 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate message-passing for convex optimization with non-separable penalties
Sep 17, 2018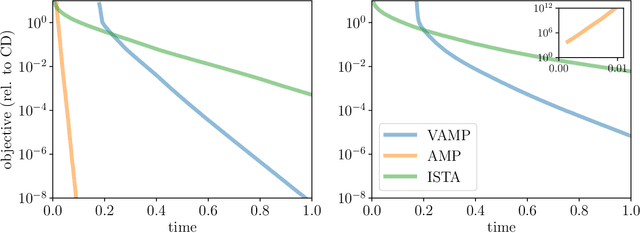
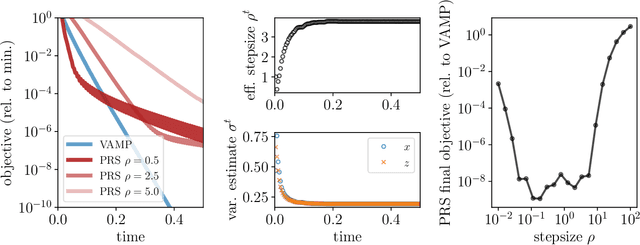
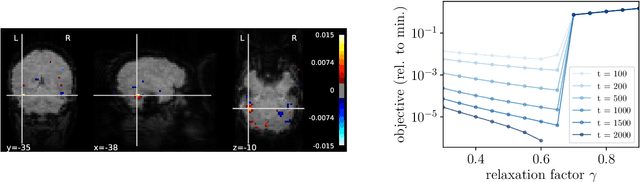
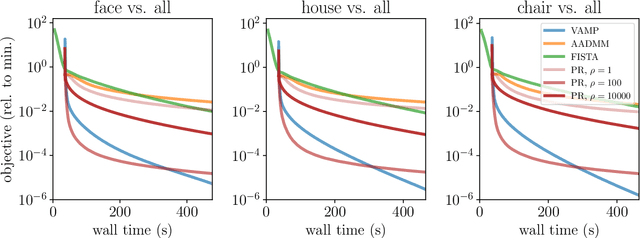
We introduce an iterative optimization scheme for convex objectives consisting of a linear loss and a non-separable penalty, based on the expectation-consistent approximation and the vector approximate message-passing (VAMP) algorithm. Specifically, the penalties we approach are convex on a linear transformation of the variable to be determined, a notable example being total variation (TV). We describe the connection between message-passing algorithms -- typically used for approximate inference -- and proximal methods for optimization, and show that our scheme is, as VAMP, similar in nature to the Peaceman-Rachford splitting, with the important difference that stepsizes are set adaptively. Finally, we benchmark the performance of our VAMP-like iteration in problems where TV penalties are useful, namely classification in task fMRI and reconstruction in tomography, and show faster convergence than that of state-of-the-art approaches such as FISTA and ADMM in most settings.
