 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwin Systems for DeepCBR: A Menagerie of Deep Learning and Case-Based Reasoning Pairings for Explanation and Data Augmentation
Apr 29, 2021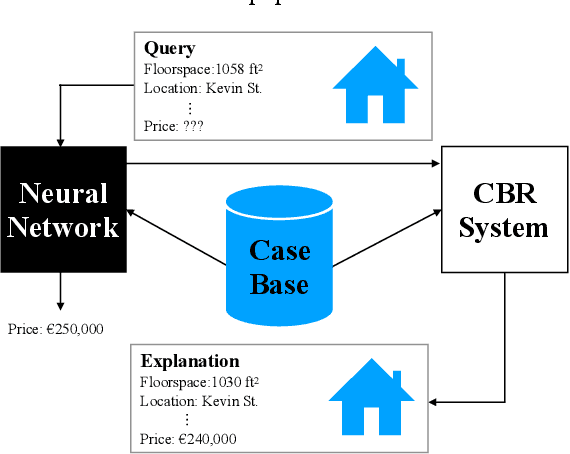
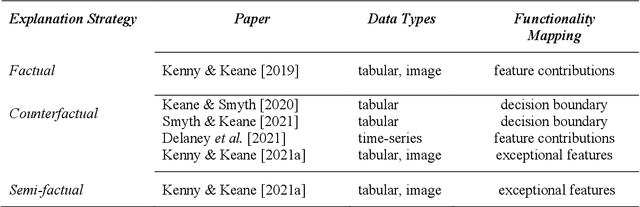
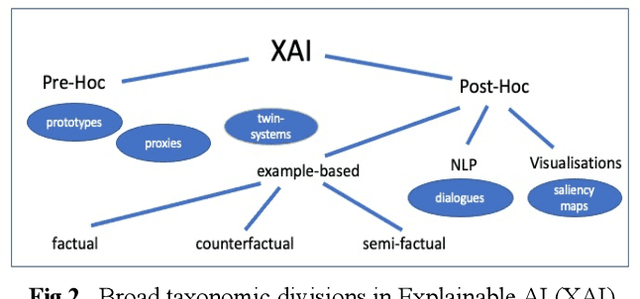

Recently, it has been proposed that fruitful synergies may exist between Deep Learning (DL) and Case Based Reasoning (CBR); that there are insights to be gained by applying CBR ideas to problems in DL (what could be called DeepCBR). In this paper, we report on a program of research that applies CBR solutions to the problem of Explainable AI (XAI) in the DL. We describe a series of twin-systems pairings of opaque DL models with transparent CBR models that allow the latter to explain the former using factual, counterfactual and semi-factual explanation strategies. This twinning shows that functional abstractions of DL (e.g., feature weights, feature importance and decision boundaries) can be used to drive these explanatory solutions. We also raise the prospect that this research also applies to the problem of Data Augmentation in DL, underscoring the fecundity of these DeepCBR ideas.
Handling Climate Change Using Counterfactuals: Using Counterfactuals in Data Augmentation to Predict Crop Growth in an Uncertain Climate Future
Apr 08, 2021

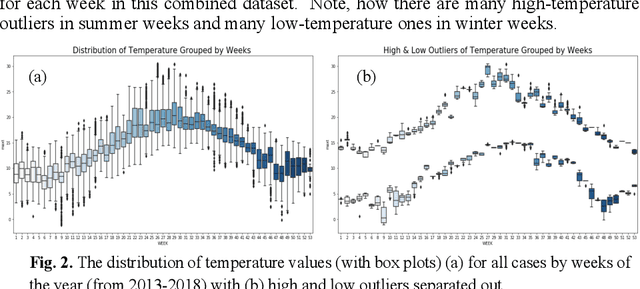
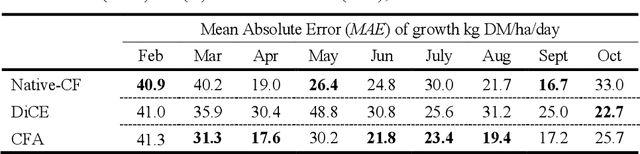
Climate change poses a major challenge to humanity, especially in its impact on agriculture, a challenge that a responsible AI should meet. In this paper, we examine a CBR system (PBI-CBR) designed to aid sustainable dairy farming by supporting grassland management, through accurate crop growth prediction. As climate changes, PBI-CBRs historical cases become less useful in predicting future grass growth. Hence, we extend PBI-CBR using data augmentation, to specifically handle disruptive climate events, using a counterfactual method (from XAI). Study 1 shows that historical, extreme climate-events (climate outlier cases) tend to be used by PBI-CBR to predict grass growth during climate disrupted periods. Study 2 shows that synthetic outliers, generated as counterfactuals on a outlier-boundary, improve the predictive accuracy of PBICBR, during the drought of 2018. This study also shows that an instance-based counterfactual method does better than a benchmark, constraint-guided method.
