 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Nonasymptotic Theory of Gain-Dependent Error Dynamics in Behavior Cloning
Apr 15, 2026Behavior cloning (BC) policies on position-controlled robots inherit the closed-loop response of the underlying PD controller, yet the effect of controller gains on BC failure lacks a nonasymptotic theory. We show that independent sub-Gaussian action errors propagate through the gain-dependent closed-loop dynamics to yield sub-Gaussian position errors whose proxy matrix $X_\infty(K)$ governs the failure tail. The probability of horizon-$T$ task failure factorizes into a gain-dependent amplification index $Γ_T(K)$ and the validation loss plus a generalization slack, so training loss alone cannot predict closed-loop performance. Under shape-preserving upper-bound structural assumptions the proxy admits the scalar bound $X_\infty(K)\preceqΨ(K)\bar X$ with $Ψ(K)$ decomposed into label difficulty, injection strength, and contraction, ranking the four canonical regimes with compliant-overdamped (CO) tightest, stiff-underdamped (SU) loosest, and the stiff-overdamped versus compliant-underdamped ordering system-dependent. For the canonical scalar second-order PD system the closed-form continuous-time stationary variance $X_\infty^{\mathrm{c}}(α,β)=σ^2α/(2β)$ is strictly monotone in stiffness and damping over the entire stable orthant, covering both underdamped and overdamped regimes, and the exact zero-order-hold (ZOH) discretization inherits this monotonicity. The analysis provides the first nonasymptotic explanation of the empirical finding that compliant, overdamped controllers improve BC success rates.
Distributional Stability of Tangent-Linearized Gaussian Inference on Smooth Manifolds
Feb 22, 2026Gaussian inference on smooth manifolds is central to robotics, but exact marginalization and conditioning are generally non-Gaussian and geometry-dependent. We study tangent-linearized Gaussian inference and derive explicit non-asymptotic $W_2$ stability bounds for projection marginalization and surface-measure conditioning. The bounds separate local second-order geometric distortion from nonlocal tail leakage and, for Gaussian inputs, yield closed-form diagnostics from $(μ,Σ)$ and curvature/reach surrogates. Circle and planar-pushing experiments validate the predicted calibration transition near $\sqrt{\|Σ\|_{\mathrm{op}}}/R\approx 1/6$ and indicate that normal-direction uncertainty is the dominant failure mode when locality breaks. These diagnostics provide practical triggers for switching from single-chart linearization to multi-chart or sample-based manifold inference.
You Only Pose Once: A Minimalist's Detection Transformer for Monocular RGB Category-level 9D Multi-Object Pose Estimation
Aug 20, 2025



Accurately recovering the full 9-DoF pose of unseen instances within specific categories from a single RGB image remains a core challenge for robotics and automation. Most existing solutions still rely on pseudo-depth, CAD models, or multi-stage cascades that separate 2D detection from pose estimation. Motivated by the need for a simpler, RGB-only alternative that learns directly at the category level, we revisit a longstanding question: Can object detection and 9-DoF pose estimation be unified with high performance, without any additional data? We show that they can with our method, YOPO, a single-stage, query-based framework that treats category-level 9-DoF estimation as a natural extension of 2D detection. YOPO augments a transformer detector with a lightweight pose head, a bounding-box-conditioned translation module, and a 6D-aware Hungarian matching cost. The model is trained end-to-end only with RGB images and category-level pose labels. Despite its minimalist design, YOPO sets a new state of the art on three benchmarks. On the REAL275 dataset, it achieves 79.6% $\rm{IoU}_{50}$ and 54.1% under the $10^\circ$$10{\rm{cm}}$ metric, surpassing prior RGB-only methods and closing much of the gap to RGB-D systems. The code, models, and additional qualitative results can be found on our project.
Posture-Informed Muscular Force Learning for Robust Hand Pressure Estimation
Oct 31, 2024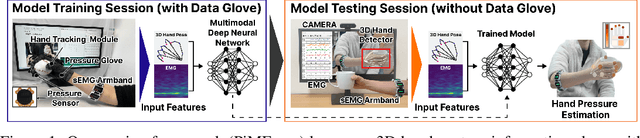
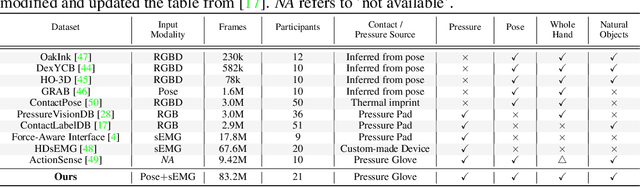
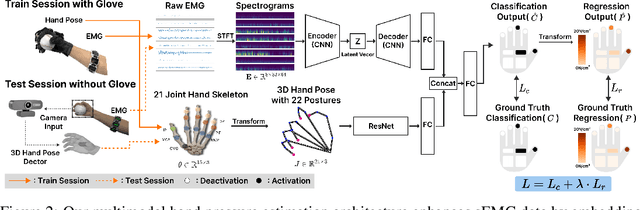

