 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability Beyond Classification Output: Semantic Bottleneck Networks
Jul 28, 2019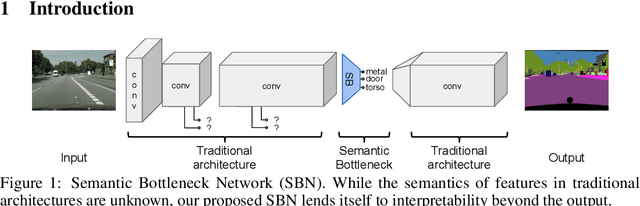
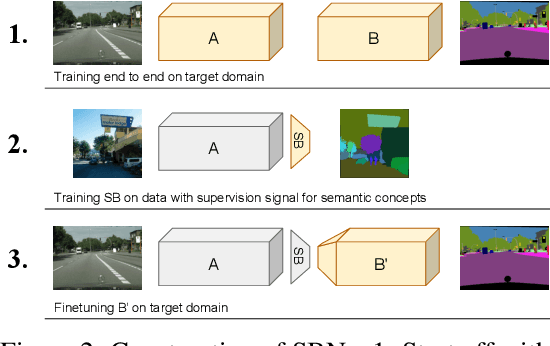
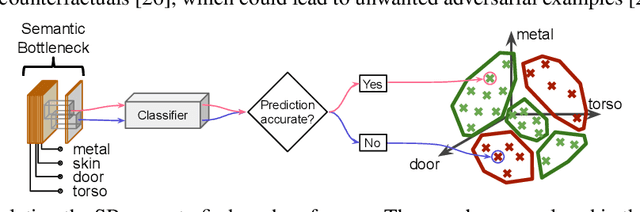

Today's deep learning systems deliver high performance based on end-to-end training. While they deliver strong performance, these systems are hard to interpret. To address this issue, we propose Semantic Bottleneck Networks (SBN): deep networks with semantically interpretable intermediate layers that all downstream results are based on. As a consequence, the analysis on what the final prediction is based on is transparent to the engineer and failure cases and modes can be analyzed and avoided by high-level reasoning. We present a case study on street scene segmentation to demonstrate the feasibility and power of SBN. In particular, we start from a well performing classic deep network which we adapt to house a SB-Layer containing task related semantic concepts (such as object-parts and materials). Importantly, we can recover state of the art performance despite a drastic dimensionality reduction from 1000s (non-semantic feature) to 10s (semantic concept) channels. Additionally we show how the activations of the SB-Layer can be used for both the interpretation of failure cases of the network as well as for confidence prediction of the resulting output. For the first time, e.g., we show interpretable segmentation results for most predictions at over 99% accuracy.
Prediction Poisoning: Utility-Constrained Defenses Against Model Stealing Attacks
Jun 26, 2019



With the advances of ML models in recent years, we are seeing an increasing number of real-world commercial applications and services e.g., autonomous vehicles, medical equipment, web APIs emerge. Recent advances in model functionality stealing attacks via black-box access (i.e., inputs in, predictions out) threaten the business model of such ML applications, which require a lot of time, money, and effort to develop. In this paper, we address the issue by studying defenses for model stealing attacks, largely motivated by a lack of effective defenses in literature. We work towards the first defense which introduces targeted perturbations to the model predictions under a utility constraint. Our approach introduces the perturbations targeted towards manipulating the training procedure of the attacker. We evaluate our approach on multiple datasets and attack scenarios across a range of utility constrains. Our results show that it is indeed possible to trade-off utility (e.g., deviation from original prediction, test accuracy) to significantly reduce effectiveness of model stealing attacks.