If Only We Had Better Counterfactual Explanations: Five Key Deficits to Rectify in the Evaluation of Counterfactual XAI Techniques
Feb 26, 2021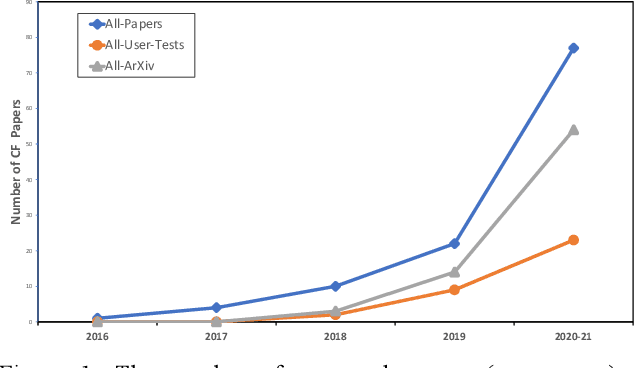
In recent years, there has been an explosion of AI research on counterfactual explanations as a solution to the problem of eXplainable AI (XAI). These explanations seem to offer technical, psychological and legal benefits over other explanation techniques. We survey 100 distinct counterfactual explanation methods reported in the literature. This survey addresses the extent to which these methods have been adequately evaluated, both psychologically and computationally, and quantifies the shortfalls occurring. For instance, only 21% of these methods have been user tested. Five key deficits in the evaluation of these methods are detailed and a roadmap, with standardised benchmark evaluations, is proposed to resolve the issues arising; issues, that currently effectively block scientific progress in this field.
A Few Good Counterfactuals: Generating Interpretable, Plausible and Diverse Counterfactual Explanations
Jan 22, 2021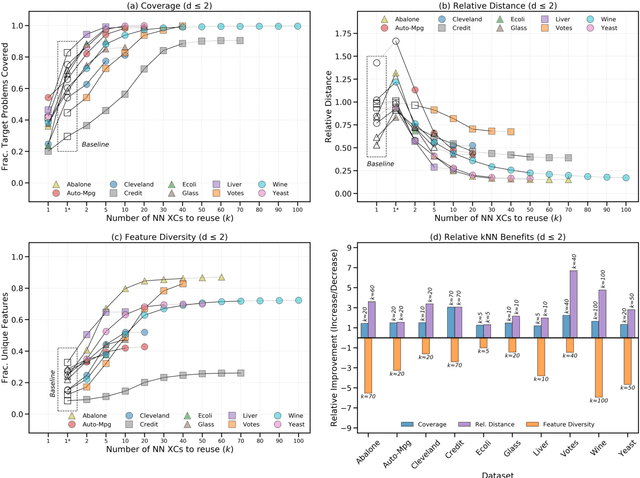
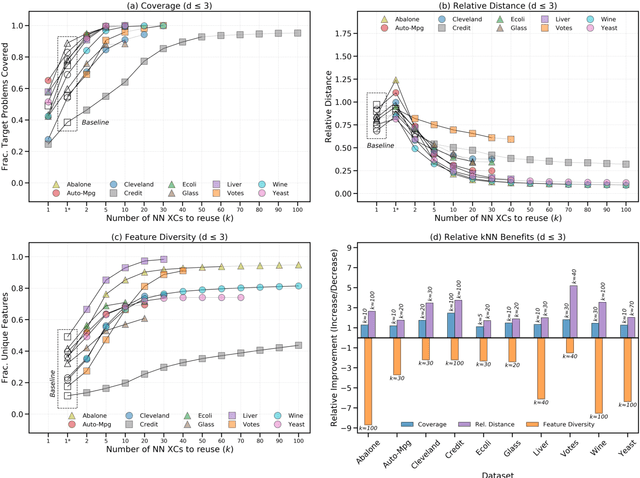
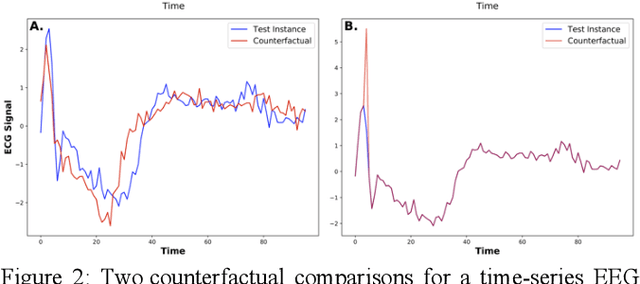
Counterfactual explanations provide a potentially significant solution to the Explainable AI (XAI) problem, but good, native counterfactuals have been shown to rarely occur in most datasets. Hence, the most popular methods generate synthetic counterfactuals using blind perturbation. However, such methods have several shortcomings: the resulting counterfactuals (i) may not be valid data-points (they often use features that do not naturally occur), (ii) may lack the sparsity of good counterfactuals (if they modify too many features), and (iii) may lack diversity (if the generated counterfactuals are minimal variants of one another). We describe a method designed to overcome these problems, one that adapts native counterfactuals in the original dataset, to generate sparse, diverse synthetic counterfactuals from naturally occurring features. A series of experiments are reported that systematically explore parametric variations of this novel method on common datasets to establish the conditions for optimal performance.
Generating Plausible Counterfactual Explanations for Deep Transformers in Financial Text Classification
Oct 23, 2020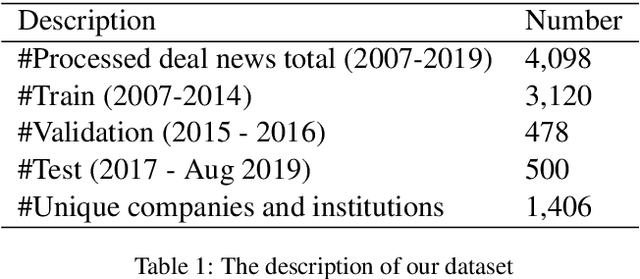
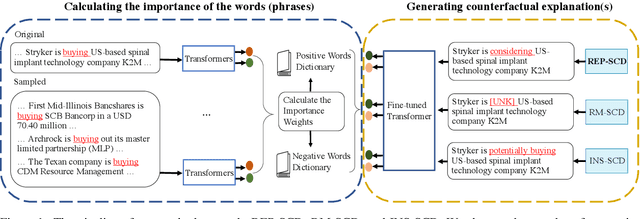
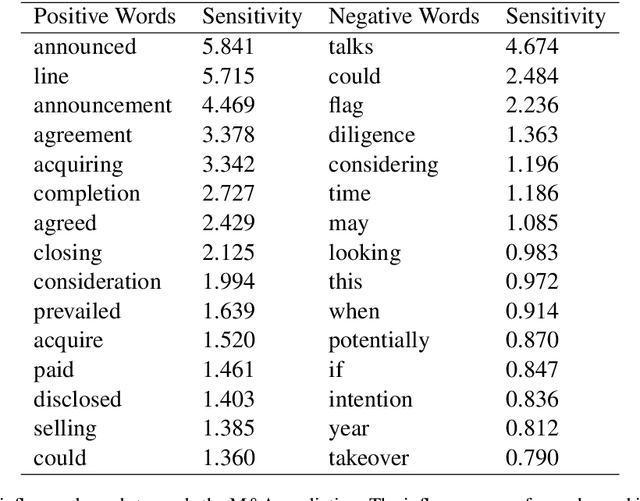
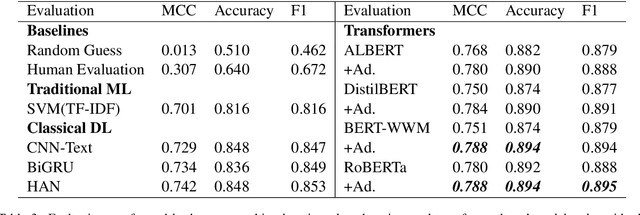
Corporate mergers and acquisitions (M&A) account for billions of dollars of investment globally every year, and offer an interesting and challenging domain for artificial intelligence. However, in these highly sensitive domains, it is crucial to not only have a highly robust and accurate model, but be able to generate useful explanations to garner a user's trust in the automated system. Regrettably, the recent research regarding eXplainable AI (XAI) in financial text classification has received little to no attention, and many current methods for generating textual-based explanations result in highly implausible explanations, which damage a user's trust in the system. To address these issues, this paper proposes a novel methodology for producing plausible counterfactual explanations, whilst exploring the regularization benefits of adversarial training on language models in the domain of FinTech. Exhaustive quantitative