 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Trajectory Curvature of ODE-based Generative Models
Feb 05, 2023Recent ODE/SDE-based generative models, such as diffusion models, rectified flows, and flow matching, define a generative process as a time reversal of a fixed forward process. Even though these models show impressive performance on large-scale datasets, numerical simulation requires multiple evaluations of a neural network, leading to a slow sampling speed. We attribute the reason to the high curvature of the learned generative trajectories, as it is directly related to the truncation error of a numerical solver. Based on the relationship between the forward process and the curvature, here we present an efficient method of training the forward process to minimize the curvature of generative trajectories without any ODE/SDE simulation. Experiments show that our method achieves a lower curvature than previous models and, therefore, decreased sampling costs while maintaining competitive performance. Code is available at https://github.com/sangyun884/fast-ode.
Measuring and Improving Semantic Diversity of Dialogue Generation
Oct 11, 2022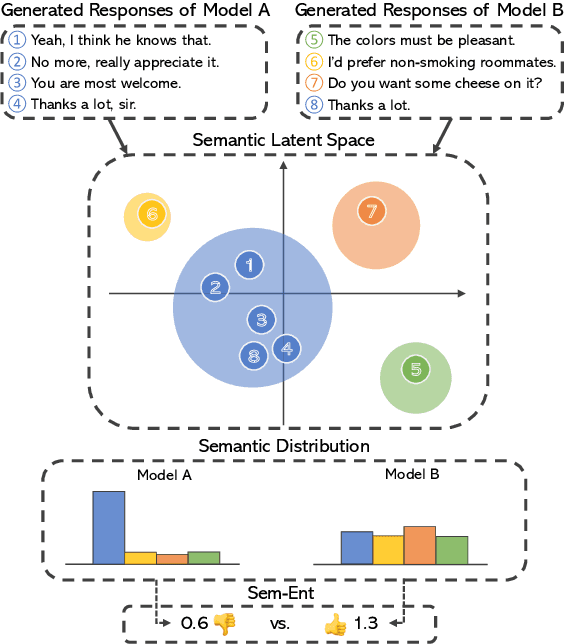


Response diversity has become an important criterion for evaluating the quality of open-domain dialogue generation models. However, current evaluation metrics for response diversity often fail to capture the semantic diversity of generated responses, as they mainly consider lexical aspects of the generated responses. In this paper, we introduce a new automatic evaluation metric to measure the semantic diversity of generated responses. Through human evaluation, we demonstrate that our proposed metric captures human judgments on response diversity better than existing lexical-level diversity metrics. Furthermore, motivated by analyzing an existing dialogue dataset, we propose a simple yet effective learning method that improves the semantic diversity of generated responses. Our learning method weights training samples based on the semantic distribution of the training set. We show that our learning method improves response diversity and coherency better than other baseline methods through automatic and human evaluation.
