 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAspect-Aware Content-Based Recommendations for Mathematical Research Papers
May 05, 2026Content-based research paper recommendation (CbRPR) has seen advances in computer science and biomedicine, but remains unexplored for mathematics, where paper relatedness is more conceptual than explicit textual or citation-based similarity. Mathematics papers may be connected through shared proof techniques, logical implications, or natural generalizations, yet exhibit minimal textual or citation overlap, rendering existing CbRPR ineffective. To address this gap, we first conduct an expert-driven study characterizing mathematical recommendations, revealing that relevance is inherently \textit{aspect}-driven. Grounded in this insight, we introduce GoldRiM (small, expert-annotated) and SilverRiM (large, automatically derived), the first datasets for \textit{aspect}-aware CbRPR in mathematics. Recognizing that LLM embeddings of mathematical content alone yield suboptimal representation, we propose AchGNN, an \textit{aspect}-conditioned heterogeneous GNN that jointly models textual semantics, citation structure, and author lineage. Across GoldRiM and SilverRiM, AchGNN consistently outperforms prior \textit{aspect}-based CbRPR methods, achieving substantial gains across all evaluated \textit{aspects}. We conduct ablation studies to analyze the contributions of individual \textit{aspect} supervision, authorship lineage, and graph-structural signals to AchGNN's performance. To assess domain generality, we further evaluate AchGNN on the \textit{Papers with Code} dataset of machine learning publications, demonstrating that our \textit{aspect}-aware approach effectively transfers beyond mathematics. We deploy our system on the MaRDI platform to help mathematicians with recommendations and release datasets and code publicly for reproducibility.
Overview of PAN 2026: Voight-Kampff Generative AI Detection, Text Watermarking, Multi-Author Writing Style Analysis, Generative Plagiarism Detection, and Reasoning Trajectory Detection
Feb 09, 2026The goal of the PAN workshop is to advance computational stylometry and text forensics via objective and reproducible evaluation. In 2026, we run the following five tasks: (1) Voight-Kampff Generative AI Detection, particularly in mixed and obfuscated authorship scenarios, (2) Text Watermarking, a new task that aims to find new and benchmark the robustness of existing text watermarking schemes, (3) Multi-author Writing Style Analysis, a continued task that aims to find positions of authorship change, (4) Generative Plagiarism Detection, a continued task that targets source retrieval and text alignment between generated text and source documents, and (5) Reasoning Trajectory Detection, a new task that deals with source detection and safety detection of LLM-generated or human-written reasoning trajectories. As in previous years, PAN invites software submissions as easy-to-reproduce Docker containers for most of the tasks. Since PAN 2012, more than 1,100 submissions have been made this way via the TIRA experimentation platform.
TEIMMA: The First Content Reuse Annotator for Text, Images, and Math
May 22, 2023This demo paper presents the first tool to annotate the reuse of text, images, and mathematical formulae in a document pair -- TEIMMA. Annotating content reuse is particularly useful to develop plagiarism detection algorithms. Real-world content reuse is often obfuscated, which makes it challenging to identify such cases. TEIMMA allows entering the obfuscation type to enable novel classifications for confirmed cases of plagiarism. It enables recording different reuse types for text, images, and mathematical formulae in HTML and supports users by visualizing the content reuse in a document pair using similarity detection methods for text and math.