experiments demonstrate that not only does this approach improve the model accuracy when compared to the current state-of-the-art and human performance, but it also generates counterfactual explanations which are significantly more plausible based on human trials.
Good Counterfactuals and Where to Find Them: A Case-Based Technique for Generating Counterfactuals for Explainable AI
May 26, 2020
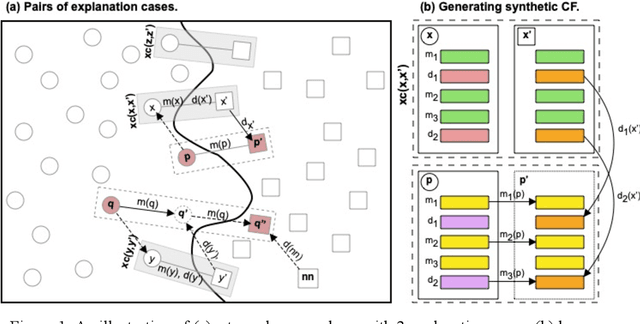
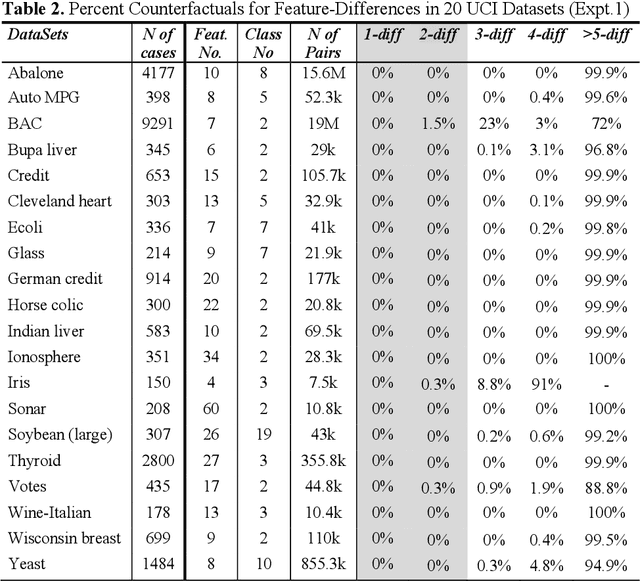
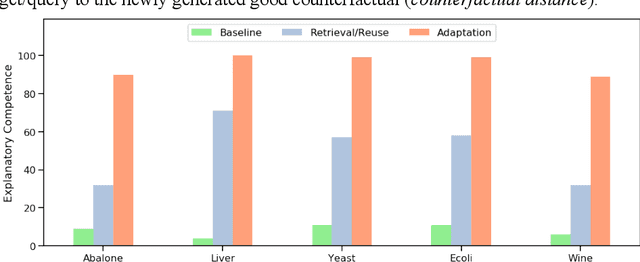
Recently, a groundswell of research has identified the use of counterfactual explanations as a potentially significant solution to the Explainable AI (XAI) problem. It is argued that (a) technically, these counterfactual cases can be generated by permuting problem-features until a class change is found, (b) psychologically, they are much more causally informative than factual explanations, (c) legally, they are GDPR-compliant. However, there are issues around the finding of good counterfactuals using current techniques (e.g. sparsity and plausibility). We show that many commonly-used datasets appear to have few good counterfactuals for explanation purposes. So, we propose a new case based approach for generating counterfactuals using novel ideas about the counterfactual potential and explanatory coverage of a case-base. The new technique reuses patterns of good counterfactuals, present in a case-base, to generate analogous counterfactuals that can explain new problems and their solutions. Several experiments show how this technique can improve the counterfactual potential and explanatory coverage of case-bases that were previously found wanting.
* 15 pages, 3 figures
