 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangevin DQN
Feb 17, 2020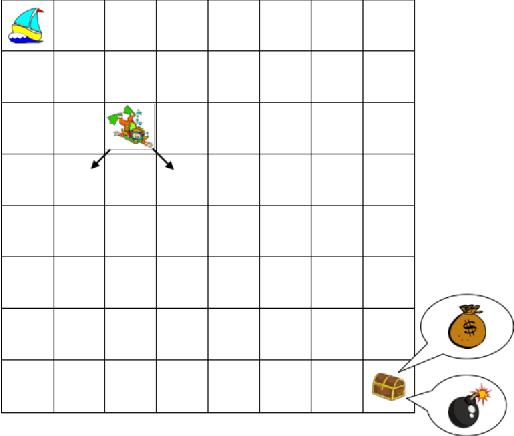
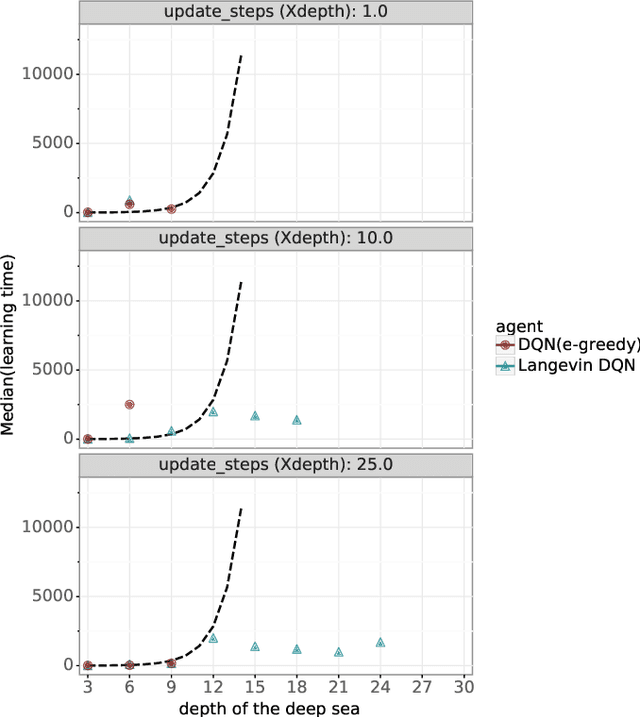
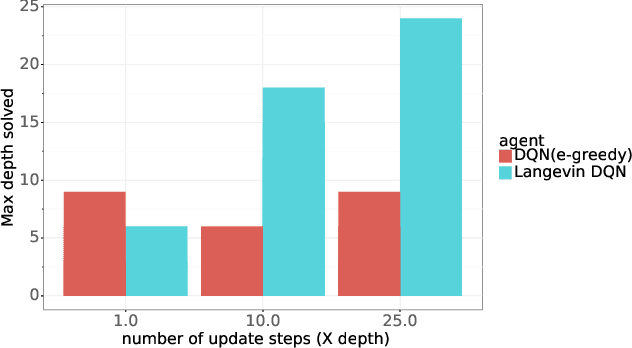
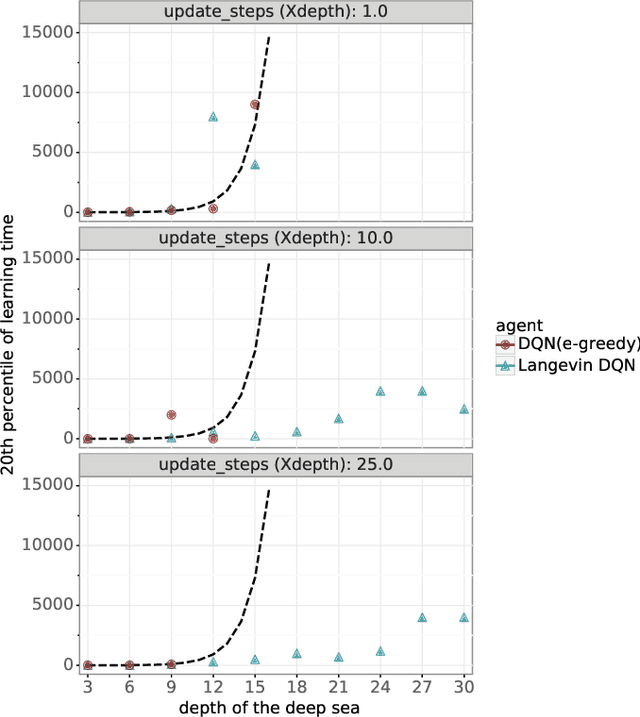
Algorithms that tackle deep exploration -- an important challenge in reinforcement learning -- have relied on epistemic uncertainty representation through ensembles or other hypermodels, exploration bonuses, or visitation count distributions. An open question is whether deep exploration can be achieved by an incremental reinforcement learning algorithm that tracks a single point estimate, without additional complexity required to account for epistemic uncertainty. We answer this question in the affirmative. In particular, we develop Langevin DQN, a variation of DQN that differs only in perturbing parameter updates with Gaussian noise, and demonstrate through a computational study that the algorithm achieves deep exploration. We also provide an intuition for why Langevin DQN performs deep exploration.