Optimizing deep video representation to match brain activity
Sep 07, 2018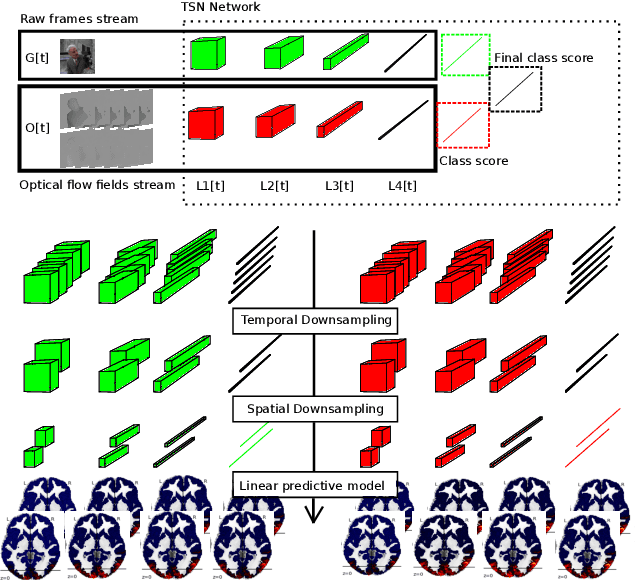
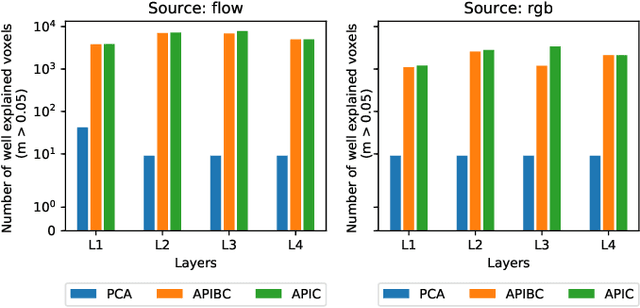
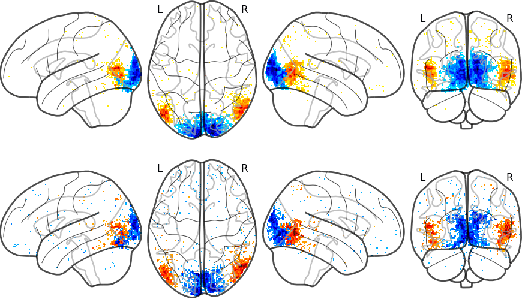
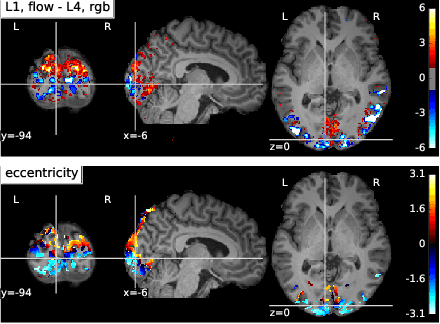
The comparison of observed brain activity with the statistics generated by artificial intelligence systems is useful to probe brain functional organization under ecological conditions. Here we study fMRI activity in ten subjects watching color natural movies and compute deep representations of these movies with an architecture that relies on optical flow and image content. The association of activity in visual areas with the different layers of the deep architecture displays complexity-related contrasts across visual areas and reveals a striking foveal/peripheral dichotomy.
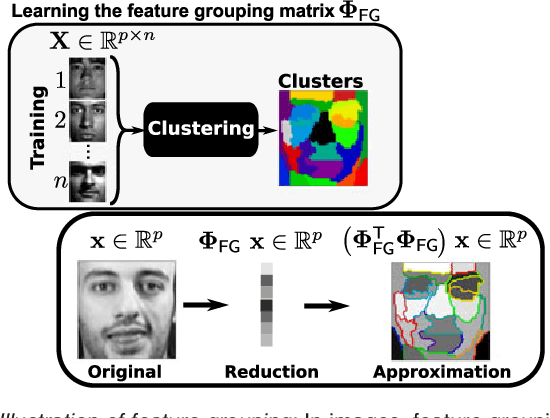
Using Feature Grouping as a Stochastic Regularizer for High-Dimensional Noisy Data
Jul 31, 2018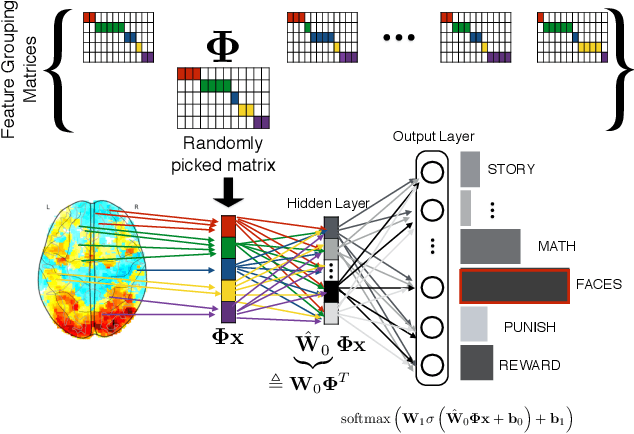
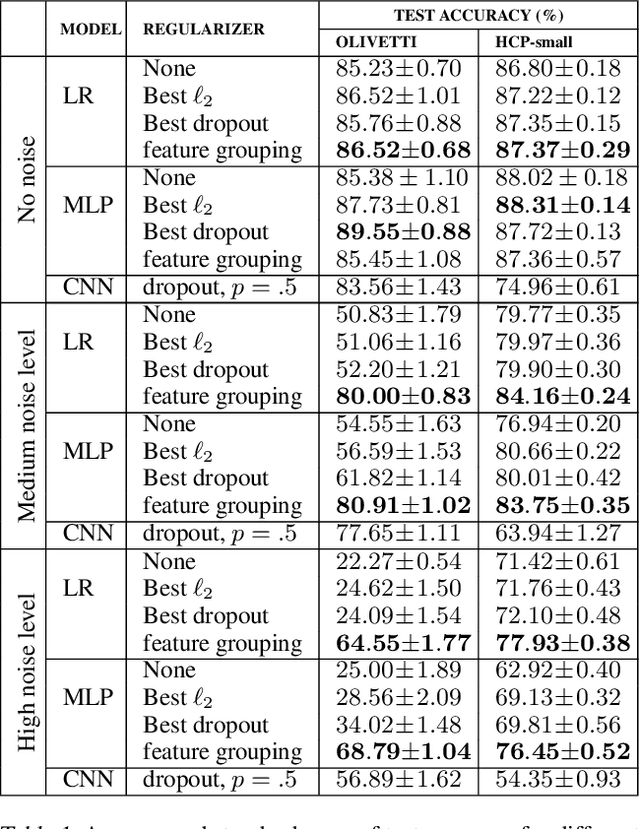
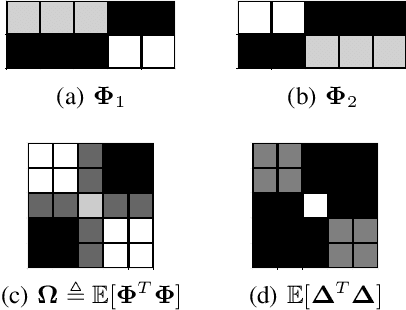

The use of complex models --with many parameters-- is challenging with high-dimensional small-sample problems: indeed, they face rapid overfitting. Such situations are common when data collection is expensive, as in neuroscience, biology, or geology. Dedicated regularization can be crafted to tame overfit, typically via structured penalties. But rich penalties require mathematical expertise and entail large computational costs. Stochastic regularizers such as dropout are easier to implement: they prevent overfitting by random perturbations. Used inside a stochastic optimizer, they come with little additional cost. We propose a structured stochastic regularization that relies on feature grouping. Using a fast clustering algorithm, we define a family of groups of features that capture feature covariations. We then randomly select these groups inside a stochastic gradient descent loop. This procedure acts as a structured regularizer for high-dimensional correlated data without additional computational cost and it has a denoising effect. We demonstrate the performance of our approach for logistic regression both on a sample-limited face image dataset with varying additive noise and on a typical high-dimensional learning problem, brain image classification.