Learning to Self-Train for Semi-Supervised Few-Shot Classification
Jun 03, 2019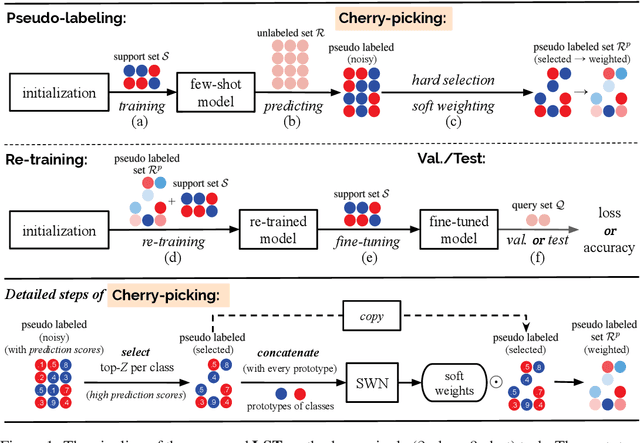
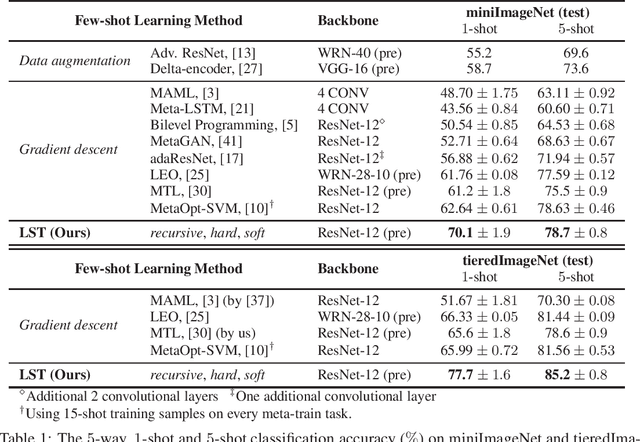
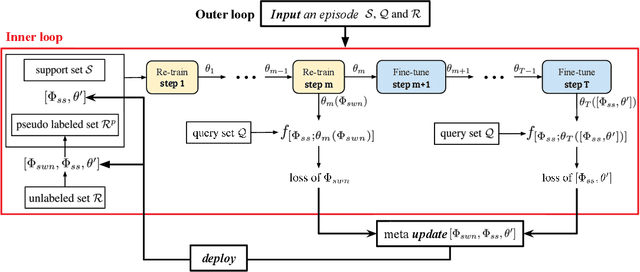
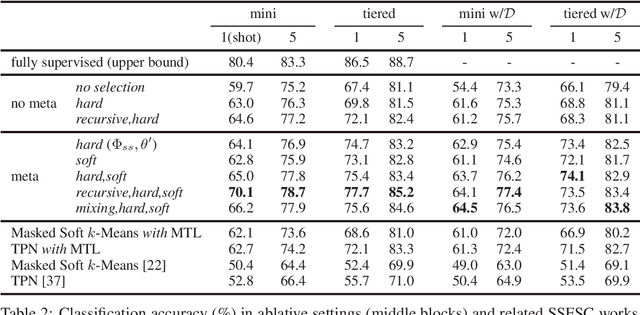
Few-shot classification (FSC) is challenging due to the scarcity of labeled training data (e.g. only one labeled data point per class). Meta-learning has shown to achieve promising results by learning to initialize a classification model for FSC. In this paper we propose a novel semi-supervised meta-learning method called learning to self-train (LST) that leverages unlabeled data and specifically meta-learns how to cherry-pick and label such unsupervised data to further improve performance. To this end, we train the LST model through a large number of semi-supervised few-shot tasks. On each task, we train a few-shot model to predict pseudo labels for unlabeled data, and then iterate the self-training steps on labeled and pseudo-labeled data with each step followed by fine-tuning. We additionally learn a soft weighting network (SWN) to optimize the self-training weights of pseudo labels so that better ones can contribute more to gradient descent optimization. We evaluate our LST method on two ImageNet benchmarks for semi-supervised few-shot classification and achieve large improvements over the state-of-the-art.