Methods and Tools to Advance the Retrieval of Mathematical Knowledge from Digital Libraries for Search-, Recommendation-, and Assistance-Systems
May 12, 2023
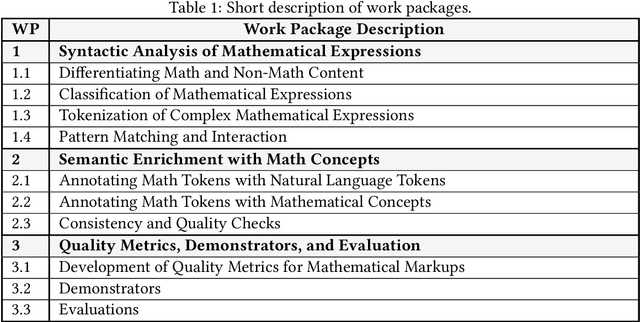

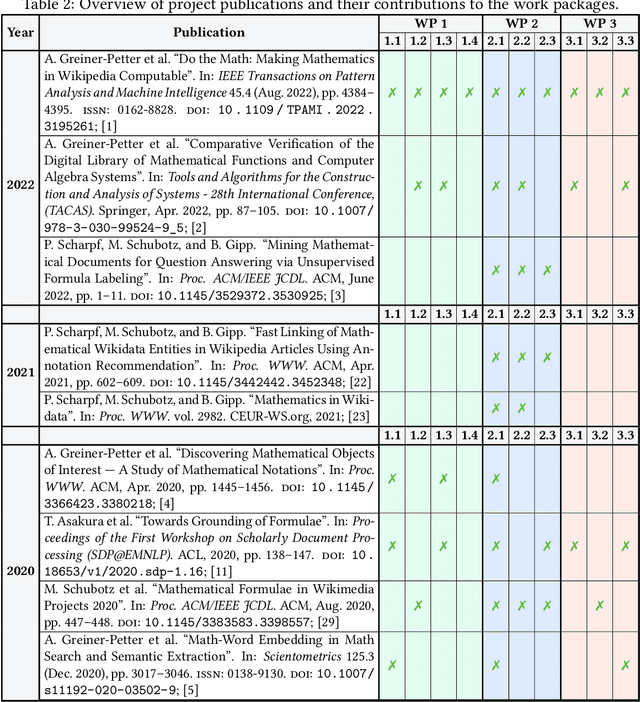
This project investigated new approaches and technologies to enhance the accessibility of mathematical content and its semantic information for a broad range of information retrieval applications. To achieve this goal, the project addressed three main research challenges: (1) syntactic analysis of mathematical expressions, (2) semantic enrichment of mathematical expressions, and (3) evaluation using quality metrics and demonstrators. To make our research useful for the research community, we published tools that enable researchers to process mathematical expressions more effectively and efficiently.
Semantic Preserving Bijective Mappings of Mathematical Formulae between Document Preparation Systems and Computer Algebra Systems
Sep 17, 2021
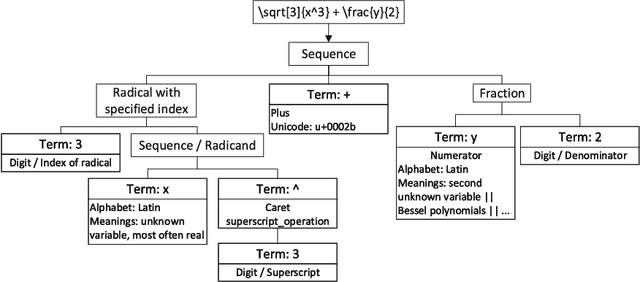
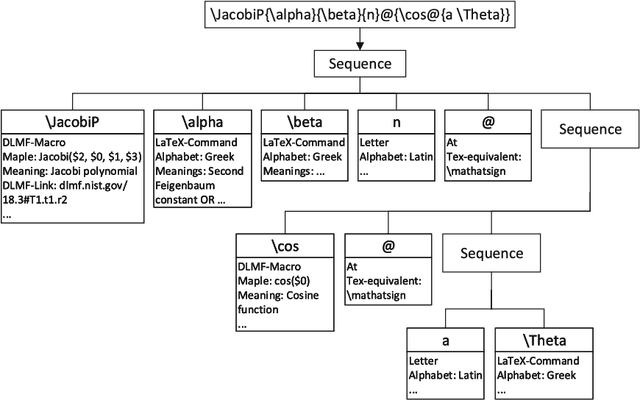
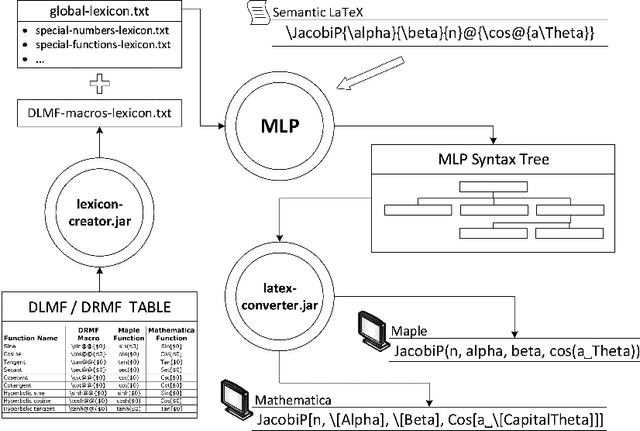
Document preparation systems like LaTeX offer the ability to render mathematical expressions as one would write these on paper. Using LaTeX, LaTeXML, and tools generated for use in the National Institute of Standards (NIST) Digital Library of Mathematical Functions, semantically enhanced mathematical LaTeX markup (semantic LaTeX) is achieved by using a semantic macro set. Computer algebra systems (CAS) such as Maple and Mathematica use alternative markup to represent mathematical expressions. By taking advantage of Youssef's Part-of-Math tagger and CAS internal representations, we develop algorithms