 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptivity and Computation-Statistics Tradeoffs for Kernel and Distance based High Dimensional Two Sample Testing
Aug 04, 2015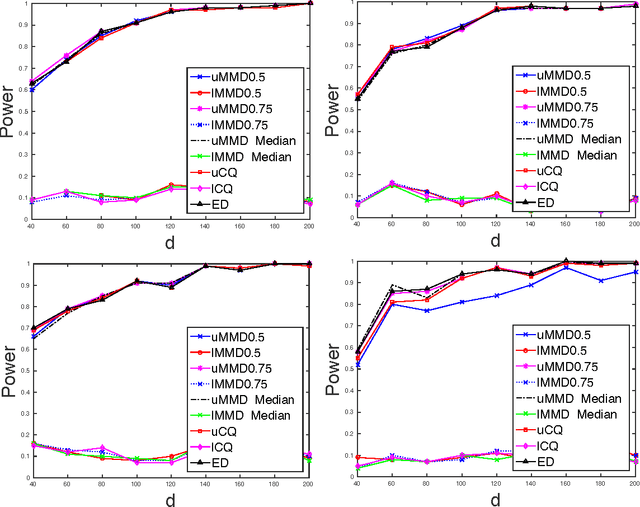
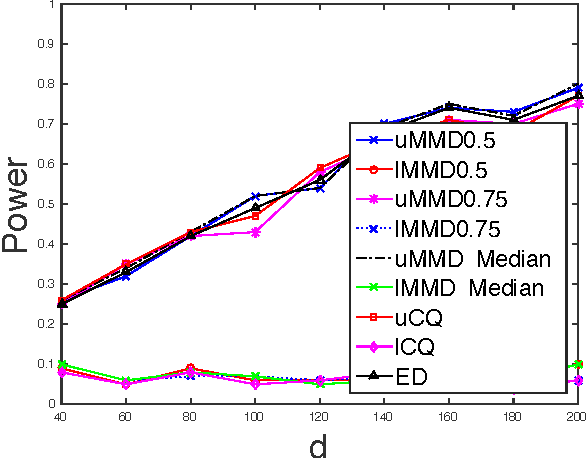
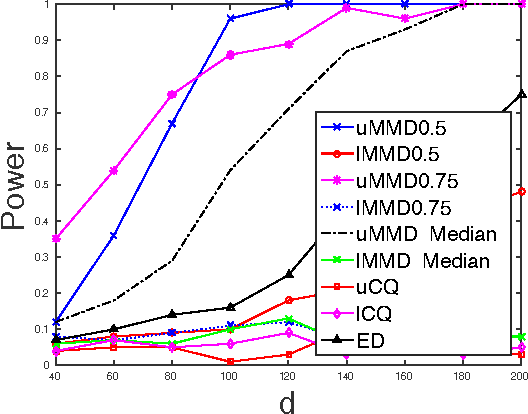
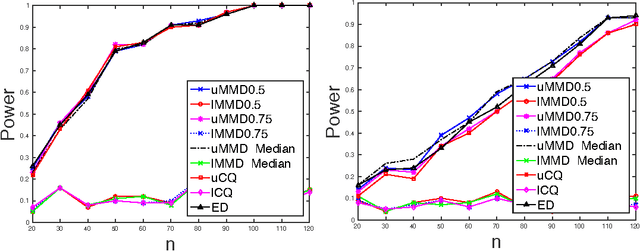
Nonparametric two sample testing is a decision theoretic problem that involves identifying differences between two random variables without making parametric assumptions about their underlying distributions. We refer to the most common settings as mean difference alternatives (MDA), for testing differences only in first moments, and general difference alternatives (GDA), which is about testing for any difference in distributions. A large number of test statistics have been proposed for both these settings. This paper connects three classes of statistics - high dimensional variants of Hotelling's t-test, statistics based on Reproducing Kernel Hilbert Spaces, and energy statistics based on pairwise distances. We ask the question: how much statistical power do popular kernel and distance based tests for GDA have when the unknown distributions differ in their means, compared to specialized tests for MDA? We formally characterize the power of popular tests for GDA like the Maximum Mean Discrepancy with the Gaussian kernel (gMMD) and bandwidth-dependent variants of the Energy Distance with the Euclidean norm (eED) in the high-dimensional MDA regime. Some practically important properties include (a) eED and gMMD have asymptotically equal power; furthermore they enjoy a free lunch because, while they are additionally consistent for GDA, they also have the same power as specialized high-dimensional t-test variants for MDA. All these tests are asymptotically optimal (including matching constants) under MDA for spherical covariances, according to simple lower bounds, (b) The power of gMMD is independent of the kernel bandwidth, as long as it is larger than the choice made by the median heuristic, (c) There is a clear and smooth computation-statistics tradeoff for linear-time, subquadratic-time and quadratic-time versions of these tests, with more computation resulting in higher power.
