 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeking Similarities over Differences: Similarity-based Domain Alignment for Adaptive Object Detection
Oct 04, 2021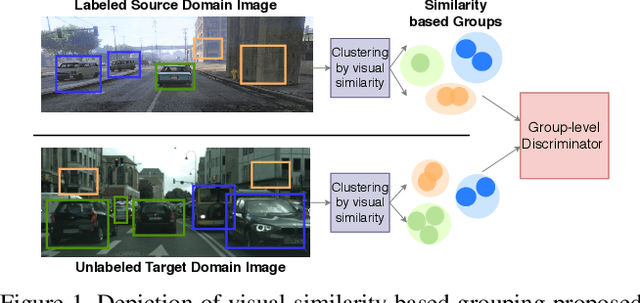
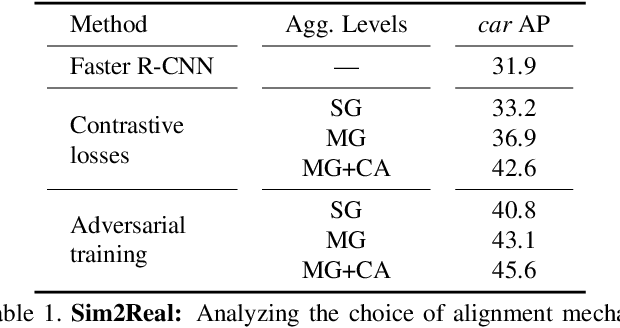
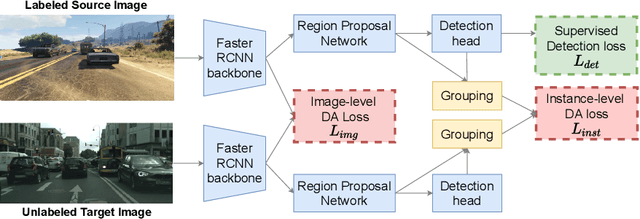

In order to robustly deploy object detectors across a wide range of scenarios, they should be adaptable to shifts in the input distribution without the need to constantly annotate new data. This has motivated research in Unsupervised Domain Adaptation (UDA) algorithms for detection. UDA methods learn to adapt from labeled source domains to unlabeled target domains, by inducing alignment between detector features from source and target domains. Yet, there is no consensus on what features to align and how to do the alignment. In our work, we propose a framework that generalizes the different components commonly used by UDA methods laying the ground for an in-depth analysis of the UDA design space. Specifically, we propose a novel UDA algorithm, ViSGA, a direct implementation of our framework, that leverages the best design choices and introduces a simple but effective method to aggregate features at instance-level based on visual similarity before inducing group alignment via adversarial training. We show that both similarity-based grouping and adversarial training allows our model to focus on coarsely aligning feature groups, without being forced to match all instances across loosely aligned domains. Finally, we examine the applicability of ViSGA to the setting where labeled data are gathered from different sources. Experiments show that not only our method outperforms previous single-source approaches on Sim2Real and Adverse Weather, but also generalizes well to the multi-source setting.
