 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Do Not Simulate Human Psychology
Aug 13, 2025Large Language Models (LLMs),such as ChatGPT, are increasingly used in research, ranging from simple writing assistance to complex data annotation tasks. Recently, some research has suggested that LLMs may even be able to simulate human psychology and can, hence, replace human participants in psychological studies. We caution against this approach. We provide conceptual arguments against the hypothesis that LLMs simulate human psychology. We then present empiric evidence illustrating our arguments by demonstrating that slight changes to wording that correspond to large changes in meaning lead to notable discrepancies between LLMs' and human responses, even for the recent CENTAUR model that was specifically fine-tuned on psychological responses. Additionally, different LLMs show very different responses to novel items, further illustrating their lack of reliability. We conclude that LLMs do not simulate human psychology and recommend that psychological researchers should treat LLMs as useful but fundamentally unreliable tools that need to be validated against human responses for every new application.
Assessing LLM Text Detection in Educational Contexts: Does Human Contribution Affect Detection?
Aug 11, 2025Recent advancements in Large Language Models (LLMs) and their increased accessibility have made it easier than ever for students to automatically generate texts, posing new challenges for educational institutions. To enforce norms of academic integrity and ensure students' learning, learning analytics methods to automatically detect LLM-generated text appear increasingly appealing. This paper benchmarks the performance of different state-of-the-art detectors in educational contexts, introducing a novel dataset, called Generative Essay Detection in Education (GEDE), containing over 900 student-written essays and over 12,500 LLM-generated essays from various domains. To capture the diversity of LLM usage practices in generating text, we propose the concept of contribution levels, representing students' contribution to a given assignment. These levels range from purely human-written texts, to slightly LLM-improved versions, to fully LLM-generated texts, and finally to active attacks on the detector by "humanizing" generated texts. We show that most detectors struggle to accurately classify texts of intermediate student contribution levels, like LLM-improved human-written texts. Detectors are particularly likely to produce false positives, which is problematic in educational settings where false suspicions can severely impact students' lives. Our dataset, code, and additional supplementary materials are publicly available at https://github.com/lukasgehring/Assessing-LLM-Text-Detection-in-Educational-Contexts.
LLLMs: A Data-Driven Survey of Evolving Research on Limitations of Large Language Models
May 25, 2025Large language model (LLM) research has grown rapidly, along with increasing concern about their limitations such as failures in reasoning, hallucinations, and limited multilingual capability. In this survey, we conduct a data-driven, semi-automated review of research on limitations of LLM (LLLMs) from 2022 to 2024 using a bottom-up approach. From a corpus of 250,000 ACL and arXiv papers, we identify 14,648 relevant papers using keyword filtering, LLM-based classification, validated against expert labels, and topic clustering (via two approaches, HDBSCAN+BERTopic and LlooM). We find that LLM-related research increases over fivefold in ACL and fourfold in arXiv. Since 2022, LLLMs research grows even faster, reaching over 30% of LLM papers by late 2024. Reasoning remains the most studied limitation, followed by generalization, hallucination, bias, and security. The distribution of topics in the ACL dataset stays relatively stable over time, while arXiv shifts toward safety and controllability (with topics like security risks, alignment, hallucinations, knowledge editing), and multimodality between 2022 and 2024. We release a dataset of annotated abstracts and a validated methodology, and offer a quantitative view of trends in LLM limitations research.
Healthy Distrust in AI systems
May 14, 2025Under the slogan of trustworthy AI, much of contemporary AI research is focused on designing AI systems and usage practices that inspire human trust and, thus, enhance adoption of AI systems. However, a person affected by an AI system may not be convinced by AI system design alone -- neither should they, if the AI system is embedded in a social context that gives good reason to believe that it is used in tension with a person's interest. In such cases, distrust in the system may be justified and necessary to build meaningful trust in the first place. We propose the term "healthy distrust" to describe such a justified, careful stance towards certain AI usage practices. We investigate prior notions of trust and distrust in computer science, sociology, history, psychology, and philosophy, outline a remaining gap that healthy distrust might fill and conceptualize healthy distrust as a crucial part for AI usage that respects human autonomy.
