 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2020 CATARACTS Semantic Segmentation Challenge
Oct 21, 2021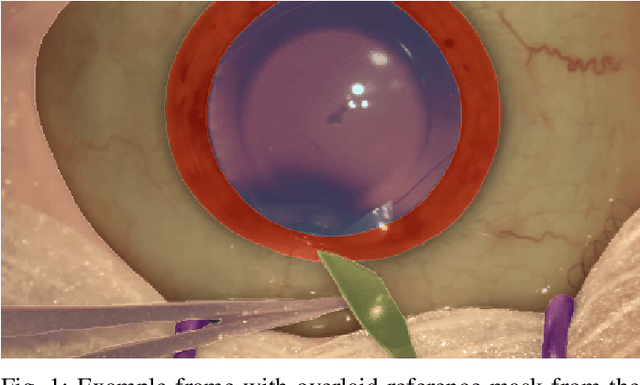
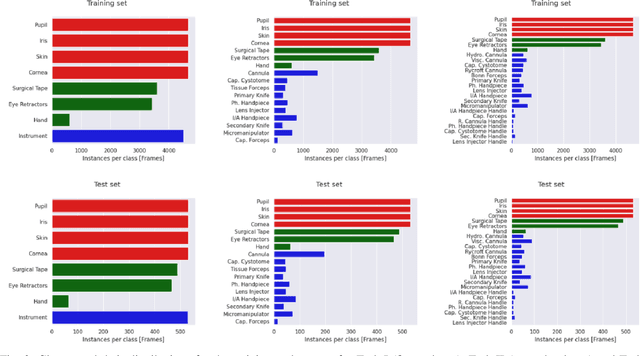
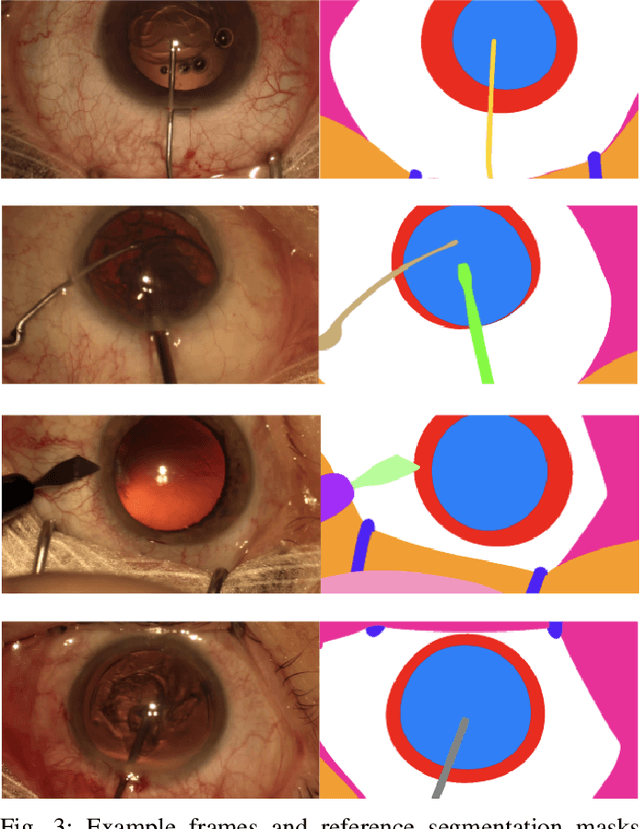
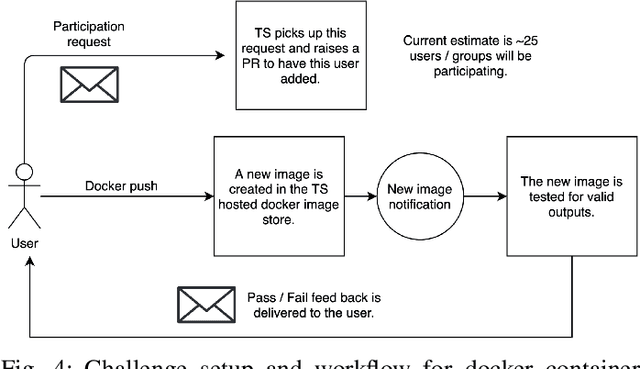
Surgical scene segmentation is essential for anatomy and instrument localization which can be further used to assess tissue-instrument interactions during a surgical procedure. In 2017, the Challenge on Automatic Tool Annotation for cataRACT Surgery (CATARACTS) released 50 cataract surgery videos accompanied by instrument usage annotations. These annotations included frame-level instrument presence information. In 2020, we released pixel-wise semantic annotations for anatomy and instruments for 4670 images sampled from 25 videos of the CATARACTS training set. The 2020 CATARACTS Semantic Segmentation Challenge, which was a sub-challenge of the 2020 MICCAI Endoscopic Vision (EndoVis) Challenge, presented three sub-tasks to assess participating solutions on anatomical structure and instrument segmentation. Their performance was assessed on a hidden test set of 531 images from 10 videos of the CATARACTS test set.
Normalized Label Distribution: Towards Learning Calibrated, Adaptable and Efficient Activation Maps
Dec 12, 2020


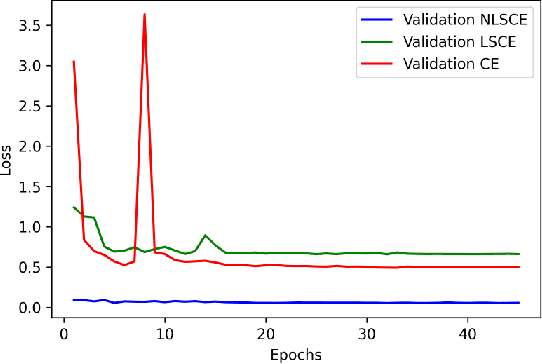
The vulnerability of models to data aberrations and adversarial attacks influences their ability to demarcate distinct class boundaries efficiently. The network's confidence and uncertainty play a pivotal role in weight adjustments and the extent of acknowledging such attacks. In this paper, we address the trade-off between the accuracy and calibration potential of a classification network. We study the significance of ground-truth distribution changes on the performance and generalizability of various state-of-the-art networks and compare the proposed method's response to unanticipated attacks. Furthermore, we demonstrate the role of label-smoothing regularization and normalization in yielding better generalizability and calibrated probability distribution by proposing normalized soft labels to enhance the calibration of feature maps. Subsequently, we substantiate our inference by translating conventional convolutions to padding based partial convolution to establish the tangible impact of corrections in reinforcing the performance and convergence rate. We graphically elucidate the implication of such variations with the critical purpose of corroborating the reliability and reproducibility for multiple datasets.