Influence Functions for Machine Learning: Nonparametric Estimators for Entropies, Divergences and Mutual Informations
Jun 19, 2015
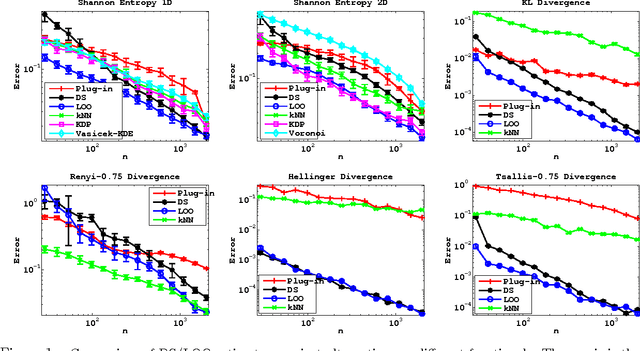
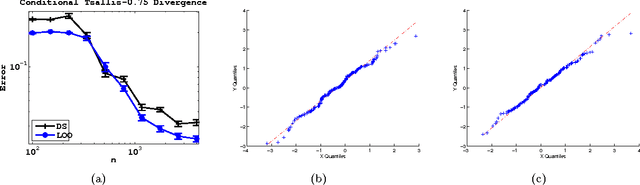

We propose and analyze estimators for statistical functionals of one or more distributions under nonparametric assumptions. Our estimators are based on the theory of influence functions, which appear in the semiparametric statistics literature. We show that estimators based either on data-splitting or a leave-one-out technique enjoy fast rates of convergence and other favorable theoretical properties. We apply this framework to derive estimators for several popular information theoretic quantities, and via empirical evaluation, show the advantage of this approach over existing estimators.
An Analysis of Active Learning With Uniform Feature Noise
May 15, 2015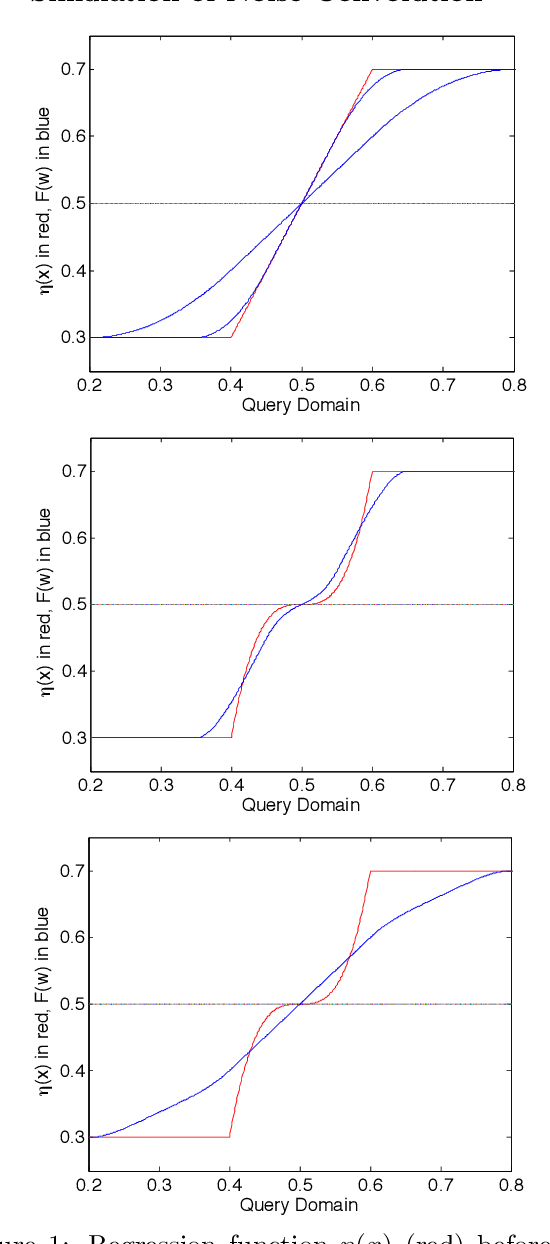
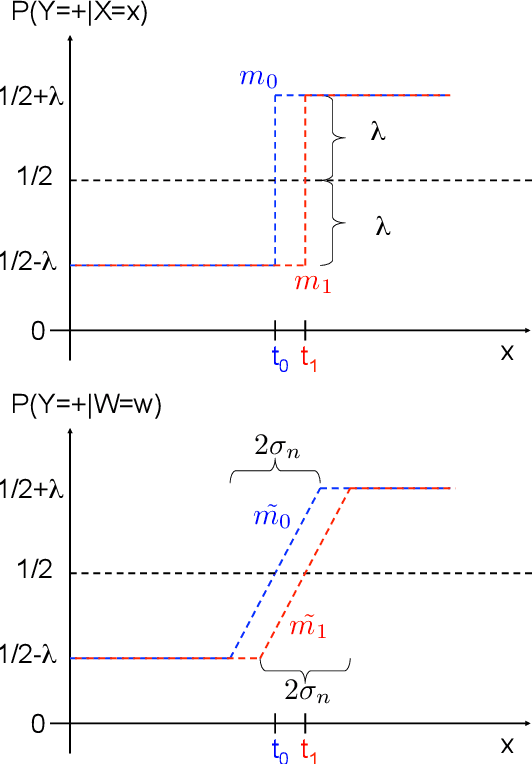
In active learning, the user sequentially chooses values for feature $X$ and an oracle returns the corresponding label $Y$. In this paper, we consider the effect of feature noise in active learning, which could arise either because $X$ itself is being measured, or it is corrupted in transmission to the oracle, or the oracle returns the label of a noisy version of the query point. In statistics, feature noise is known as "errors in variables" and has been studied extensively in non-active settings. However, the effect of feature noise in active learning has not been studied before. We consider the well-known Berkson errors-in-variables model with additive uniform noise of width $\sigma$. Our simple but revealing setting is that of one-dimensional binary classification setting where the goal is to learn a threshold (point where the probability of a $+$ label crosses half). We deal with regression functions that are antisymmetric in a region of size $\sigma$ around the threshold and also satisfy Tsybakov's margin condition around the threshold. We prove minimax lower and upper bounds which demonstrate that when $\sigma$ is smaller than the minimiax active/passive noiseless error derived in \cite{CN07}, then noise has no effect