Text to brain: predicting the spatial distribution of neuroimaging observations from text reports
Jun 28, 2018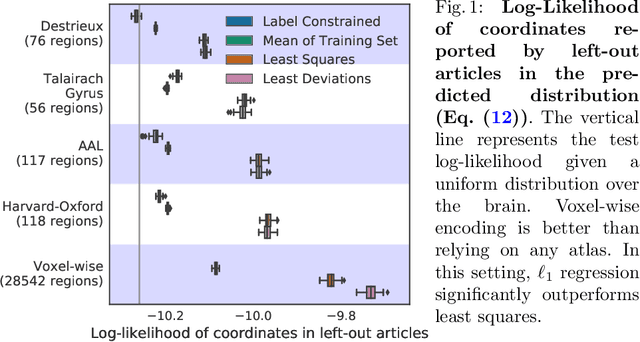
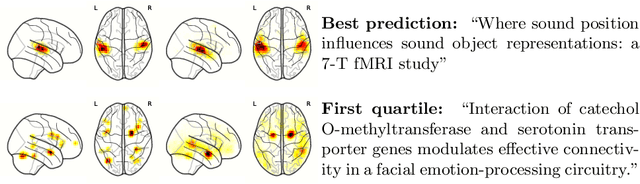
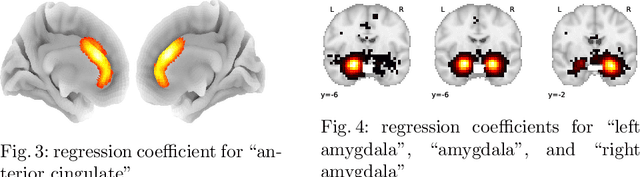
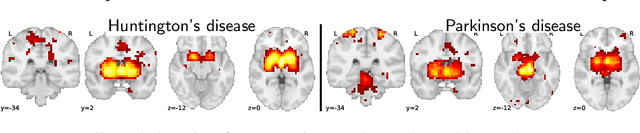
Despite the digital nature of magnetic resonance imaging, the resulting observations are most frequently reported and stored in text documents. There is a trove of information untapped in medical health records, case reports, and medical publications. In this paper, we propose to mine brain medical publications to learn the spatial distribution associated with anatomical terms. The problem is formulated in terms of minimization of a risk on distributions which leads to a least-deviation cost function. An efficient algorithm in the dual then learns the mapping from documents to brain structures. Empirical results using coordinates extracted from the brain-imaging literature show that i) models must adapt to semantic variation in the terms used to describe a given anatomical structure, ii) voxel-wise parameterization leads to higher likelihood of locations reported in unseen documents, iii) least-deviation cost outperforms least-square. As a proof of concept for our method, we use our model of spatial distributions to predict the distribution of specific neurological conditions from text-only reports.
Scikit-learn: Machine Learning in Python
Jun 05, 2018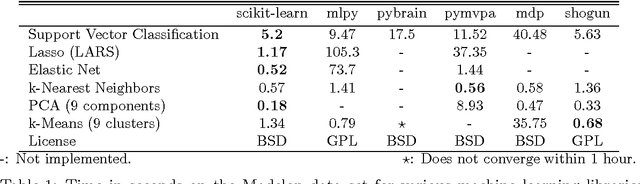
Scikit-learn is a Python module integrating a wide range of state-of-the-art machine learning algorithms for medium-scale supervised and unsupervised problems. This package focuses on bringing machine learning to non-specialists using a general-purpose high-level language. Emphasis is put on ease of use, performance, documentation, and API consistency. It has minimal dependencies and is distributed under the simplified BSD license, encouraging its use in both academic and commercial settings. Source code, binaries, and documentation can be downloaded from http://scikit-learn.org.
* Update authors list and URLs
Recursive nearest agglomeration (ReNA): fast clustering for approximation of structured signals
Mar 19, 2018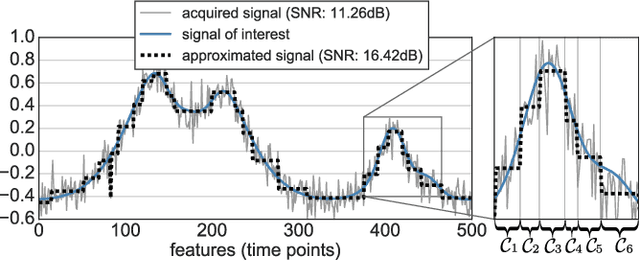
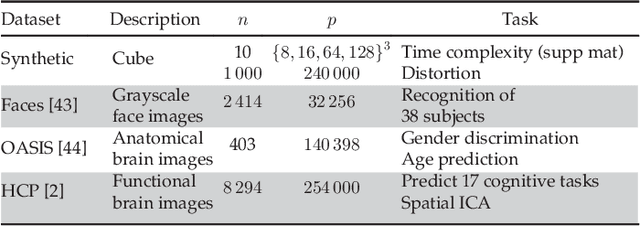
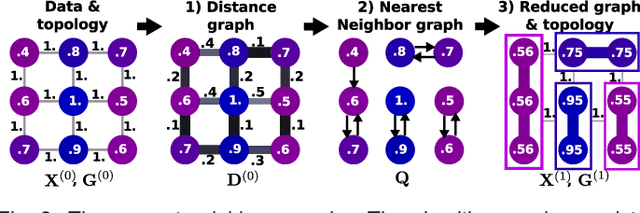
In this work, we revisit fast dimension reduction approaches, as with random projections and random sampling. Our goal is to summarize the data to decrease computational costs and memory footprint of subsequent analysis. Such dimension reduction can be very efficient when the signals of interest have a strong structure, such as with images. We focus on this setting and investigate feature clustering schemes for data reductions that capture this structure. An impediment to fast dimension reduction is that good clustering comes with large algorithmic costs. We address it by contributing a linear-time agglomerative clustering scheme, Recursive Nearest Agglomeration (ReNA). Unlike existing fast agglomerative schemes, it avoids the creation of giant clusters. We empirically validate that it approximates the data as well as traditional variance-minimizing clustering schemes that have a quadratic complexity. In addition, we analyze signal approximation with feature clustering and show that it can remove noise, improving subsequent analysis steps. As a consequence, data reduction by clustering features with ReNA yields very fast and accurate models, enabling to process large datasets on budget. Our theoretical analysis is backed by extensive experiments on publicly-available data that illustrate the computation efficiency and the denoising properties of the resulting dimension reduction scheme.