Denoising MCMC for Accelerating Diffusion-Based Generative Models
Sep 29, 2022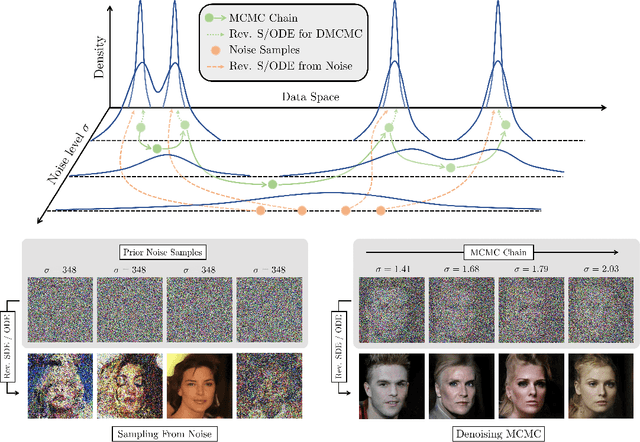
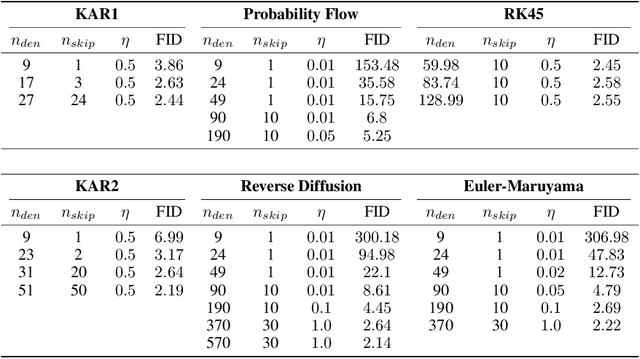
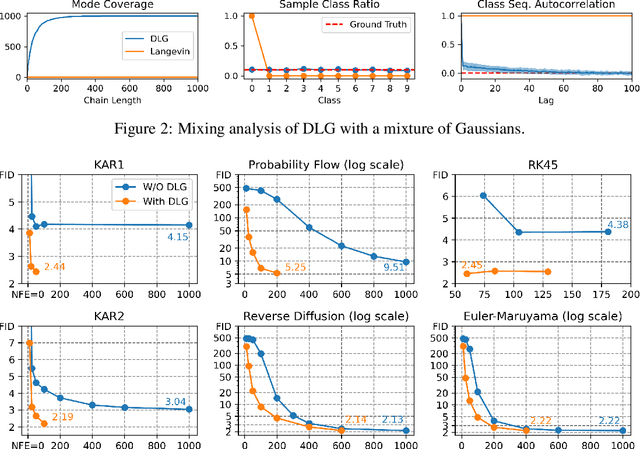
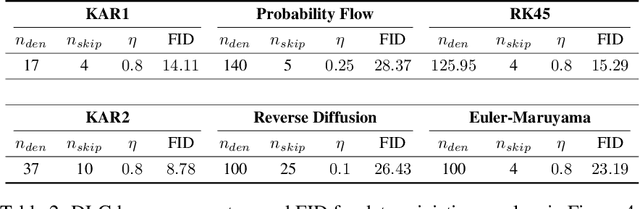
Diffusion models are powerful generative models that simulate the reverse of diffusion processes using score functions to synthesize data from noise. The sampling process of diffusion models can be interpreted as solving the reverse stochastic differential equation (SDE) or the ordinary differential equation (ODE) of the diffusion process, which often requires up to thousands of discretization steps to generate a single image. This has sparked a great interest in developing efficient integration techniques for reverse-S/ODEs. Here, we propose an orthogonal approach to accelerating score-based sampling: Denoising MCMC (DMCMC). DMCMC first uses MCMC to produce samples in the product space of data and variance (or diffusion time). Then, a reverse-S/ODE integrator is used to denoise the MCMC samples. Since MCMC traverses close to the data manifold, the computation cost of producing a clean sample for DMCMC is much less than that of producing a clean sample from noise. To verify the proposed concept, we show that Denoising Langevin Gibbs (DLG), an instance of DMCMC, successfully accelerates all six reverse-S/ODE integrators considered in this work on the tasks of CIFAR10 and CelebA-HQ-256 image generation. Notably, combined with integrators of Karras et al. (2022) and pre-trained score models of Song et al. (2021b), DLG achieves SOTA results. In the limited number of score function evaluation (NFE) settings on CIFAR10, we have $3.86$ FID with $\approx 10$ NFE and $2.63$ FID with $\approx 20$ NFE. On CelebA-HQ-256, we have $6.99$ FID with $\approx 160$ NFE, which beats the current best record of Kim et al. (2022) among score-based models, $7.16$ FID with $4000$ NFE. Code: https://github.com/1202kbs/DMCMC
Mitigating Out-of-Distribution Data Density Overestimation in Energy-Based Models
May 30, 2022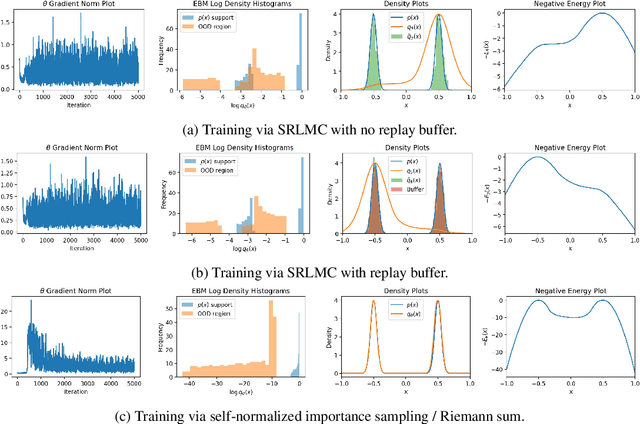

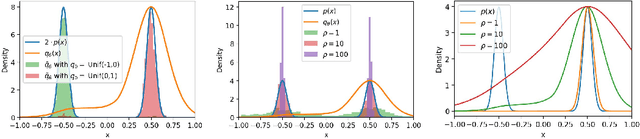
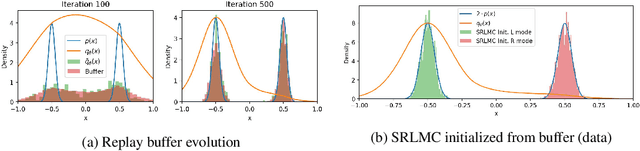