on the rates and one achieves the same noiseless rates. For larger $\sigma$, the \textit{unflattening} of the regression function on convolution with uniform noise, along with its local antisymmetry around the threshold, together yield a behaviour where noise \textit{appears} to be beneficial. Our key result is that active learning can buy significant improvement over a passive strategy even in the presence of feature noise.
Two-stage Sampled Learning Theory on Distributions
Jan 26, 2015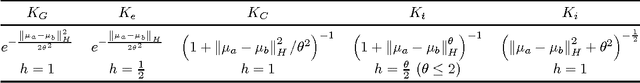


We focus on the distribution regression problem: regressing to a real-valued response from a probability distribution. Although there exist a large number of similarity measures between distributions, very little is known about their generalization performance in specific learning tasks. Learning problems formulated on distributions have an inherent two-stage sampled difficulty: in practice only samples from sampled distributions are observable, and one has to build an estimate on similarities computed between sets of points. To the best of our knowledge, the only existing method with consistency guarantees for distribution regression requires kernel density estimation as an intermediate step (which suffers from slow convergence issues in high dimensions), and the domain of the distributions to be compact Euclidean. In this paper, we provide theoretical guarantees for a remarkably simple algorithmic alternative to solve the distribution regression problem: embed the distributions to a reproducing kernel Hilbert space, and learn a ridge regressor from the embeddings to the outputs. Our main contribution is to prove the consistency of this technique in the two-stage sampled setting under mild conditions (on separable, topological domains endowed with kernels). For a given total number of observations, we derive convergence rates as an explicit function of the problem difficulty. As a special case, we answer a 15-year-old open question: we establish the consistency of the classical set kernel [Haussler, 1999; Gartner et. al, 2002] in regression, and cover more recent kernels on distributions, including those due to [Christmann and Steinwart, 2010].