to translate mathematical expressions represented in semantic LaTeX to corresponding CAS representations and vice versa. We have also developed tools for translating the entire Wolfram Encoding Continued Fraction Knowledge and University of Antwerp Continued Fractions for Special Functions datasets, for use in the NIST Digital Repository of Mathematical Formulae. The overall goal of these efforts is to provide semantically enriched standard conforming MathML representations to the public for formulae in digital mathematics libraries. These representations include presentation MathML, content MathML, generic LaTeX, semantic LaTeX, and now CAS representations as well.
Why Machines Cannot Learn Mathematics, Yet
May 20, 2019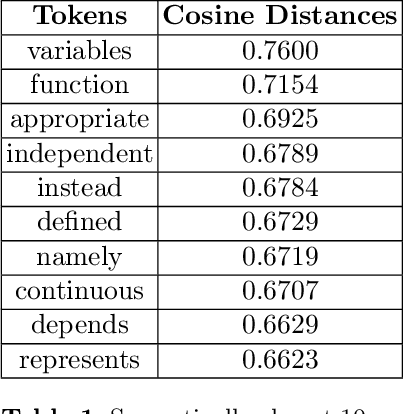
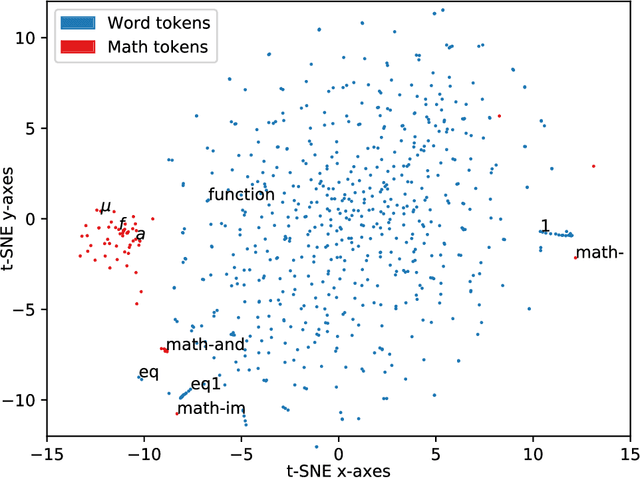
Nowadays, Machine Learning (ML) is seen as the universal solution to improve the effectiveness of information retrieval (IR) methods. However, while mathematics is a precise and accurate science, it is usually expressed by less accurate and imprecise descriptions, contributing to the relative dearth of machine learning applications for IR in this domain. Generally, mathematical documents communicate their knowledge with an ambiguous, context-dependent, and non-formal language. Given recent advances in ML, it seems canonical to apply ML techniques to represent and retrieve mathematics semantically. In this work, we apply popular text embedding techniques to the arXiv collection of STEM documents and explore how these are unable to properly understand mathematics from that corpus. In addition, we also investigate the missing aspects that would allow mathematics to be learned by computers.