Fairness in KI-Systemen
Jul 17, 2023The more AI-assisted decisions affect people's lives, the more important the fairness of such decisions becomes. In this chapter, we provide an introduction to research on fairness in machine learning. We explain the main fairness definitions and strategies for achieving fairness using concrete examples and place fairness research in the European context. Our contribution is aimed at an interdisciplinary audience and therefore avoids mathematical formulation but emphasizes visualizations and examples. -- Je mehr KI-gest\"utzte Entscheidungen das Leben von Menschen betreffen, desto wichtiger ist die Fairness solcher Entscheidungen. In diesem Kapitel geben wir eine Einf\"uhrung in die Forschung zu Fairness im maschinellen Lernen. Wir erkl\"aren die wesentlichen Fairness-Definitionen und Strategien zur Erreichung von Fairness anhand konkreter Beispiele und ordnen die Fairness-Forschung in den europ\"aischen Kontext ein. Unser Beitrag richtet sich dabei an ein interdisziplin\"ares Publikum und verzichtet daher auf die mathematische Formulierung sondern betont Visualisierungen und Beispiele.
Automatic Creativity Measurement in Scratch Programs Across Modalities
Nov 07, 2022Promoting creativity is considered an important goal of education, but creativity is notoriously hard to measure.In this paper, we make the journey fromdefining a formal measure of creativity that is efficientlycomputable to applying the measure in a practical domain. The measure is general and relies on coretheoretical concepts in creativity theory, namely fluency, flexibility, and originality, integratingwith prior cognitive science literature. We adapted the general measure for projects in the popular visual programming language Scratch.We designed a machine learning model for predicting the creativity of Scratch projects, trained and evaluated on human expert creativity assessments in an extensive user study. Our results show that opinions about creativity in Scratch varied widely across experts. The automatic creativity assessment aligned with the assessment of the human experts more than the experts agreed with each other. This is a first step in providing computational models for measuring creativity that can be applied to educational technologies, and to scale up the benefit of creativity education in schools.
An A*-algorithm for the Unordered Tree Edit Distance with Custom Costs
Jul 26, 2021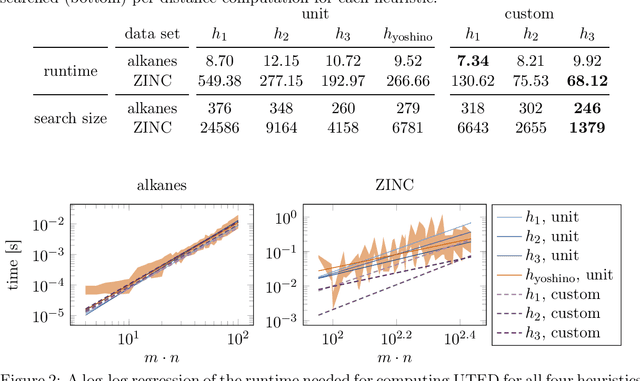
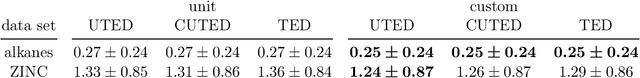
The unordered tree edit distance is a natural metric to compute distances between trees without intrinsic child order, such as representations of chemical molecules. While the unordered tree edit distance is MAX SNP-hard in principle, it is feasible for small cases, e.g. via an A* algorithm. Unfortunately, current heuristics for the A* algorithm assume unit costs for deletions, insertions, and replacements, which limits our ability to inject domain knowledge. In this paper, we present three novel heuristics for the A* algorithm that work with custom cost functions. In experiments on two chemical data sets, we show that custom costs make the A* computation faster and improve the error of a 5-nearest neighbor regressor, predicting chemical properties. We also show that, on these data, polynomial edit distances can achieve similar results as the unordered tree edit distance.