Deep energy-based models (EBMs), which use deep neural networks (DNNs) as energy functions, are receiving increasing attention due to their ability to learn complex distributions. To train deep EBMs, the maximum likelihood estimation (MLE) with short-run Langevin Monte Carlo (LMC) is often used. While the MLE with short-run LMC is computationally efficient compared to an MLE with full Markov Chain Monte Carlo (MCMC), it often assigns high density to out-of-distribution (OOD) data. To address this issue, here we systematically investigate why the MLE with short-run LMC can converge to EBMs with wrong density estimates, and reveal that the heuristic modifications to LMC introduced by previous works were the main problem. We then propose a Uniform Support Partitioning (USP) scheme that optimizes a set of points to evenly partition the support of the EBM and then uses the resulting points to approximate the EBM-MLE loss gradient. We empirically demonstrate that USP avoids the pitfalls of short-run LMC, leading to significantly improved OOD data detection performance on Fashion-MNIST.
Meet Your Favorite Character: Open-domain Chatbot Mimicking Fictional Characters with only a Few Utterances
Apr 22, 2022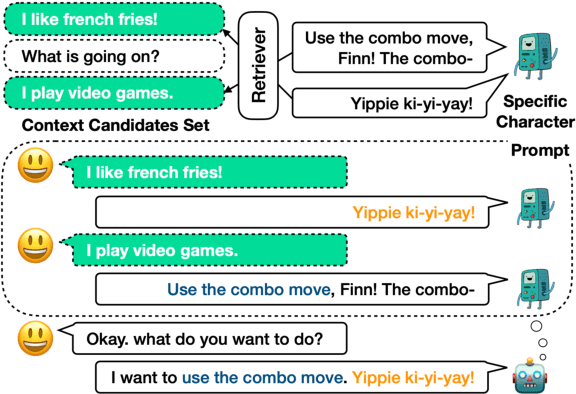
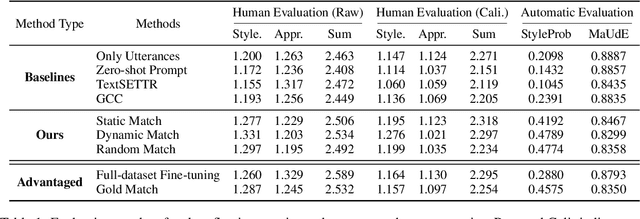

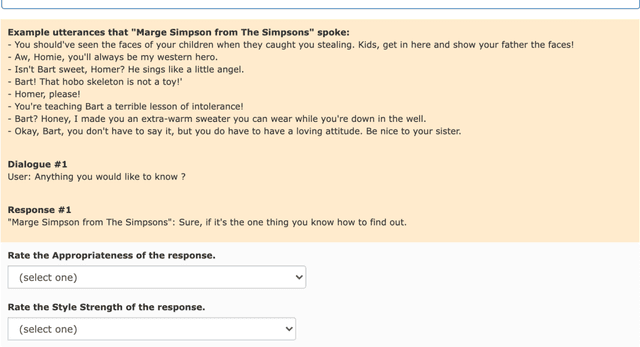
In this paper, we consider mimicking fictional characters as a promising direction for building engaging conversation models. To this end, we present a new practical task where only a few utterances of each fictional character are available to generate responses mimicking them. Furthermore, we propose a new method named Pseudo Dialog Prompting (PDP) that generates responses by leveraging the power of large-scale language models with prompts containing the target character's utterances. To better reflect the style of the character, PDP builds the prompts in the form of dialog that includes the character's utterances as dialog history. Since only utterances of the characters are available in the proposed task, PDP matches each utterance with an appropriate pseudo-context from a predefined set of context candidates using a retrieval model. Through human and automatic evaluation, we show that PDP generates responses that better reflect the style of fictional characters than baseline methods.