A Novel BiLevel Paradigm for Image-to-Image Translation
Apr 18, 2019
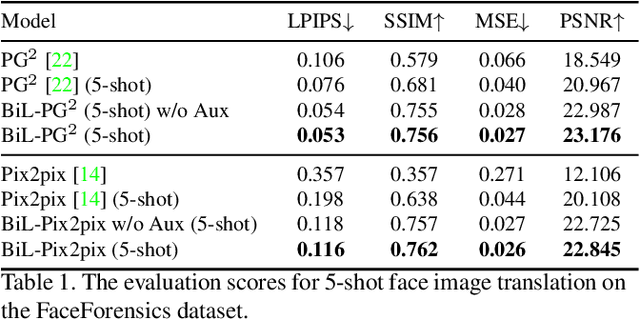
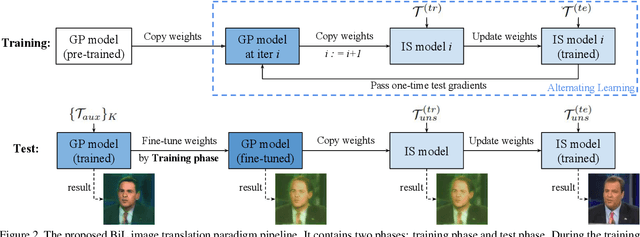
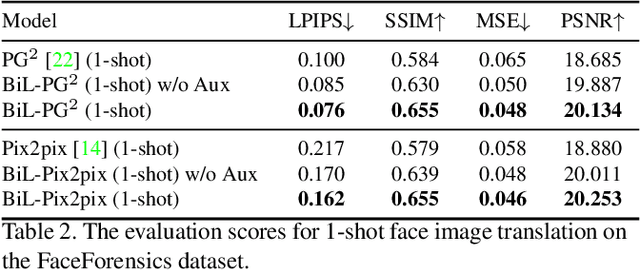
Image-to-image (I2I) translation is a pixel-level mapping that requires a large number of paired training data and often suffers from the problems of high diversity and strong category bias in image scenes. In order to tackle these problems, we propose a novel BiLevel (BiL) learning paradigm that alternates the learning of two models, respectively at an instance-specific (IS) and a general-purpose (GP) level. In each scene, the IS model learns to maintain the specific scene attributes. It is initialized by the GP model that learns from all the scenes to obtain the generalizable translation knowledge. This GP initialization gives the IS model an efficient starting point, thus enabling its fast adaptation to the new scene with scarce training data. We conduct extensive I2I translation experiments on human face and street view datasets. Quantitative results validate that our approach can significantly boost the performance of classical I2I translation models, such as PG2 and Pix2Pix. Our visualization results show both higher image quality and more appropriate instance-specific details, e.g., the translated image of a person looks more like that person in terms of identity.
LCC: Learning to Customize and Combine Neural Networks for Few-Shot Learning
Apr 17, 2019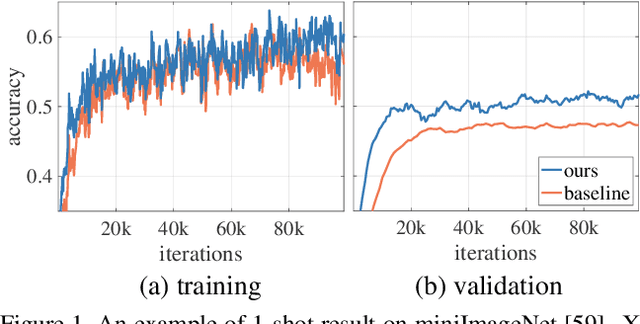
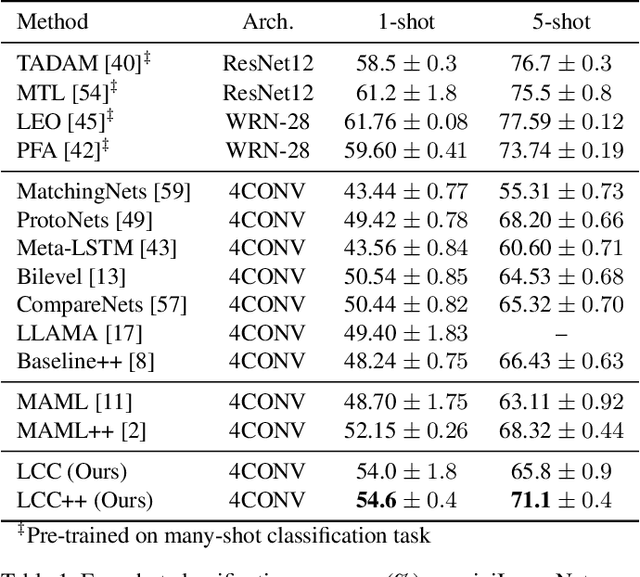
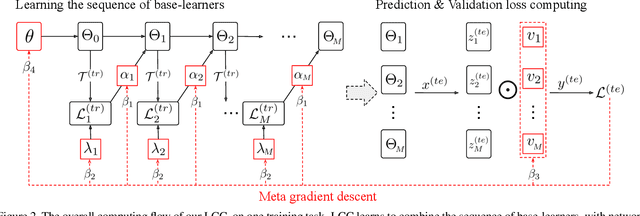
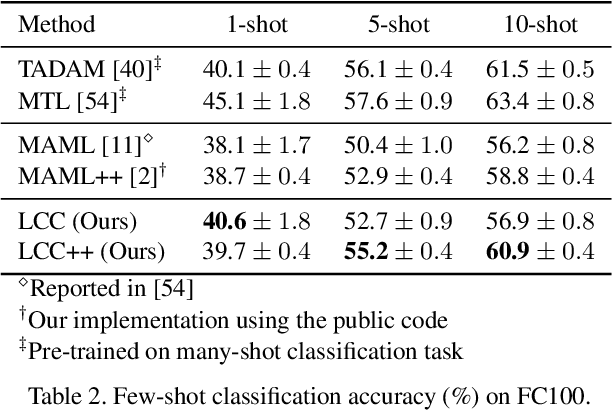
Meta-learning has been shown to be an effective strategy for few-shot learning. The key idea is to leverage a large number of similar few-shot tasks in order to meta-learn how to best initiate a (single) base-learner for novel few-shot tasks. While meta-learning how to initialize a base-learner has shown promising results, it is well known that hyperparameter settings such as the learning rate and the weighting of the regularization term are important to achieve best performance. We thus propose to also meta-learn