Reservoir Stack Machines
May 04, 2021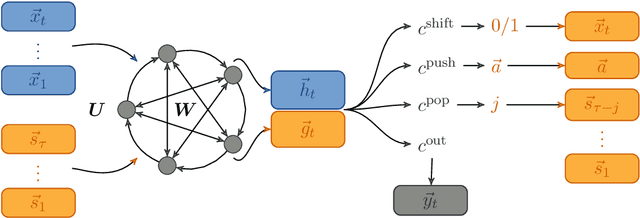

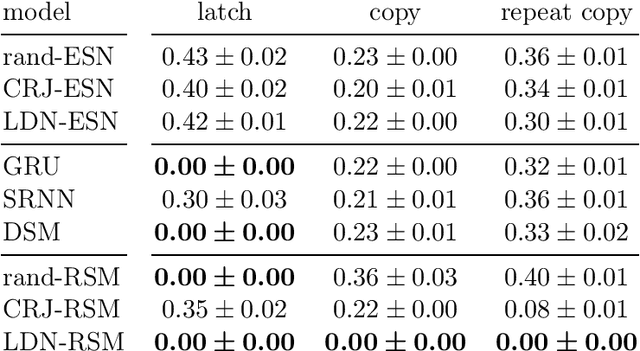
Memory-augmented neural networks equip a recurrent neural network with an explicit memory to support tasks that require information storage without interference over long times. A key motivation for such research is to perform classic computation tasks, such as parsing. However, memory-augmented neural networks are notoriously hard to train, requiring many backpropagation epochs and a lot of data. In this paper, we introduce the reservoir stack machine, a model which can provably recognize all deterministic context-free languages and circumvents the training problem by training only the output layer of a recurrent net and employing auxiliary information during training about the desired interaction with a stack. In our experiments, we validate the reservoir stack machine against deep and shallow networks from the literature on three benchmark tasks for Neural Turing machines and six deterministic context-free languages. Our results show that the reservoir stack machine achieves zero error, even on test sequences longer than the training data, requiring only a few seconds of training time and 100 training sequences.
ast2vec: Utilizing Recursive Neural Encodings of Python Programs
Mar 22, 2021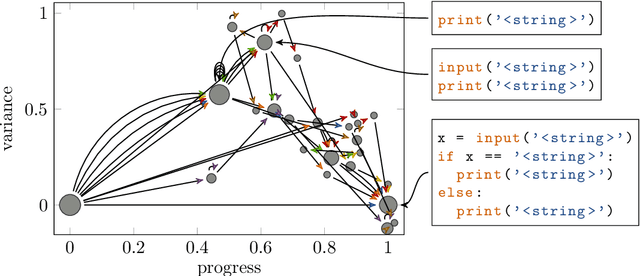
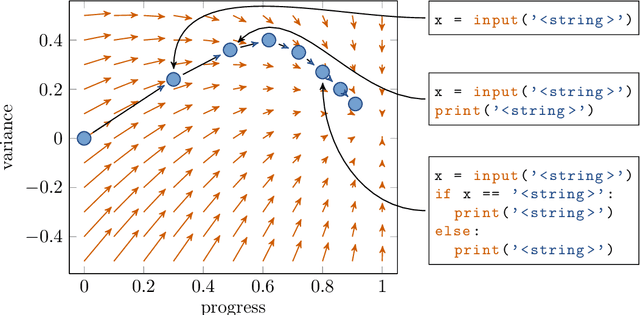
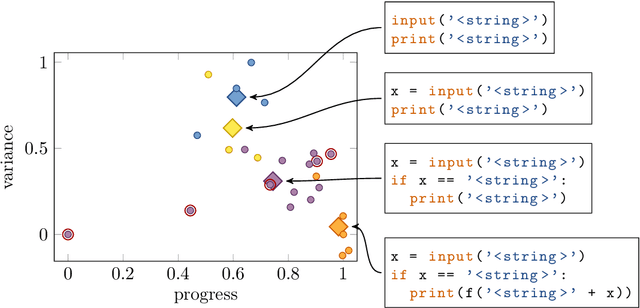
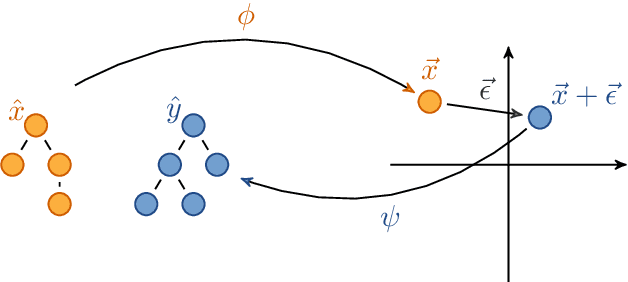
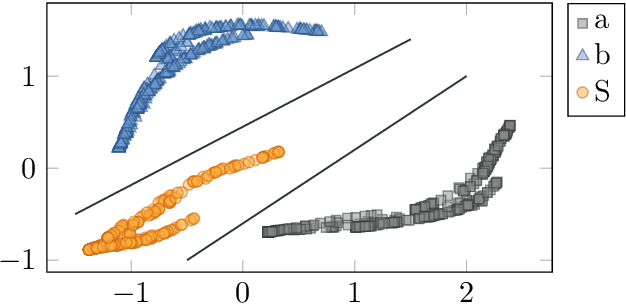
Educational datamining involves the application of datamining techniques to student activity. However, in the context of computer programming, many datamining techniques can not be applied because they expect vector-shaped input whereas computer programs have the form of syntax trees. In this paper, we present ast2vec, a neural network that maps Python syntax trees to vectors and back, thereby facilitating datamining on computer programs as well as the interpretation of datamining results. Ast2vec has