 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Media Bias Taxonomy: A Systematic Literature Review on the Forms and Automated Detection of Media Bias
Jan 10, 2024



The way the media presents events can significantly affect public perception, which in turn can alter people's beliefs and views. Media bias describes a one-sided or polarizing perspective on a topic. This article summarizes the research on computational methods to detect media bias by systematically reviewing 3140 research papers published between 2019 and 2022. To structure our review and support a mutual understanding of bias across research domains, we introduce the Media Bias Taxonomy, which provides a coherent overview of the current state of research on media bias from different perspectives. We show that media bias detection is a highly active research field, in which transformer-based classification approaches have led to significant improvements in recent years. These improvements include higher classification accuracy and the ability to detect more fine-granular types of bias. However, we have identified a lack of interdisciplinarity in existing projects, and a need for more awareness of the various types of media bias to support methodologically thorough performance evaluations of media bias detection systems. Concluding from our analysis, we see the integration of recent machine learning advancements with reliable and diverse bias assessment strategies from other research areas as the most promising area for future research contributions in the field.
Paraphrase Types for Generation and Detection
Oct 23, 2023Current approaches in paraphrase generation and detection heavily rely on a single general similarity score, ignoring the intricate linguistic properties of language. This paper introduces two new tasks to address this shortcoming by considering paraphrase types - specific linguistic perturbations at particular text positions. We name these tasks Paraphrase Type Generation and Paraphrase Type Detection. Our results suggest that while current techniques perform well in a binary classification scenario, i.e., paraphrased or not, the inclusion of fine-grained paraphrase types poses a significant challenge. While most approaches are good at generating and detecting general semantic similar content, they fail to understand the intrinsic linguistic variables they manipulate. Models trained in generating and identifying paraphrase types also show improvements in tasks without them. In addition, scaling these models further improves their ability to understand paraphrase types. We believe paraphrase types can unlock a new paradigm for developing paraphrase models and solving tasks in the future.
We are Who We Cite: Bridges of Influence Between Natural Language Processing and Other Academic Fields
Oct 23, 2023Natural Language Processing (NLP) is poised to substantially influence the world. However, significant progress comes hand-in-hand with substantial risks. Addressing them requires broad engagement with various fields of study. Yet, little empirical work examines the state of such engagement (past or current). In this paper, we quantify the degree of influence between 23 fields of study and NLP (on each other). We analyzed ~77k NLP papers, ~3.1m citations from NLP papers to other papers, and ~1.8m citations from other papers to NLP papers. We show that, unlike most fields, the cross-field engagement of NLP, measured by our proposed Citation Field Diversity Index (CFDI), has declined from 0.58 in 1980 to 0.31 in 2022 (an all-time low). In addition, we find that NLP has grown more insular -- citing increasingly more NLP papers and having fewer papers that act as bridges between fields. NLP citations are dominated by computer science; Less than 8% of NLP citations are to linguistics, and less than 3% are to math and psychology. These findings underscore NLP's urgent need to reflect on its engagement with various fields.
Generative User-Experience Research for Developing Domain-specific Natural Language Processing Applications
Jun 28, 2023



User experience (UX) is a part of human-computer interaction (HCI) research and focuses on increasing intuitiveness, transparency, simplicity, and trust for system users. Most of the UX research for machine learning (ML) or natural language processing (NLP) focuses on a data-driven methodology, i.e., it fails to focus on users' requirements, and engages domain users mainly for usability evaluation. Moreover, more typical UX methods tailor the systems towards user usability, unlike learning about the user needs first. The paper proposes a methodology for integrating generative UX research into developing domain NLP applications. Generative UX research employs domain users at the initial stages of prototype development, i.e., ideation and concept evaluation, and the last stage for evaluating the change in user value. In the case study, we report the full-cycle prototype development of a domain-specific semantic search for daily operations in the process industry. Our case study shows that involving domain experts increases their interest and trust in the final NLP application. Moreover, we show that synergetic UX+NLP research efficiently considers data- and user-driven opportunities and constraints, which can be crucial for NLP applications in narrow domains
Neural Machine Translation for Mathematical Formulae
May 25, 2023



We tackle the problem of neural machine translation of mathematical formulae between ambiguous presentation languages and unambiguous content languages. Compared to neural machine translation on natural language, mathematical formulae have a much smaller vocabulary and much longer sequences of symbols, while their translation requires extreme precision to satisfy mathematical information needs. In this work, we perform the tasks of translating from LaTeX to Mathematica as well as from LaTeX to semantic LaTeX. While recurrent, recursive, and transformer networks struggle with preserving all contained information, we find that convolutional sequence-to-sequence networks achieve 95.1% and 90.7% exact matches, respectively.
TEIMMA: The First Content Reuse Annotator for Text, Images, and Math
May 22, 2023This demo paper presents the first tool to annotate the reuse of text, images, and mathematical formulae in a document pair -- TEIMMA. Annotating content reuse is particularly useful to develop plagiarism detection algorithms. Real-world content reuse is often obfuscated, which makes it challenging to identify such cases. TEIMMA allows entering the obfuscation type to enable novel classifications for confirmed cases of plagiarism. It enables recording different reuse types for text, images, and mathematical formulae in HTML and supports users by visualizing the content reuse in a document pair using similarity detection methods for text and math.
Methods and Tools to Advance the Retrieval of Mathematical Knowledge from Digital Libraries for Search-, Recommendation-, and Assistance-Systems
May 12, 2023
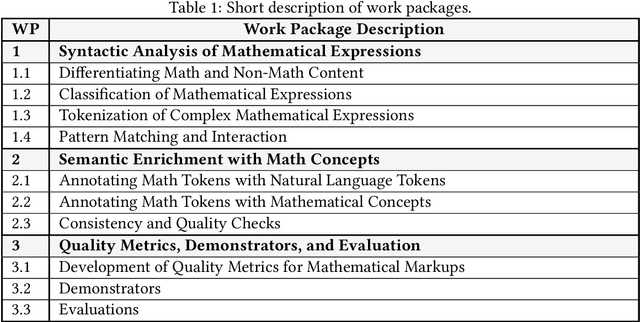