Semi-Implicit Hybrid Gradient Methods with Application to Adversarial Robustness
Feb 21, 2022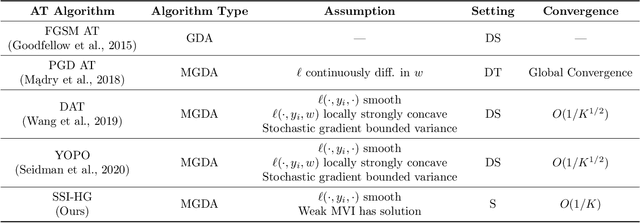
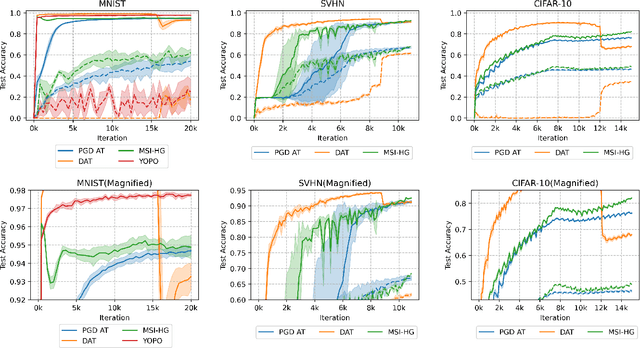

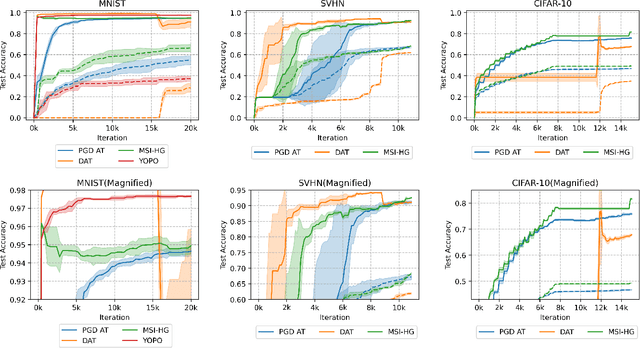
Adversarial examples, crafted by adding imperceptible perturbations to natural inputs, can easily fool deep neural networks (DNNs). One of the most successful methods for training adversarially robust DNNs is solving a nonconvex-nonconcave minimax problem with an adversarial training (AT) algorithm. However, among the many AT algorithms, only Dynamic AT (DAT) and You Only Propagate Once (YOPO) guarantee convergence to a stationary point. In this work, we generalize the stochastic primal-dual hybrid gradient algorithm to develop semi-implicit hybrid gradient methods (SI-HGs) for finding stationary points of nonconvex-nonconcave minimax problems. SI-HGs have the convergence rate $O(1/K)$, which improves upon the rate $O(1/K^{1/2})$ of DAT and YOPO. We devise a practical variant of SI-HGs, and show that it outperforms other AT algorithms in terms of convergence speed and robustness.
