variational inference into MELLE to facilitate sampling mechanisms, thereby enhancing the output diversity and model robustness. Experiments demonstrate that, compared to the two-stage codec language models VALL-E and its variants, the single-stage MELLE mitigates robustness issues by avoiding the inherent flaws of sampling discrete codes, achieves superior performance across multiple metrics, and, most importantly, offers a more streamlined paradigm. See https://aka.ms/melle for demos of our work.
AnoPatch: Towards Better Consistency in Machine Anomalous Sound Detection
Jun 17, 2024



Large pre-trained models have demonstrated dominant performances in multiple areas, where the consistency between pre-training and fine-tuning is the key to success. However, few works reported satisfactory results of pre-trained models for the machine anomalous sound detection (ASD) task. This may be caused by the inconsistency of the pre-trained model and the inductive bias of machine audio, resulting in inconsistency in data and architecture. Thus, we propose AnoPatch which utilizes a ViT backbone pre-trained on AudioSet and fine-tunes it on machine audio. It is believed that machine audio is more related to audio datasets than speech datasets, and modeling it from patch level suits the sparsity of machine audio. As a result, AnoPatch showcases state-of-the-art (SOTA) performances on the DCASE 2020 ASD dataset and the DCASE 2023 ASD dataset. We also compare multiple pre-trained models and empirically demonstrate that better consistency yields considerable improvement.
Teaching Large Language Models to Express Knowledge Boundary from Their Own Signals
Jun 16, 2024



Large language models (LLMs) have achieved great success, but their occasional content fabrication, or hallucination, limits their practical application. Hallucination arises because LLMs struggle to admit ignorance due to inadequate training on knowledge boundaries. We call it a limitation of LLMs that they can not accurately express their knowledge boundary, answering questions they know while admitting ignorance to questions they do not know. In this paper, we aim to teach LLMs to recognize and express their knowledge boundary, so they can reduce hallucinations caused by fabricating when they do not know. We propose CoKE, which first probes LLMs' knowledge boundary via internal confidence given a set of questions, and then leverages the probing results to elicit the expression of the knowledge boundary. Extensive experiments show CoKE helps LLMs express knowledge boundaries, answering known questions while declining unknown ones, significantly improving in-domain and out-of-domain performance.
Contextual Distillation Model for Diversified Recommendation
Jun 13, 2024



The diversity of recommendation is equally crucial as accuracy in improving user experience. Existing studies, e.g., Determinantal Point Process (DPP) and Maximal Marginal Relevance (MMR), employ a greedy paradigm to iteratively select items that optimize both accuracy and diversity. However, prior methods typically exhibit quadratic complexity, limiting their applications to the re-ranking stage and are not applicable to other recommendation stages with a larger pool of candidate items, such as the pre-ranking and ranking stages. In this paper, we propose Contextual Distillation Model (CDM), an efficient recommendation model that addresses diversification, suitable for the deployment in all stages of industrial recommendation pipelines. Specifically, CDM utilizes the candidate items in the same user request as context to enhance the diversification of the results. We propose a contrastive context encoder that employs attention mechanisms to model both positive and negative contexts. For the training of CDM, we compare each target item with its context embedding and utilize the knowledge distillation framework to learn the win probability of each target item under the MMR algorithm, where the teacher is derived from MMR outputs. During inference, ranking is performed through a linear combination of the recommendation and student model scores, ensuring both diversity and efficiency. We perform offline evaluations on two industrial datasets and conduct online A/B test of CDM on the short-video platform KuaiShou. The considerable enhancements observed in both recommendation quality and diversity, as shown by metrics, provide strong superiority for the effectiveness of CDM.
VALL-E R: Robust and Efficient Zero-Shot Text-to-Speech Synthesis via Monotonic Alignment
Jun 12, 2024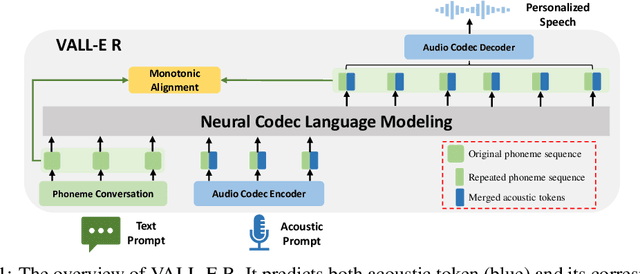