On the High-dimensional Power of Linear-time Kernel Two-Sample Testing under Mean-difference Alternatives
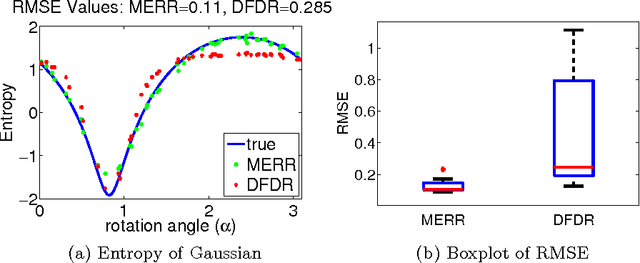
Nov 23, 2014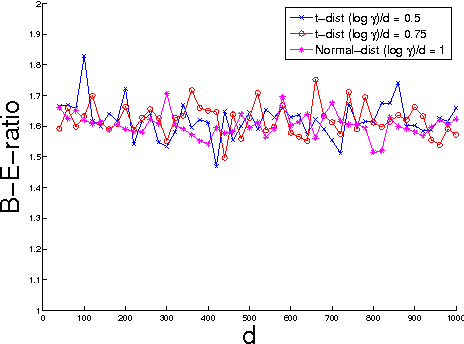
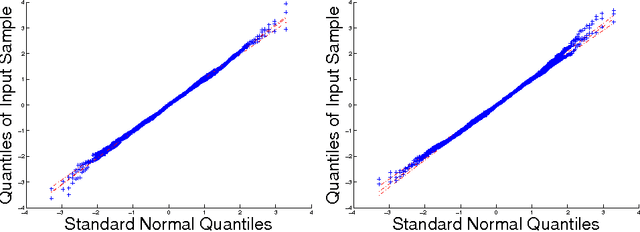
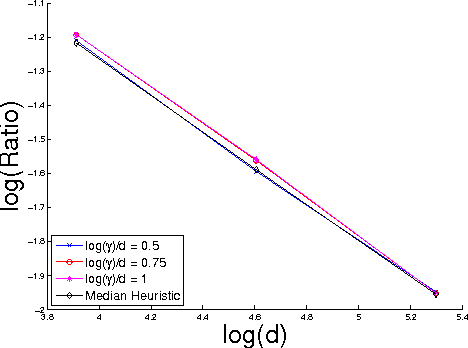
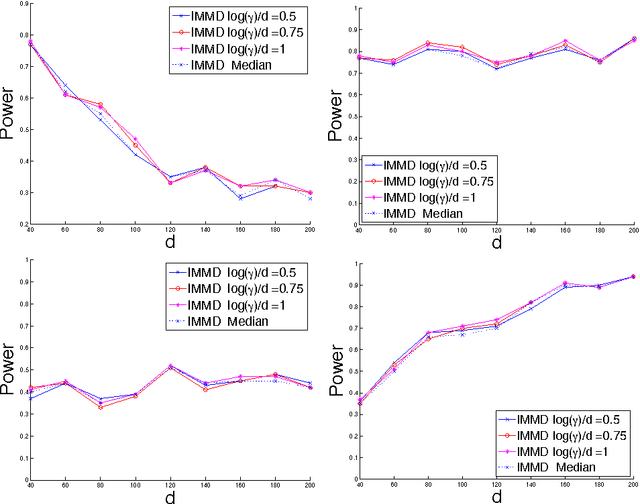
Nonparametric two sample testing deals with the question of consistently deciding if two distributions are different, given samples from both, without making any parametric assumptions about the form of the distributions. The current literature is split into two kinds of tests - those which are consistent without any assumptions about how the distributions may differ (\textit{general} alternatives), and those which are designed to specifically test easier alternatives, like a difference in means (\textit{mean-shift} alternatives). The main contribution of this paper is to explicitly characterize the power of a popular nonparametric two sample test, designed for general alternatives, under a mean-shift alternative in the high-dimensional setting. Specifically, we explicitly derive the power of the linear-time Maximum Mean Discrepancy statistic using the Gaussian kernel, where the dimension and sample size can both tend to infinity at any rate, and the two distributions differ in their means. As a corollary, we find that if the signal-to-noise ratio is held constant, then the test's power goes to one if the number of samples increases faster than the dimension increases. This is the first explicit power derivation for a general nonparametric test in the high-dimensional setting, and also the first analysis of how tests designed for general alternatives perform when faced with easier ones.