Energy-Based Contrastive Learning of Visual Representations
Feb 10, 2022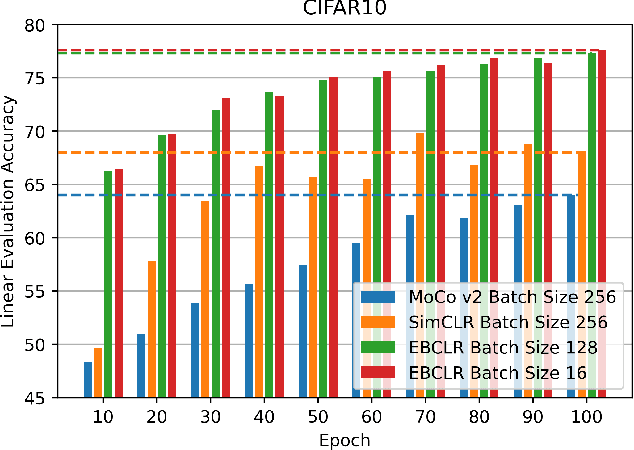
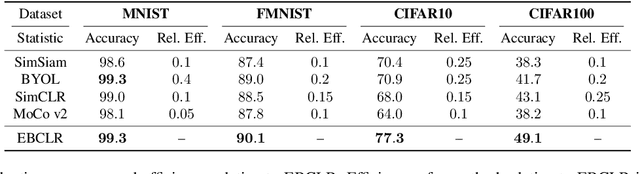
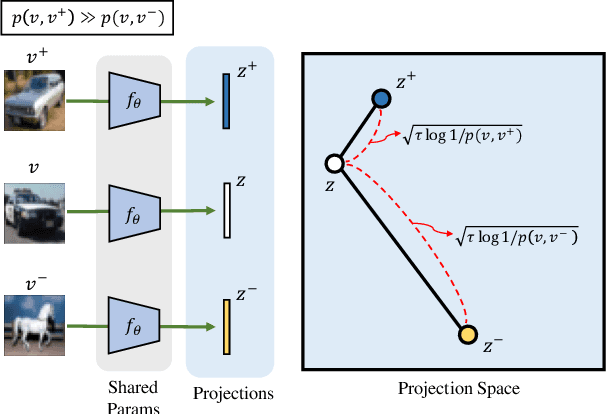
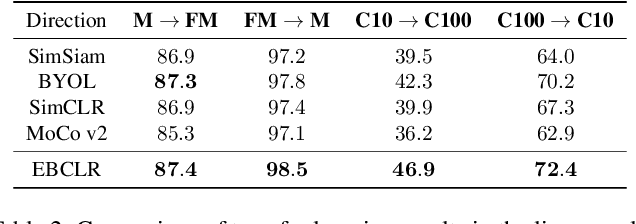
Contrastive learning is a method of learning visual representations by training Deep Neural Networks (DNNs) to increase the similarity between representations of positive pairs and reduce the similarity between representations of negative pairs. However, contrastive methods usually require large datasets with significant number of negative pairs per iteration to achieve reasonable performance on downstream tasks. To address this problem, here we propose Energy-Based Contrastive Learning (EBCLR) that combines contrastive learning with Energy-Based Models (EBMs) and can be theoretically interpreted as learning the joint distribution of positive pairs. Using a novel variant of Stochastic Gradient Langevin Dynamics (SGLD) to accelerate the training of EBCLR, we show that EBCLR is far more sample-efficient than previous self-supervised learning methods. Specifically, EBCLR shows from X4 up to X20 acceleration compared to SimCLR and MoCo v2 in terms of training epochs. Furthermore, in contrast to SimCLR, EBCLR achieves nearly the same performance with 254 negative pairs (batch size 128) and 30 negative pairs (batch size 16) per positive pair, demonstrating the robustness of EBCLR to small number of negative pairs.