been trained on almost half a million programs of novice programmers and is designed to be applied across learning tasks without re-training, meaning that users can apply it without any need for (additional) deep learning. We demonstrate the generality of ast2vec in three settings: First, we provide example analyses using ast2vec on a classroom-sized dataset, involving visualization, student motion analysis, clustering, and outlier detection, including two novel analyses, namely a progress-variance-projection and a dynamical systems analysis. Second, we consider the ability of ast2vec to recover the original syntax tree from its vector representation on the training data and two further large-scale programming datasets. Finally, we evaluate the predictive capability of a simple linear regression on top of ast2vec, obtaining similar results to techniques that work directly on syntax trees. We hope ast2vec can augment the educational datamining toolbelt by making analyses of computer programs easier, richer, and more efficient.
Reservoir Memory Machines as Neural Computers
Sep 14, 2020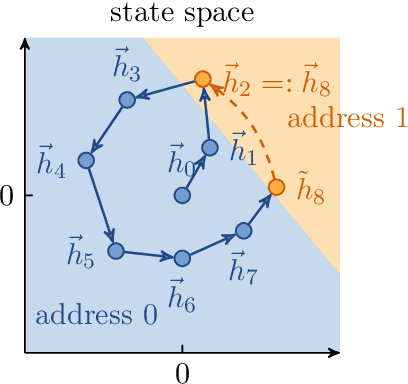

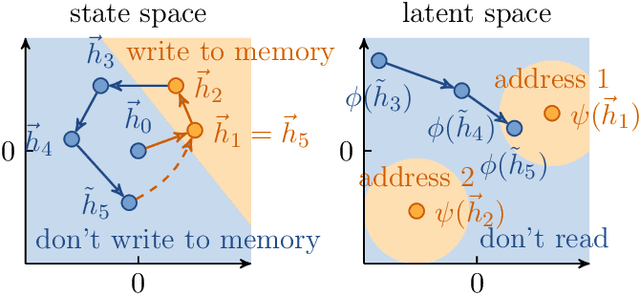

Differentiable neural computers extend artificial neural networks with an explicit memory without interference, thus enabling the model to perform classic computation tasks such as graph traversal. However, such models are difficult to train, requiring long training times and large datasets. In this work, we achieve some of the computational capabilities of differentiable neural computers with a model that can be trained extremely efficiently, namely an echo state network with an explicit memory without interference. This extension raises the computation power of echo state networks from strictly less than finite state machines to strictly more than finite state machines. Further, we demonstrate experimentally that our model performs comparably to its fully-trained deep version on several typical benchmark tasks for differentiable neural computers.