these hyperparameters and in fact learn a time- and layer-varying scheme for learning a base-learner on novel tasks. Additionally, we propose to learn not only a single base-learner but an ensemble of several base-learners to obtain more robust results. While ensembles of learners have shown to improve performance in various settings, this is challenging for few-shot learning tasks due to the limited number of training samples. Therefore, our approach also aims to meta-learn how to effectively combine several base-learners. We conduct extensive experiments and report top performance for five-class few-shot recognition tasks on two challenging benchmarks: miniImageNet and Fewshot-CIFAR100 (FC100).
f-VAEGAN-D2: A Feature Generating Framework for Any-Shot Learning
Mar 25, 2019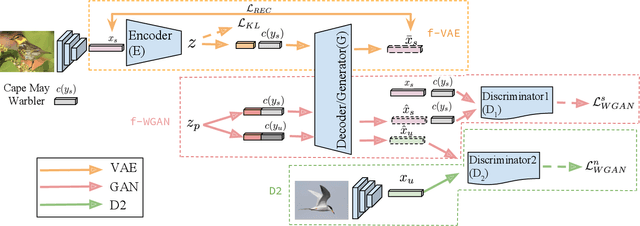
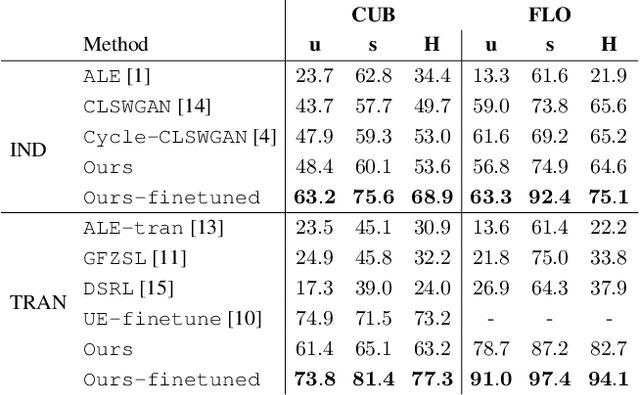
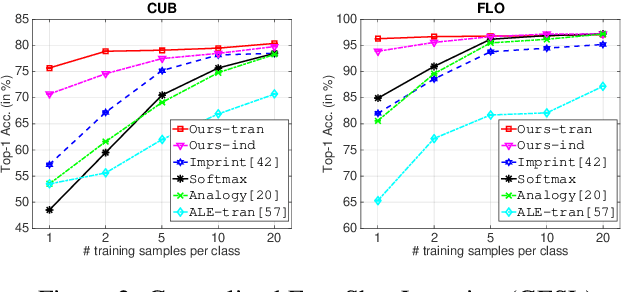
When labeled training data is scarce, a promising data augmentation approach is to generate visual features of unknown classes using their attributes. To learn the class conditional distribution of CNN features, these models rely on pairs of image features and class attributes. Hence, they can not make use of the abundance of unlabeled data samples. In this paper, we tackle any-shot learning problems i.e. zero-shot and few-shot, in a unified feature generating framework that operates in both inductive and transductive learning settings. We develop a conditional generative model that combines the strength of VAE and GANs and in addition, via an unconditional discriminator, learns the marginal feature distribution of unlabeled images. We empirically show that our model learns highly discriminative CNN features for five datasets, i.e. CUB, SUN, AWA and ImageNet, and establish a new state-of-the-art in any-shot learning, i.e. inductive and transductive (generalized) zero- and few-shot learning settings. We also demonstrate that our learned features are interpretable: we visualize them by inverting them back to the pixel space and we explain them by generating textual arguments of why they are associated with a certain label.