Optimising for Interpretability: Convolutional Dynamic Alignment Networks
Sep 27, 2021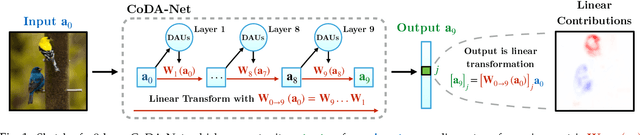
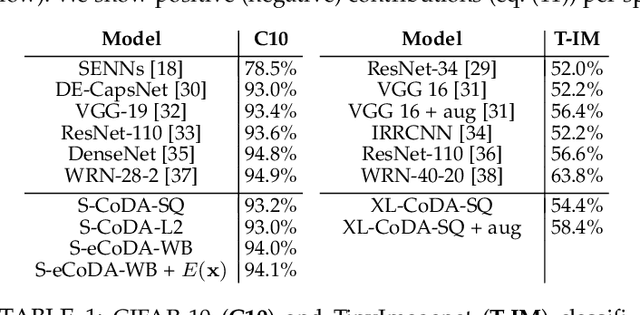
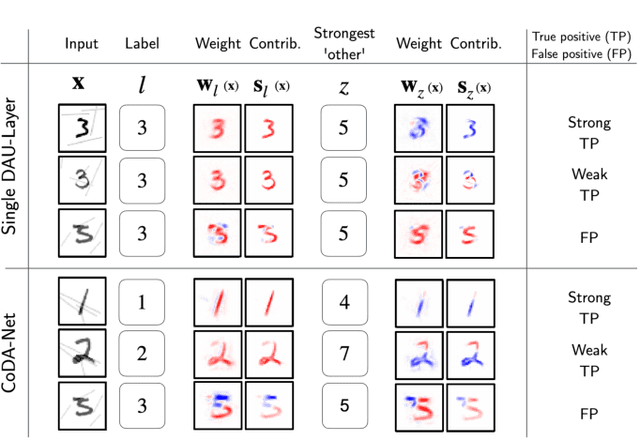
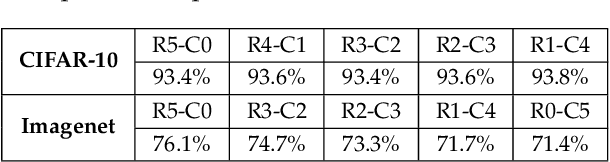
We introduce a new family of neural network models called Convolutional Dynamic Alignment Networks (CoDA Nets), which are performant classifiers with a high degree of inherent interpretability. Their core building blocks are Dynamic Alignment Units (DAUs), which are optimised to transform their inputs with dynamically computed weight vectors that align with task-relevant patterns. As a result, CoDA Nets model the classification prediction through a series of input-dependent linear transformations, allowing for linear decomposition of the output into individual input contributions. Given the alignment of the DAUs, the resulting contribution maps align with discriminative input patterns. These model-inherent decompositions are of high visual quality and outperform existing attribution methods under quantitative metrics. Further, CoDA Nets constitute performant classifiers, achieving on par results to ResNet and VGG models on e.g. CIFAR-10 and TinyImagenet. Lastly, CoDA Nets can be combined with conventional neural network models to yield powerful classifiers that more easily scale to complex datasets such as Imagenet whilst exhibiting an increased interpretable depth, i.e., the output can be explained well in terms of contributions from intermediate layers within the network.
Generalized and Incremental Few-Shot Learning by Explicit Learning and Calibration without Forgetting
Aug 18, 2021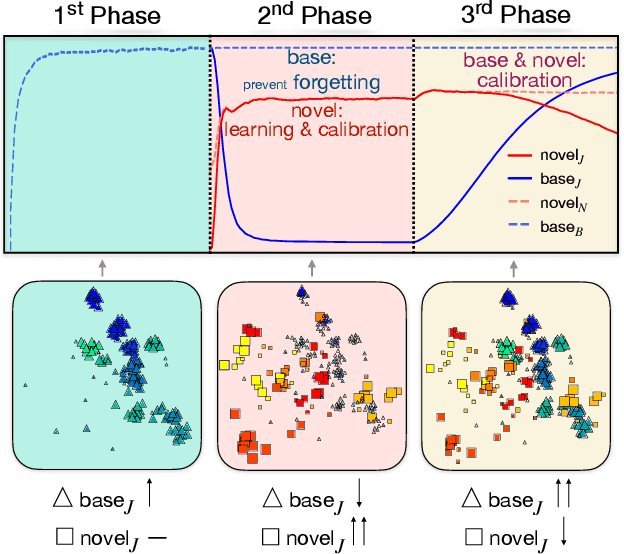
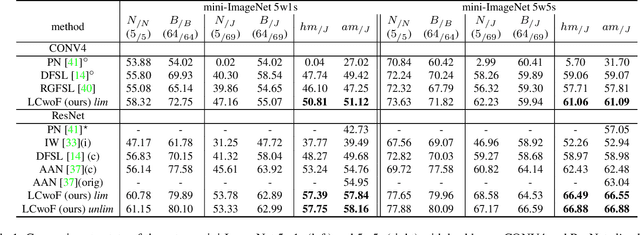
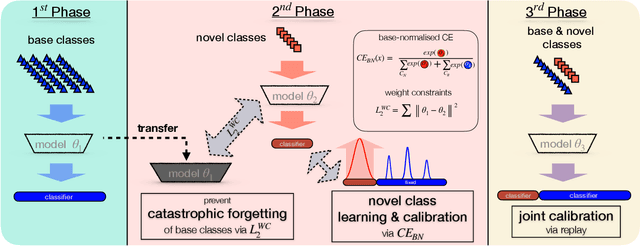
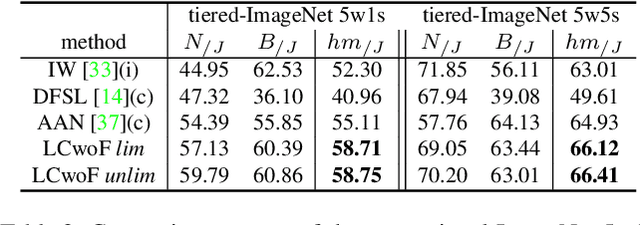
