 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoVaxNet: An Online-Offline Data Repository for COVID-19 Vaccine Hesitancy Research
Jun 30, 2022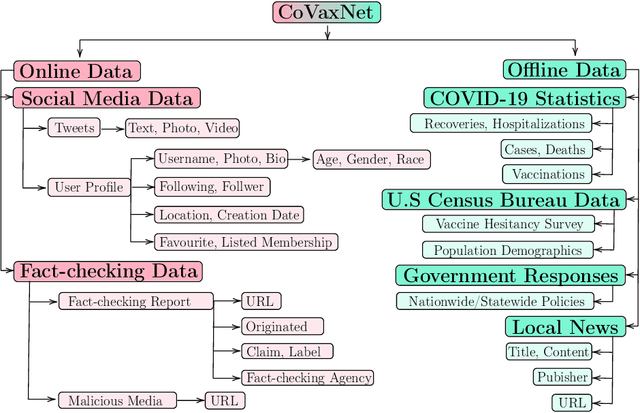

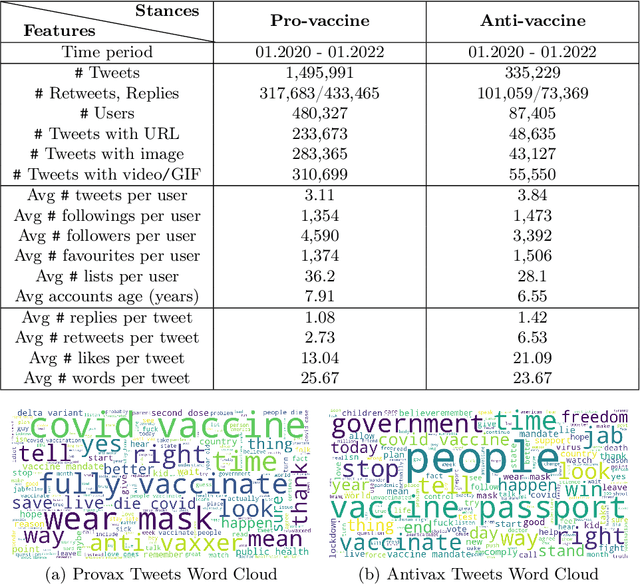
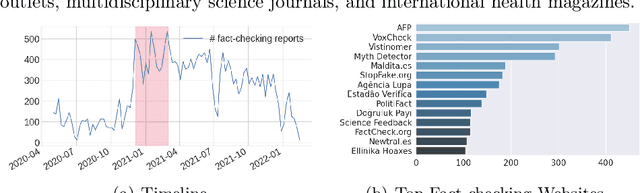
Despite the astonishing success of COVID-19 vaccines against the virus, a substantial proportion of the population is still hesitant to be vaccinated, undermining governmental efforts to control the virus. To address this problem, we need to understand the different factors giving rise to such a behavior, including social media discourses, news media propaganda, government responses, demographic and socioeconomic statuses, and COVID-19 statistics, etc. However, existing datasets fail to cover all these aspects, making it difficult to form a complete picture in inferencing about the problem of vaccine hesitancy. In this paper, we construct a multi-source, multi-modal, and multi-feature online-offline data repository CoVaxNet. We provide descriptive analyses and insights to illustrate critical patterns in CoVaxNet. Moreover, we propose a novel approach for connecting online and offline data so as to facilitate the inference tasks that exploit complementary information sources.
Optical Flow for Video Super-Resolution: A Survey
Mar 20, 2022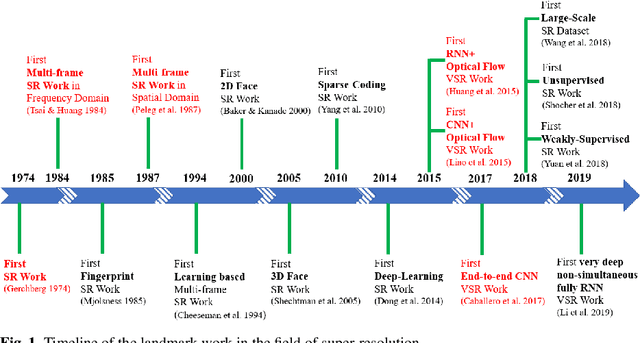
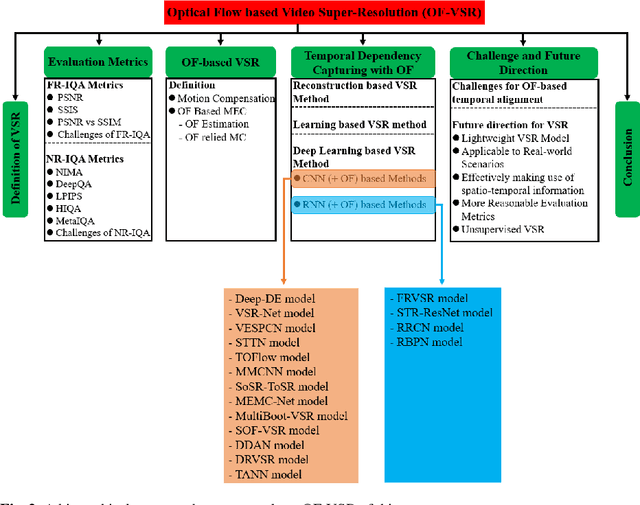

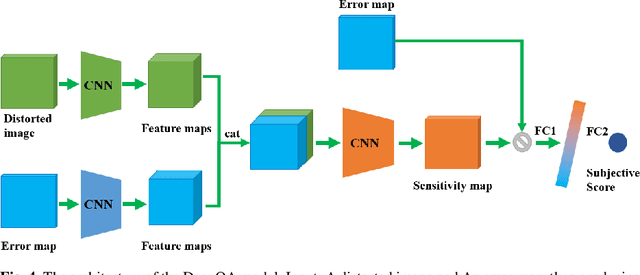
Video super-resolution is currently one of the most active research topics in computer vision as it plays an important role in many visual applications. Generally, video super-resolution contains a significant component, i.e., motion compensation, which is used to estimate the displacement between successive video frames for temporal alignment. Optical flow, which can supply dense and sub-pixel motion between consecutive frames, is among the most common ways for this task. To obtain a good understanding of the effect that optical flow acts in video super-resolution, in this work, we conduct a comprehensive review on this subject for the first time. This investigation covers the following major topics: the function of super-resolution (i.e., why we require super-resolution); the concept of video super-resolution (i.e., what is video super-resolution); the description of evaluation metrics (i.e., how (video) superresolution performs); the introduction of optical flow based video super-resolution; the investigation of using optical flow to capture temporal dependency for video super-resolution. Prominently, we give an in-depth study of the deep learning based video super-resolution method, where some representative algorithms are analyzed and compared. Additionally, we highlight some promising research directions and open issues that should be further addressed.