Understanding and Improving the Exemplar-based Generation for Open-domain Conversation
Dec 13, 2021


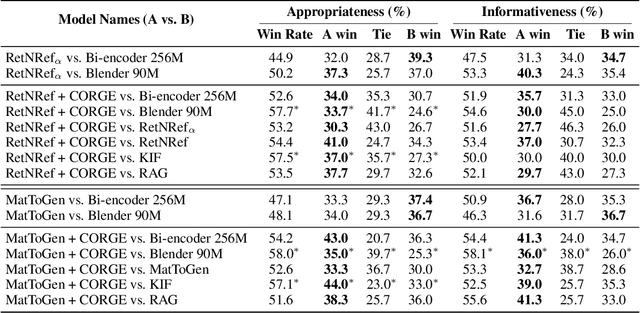
Exemplar-based generative models for open-domain conversation produce responses based on the exemplars provided by the retriever, taking advantage of generative models and retrieval models. However, they often ignore the retrieved exemplars while generating responses or produce responses over-fitted to the retrieved exemplars. In this paper, we argue that these drawbacks are derived from the one-to-many problem of the open-domain conversation. When the retrieved exemplar is relevant to the given context yet significantly different from the gold response, the exemplar-based generative models are trained to ignore the exemplar since the exemplar is not helpful for generating the gold response. On the other hand, when the retrieved exemplar is lexically similar to the gold response, the generative models are trained to rely on the exemplar highly. Therefore, we propose a training method selecting exemplars that are semantically relevant to the gold response but lexically distanced from the gold response to mitigate the above disadvantages. In the training phase, our proposed training method first uses the gold response instead of dialogue context as a query to select exemplars that are semantically relevant to the gold response. And then, it eliminates the exemplars that lexically resemble the gold responses to alleviate the dependency of the generative models on that exemplars. The remaining exemplars could be irrelevant to the given context since they are searched depending on the gold response. Thus, our proposed training method further utilizes the relevance scores between the given context and the exemplars to penalize the irrelevant exemplars. Extensive experiments demonstrate that our proposed training method alleviates the drawbacks of the existing exemplar-based generative models and significantly improves the performance in terms of appropriateness and informativeness.
Distilling the Knowledge of Large-scale Generative Models into Retrieval Models for Efficient Open-domain Conversation
Aug 31, 2021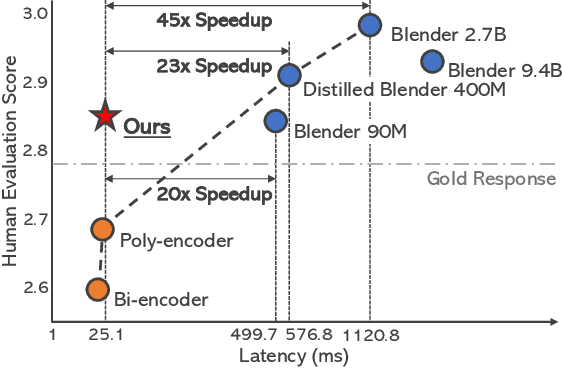

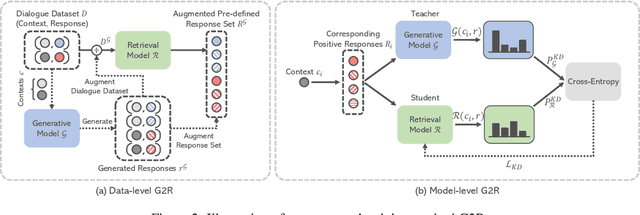

Despite the remarkable performance of large-scale generative models in open-domain conversation, they are known to be less practical for building real-time conversation systems due to high latency. On the other hand, retrieval models could return responses with much lower latency but show inferior performance to the large-scale generative models since the conversation quality is bounded by the pre-defined response set. To take advantage of both approaches, we propose a new training method called G2R (Generative-to-Retrieval distillation) that preserves the efficiency of a retrieval model while leveraging the conversational ability of a large-scale generative model by infusing the knowledge of the generative model into the retrieval model. G2R consists of two distinct techniques of distillation: the data-level G2R augments the dialogue dataset with additional responses generated by the large-scale generative model, and the model-level G2R transfers the response quality score assessed by the generative model to the score of the retrieval model by the knowledge distillation loss. Through extensive experiments including human evaluation, we demonstrate that our retrieval-based conversation system trained with G2R shows a substantially improved performance compared to the baseline retrieval model while showing significantly lower inference latency than the large-scale generative models.