On Estimating $L_2^2$ Divergence
Oct 30, 2014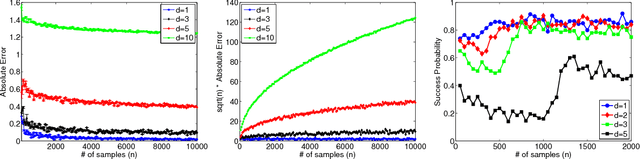
We give a comprehensive theoretical characterization of a nonparametric estimator for the $L_2^2$ divergence between two continuous distributions. We first bound the rate of convergence of our estimator, showing that it is $\sqrt{n}$-consistent provided the densities are sufficiently smooth. In this smooth regime, we then show that our estimator is asymptotically normal, construct asymptotic confidence intervals, and establish a Berry-Ess\'{e}en style inequality characterizing the rate of convergence to normality. We also show that this estimator is minimax optimal.
Fast Function to Function Regression
Oct 27, 2014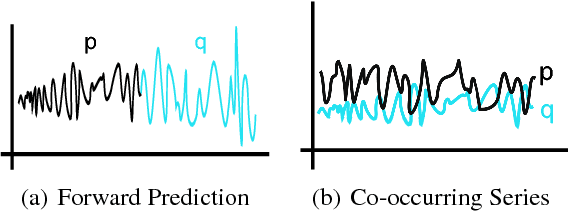
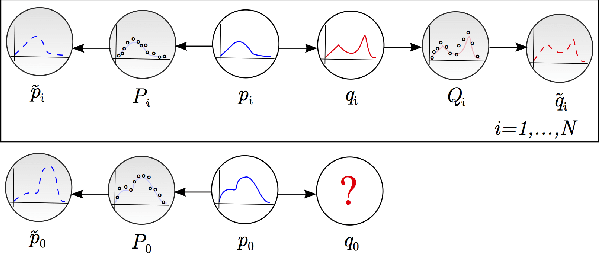
We analyze the problem of regression when both input covariates and output responses are functions from a nonparametric function class. Function to function regression (FFR) covers a large range of interesting applications including time-series prediction problems, and also more general tasks like studying a mapping between two separate types of distributions. However, previous nonparametric estimators for FFR type problems scale badly computationally with the number of input/output pairs in a data-set. Given the complexity of a mapping between general functions it may be necessary to consider large data-sets in order to achieve a low estimation risk. To address this issue, we develop a novel scalable nonparametric estimator, the Triple-Basis Estimator (3BE), which is capable of operating over datasets with many instances. To the best of our knowledge, the 3BE is the first nonparametric FFR estimator that can scale to massive datasets. We analyze the 3BE's risk and derive an upperbound rate. Furthermore, we show an improvement of several orders of magnitude in terms of prediction speed and a reduction in error over previous estimators in various real-world data-sets.