Personalized, Health-Aware Recipe Recommendation: An Ensemble Topic Modeling Based Approach
Jul 31, 2019
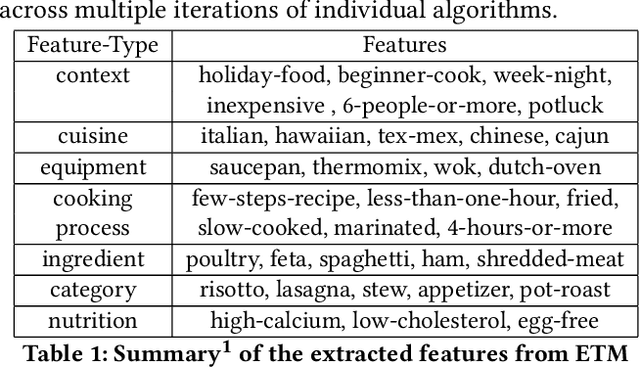
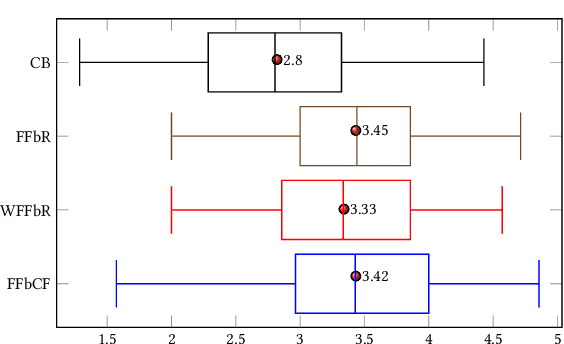
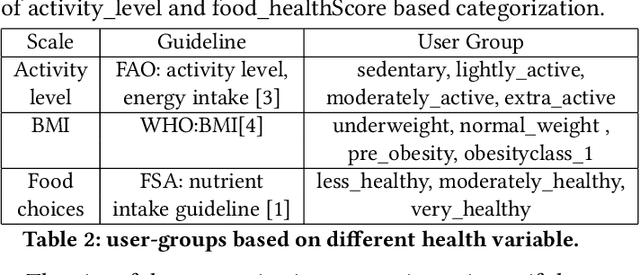
Food choices are personal and complex and have a significant impact on our long-term health and quality of life. By helping users to make informed and satisfying decisions, Recommender Systems (RS) have the potential to support users in making healthier food choices. Intelligent users-modeling is a key challenge in achieving this potential. This paper investigates Ensemble Topic Modelling (EnsTM) based Feature Identification techniques for efficient user-modeling and recipe recommendation. It builds on findings in EnsTM to propose a reduced data representation format and a smart user-modeling strategy that makes capturing user-preference fast, efficient and interactive. This approach enables personalization, even in a cold-start scenario. This paper proposes two different EnsTM based and one Hybrid EnsTM based recommenders. We compared all three EnsTM based variations through a user study with 48 participants, using a large-scale,real-world corpus of 230,876 recipes, and compare against a conventional Content Based (CB) approach. EnsTM based recommenders performed significantly better than the CB approach. Besides acknowledging multi-domain contents such as taste, demographics and cost, our proposed approach also considers user's nutritional preference and assists them finding recipes under diverse nutritional categories. Furthermore, it provides excellent coverage and enables implicit understanding of user's food practices. Subsequent analysis also exposed correlation between certain features and a healthier lifestyle.