Both generalized and incremental few-shot learning have to deal with three major challenges: learning novel classes from only few samples per class, preventing catastrophic forgetting of base classes, and classifier calibration across novel and base classes. In this work we propose a three-stage framework that allows to explicitly and effectively address these challenges. While the first phase learns base classes with many samples, the second phase learns a calibrated classifier for novel classes from few samples while also preventing catastrophic forgetting. In the final phase, calibration is achieved across all classes. We evaluate the proposed framework on four challenging benchmark datasets for image and video few-shot classification and obtain state-of-the-art results for both generalized and incremental few shot learning.
Euro-PVI: Pedestrian Vehicle Interactions in Dense Urban Centers
Jun 22, 2021
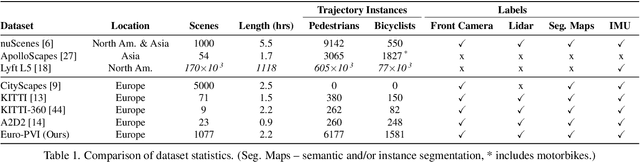
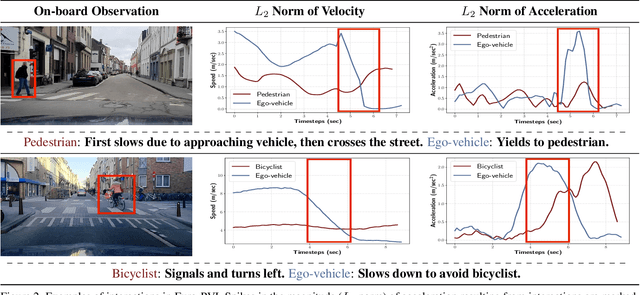
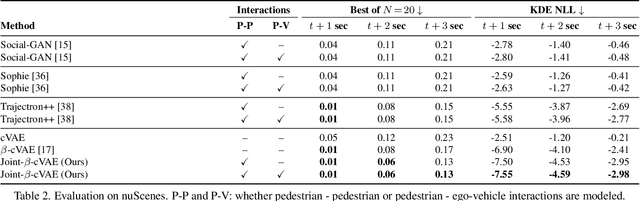
Accurate prediction of pedestrian and bicyclist paths is integral to the development of reliable autonomous vehicles in dense urban environments. The interactions between vehicle and pedestrian or bicyclist have a significant impact on the trajectories of traffic participants e.g. stopping or turning to avoid collisions. Although recent datasets and trajectory prediction approaches have fostered the development of autonomous vehicles yet the amount of vehicle-pedestrian (bicyclist) interactions modeled are sparse. In this work, we propose Euro-PVI, a dataset of pedestrian and bicyclist trajectories. In particular, our dataset caters more diverse and complex interactions in dense urban scenarios compared to the existing datasets. To address the challenges in predicting future trajectories with dense interactions, we develop a joint inference model that learns an expressive multi-modal shared latent space across agents in the urban scene. This enables our Joint-$\beta$-cVAE approach to better model the distribution of future trajectories. We achieve state of the art results on the nuScenes and Euro-PVI datasets demonstrating the importance of capturing interactions between ego-vehicle and pedestrians (bicyclists) for accurate predictions.
