 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Capacity of Distinguishable Synthetic Identity Generation under Face Verification
Apr 12, 2026We study how many synthetic identities can be generated so that a face verifier declares same-identity pairs as matches and different-identity pairs as non-matches at a fixed threshold $τ$. We formalize this question for a generative face-recognition pipeline consisting of a generator followed by a normalized recognition map with outputs on the unit hypersphere. We define the capacity of distinguishable identity generation as the largest number of latent identities whose induced embedding distributions satisfy prescribed same-identity and different-identity verification constraints. In the deterministic view-invariant regime, we show that this capacity is characterized by a spherical-code problem over the realizable set of embeddings, and reduces to the classical spherical-code quantity under a full angular expressivity assumption. For stochastic identity generation, we introduce a centered model and derive a sufficient admissibility condition in which the required separation between identity centers is $\arccos(τ)+2ρ$, where $ρ$ is a within-identity concentration radius. Under full angular expressivity, this yields spherical-code-based achievable lower bounds and a positive asymptotic lower bound on the exponential growth rate with embedding dimension. We also introduce a prior-constrained random-code capacity, in which latent identities are sampled independently from a given prior, and derive high-probability lower bounds in terms of pairwise separation-failure probabilities of the induced identity centers. Under a stronger full-cap-support model, we obtain a converse and an exact spherical-code characterization.
Principles Do Not Apply Themselves: A Hermeneutic Perspective on AI Alignment
Apr 12, 2026AI alignment is often framed as the task of ensuring that an AI system follows a set of stated principles or human preferences, but general principles rarely determine their own application in concrete cases. When principles conflict, when they are too broad to settle a situation, or when the relevant facts are unclear, an additional act of judgment is required. This paper analyzes that step through the lens of hermeneutics and argues that alignment therefore includes an interpretive component: it involves context-sensitive judgments about how principles should be read, applied, and prioritized in practice. We connect this claim to recent empirical findings showing that a substantial portion of preference-labeling data falls into cases of principle conflict or indifference, where the principle set does not uniquely determine a decision. We then draw an operational consequence: because such judgments are expressed in behavior, many alignment-relevant choices appear only in the distribution of responses a model generates at deployment time. To formalize this point, we distinguish deployment-induced and corpus-induced evaluation and show that off-policy audits can fail to capture alignment-relevant failures when the two response distributions differ. We argue that principle-specified alignment includes a context-dependent interpretive component.
Synthetic to Authentic: Transferring Realism to 3D Face Renderings for Boosting Face Recognition
Jul 10, 2024



In this paper, we investigate the potential of image-to-image translation (I2I) techniques for transferring realism to 3D-rendered facial images in the context of Face Recognition (FR) systems. The primary motivation for using 3D-rendered facial images lies in their ability to circumvent the challenges associated with collecting large real face datasets for training FR systems. These images are generated entirely by 3D rendering engines, facilitating the generation of synthetic identities. However, it has been observed that FR systems trained on such synthetic datasets underperform when compared to those trained on real datasets, on various FR benchmarks. In this work, we demonstrate that by transferring the realism to 3D-rendered images (i.e., making the 3D-rendered images look more real), we can boost the performance of FR systems trained on these more photorealistic images. This improvement is evident when these systems are evaluated against FR benchmarks utilizing real-world data, thereby paving new pathways for employing synthetic data in real-world applications.
Deep Privacy Funnel Model: From a Discriminative to a Generative Approach with an Application to Face Recognition
Apr 03, 2024



In this study, we apply the information-theoretic Privacy Funnel (PF) model to the domain of face recognition, developing a novel method for privacy-preserving representation learning within an end-to-end training framework. Our approach addresses the trade-off between obfuscation and utility in data protection, quantified through logarithmic loss, also known as self-information loss. This research provides a foundational exploration into the integration of information-theoretic privacy principles with representation learning, focusing specifically on the face recognition systems. We particularly highlight the adaptability of our framework with recent advancements in face recognition networks, such as AdaFace and ArcFace. In addition, we introduce the Generative Privacy Funnel ($\mathsf{GenPF}$) model, a paradigm that extends beyond the traditional scope of the PF model, referred to as the Discriminative Privacy Funnel ($\mathsf{DisPF}$). This $\mathsf{GenPF}$ model brings new perspectives on data generation methods with estimation-theoretic and information-theoretic privacy guarantees. Complementing these developments, we also present the deep variational PF (DVPF) model. This model proposes a tractable variational bound for measuring information leakage, enhancing the understanding of privacy preservation challenges in deep representation learning. The DVPF model, associated with both $\mathsf{DisPF}$ and $\mathsf{GenPF}$ models, sheds light on connections with various generative models such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Diffusion models. Complementing our theoretical contributions, we release a reproducible PyTorch package, facilitating further exploration and application of these privacy-preserving methodologies in face recognition systems.