We present PiMForce, a novel framework that enhances hand pressure estimation by leveraging 3D hand posture information to augment forearm surface electromyography (sEMG) signals. Our approach utilizes detailed spatial information from 3D hand poses in conjunction with dynamic muscle activity from sEMG to enable accurate and robust whole-hand pressure measurements under diverse hand-object interactions. We also developed a multimodal data collection system that combines a pressure glove, an sEMG armband, and a markerless finger-tracking module. We created a comprehensive dataset from 21 participants, capturing synchronized data of hand posture, sEMG signals, and exerted hand pressure across various hand postures and hand-object interaction scenarios using our collection system. Our framework enables precise hand pressure estimation in complex and natural interaction scenarios. Our approach substantially mitigates the limitations of traditional sEMG-based or vision-based methods by integrating 3D hand posture information with sEMG signals. Video demos, data, and code are available online.
Masked Autoregressive Model for Weather Forecasting
Sep 30, 2024The growing impact of global climate change amplifies the need for accurate and reliable weather forecasting. Traditional autoregressive approaches, while effective for temporal modeling, suffer from error accumulation in long-term prediction tasks. The lead time embedding method has been suggested to address this issue, but it struggles to maintain crucial correlations in atmospheric events. To overcome these challenges, we propose the Masked Autoregressive Model for Weather Forecasting (MAM4WF). This model leverages masked modeling, where portions of the input data are masked during training, allowing the model to learn robust spatiotemporal relationships by reconstructing the missing information. MAM4WF combines the advantages of both autoregressive and lead time embedding methods, offering flexibility in lead time modeling while iteratively integrating predictions. We evaluate MAM4WF across weather, climate forecasting, and video frame prediction datasets, demonstrating superior performance on five test datasets.
Pushing the Limits of Vision-Language Models in Remote Sensing without Human Annotations
Sep 11, 2024The prominence of generalized foundation models in vision-language integration has witnessed a surge, given their multifarious applications. Within the natural domain, the procurement of vision-language datasets to construct these foundation models is facilitated by their abundant availability and the ease of web crawling. Conversely, in the remote sensing domain, although vision-language datasets exist, their volume is suboptimal for constructing robust foundation models. This study introduces an approach to curate vision-language datasets by employing an image decoding machine learning model, negating the need for human-annotated labels. Utilizing this methodology, we amassed approximately 9.6 million vision-language paired datasets in VHR imagery. The resultant model outperformed counterparts that did not leverage publicly available vision-language datasets, particularly in downstream tasks such as zero-shot classification, semantic localization, and image-text retrieval. Moreover, in tasks exclusively employing vision encoders, such as linear probing and k-NN classification, our model demonstrated superior efficacy compared to those relying on domain-specific vision-language datasets.
Geometric Remove-and-Retrain (GOAR): Coordinate-Invariant eXplainable AI Assessment
Jul 17, 2024Identifying the relevant input features that have a critical influence on the output results is indispensable for the development of explainable artificial intelligence (XAI). Remove-and-Retrain (ROAR) is a widely accepted approach for assessing the importance of individual pixels by measuring changes in accuracy following their removal and subsequent retraining of the modified dataset. However, we uncover notable limitations in pixel-perturbation strategies. When viewed from a geometric perspective, we discover that these metrics fail to discriminate between differences among feature attribution methods, thereby compromising the reliability of the evaluation. To address this challenge, we introduce an alternative feature-perturbation approach named Geometric Remove-and-Retrain (GOAR). Through a series of experiments with both synthetic and real datasets, we substantiate that GOAR transcends the limitations of pixel-centric metrics.
Prototype-oriented Unsupervised Change Detection for Disaster Management
Oct 17, 2023


Climate change has led to an increased frequency of natural disasters such as floods and cyclones. This emphasizes the importance of effective disaster monitoring. In response, the remote sensing community has explored change detection methods. These methods are primarily categorized into supervised techniques, which yield precise results but come with high labeling costs, and unsupervised techniques, which eliminate the need for labeling but involve intricate hyperparameter tuning. To address these challenges, we propose a novel unsupervised change detection method named Prototype-oriented Unsupervised Change Detection for Disaster Management (PUCD). PUCD captures changes by comparing features from pre-event, post-event, and prototype-oriented change synthesis images via a foundational model, and refines results using the Segment Anything Model (SAM). Although PUCD is an unsupervised change detection, it does not require complex hyperparameter tuning. We evaluate PUCD framework on the LEVIR-Extension dataset and the disaster dataset and it achieves state-of-the-art performance compared to other methods on the LEVIR-Extension dataset.
RHINO: Rotated DETR with Dynamic Denoising via Hungarian Matching for Oriented Object Detection
May 15, 2023



With the publication of DINO, a variant of the Detection Transformer (DETR), Detection Transformers are breaking the record in the object detection benchmark with the merits of their end-to-end design and scalability. However, the extension of DETR to oriented object detection has not been thoroughly studied although more benefits from its end-to-end architecture are expected such as removing NMS and anchor-related costs. In this paper, we propose a first strong DINO-based baseline for oriented object detection. We found that straightforward employment of DETRs for oriented object detection does not guarantee non-duplicate prediction, and propose a simple cost to mitigate this. Furthermore, we introduce a $\textit{dynamic denoising}$ strategy that uses Hungarian matching to filter redundant noised queries and $\textit{query alignment}$ to preserve matching consistency between Transformer decoder layers. Our proposed model outperforms previous rotated DETRs and other counterparts, achieving state-of-the-art performance in DOTA-v1.0/v1.5/v2.0, and DIOR-R benchmarks.
On Pitfalls of $\textit{RemOve-And-Retrain}$: Data Processing Inequality Perspective
May 11, 2023Approaches for appraising feature importance approximations, alternatively referred to as attribution methods, have been established across an extensive array of contexts. The development of resilient techniques for performance benchmarking constitutes a critical concern in the sphere of explainable deep learning. This study scrutinizes the dependability of the RemOve-And-Retrain (ROAR) procedure, which is prevalently employed for gauging the performance of feature importance estimates. The insights gleaned from our theoretical foundation and empirical investigations reveal that attributions containing lesser information about the decision function may yield superior results in ROAR benchmarks, contradicting the original intent of ROAR. This occurrence is similarly observed in the recently introduced variant RemOve-And-Debias (ROAD), and we posit a persistent pattern of blurriness bias in ROAR attribution metrics. Our findings serve as a warning against indiscriminate use on ROAR metrics. The code is available as open source.