RARD II: The 2nd Related-Article Recommendation Dataset
Jul 20, 2018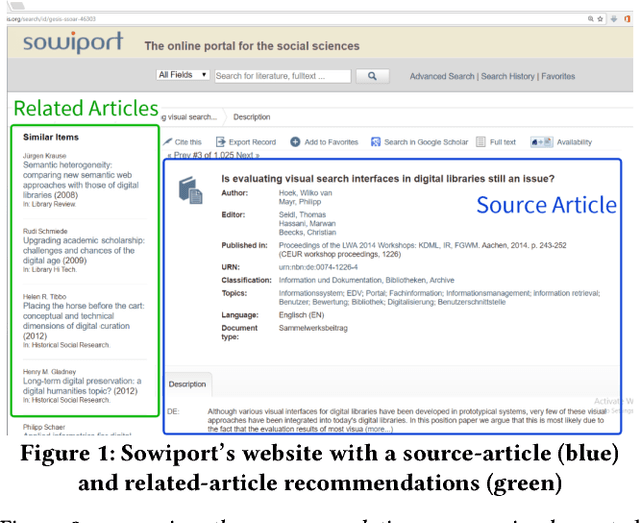

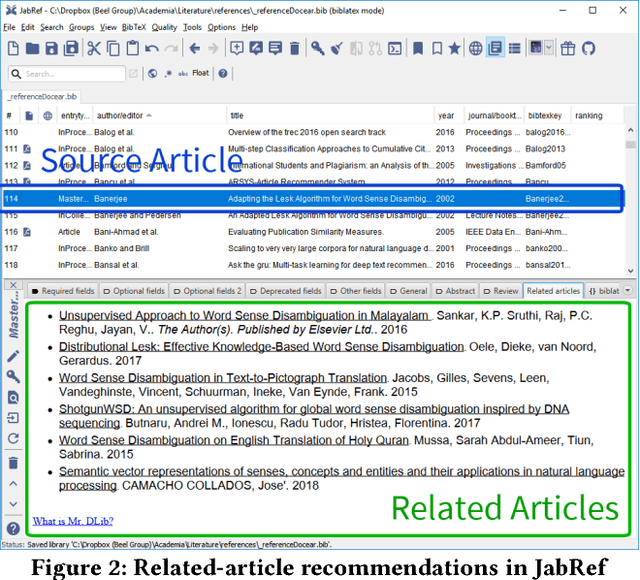
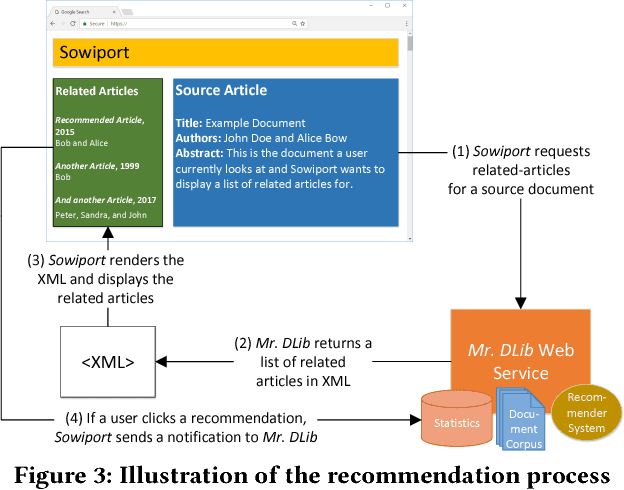
The main contribution of this paper is to introduce and describe a new recommender-systems dataset (RARD II). It is based on data from a recommender-system in the digital library and reference management software domain. As such, it complements datasets from other domains such as books, movies, and music. The RARD II dataset encompasses 89m recommendations, covering an item-space of 24m unique items. RARD II provides a range of rich recommendation data, beyond conventional ratings. For example, in addition to the usual ratings matrices, RARD II includes the original recommendation logs, which provide a unique insight into many aspects of the algorithms that generated the recommendations. In this paper, we summarise the key features of this dataset release, describing how it was generated and discussing some of its unique features.