Learning Neural Representations of Human Cognition across Many fMRI Studies
Nov 11, 2017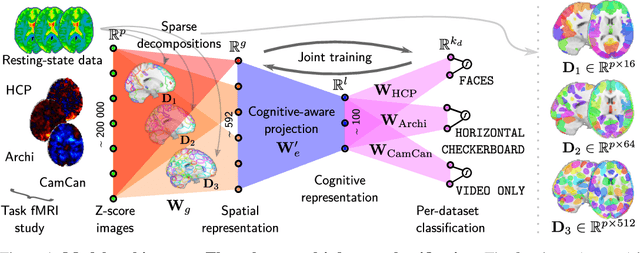
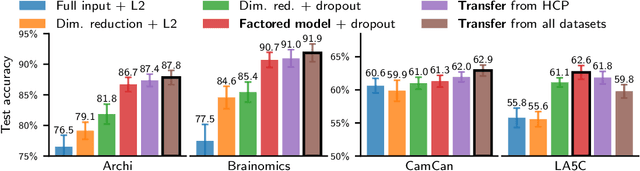
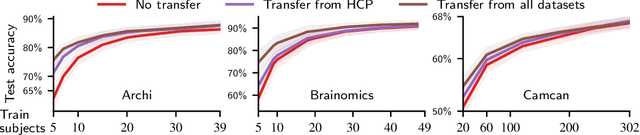

Cognitive neuroscience is enjoying rapid increase in extensive public brain-imaging datasets. It opens the door to large-scale statistical models. Finding a unified perspective for all available data calls for scalable and automated solutions to an old challenge: how to aggregate heterogeneous information on brain function into a universal cognitive system that relates mental operations/cognitive processes/psychological tasks to brain networks? We cast this challenge in a machine-learning approach to predict conditions from statistical brain maps across different studies. For this, we leverage multi-task learning and multi-scale dimension reduction to learn low-dimensional representations of brain images that carry cognitive information and can be robustly associated with psychological stimuli. Our multi-dataset classification model achieves the best prediction performance on several large reference datasets, compared to models without cognitive-aware low-dimension representations, it brings a substantial performance boost to the analysis of small datasets, and can be introspected to identify universal template cognitive concepts.