Disentangling Label Distribution for Long-tailed Visual Recognition
Dec 01, 2020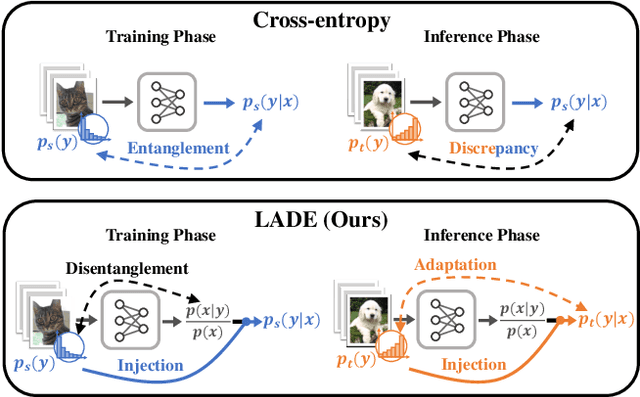
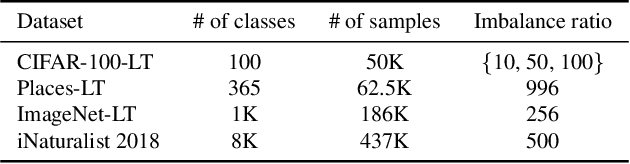
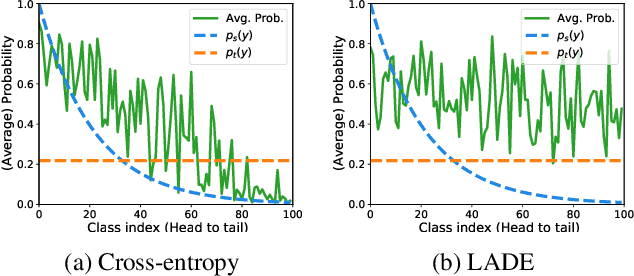
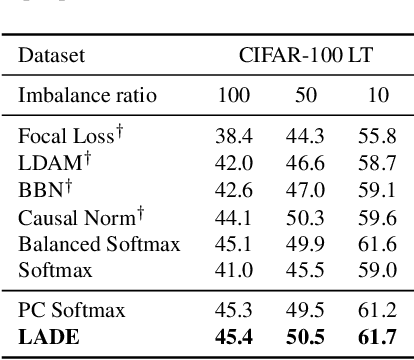
The current evaluation protocol of long-tailed visual recognition trains the classification model on the long-tailed source label distribution and evaluates its performance on the uniform target label distribution. Such protocol has questionable practicality since the target may also be long-tailed. Therefore, we formulate long-tailed visual recognition as a label shift problem where the target and source label distributions are different. One of the significant hurdles in dealing with the label shift problem is the entanglement between the source label distribution and the model prediction. In this paper, we focus on disentangling the source label distribution from the model prediction. We first introduce a simple baseline method that matches the target label distribution by post-processing the model prediction trained by the cross-entropy loss and the Softmax function. Although this method surpasses state-of-the-art methods on benchmark datasets, it can be further improved by directly disentangling the source label distribution from the model prediction in the training phase. Thus, we propose a novel method, LAbel distribution DisEntangling (LADE) loss based on the optimal bound of Donsker-Varadhan representation. LADE achieves state-of-the-art performance on benchmark datasets such as CIFAR-100-LT, Places-LT, ImageNet-LT, and iNaturalist 2018. Moreover, LADE outperforms existing methods on various shifted target label distributions, showing the general adaptability of our proposed method.