Random and Adversarial Bit Error Robustness: Energy-Efficient and Secure DNN Accelerators
Apr 16, 2021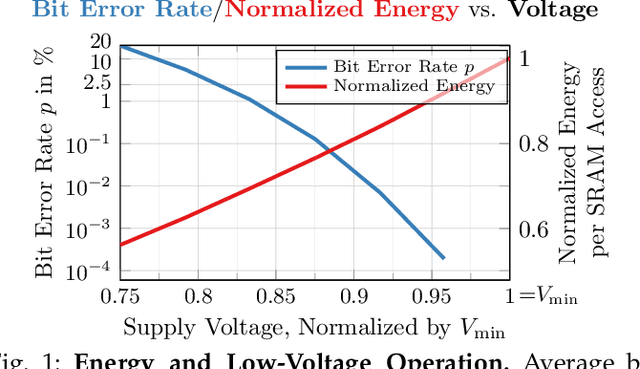
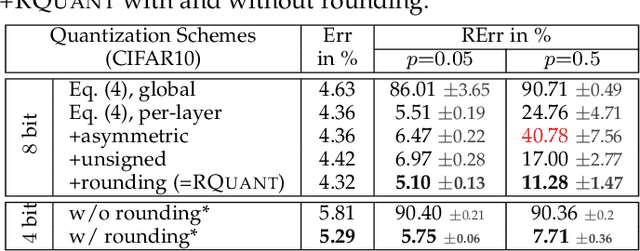
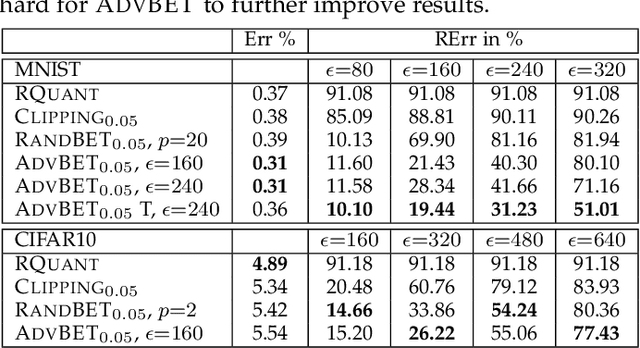
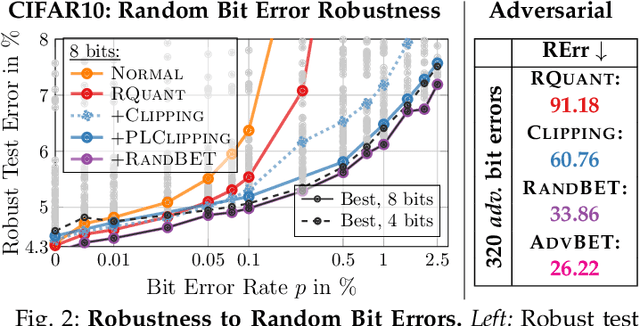
Deep neural network (DNN) accelerators received considerable attention in recent years due to the potential to save energy compared to mainstream hardware. Low-voltage operation of DNN accelerators allows to further reduce energy consumption significantly, however, causes bit-level failures in the memory storing the quantized DNN weights. Furthermore, DNN accelerators have been shown to be vulnerable to adversarial attacks on voltage controllers or individual bits. In this paper, we show that a combination of robust fixed-point quantization, weight clipping, as well as random bit error training (RandBET) or adversarial bit error training (AdvBET) improves robustness against random or adversarial bit errors in quantized DNN weights significantly. This leads not only to high energy savings for low-voltage operation as well as low-precision quantization, but also improves security of DNN accelerators. Our approach generalizes across operating voltages and accelerators, as demonstrated on bit errors from profiled SRAM arrays, and achieves robustness against both targeted and untargeted bit-level attacks. Without losing more than 0.8%/2% in test accuracy, we can reduce energy consumption on CIFAR10 by 20%/30% for 8/4-bit quantization using RandBET. Allowing up to 320 adversarial bit errors, AdvBET reduces test error from above 90% (chance level) to 26.22% on CIFAR10.