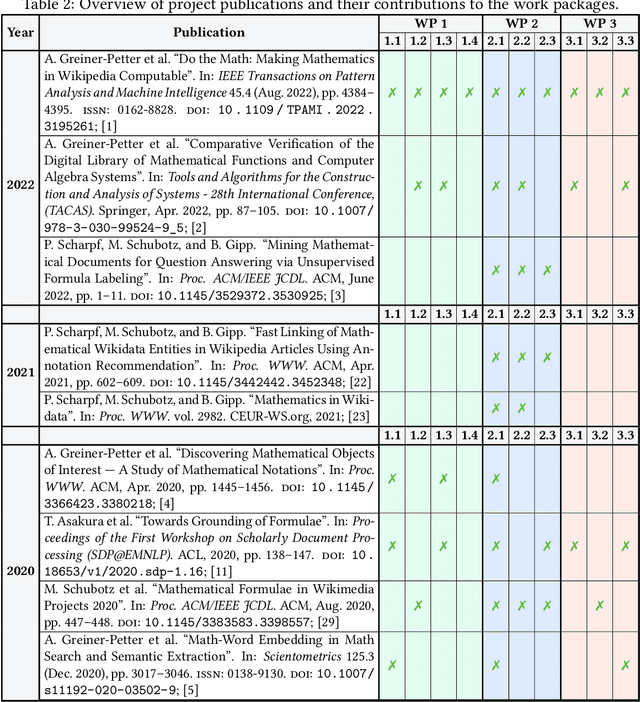
This project investigated new approaches and technologies to enhance the accessibility of mathematical content and its semantic information for a broad range of information retrieval applications. To achieve this goal, the project addressed three main research challenges: (1) syntactic analysis of mathematical expressions, (2) semantic enrichment of mathematical expressions, and (3) evaluation using quality metrics and demonstrators. To make our research useful for the research community, we published tools that enable researchers to process mathematical expressions more effectively and efficiently.
Introducing MBIB -- the first Media Bias Identification Benchmark Task and Dataset Collection
Apr 25, 2023



Although media bias detection is a complex multi-task problem, there is, to date, no unified benchmark grouping these evaluation tasks. We introduce the Media Bias Identification Benchmark (MBIB), a comprehensive benchmark that groups different types of media bias (e.g., linguistic, cognitive, political) under a common framework to test how prospective detection techniques generalize. After reviewing 115 datasets, we select nine tasks and carefully propose 22 associated datasets for evaluating media bias detection techniques. We evaluate MBIB using state-of-the-art Transformer techniques (e.g., T5, BART). Our results suggest that while hate speech, racial bias, and gender bias are easier to detect, models struggle to handle certain bias types, e.g., cognitive and political bias. However, our results show that no single technique can outperform all the others significantly. We also find an uneven distribution of research interest and resource allocation to the individual tasks in media bias. A unified benchmark encourages the development of more robust systems and shifts the current paradigm in media bias detection evaluation towards solutions that tackle not one but multiple media bias types simultaneously.
Paraphrase Detection: Human vs. Machine Content
Mar 24, 2023The growing prominence of large language models, such as GPT-4 and ChatGPT, has led to increased concerns over academic integrity due to the potential for machine-generated content and paraphrasing. Although studies have explored the detection of human- and machine-paraphrased content, the comparison between these types of content remains underexplored. In this paper, we conduct a comprehensive analysis of various datasets commonly employed for paraphrase detection tasks and evaluate an array of detection methods. Our findings highlight the strengths and limitations of different detection methods in terms of performance on individual datasets, revealing a lack of suitable machine-generated datasets that can be aligned with human expectations. Our main finding is that human-authored paraphrases exceed machine-generated ones in terms of difficulty, diversity, and similarity implying that automatically generated texts are not yet on par with human-level performance. Transformers emerged as the most effective method across datasets with TF-IDF excelling on semantically diverse corpora. Additionally, we identify four datasets as the most diverse and challenging for paraphrase detection.
Discovery and Recognition of Formula Concepts using Machine Learning
Mar 19, 2023Citation-based Information Retrieval (IR) methods for scientific documents have proven effective for IR applications, such as Plagiarism Detection or Literature Recommender Systems in academic disciplines that use many references. In science, technology, engineering, and mathematics, researchers often employ mathematical concepts through formula notation to refer to prior knowledge. Our long-term goal is to generalize citation-based IR methods and apply this generalized method to both classical references and mathematical concepts. In this paper, we suggest how mathematical formulas could be cited and define a Formula Concept Retrieval task with two subtasks: Formula Concept Discovery (FCD) and Formula Concept Recognition (FCR). While FCD aims at the definition and exploration of a 'Formula Concept' that names bundled equivalent representations of a formula, FCR is designed to match a given formula to a prior assigned unique mathematical concept identifier. We present machine learning-based approaches to address the FCD and FCR tasks. We then evaluate these approaches on a standardized test collection (NTCIR arXiv dataset). Our FCD approach yields a precision of 68% for retrieving equivalent representations of frequent formulas and a recall of 72% for extracting the formula name from the surrounding text. FCD and FCR enable the citation of formulas within mathematical documents and facilitate semantic search and question answering as well as document similarity assessments for plagiarism detection or recommender systems.