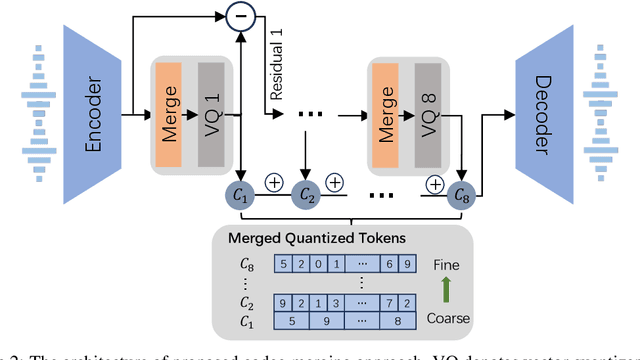

With the help of discrete neural audio codecs, large language models (LLM) have increasingly been recognized as a promising methodology for zero-shot Text-to-Speech (TTS) synthesis. However, sampling based decoding strategies bring astonishing diversity to generation, but also pose robustness issues such as typos, omissions and repetition. In addition, the high sampling rate of audio also brings huge computational overhead to the inference process of autoregression. To address these issues, we propose VALL-E R, a robust and efficient zero-shot TTS system, building upon the foundation of VALL-E. Specifically, we introduce a phoneme monotonic alignment strategy to strengthen the connection between phonemes and acoustic sequence, ensuring a more precise alignment by constraining the acoustic tokens to match their associated phonemes. Furthermore, we employ a codec-merging approach to downsample the discrete codes in shallow quantization layer, thereby accelerating the decoding speed while preserving the high quality of speech output. Benefiting from these strategies, VALL-E R obtains controllablity over phonemes and demonstrates its strong robustness by approaching the WER of ground truth. In addition, it requires fewer autoregressive steps, with over 60% time reduction during inference. This research has the potential to be applied to meaningful projects, including the creation of speech for those affected by aphasia. Audio samples will be available at: https://aka.ms/valler.
Brain-inspired and Self-based Artificial Intelligence
Feb 29, 2024



The question "Can machines think?" and the Turing Test to assess whether machines could achieve human-level intelligence is one of the roots of AI. With the philosophical argument "I think, therefore I am", this paper challenge the idea of a "thinking machine" supported by current AIs since there is no sense of self in them. Current artificial intelligence is only seemingly intelligent information processing and does not truly understand or be subjectively aware of oneself and perceive the world with the self as human intelligence does. In this paper, we introduce a Brain-inspired and Self-based Artificial Intelligence (BriSe AI) paradigm. This BriSe AI paradigm is dedicated to coordinating various cognitive functions and learning strategies in a self-organized manner to build human-level AI models and robotic applications. Specifically, BriSe AI emphasizes the crucial role of the Self in shaping the future AI, rooted with a practical hierarchical Self framework, including Perception and Learning, Bodily Self, Autonomous Self, Social Self, and Conceptual Self. The hierarchical framework of the Self highlights self-based environment perception, self-bodily modeling, autonomous interaction with the environment, social interaction and collaboration with others, and even more abstract understanding of the Self. Furthermore, the positive mutual promotion and support among multiple levels of Self, as well as between Self and learning, enhance the BriSe AI's conscious understanding of information and flexible adaptation to complex environments, serving as a driving force propelling BriSe AI towards real Artificial General Intelligence.
Integrating Large Language Models with Graphical Session-Based Recommendation
Feb 26, 2024



With the rapid development of Large Language Models (LLMs), various explorations have arisen to utilize LLMs capability of context understanding on recommender systems. While pioneering strategies have primarily transformed traditional recommendation tasks into challenges of natural language generation, there has been a relative scarcity of exploration in the domain of session-based recommendation (SBR) due to its specificity. SBR has been primarily dominated by Graph Neural Networks, which have achieved many successful outcomes due to their ability to capture both the implicit and explicit relationships between adjacent behaviors. The structural nature of graphs contrasts with the essence of natural language, posing a significant adaptation gap for LLMs. In this paper, we introduce large language models with graphical Session-Based recommendation, named LLMGR, an effective framework that bridges the aforementioned gap by harmoniously integrating LLMs with Graph Neural Networks (GNNs) for SBR tasks. This integration seeks to leverage the complementary strengths of LLMs in natural language understanding and GNNs in relational data processing, leading to a more powerful session-based recommender system that can understand and recommend items within a session. Moreover, to endow the LLM with the capability to empower SBR tasks, we design a series of prompts for both auxiliary and major instruction tuning tasks. These prompts are crafted to assist the LLM in understanding graph-structured data and align textual information with nodes, effectively translating nuanced user interactions into a format that can be understood and utilized by LLM architectures. Extensive experiments on three real-world datasets demonstrate that LLMGR outperforms several competitive baselines, indicating its effectiveness in enhancing SBR tasks and its potential as a research direction for future exploration.
SegRap2023: A Benchmark of Organs-at-Risk and Gross Tumor Volume Segmentation for Radiotherapy Planning of Nasopharyngeal Carcinoma
Dec 15, 2023



Radiation therapy is a primary and effective NasoPharyngeal Carcinoma (NPC) treatment strategy. The precise delineation of Gross Tumor Volumes (GTVs) and Organs-At-Risk (OARs) is crucial in radiation treatment, directly impacting patient prognosis. Previously, the delineation of GTVs and OARs was performed by experienced radiation oncologists. Recently, deep learning has achieved promising results in many medical image segmentation tasks. However, for NPC OARs and GTVs segmentation, few public datasets are available for model development and evaluation. To alleviate this problem, the SegRap2023 challenge was organized in conjunction with MICCAI2023 and presented a large-scale benchmark for OAR and GTV segmentation with 400 Computed Tomography (CT) scans from 200 NPC patients, each with a pair of pre-aligned non-contrast and contrast-enhanced CT scans. The challenge's goal was to segment 45 OARs and 2 GTVs from the paired CT scans. In this paper, we detail the challenge and analyze the solutions of all participants. The average Dice similarity coefficient scores for all submissions ranged from 76.68\% to 86.70\%, and 70.42\% to 73.44\% for OARs and GTVs, respectively. We conclude that the segmentation of large-size OARs is well-addressed, and more efforts are needed for GTVs and small-size or thin-structure OARs. The benchmark will remain publicly available here: https://segrap2023.grand-challenge.org