Aggregating Content and Network Information to Curate Twitter User Lists
Jul 02, 2012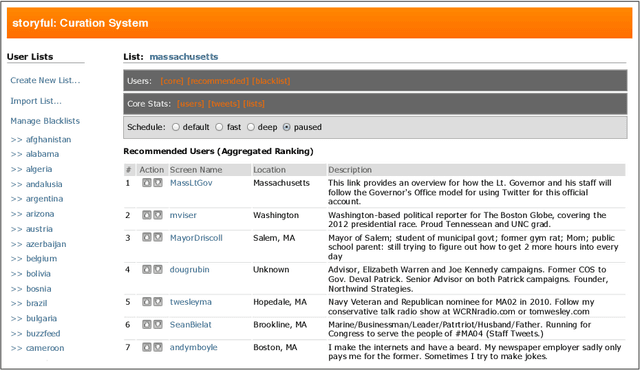
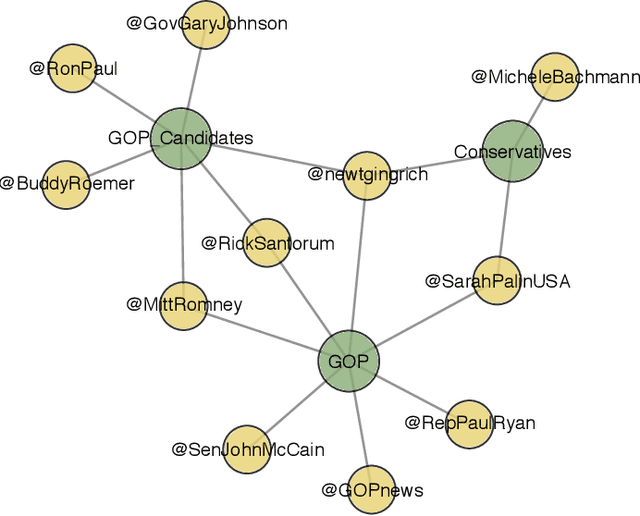
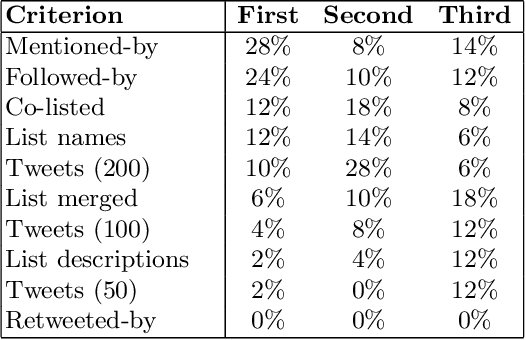
Twitter introduced user lists in late 2009, allowing users to be grouped according to meaningful topics or themes. Lists have since been adopted by media outlets as a means of organising content around news stories. Thus the curation of these lists is important - they should contain the key information gatekeepers and present a balanced perspective on a story. Here we address this list curation process from a recommender systems perspective. We propose a variety of criteria for generating user list recommendations, based on content analysis, network analysis, and the "crowdsourcing" of existing user lists. We demonstrate that these types of criteria are often only successful for datasets with certain characteristics. To resolve this issue, we propose the aggregation of these different "views" of a news story on Twitter to produce more accurate user recommendations to support the curation process.