Deep Variational Privacy Funnel: General Modeling with Applications in Face Recognition
Jan 26, 2024


In this study, we harness the information-theoretic Privacy Funnel (PF) model to develop a method for privacy-preserving representation learning using an end-to-end training framework. We rigorously address the trade-off between obfuscation and utility. Both are quantified through the logarithmic loss, a measure also recognized as self-information loss. This exploration deepens the interplay between information-theoretic privacy and representation learning, offering substantive insights into data protection mechanisms for both discriminative and generative models. Importantly, we apply our model to state-of-the-art face recognition systems. The model demonstrates adaptability across diverse inputs, from raw facial images to both derived or refined embeddings, and is competent in tasks such as classification, reconstruction, and generation.
Bottlenecks CLUB: Unifying Information-Theoretic Trade-offs Among Complexity, Leakage, and Utility
Jul 11, 2022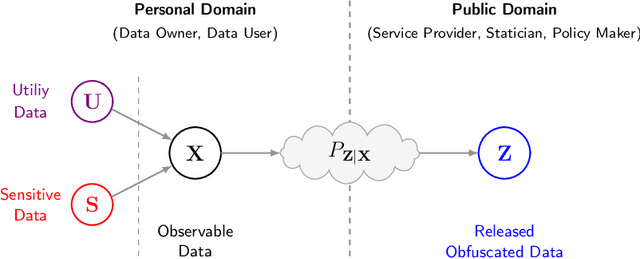
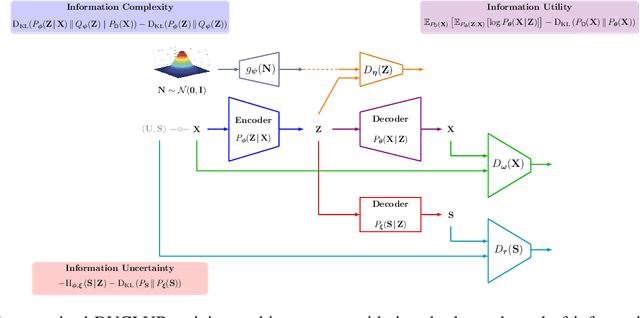
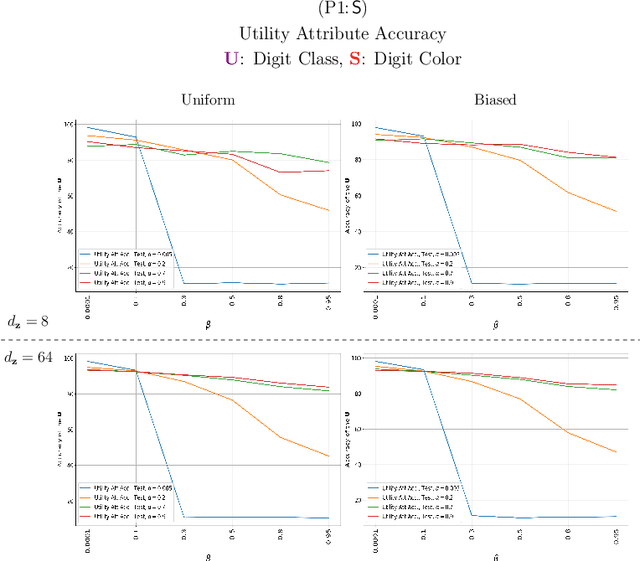
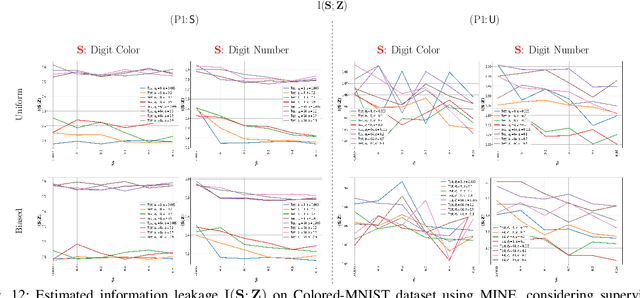
Bottleneck problems are an important class of optimization problems that have recently gained increasing attention in the domain of machine learning and information theory. They are widely used in generative models, fair machine learning algorithms, design of privacy-assuring mechanisms, and appear as information-theoretic performance bounds in various multi-user communication problems. In this work, we propose a general family of optimization problems, termed as complexity-leakage-utility bottleneck (CLUB) model, which (i) provides a unified theoretical framework that generalizes most of the state-of-the-art literature for the information-theoretic privacy models, (ii) establishes a new interpretation of the popular generative and discriminative models, (iii) constructs new insights to the generative compression models, and (iv) can be used in the fair generative models. We first formulate the CLUB model as a complexity-constrained privacy-utility optimization problem. We then connect it with the closely related bottleneck problems, namely information