Provably Efficient Reinforcement Learning with Aggregated States
Dec 13, 2019We establish that an optimistic variant of Q-learning applied to a finite-horizon episodic Markov decision process with an aggregated state representation incurs regret $\tilde{\mathcal{O}}(\sqrt{H^5 M K} + \epsilon HK)$, where $H$ is the horizon, $M$ is the number of aggregate states, $K$ is the number of episodes, and $\epsilon$ is the largest difference between any pair of optimal state-action values associated with a common aggregate state. Notably, this regret bound does not depend on the number of states or actions. To the best of our knowledge, this is the first such result pertaining to a reinforcement learning algorithm applied with nontrivial value function approximation without any restrictions on the Markov decision process.
Information-Theoretic Confidence Bounds for Reinforcement Learning
Nov 21, 2019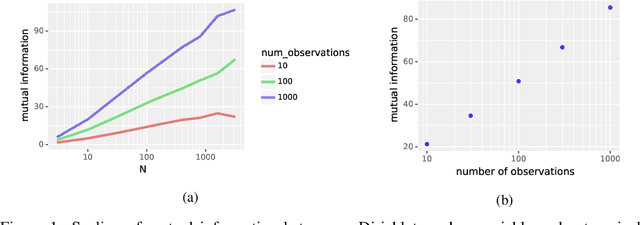
We integrate information-theoretic concepts into the design and analysis of optimistic algorithms and Thompson sampling. By making a connection between information-theoretic quantities and confidence bounds, we obtain results that relate the per-period performance of the agent with its information gain about the environment, thus explicitly characterizing the exploration-exploitation tradeoff. The resulting cumulative regret bound depends on the agent's uncertainty over the environment and quantifies the value of prior information. We show applicability of this approach to several environments, including linear bandits, tabular MDPs, and factored MDPs. These examples demonstrate the potential of a general information-theoretic approach for the design and analysis of reinforcement learning algorithms.
Comments on the Du-Kakade-Wang-Yang Lower Bounds
Nov 18, 2019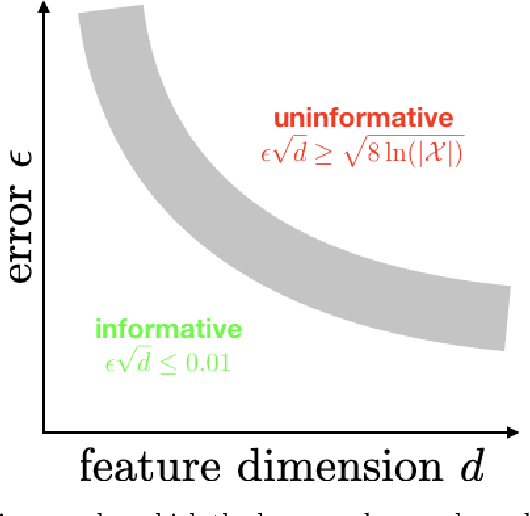
Du, Kakade, Wang, and Yang recently established intriguing lower bounds on sample complexity, which suggest that reinforcement learning with a misspecified representation is intractable. Another line of work, which centers around a statistic called the eluder dimension, establishes tractability of problems similar to those considered in the Du-Kakade-Wang-Yang paper. We compare these results and reconcile interpretations.
