 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Analysis of 150+ years of German Parliamentary Debates on Migration Reveals Shift from Post-War Solidarity to Anti-Solidarity in the Last Decade
Sep 08, 2025Migration has been a core topic in German political debate, from millions of expellees post World War II over labor migration to refugee movements in the recent past. Studying political speech regarding such wide-ranging phenomena in depth traditionally required extensive manual annotations, limiting the scope of analysis to small subsets of the data. Large language models (LLMs) have the potential to partially automate even complex annotation tasks. We provide an extensive evaluation of a multiple LLMs in annotating (anti-)solidarity subtypes in German parliamentary debates compared to a large set of thousands of human reference annotations (gathered over a year). We evaluate the influence of model size, prompting differences, fine-tuning, historical versus contemporary data; and we investigate systematic errors. Beyond methodological evaluation, we also interpret the resulting annotations from a social science lense, gaining deeper insight into (anti-)solidarity trends towards migrants in the German post-World War II period and recent past. Our data reveals a high degree of migrant-directed solidarity in the postwar period, as well as a strong trend towards anti-solidarity in the German parliament since 2015, motivating further research. These findings highlight the promise of LLMs for political text analysis and the importance of migration debates in Germany, where demographic decline and labor shortages coexist with rising polarization.
LLLMs: A Data-Driven Survey of Evolving Research on Limitations of Large Language Models
May 25, 2025Large language model (LLM) research has grown rapidly, along with increasing concern about their limitations such as failures in reasoning, hallucinations, and limited multilingual capability. In this survey, we conduct a data-driven, semi-automated review of research on limitations of LLM (LLLMs) from 2022 to 2024 using a bottom-up approach. From a corpus of 250,000 ACL and arXiv papers, we identify 14,648 relevant papers using keyword filtering, LLM-based classification, validated against expert labels, and topic clustering (via two approaches, HDBSCAN+BERTopic and LlooM). We find that LLM-related research increases over fivefold in ACL and fourfold in arXiv. Since 2022, LLLMs research grows even faster, reaching over 30% of LLM papers by late 2024. Reasoning remains the most studied limitation, followed by generalization, hallucination, bias, and security. The distribution of topics in the ACL dataset stays relatively stable over time, while arXiv shifts toward safety and controllability (with topics like security risks, alignment, hallucinations, knowledge editing), and multimodality between 2022 and 2024. We release a dataset of annotated abstracts and a validated methodology, and offer a quantitative view of trends in LLM limitations research.
FairGer: Using NLP to Measure Support for Women and Migrants in 155 Years of German Parliamentary Debates
Oct 09, 2022


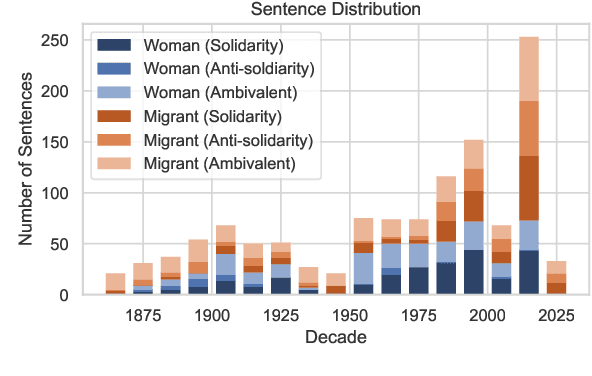
We measure support with women and migrants in German political debates over the last 155 years. To do so, we (1) provide a gold standard of 1205 text snippets in context, annotated for support with our target groups, (2) train a BERT model on our annotated data, with which (3) we infer large-scale trends. These show that support with women is stronger than support with migrants, but both have steadily increased over time. While we hardly find any direct anti-support with women, there is more polarization when it comes to migrants. We also discuss the difficulty of annotation as a result of ambiguity in political discourse and indirectness, i.e., politicians' tendency to relate stances attributed to political opponents. Overall, our results indicate that German society, as measured from its political elite, has become fairer over time.