Relating Adversarially Robust Generalization to Flat Minima
Apr 09, 2021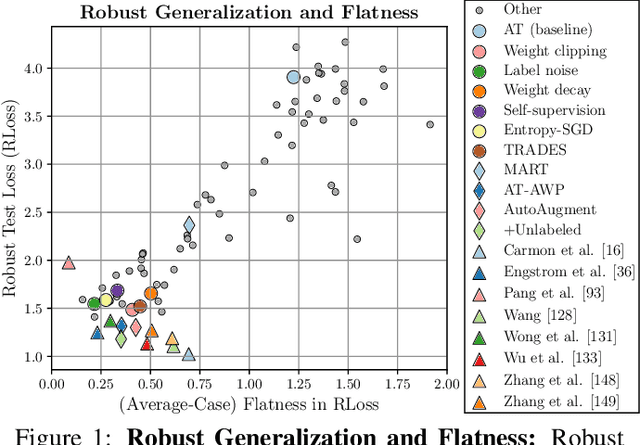
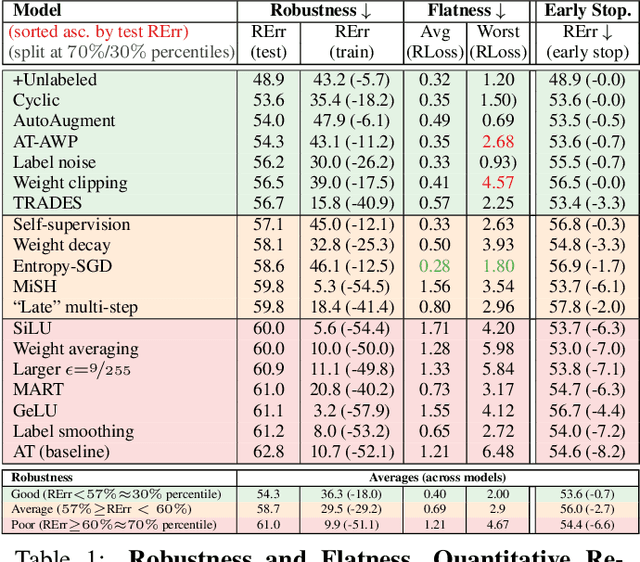
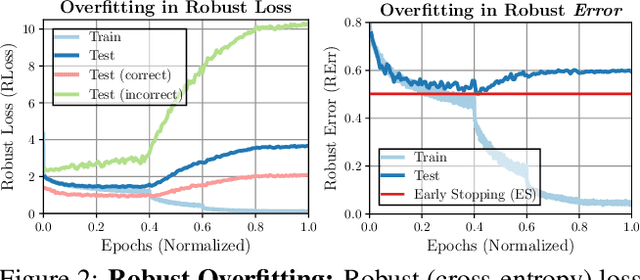

Adversarial training (AT) has become the de-facto standard to obtain models robust against adversarial examples. However, AT exhibits severe robust overfitting: cross-entropy loss on adversarial examples, so-called robust loss, decreases continuously on training examples, while eventually increasing on test examples. In practice, this leads to poor robust generalization, i.e., adversarial robustness does not generalize well to new examples. In this paper, we study the relationship between robust generalization and flatness of the robust loss landscape in weight space, i.e., whether robust loss changes significantly when perturbing weights. To this end, we propose average- and worst-case metrics to measure flatness in the robust loss landscape and show a correlation between good robust generalization and flatness. For example, throughout training, flatness reduces significantly during overfitting such that early stopping effectively finds flatter minima in the robust loss landscape. Similarly, AT variants achieving higher adversarial robustness also correspond to flatter minima. This holds for many popular choices, e.g., AT-AWP, TRADES, MART, AT with self-supervision or additional unlabeled examples, as well as simple regularization techniques, e.g., AutoAugment, weight decay or label noise. For fair comparison across these approaches, our flatness measures are specifically designed to be scale-invariant and we conduct extensive experiments to validate our findings.