Not Using the Car to See the Sidewalk: Quantifying and Controlling the Effects of Context in Classification and Segmentation
Dec 17, 2018
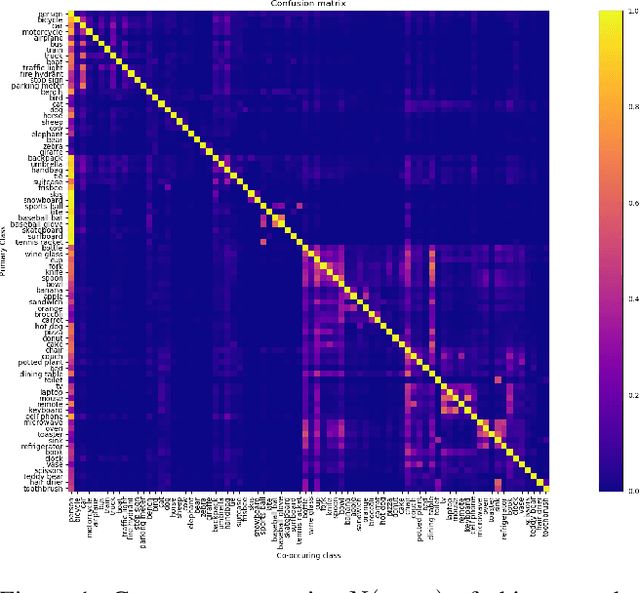

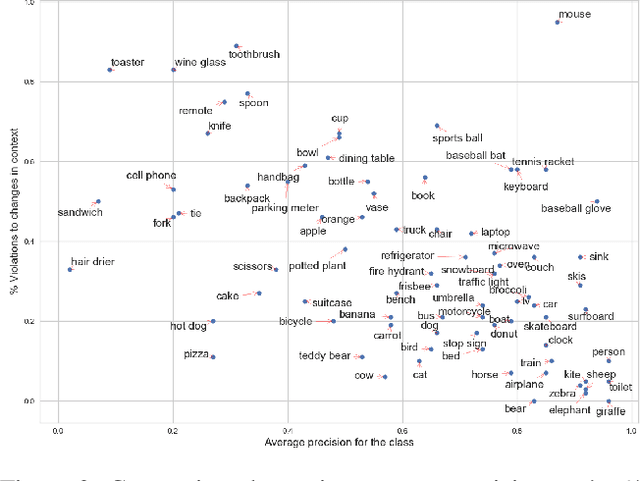
Importance of visual context in scene understanding tasks is well recognized in the computer vision community. However, to what extent the computer vision models for image classification and semantic segmentation are dependent on the context to make their predictions is unclear. A model overly relying on context will fail when encountering objects in context distributions different from training data and hence it is important to identify these dependencies before we can deploy the models in the real-world. We propose a method to quantify the sensitivity of black-box vision models to visual context by editing images to remove selected objects and measuring the response of the target models. We apply this methodology on two tasks, image classification and semantic segmentation, and discover undesirable dependency between objects and context, for example that "sidewalk" segmentation relies heavily on "cars" being present in the image. We propose an object removal based data augmentation solution to mitigate this dependency and increase the robustness of classification and segmentation models to contextual variations. Our experiments show that the proposed data augmentation helps these models improve the performance in out-of-context scenarios, while preserving the performance on regular data.