Behaviour Suite for Reinforcement Learning
Aug 13, 2019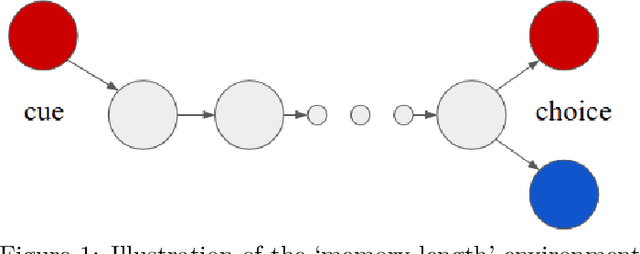
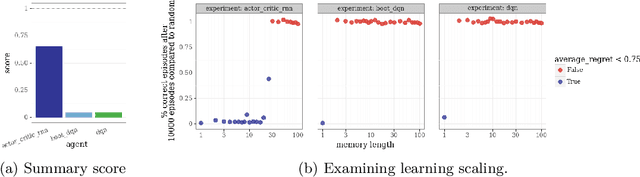
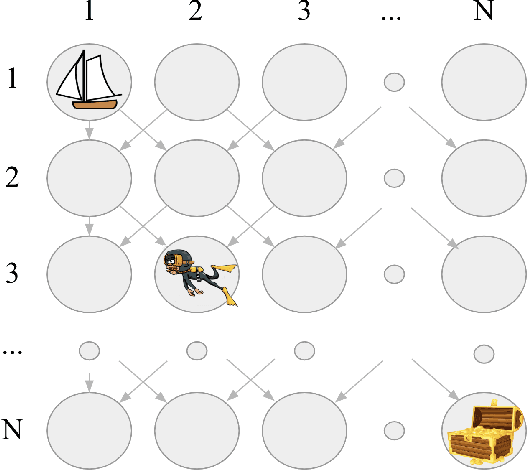
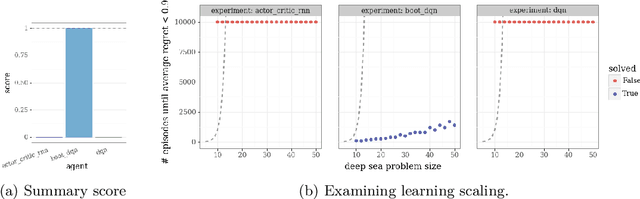
This paper introduces the Behaviour Suite for Reinforcement Learning, or bsuite for short. bsuite is a collection of carefully-designed experiments that investigate core capabilities of reinforcement learning (RL) agents with two objectives. First, to collect clear, informative and scalable problems that capture key issues in the design of general and efficient learning algorithms. Second, to study agent behaviour through their performance on these shared benchmarks. To complement this effort, we open source github.com/deepmind/bsuite, which automates evaluation and analysis of any agent on bsuite. This library facilitates reproducible and accessible research on the core issues in RL, and ultimately the design of superior learning algorithms. Our code is Python, and easy to use within existing projects. We include examples with OpenAI Baselines, Dopamine as well as new reference implementations. Going forward, we hope to incorporate more excellent experiments from the research community, and commit to a periodic review of bsuite from a committee of prominent researchers.
On the Performance of Thompson Sampling on Logistic Bandits
May 12, 2019
We study the logistic bandit, in which rewards are binary with success probability $\exp(\beta a^\top \theta) / (1 + \exp(\beta a^\top \theta))$ and actions $a$ and coefficients $\theta$ are within the $d$-dimensional unit ball. While prior regret bounds for algorithms that address the logistic bandit exhibit exponential dependence on the slope parameter $\beta$, we establish a regret bound for Thompson sampling that is independent of $\beta$. Specifically, we establish that, when the set of feasible actions is identical to the set of possible coefficient vectors, the Bayesian regret of Thompson sampling is $\tilde{O}(d\sqrt{T})$. We also establish a $\tilde{O}(\sqrt{d\eta T}/\lambda)$ bound that applies more broadly, where $\lambda$ is the worst-case optimal log-odds and $\eta$ is the "fragility dimension," a new statistic we define to capture the degree to which an optimal action for one model fails to satisfice for others. We demonstrate that the fragility dimension plays an essential role by showing that, for any $\epsilon > 0$, no algorithm can achieve $\mathrm{poly}(d, 1/\lambda)\cdot T^{1-\epsilon}$ regret.
