 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing LLM Text Detection in Educational Contexts: Does Human Contribution Affect Detection?
Aug 11, 2025Recent advancements in Large Language Models (LLMs) and their increased accessibility have made it easier than ever for students to automatically generate texts, posing new challenges for educational institutions. To enforce norms of academic integrity and ensure students' learning, learning analytics methods to automatically detect LLM-generated text appear increasingly appealing. This paper benchmarks the performance of different state-of-the-art detectors in educational contexts, introducing a novel dataset, called Generative Essay Detection in Education (GEDE), containing over 900 student-written essays and over 12,500 LLM-generated essays from various domains. To capture the diversity of LLM usage practices in generating text, we propose the concept of contribution levels, representing students' contribution to a given assignment. These levels range from purely human-written texts, to slightly LLM-improved versions, to fully LLM-generated texts, and finally to active attacks on the detector by "humanizing" generated texts. We show that most detectors struggle to accurately classify texts of intermediate student contribution levels, like LLM-improved human-written texts. Detectors are particularly likely to produce false positives, which is problematic in educational settings where false suspicions can severely impact students' lives. Our dataset, code, and additional supplementary materials are publicly available at https://github.com/lukasgehring/Assessing-LLM-Text-Detection-in-Educational-Contexts.
PyExperimenter: Easily distribute experiments and track results
Jan 16, 2023
PyExperimenter is a tool to facilitate the setup, documentation, execution, and subsequent evaluation of results from an empirical study of algorithms and in particular is designed to reduce the involved manual effort significantly. It is intended to be used by researchers in the field of artificial intelligence, but is not limited to those.
Algorithm Selection on a Meta Level
Jul 20, 2021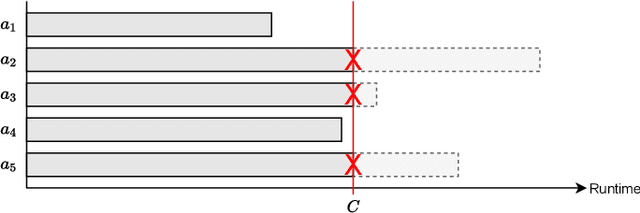
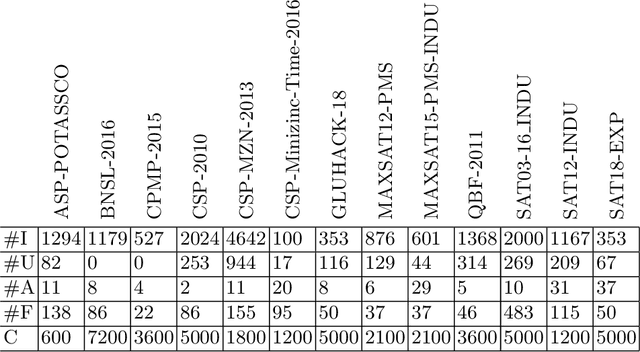
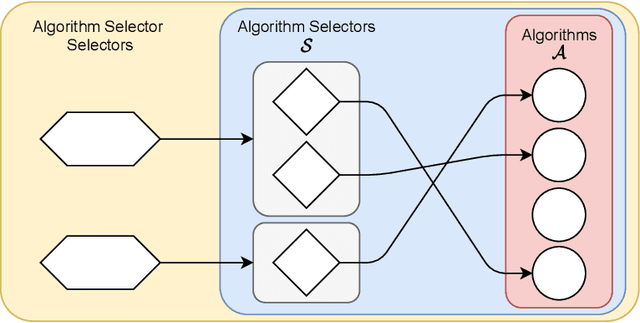
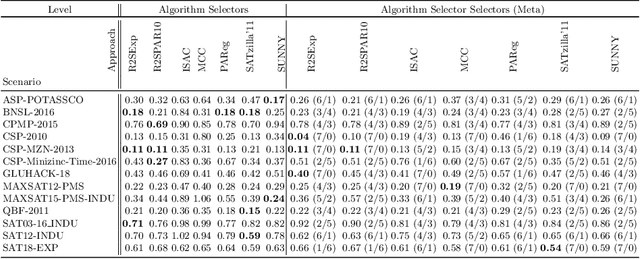
The problem of selecting an algorithm that appears most suitable for a specific instance of an algorithmic problem class, such as the Boolean satisfiability problem, is called instance-specific algorithm selection. Over the past decade, the problem has received considerable attention, resulting in a number of different methods for algorithm selection. Although most of these methods are based on machine learning, surprisingly little work has been done on meta learning, that is, on taking advantage of the complementarity of existing algorithm selection methods in order to combine them into a single superior algorithm selector. In this paper, we introduce the problem of meta algorithm selection, which essentially asks for the best way to combine a given set of algorithm selectors. We present a general methodological framework for meta algorithm selection as well as several concrete learning methods as instantiations of this framework, essentially combining ideas of meta learning and ensemble learning. In an extensive experimental evaluation, we demonstrate that ensembles of algorithm selectors can significantly outperform single algorithm selectors and have the potential to form the new state of the art in algorithm selection.