bottleneck (IB), privacy funnel (PF), deterministic IB (DIB), conditional entropy bottleneck (CEB), and conditional PF (CPF). We show that the CLUB model generalizes all these problems as well as most other information-theoretic privacy models. Then, we construct the deep variational CLUB (DVCLUB) models by employing neural networks to parameterize variational approximations of the associated information quantities. Building upon these information quantities, we present unified objectives of the supervised and unsupervised DVCLUB models. Leveraging the DVCLUB model in an unsupervised setup, we then connect it with state-of-the-art generative models, such as variational auto-encoders (VAEs), generative adversarial networks (GANs), as well as the Wasserstein GAN (WGAN), Wasserstein auto-encoder (WAE), and adversarial auto-encoder (AAE) models through the optimal transport (OT) problem. We then show that the DVCLUB model can also be used in fair representation learning problems, where the goal is to mitigate the undesired bias during the training phase of a machine learning model. We conduct extensive quantitative experiments on colored-MNIST and CelebA datasets, with a public implementation available, to evaluate and analyze the CLUB model.
Variational Leakage: The Role of Information Complexity in Privacy Leakage
Jun 08, 2021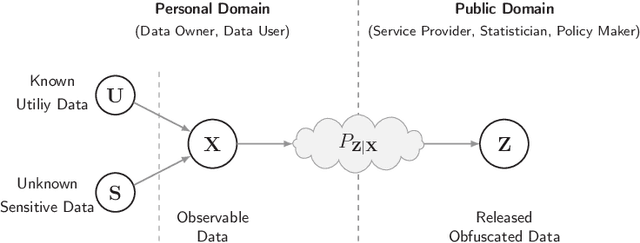
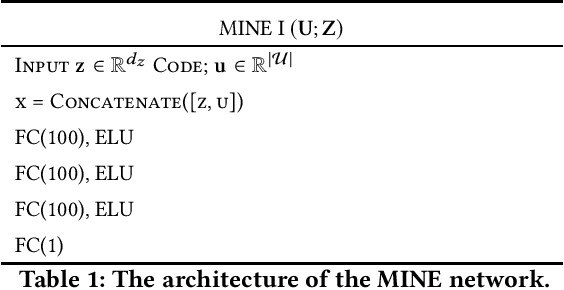
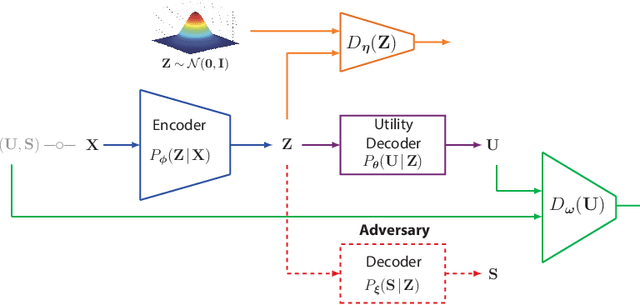

We study the role of information complexity in privacy leakage about an attribute of an adversary's interest, which is not known a priori to the system designer. Considering the supervised representation learning setup and using neural networks to parameterize the variational bounds of information quantities, we study the impact of the following factors on the amount of information leakage: information complexity regularizer weight, latent space dimension, the cardinalities of the known utility and unknown sensitive attribute sets, the correlation between utility and sensitive attributes, and a potential bias in a sensitive attribute of adversary's interest. We conduct extensive experiments on Colored-MNIST and CelebA datasets to evaluate the effect of information complexity on the amount of intrinsic leakage.