Convolutional Dynamic Alignment Networks for Interpretable Classifications
Mar 31, 2021
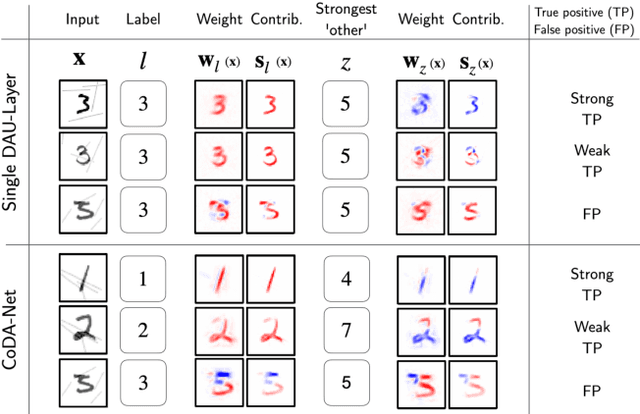

We introduce a new family of neural network models called Convolutional Dynamic Alignment Networks (CoDA-Nets), which are performant classifiers with a high degree of inherent interpretability. Their core building blocks are Dynamic Alignment Units (DAUs), which linearly transform their input with weight vectors that dynamically align with task-relevant patterns. As a result, CoDA-Nets model the classification prediction through a series of input-dependent linear transformations, allowing for linear decomposition of the output into individual input contributions. Given the alignment of the DAUs, the resulting contribution maps align with discriminative input patterns. These model-inherent decompositions are of high visual quality and outperform existing attribution methods under quantitative metrics. Further, CoDA-Nets constitute performant classifiers, achieving on par results to ResNet and VGG models on e.g. CIFAR-10 and TinyImagenet.
Deep Wiener Deconvolution: Wiener Meets Deep Learning for Image Deblurring
Mar 18, 2021
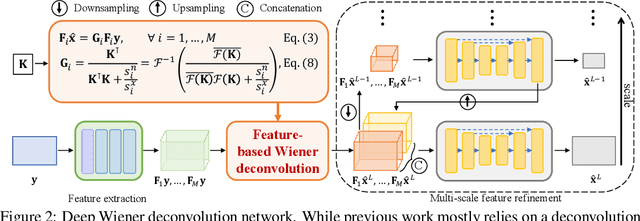
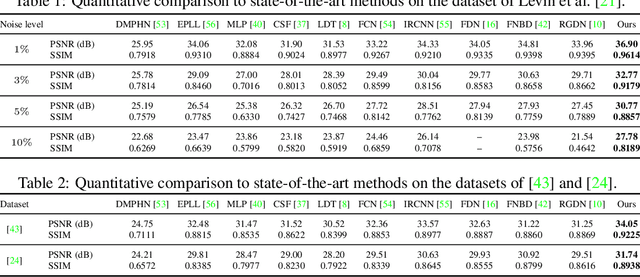

We present a simple and effective approach for non-blind image deblurring, combining classical techniques and deep learning. In contrast to existing methods that deblur the image directly in the standard image space, we propose to perform an explicit deconvolution process in a feature space by integrating a classical Wiener deconvolution framework with learned deep features. A multi-scale feature refinement module then predicts the deblurred image from the deconvolved deep features, progressively recovering detail and small-scale structures. The proposed model is trained in an end-to-end manner and evaluated on scenarios with both simulated and real-world image blur. Our extensive experimental results show that the proposed deep Wiener deconvolution network facilitates deblurred results with visibly fewer artifacts. Moreover, our approach quantitatively outperforms state-of-the-art non-blind image deblurring methods by a wide margin.