Meta-Transfer Learning for Few-Shot Learning
Dec 07, 2018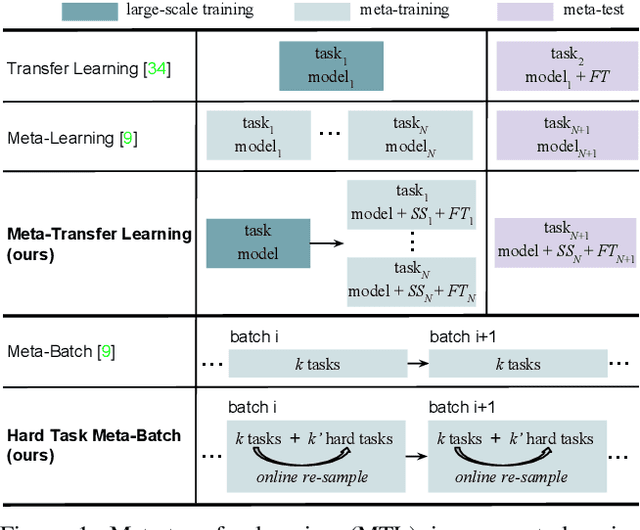
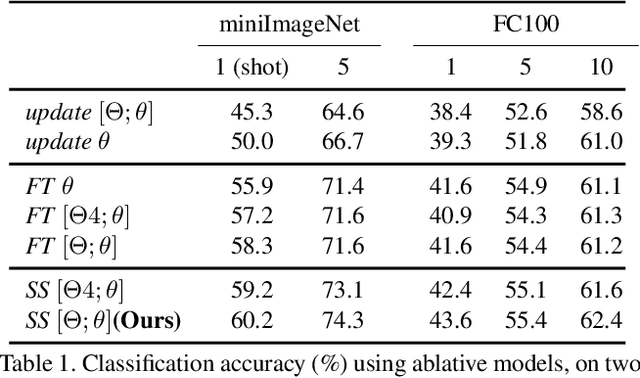

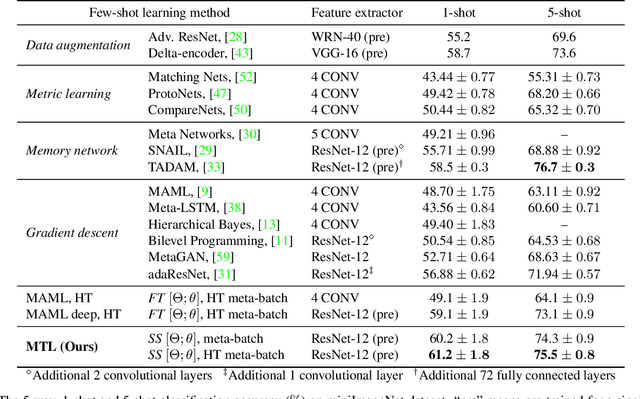
Meta-learning has been proposed as a framework to address the challenging few-shot learning setting. The key idea is to leverage a large number of similar few-shot tasks in order to learn how to adapt a base-learner to a new task for which only a few labeled samples are available. As deep neural networks (DNNs) tend to overfit using a few samples only, meta-learning typically uses shallow neural networks (SNNs), thus limiting its effectiveness. In this paper we propose a novel few-shot learning method called meta-transfer learning (MTL) which learns to adapt a deep NN for few shot learning tasks. Specifically, "meta" refers to training multiple tasks, and "transfer" is achieved by learning scaling and shifting functions of DNN weights for each task. In addition, we introduce the hard task (HT) meta-batch scheme as an effective learning curriculum for MTL. We conduct experiments using (5-class, 1-shot) and (5-class, 5-shot) recognition tasks on two challenging few-shot learning benchmarks: miniImageNet and Fewshot-CIFAR100. Extensive comparisons to related works validate that our meta-transfer learning approach trained with the proposed HT meta-batch scheme achieves top performance. An ablation study also shows that both components contribute to fast convergence and high accuracy.