Privacy-Preserving Near Neighbor Search via Sparse Coding with Ambiguation
Feb 08, 2021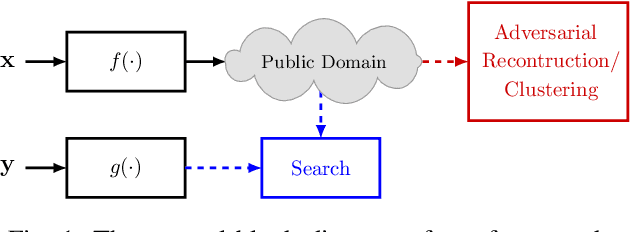
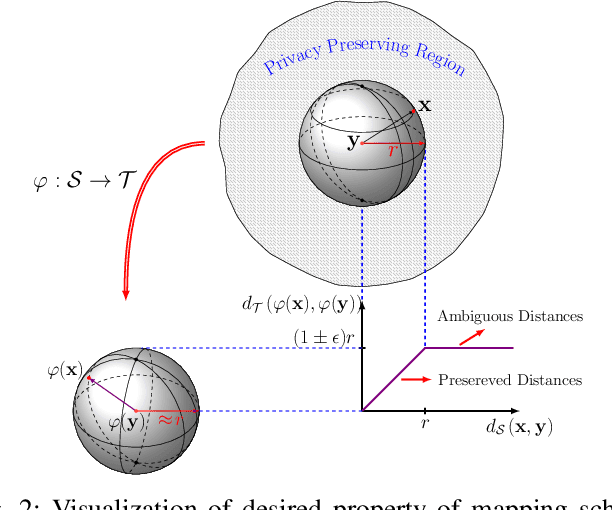

In this paper, we propose a framework for privacy-preserving approximate near neighbor search via stochastic sparsifying encoding. The core of the framework relies on sparse coding with ambiguation (SCA) mechanism that introduces the notion of inherent shared secrecy based on the support intersection of sparse codes. This approach is `fairness-aware', in the sense that any point in the neighborhood has an equiprobable chance to be chosen. Our approach can be applied to raw data, latent representation of autoencoders, and aggregated local descriptors. The proposed method is tested on both synthetic i.i.d data and real large-scale image databases.
Privacy-Preserving Image Sharing via Sparsifying Layers on Convolutional Groups
Feb 04, 2020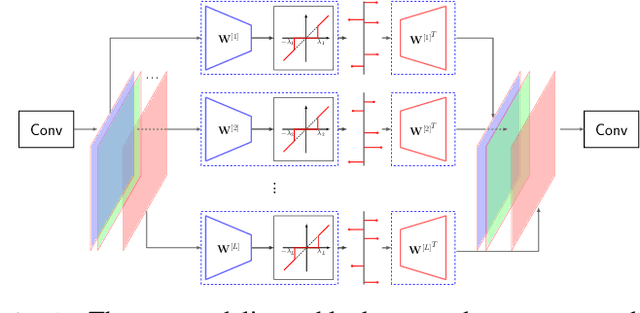
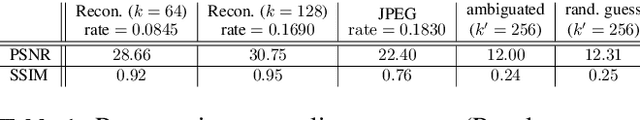


We propose a practical framework to address the problem of privacy-aware image sharing in large-scale setups. We argue that, while compactness is always desired at scale, this need is more severe when trying to furthermore protect the privacy-sensitive content. We therefore encode images, such that, from one hand, representations are stored in the public domain without paying the huge cost of privacy protection, but ambiguated and hence leaking no discernible content from the images, unless a combinatorially-expensive guessing mechanism is available for the attacker. From the other hand, authorized users are provided with very compact keys that can easily be kept secure. This can be used to disambiguate and reconstruct faithfully the corresponding access-granted images. We achieve this with a convolutional autoencoder of our design, where feature maps are passed independently through sparsifying transformations, providing multiple compact codes, each responsible for reconstructing different attributes of the image. The framework is tested on a large-scale database of images with public implementation available.