Nonparametric Estimation of Renyi Divergence and Friends
May 12, 2014
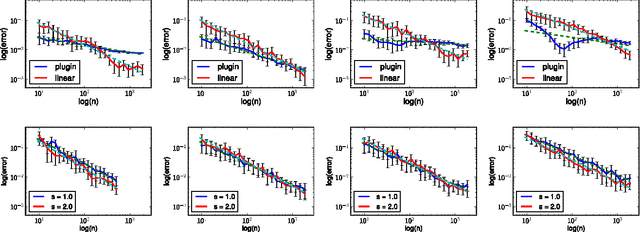
We consider nonparametric estimation of $L_2$, Renyi-$\alpha$ and Tsallis-$\alpha$ divergences between continuous distributions. Our approach is to construct estimators for particular integral functionals of two densities and translate them into divergence estimators. For the integral functionals, our estimators are based on corrections of a preliminary plug-in estimator. We show that these estimators achieve the parametric convergence rate of $n^{-1/2}$ when the densities' smoothness, $s$, are both at least $d/4$ where $d$ is the dimension. We also derive minimax lower bounds for this problem which confirm that $s > d/4$ is necessary to achieve the $n^{-1/2}$ rate of convergence. We validate our theoretical guarantees with a number of simulations.
Fast Distribution To Real Regression
Mar 09, 2014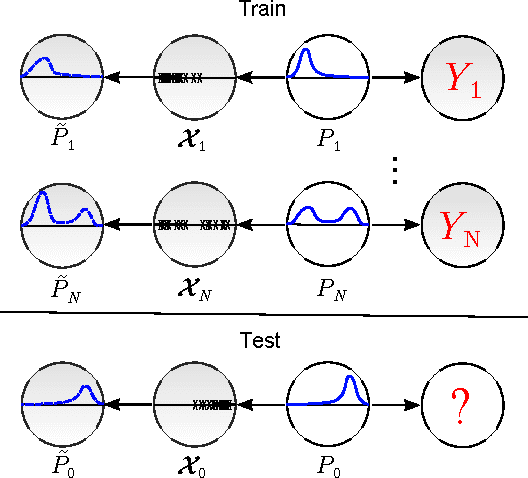
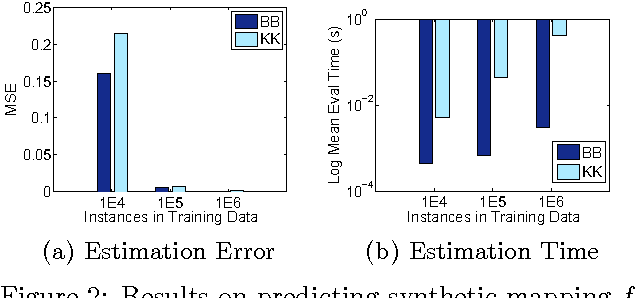
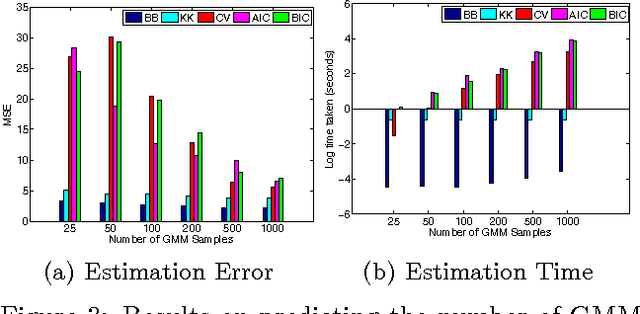
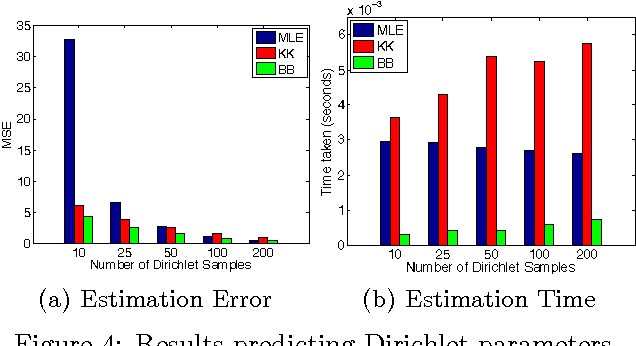
We study the problem of distribution to real-value regression, where one aims to regress a mapping $f$ that takes in a distribution input covariate $P\in \mathcal{I}$ (for a non-parametric family of distributions $\mathcal{I}$) and outputs a real-valued response $Y=f(P) + \epsilon$. This setting was recently studied, and a "Kernel-Kernel" estimator was introduced and shown to have a polynomial rate of convergence. However, evaluating a new prediction with the Kernel-Kernel estimator scales as $\Omega(N)$. This causes the difficult situation where a large amount of data may be necessary for a low estimation risk, but the computation cost of estimation becomes infeasible when the data-set is too large. To this end, we propose the Double-Basis estimator, which looks to alleviate this big data problem in two ways: first, the Double-Basis estimator is shown to have a computation complexity that is independent of the number of of instances $N$ when evaluating new predictions after training; secondly, the Double-Basis estimator is shown to have a fast rate of convergence for a general class of mappings $f\in\mathcal{F}$.