Knockoff Nets: Stealing Functionality of Black-Box Models
Dec 06, 2018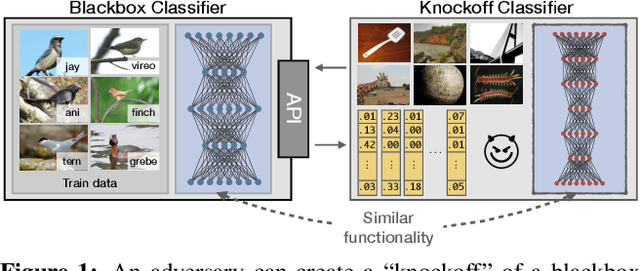

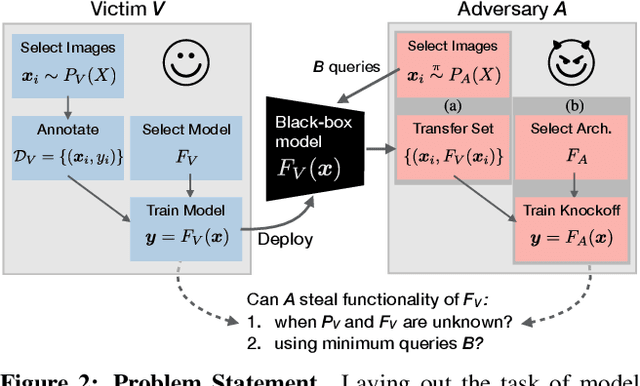

Machine Learning (ML) models are increasingly deployed in the wild to perform a wide range of tasks. In this work, we ask to what extent can an adversary steal functionality of such "victim" models based solely on blackbox interactions: image in, predictions out. In contrast to prior work, we present an adversary lacking knowledge of train/test data used by the model, its internals, and semantics over model outputs. We formulate model functionality stealing as a two-step approach: (i) querying a set of input images to the blackbox model to obtain predictions; and (ii) training a "knockoff" with queried image-prediction pairs. We make multiple remarkable observations: (a) querying random images from a different distribution than that of the blackbox training data results in a well-performing knockoff; (b) this is possible even when the knockoff is represented using a different architecture; and (c) our reinforcement learning approach additionally improves query sample efficiency in certain settings and provides performance gains. We validate model functionality stealing on a range of datasets and tasks, as well as on a popular image analysis API where we create a reasonable knockoff for as little as $30.
Disentangling Adversarial Robustness and Generalization
Dec 03, 2018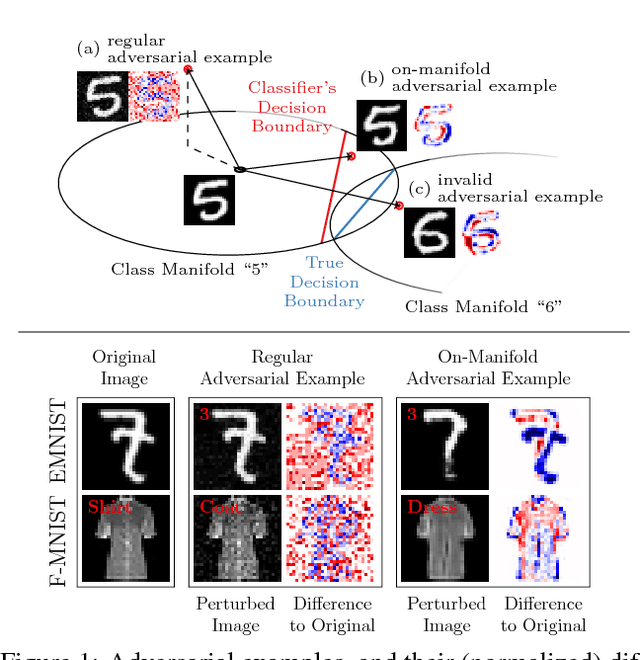

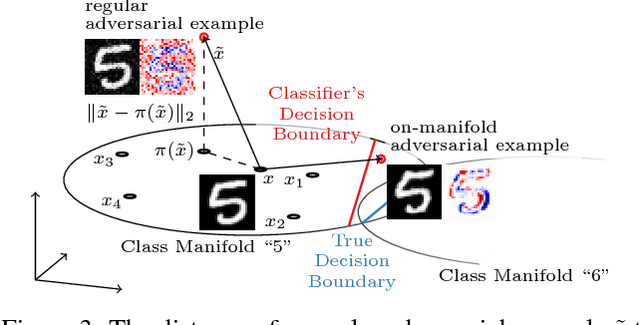

Obtaining deep networks that are robust against adversarial examples and generalize well is an open problem. A recent hypothesis even states that both robust and accurate models are impossible, i.e., adversarial robustness and generalization are conflicting goals. In an effort to clarify the relationship between robustness and generalization, we assume an underlying, low-dimensional data manifold and show that: 1. regular adversarial examples leave the manifold; 2. adversarial examples constrained to the manifold, i.e., on-manifold adversarial examples, exist; 3. on-manifold adversarial examples are generalization errors, and on-manifold adversarial training boosts generalization; 4. and regular robustness is independent of generalization. These assumptions imply that both robust and accurate models are possible. However, different models (architectures, training strategies etc.) can exhibit different robustness and generalization characteristics. To confirm our claims, we present extensive experiments on synthetic data (with access to the true manifold) as well as on EMNIST, Fashion-MNIST and CelebA.