Reconstruction of Privacy-Sensitive Data from Protected Templates
May 08, 2019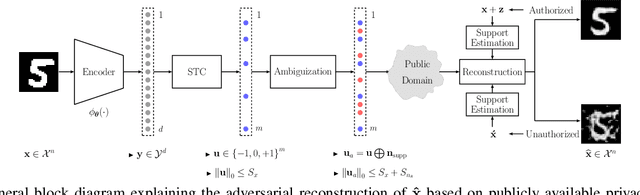
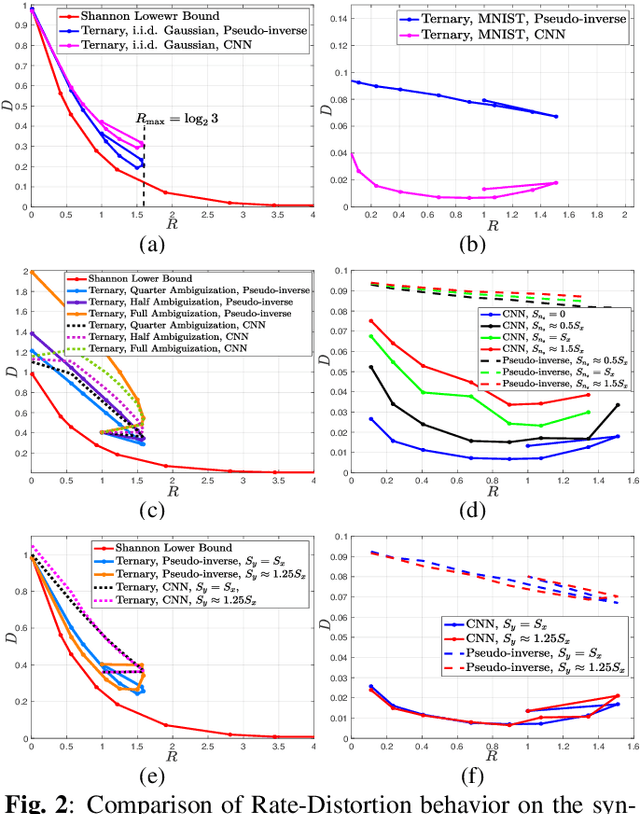

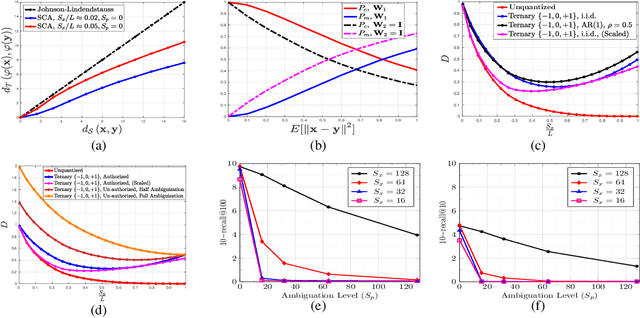
In this paper, we address the problem of data reconstruction from privacy-protected templates, based on recent concept of sparse ternary coding with ambiguization (STCA). The STCA is a generalization of randomization techniques which includes random projections, lossy quantization, and addition of ambiguization noise to satisfy the privacy-utility trade-off requirements. The theoretical privacy-preserving properties of STCA have been validated on synthetic data. However, the applicability of STCA to real data and potential threats linked to reconstruction based on recent deep reconstruction algorithms are still open problems. Our results demonstrate that STCA still achieves the claimed theoretical performance when facing deep reconstruction attacks for the synthetic i.i.d. data, while for real images special measures are required to guarantee proper protection of the templates.