FuSSO: Functional Shrinkage and Selection Operator
Mar 09, 2014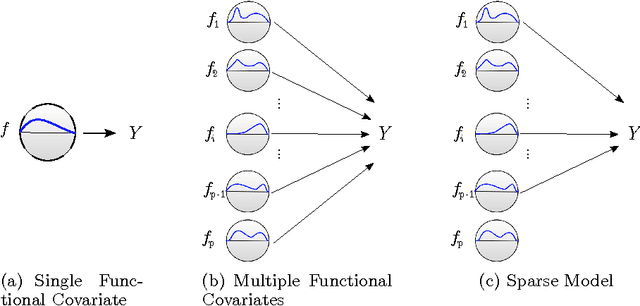
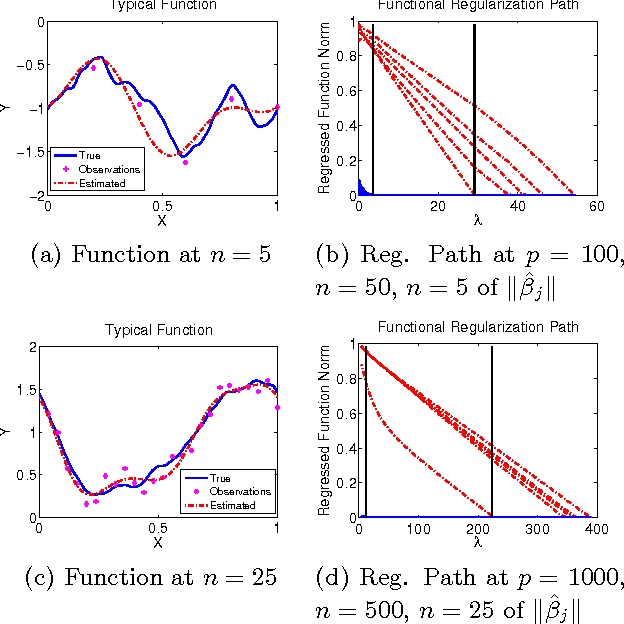
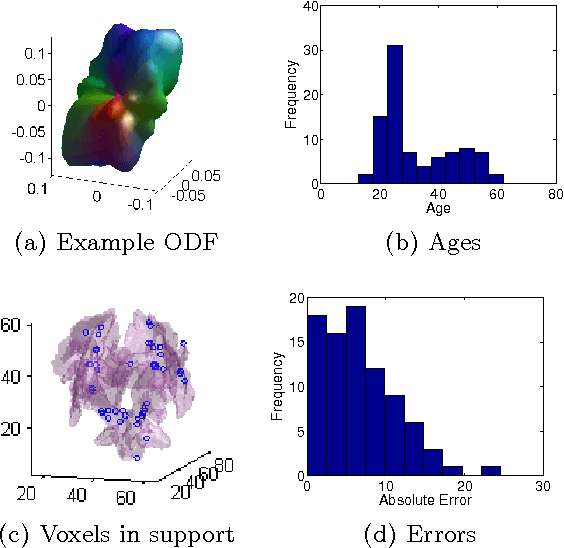
We present the FuSSO, a functional analogue to the LASSO, that efficiently finds a sparse set of functional input covariates to regress a real-valued response against. The FuSSO does so in a semi-parametric fashion, making no parametric assumptions about the nature of input functional covariates and assuming a linear form to the mapping of functional covariates to the response. We provide a statistical backing for use of the FuSSO via proof of asymptotic sparsistency under various conditions. Furthermore, we observe good results on both synthetic and real-world data.