Adjoint Rigid Transform Network: Self-supervised Alignment of 3D Shapes
Feb 01, 2021
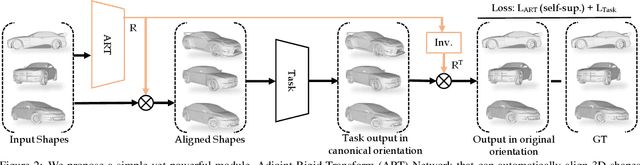
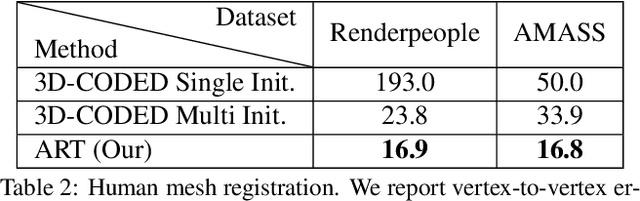
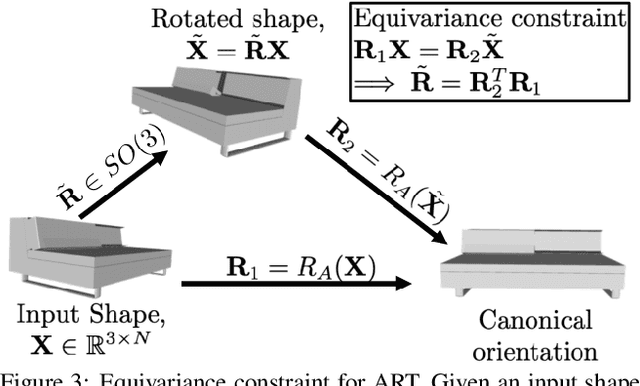
Most learning methods for 3D data (point clouds, meshes) suffer significant performance drops when the data is not carefully aligned to a canonical orientation. Aligning real world 3D data collected from different sources is non-trivial and requires manual intervention. In this paper, we propose the Adjoint Rigid Transform (ART) Network, a neural module which can be integrated with existing 3D networks to significantly boost their performance in tasks such as shape reconstruction, non-rigid registration, and latent disentanglement. ART learns to rotate input shapes to a canonical orientation that is crucial for a lot of tasks. ART achieves this by imposing rotation equivariance constraint on input shapes. The remarkable result is that with only self-supervision, ART can discover a unique canonical orientation for both rigid and nonrigid objects, which leads to a notable boost in downstream task performance. We will release our code and pre-trained models for further research.
You Only Need Adversarial Supervision for Semantic Image Synthesis
Dec 08, 2020
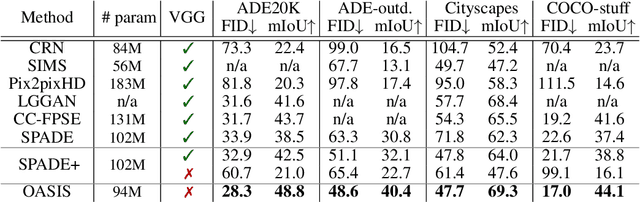

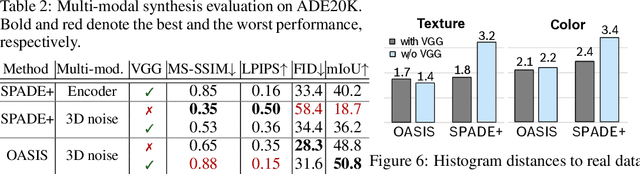
Despite their recent successes, GAN models for semantic image synthesis still suffer from poor image quality when trained with only adversarial supervision. Historically, additionally employing the VGG-based perceptual loss has helped to overcome this issue, significantly improving the synthesis quality, but at the same time limiting the progress of GAN models for semantic image synthesis. In this work, we propose a novel, simplified GAN model, which needs only adversarial supervision to achieve high quality results. We re-design the discriminator as a semantic segmentation network, directly using the given semantic label maps as the ground truth for training. By providing stronger supervision to the discriminator as well as to the generator through spatially- and semantically-aware discriminator feedback, we are able to synthesize images of higher fidelity with better alignment to their input label maps, making the use of the perceptual loss superfluous. Moreover, we enable high-quality multi-modal image synthesis through global and local sampling of a 3D noise tensor injected into the generator, which allows complete or partial image change. We show that images synthesized by our model are more diverse and follow the color and texture distributions of real images more closely. We achieve an average improvement of $6$ FID and $5$ mIoU points over the state of the art across different datasets using only adversarial supervision.