Stochastic Subsampling for Factorizing Huge Matrices
Oct 30, 2017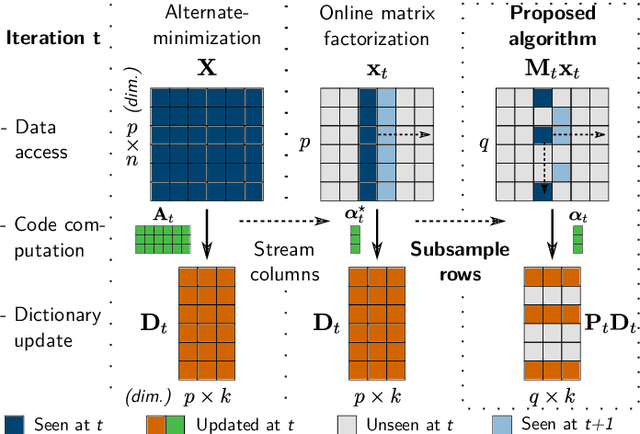
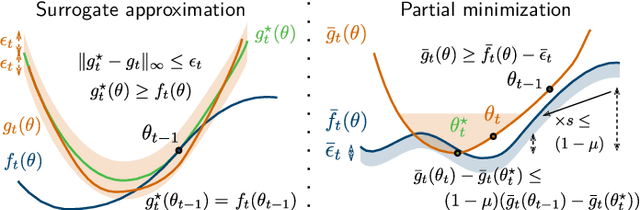
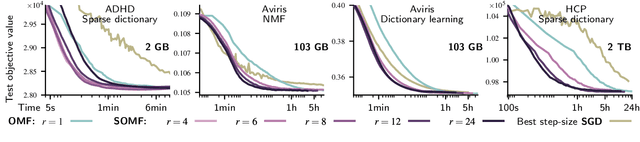
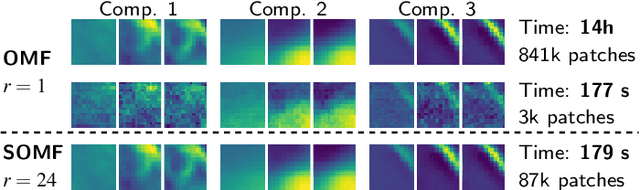
We present a matrix-factorization algorithm that scales to input matrices with both huge number of rows and columns. Learned factors may be sparse or dense and/or non-negative, which makes our algorithm suitable for dictionary learning, sparse component analysis, and non-negative matrix factorization. Our algorithm streams matrix columns while subsampling them to iteratively learn the matrix factors. At each iteration, the row dimension of a new sample is reduced by subsampling, resulting in lower time complexity compared to a simple streaming algorithm. Our method comes with convergence guarantees to reach a stationary point of the matrix-factorization problem. We demonstrate its efficiency on massive functional Magnetic Resonance Imaging data (2 TB), and on patches extracted from hyperspectral images (103 GB). For both problems, which involve different penalties on rows and columns, we obtain significant speed-ups compared to state-of-the-art algorithms.
* IEEE Transactions on Signal Processing, Institute of Electrical and Electronics Engineers, A Para\^itre
Subsampled online matrix factorization with convergence guarantees
Nov 30, 2016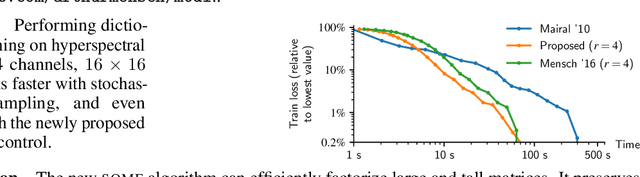
We present a matrix factorization algorithm that scales to input matrices that are large in both dimensions (i.e., that contains morethan 1TB of data). The algorithm streams the matrix columns while subsampling them, resulting in low complexity per iteration andreasonable memory footprint. In contrast to previous online matrix factorization methods, our approach relies on low-dimensional statistics from past iterates to control the extra variance introduced by subsampling. We present a convergence analysis that guarantees us to reach a stationary point of the problem. Large speed-ups can be obtained compared to previous online algorithms that do not perform subsampling, thanks to the feature redundancy that often exists in high-dimensional settings.