An Information-Theoretic Analysis for Thompson Sampling with Many Actions
Oct 01, 2018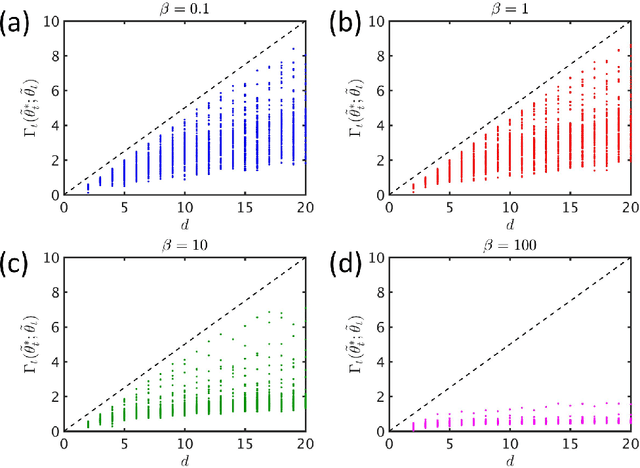
Information-theoretic Bayesian regret bounds of Russo and Van Roy capture the dependence of regret on prior uncertainty. However, this dependence is through entropy, which can become arbitrarily large as the number of actions increases. We establish new bounds that depend instead on a notion of rate-distortion. Among other things, this allows us to recover through information-theoretic arguments a near-optimal bound for the linear bandit. We also offer a bound for the logistic bandit that dramatically improves on the best previously available, though this bound depends on an information-theoretic statistic that we have only been able to quantify via computation.
Deep Exploration via Randomized Value Functions
Jun 06, 2018
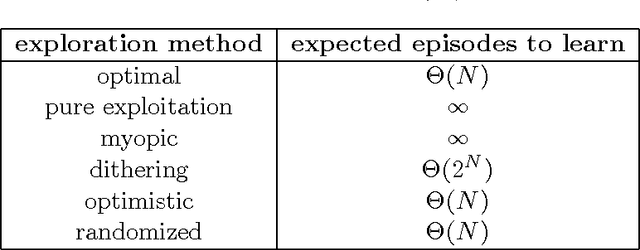
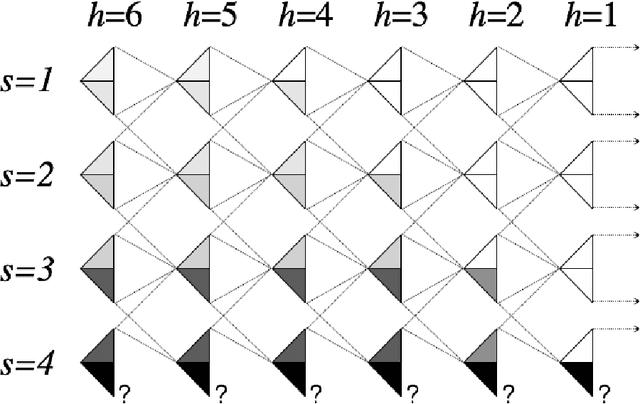
We study the use of randomized value functions to guide deep exploration in reinforcement learning. This offers an elegant means for synthesizing statistically and computationally efficient exploration with common practical approaches to value function learning. We present several reinforcement learning algorithms that leverage randomized value functions and demonstrate their efficacy through computational studies. We also prove a regret bound that establishes statistical efficiency with a tabular representation.