Deriving reproducible biomarkers from multi-site resting-state data: An Autism-based example
Nov 18, 2016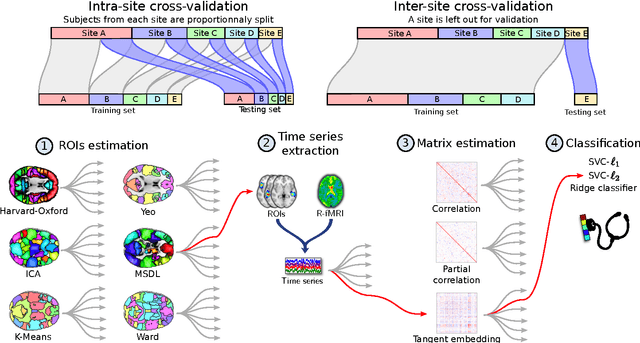
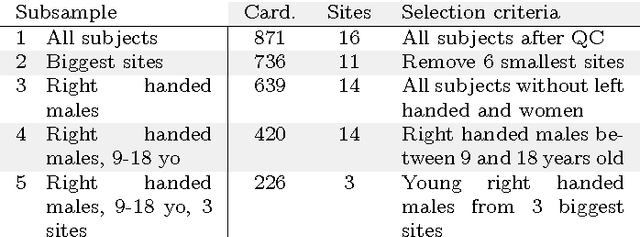
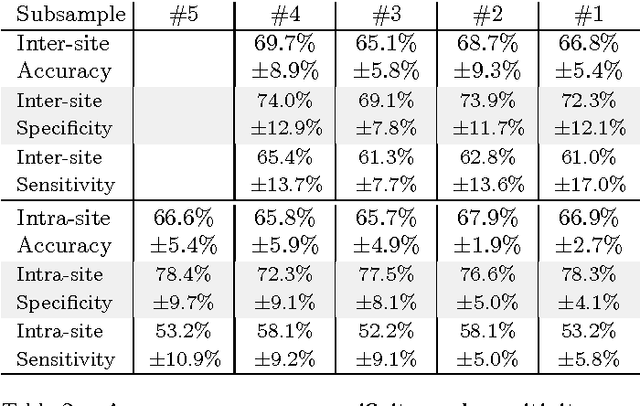
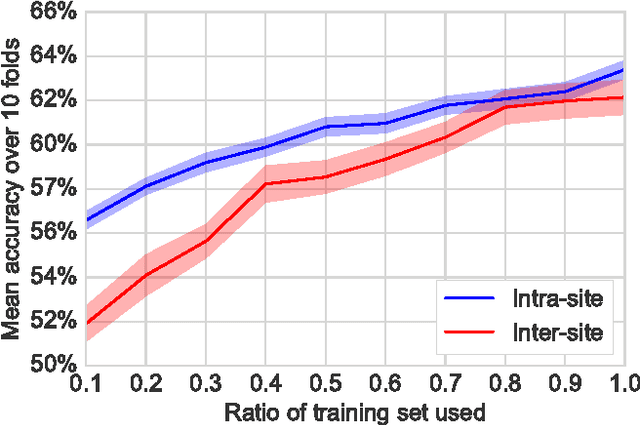
Resting-state functional Magnetic Resonance Imaging (R-fMRI) holds the promise to reveal functional biomarkers of neuropsychiatric disorders. However, extracting such biomarkers is challenging for complex multi-faceted neuropatholo-gies, such as autism spectrum disorders. Large multi-site datasets increase sample sizes to compensate for this complexity, at the cost of uncontrolled heterogeneity. This heterogeneity raises new challenges, akin to those face in realistic diagnostic applications. Here, we demonstrate the feasibility of inter-site classification of neuropsychiatric status, with an application to the Autism Brain Imaging Data Exchange (ABIDE) database, a large (N=871) multi-site autism dataset. For this purpose, we investigate pipelines that extract the most predictive biomarkers from the data. These R-fMRI pipelines build participant-specific connectomes from functionally-defined brain areas. Connectomes are then compared across participants to learn patterns of connectivity that differentiate typical controls from individuals with autism. We predict this neuropsychiatric status for participants from the same acquisition sites or different, unseen, ones. Good choices of methods for the various steps of the pipeline lead to 67% prediction accuracy on the full ABIDE data, which is significantly better than previously reported results. We perform extensive validation on multiple subsets of the data defined by different inclusion criteria. These enables detailed analysis of the factors contributing to successful connectome-based prediction. First, prediction accuracy improves as we include more subjects, up to the maximum amount of subjects available. Second, the definition of functional brain areas is of paramount importance for biomarker discovery: brain areas extracted from large R-fMRI datasets outperform reference atlases in the classification tasks.