Scalable Coordinated Exploration in Concurrent Reinforcement Learning
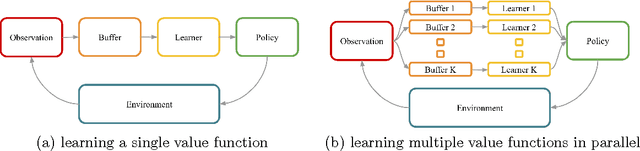
May 23, 2018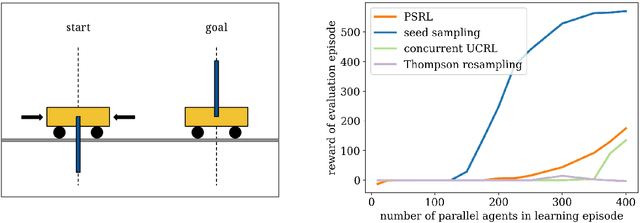
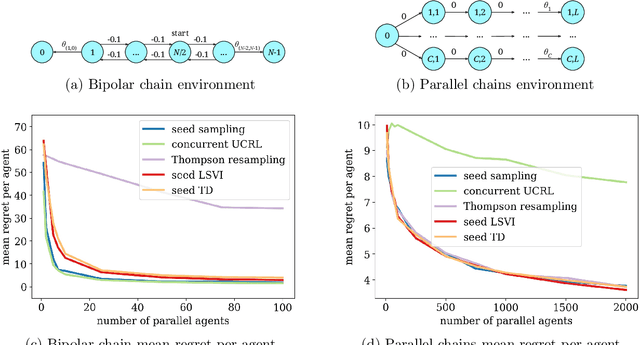
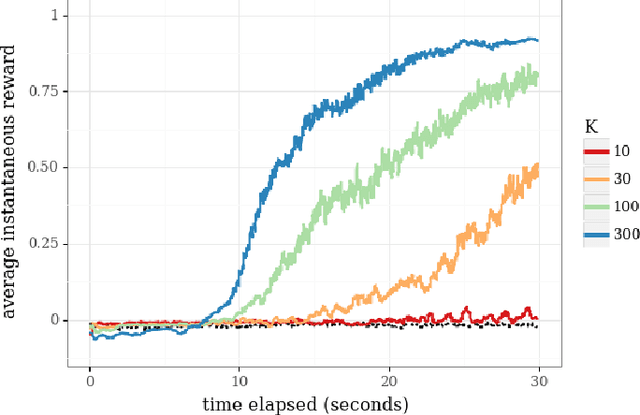
We consider a team of reinforcement learning agents that concurrently operate in a common environment, and we develop an approach to efficient coordinated exploration that is suitable for problems of practical scale. Our approach builds on seed sampling (Dimakopoulou and Van Roy, 2018) and randomized value function learning (Osband et al., 2016). We demonstrate that, for simple tabular contexts, the approach is competitive with previously proposed tabular model learning methods (Dimakopoulou and Van Roy, 2018). With a higher-dimensional problem and a neural network value function representation, the approach learns quickly with far fewer agents than alternative exploration schemes.
Satisficing in Time-Sensitive Bandit Learning
Mar 07, 2018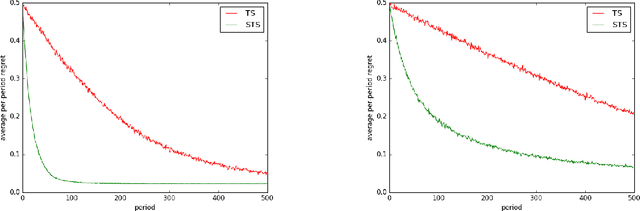
Much of the recent literature on bandit learning focuses on algorithms that aim to converge on an optimal action. One shortcoming is that this orientation does not account for time sensitivity, which can play a crucial role when learning an optimal action requires much more information than near-optimal ones. Indeed, popular approaches such as upper-confidence-bound methods and Thompson sampling can fare poorly in such situations. We consider instead learning a satisficing action, which is near-optimal while requiring less information, and propose satisficing Thompson sampling, an algorithm that serves this purpose. We establish a general bound on expected discounted regret and study the application of satisficing Thompson sampling to linear and infinite-armed bandits, demonstrating arbitrarily large benefits over Thompson sampling. We also discuss the relation between the notion of satisficing and the theory of rate distortion, which offers guidance on the selection of satisficing actions.