Slow-Fast Visual Tempo Learning for Video-based Action Recognition
Feb 24, 2022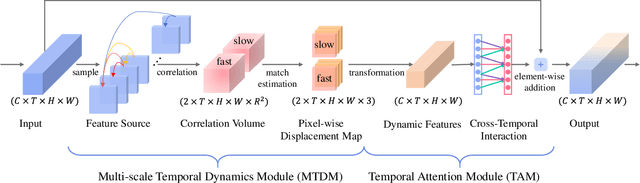
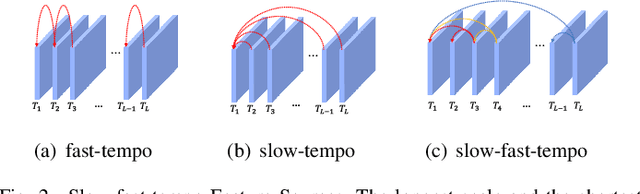
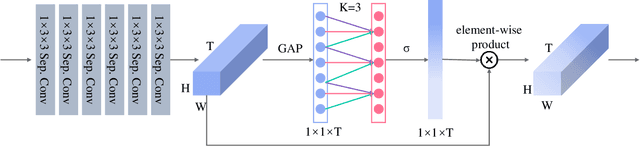
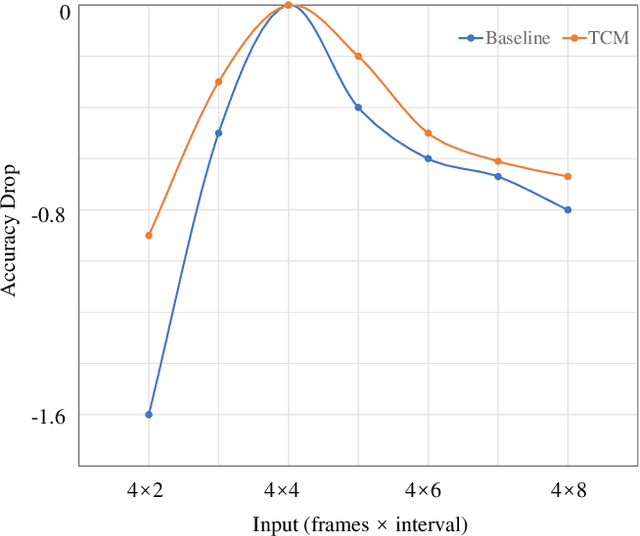
Action visual tempo characterizes the dynamics and the temporal scale of an action, which is helpful to distinguish human actions that share high similarities in visual dynamics and appearance. Previous methods capture the visual tempo either by sampling raw videos with multiple rates, which requires a costly multi-layer network to handle each rate, or by hierarchically sampling backbone features, which relies heavily on high-level features that miss fine-grained temporal dynamics. In this work, we propose a Temporal Correlation Module (TCM), which can be easily embedded into the current action recognition backbones in a plug-in-and-play manner, to extract action visual tempo from low-level backbone features at single-layer remarkably. Specifically, our TCM contains two main components: a Multi-scale Temporal Dynamics Module (MTDM) and a Temporal Attention Module (TAM). MTDM applies a correlation operation to learn pixel-wise fine-grained temporal dynamics for both fast-tempo and slow-tempo. TAM adaptively emphasizes expressive features and suppresses inessential ones via analyzing the global information across various tempos. Extensive experiments conducted on several action recognition benchmarks, e.g. Something-Something V1 & V2, Kinetics-400, UCF-101, and HMDB-51, have demonstrated that the proposed TCM is effective to promote the performance of the existing video-based action recognition models for a large margin. The source code is publicly released at https://github.com/zphyix/TCM.
PAT: Pseudo-Adversarial Training For Detecting Adversarial Videos
Sep 13, 2021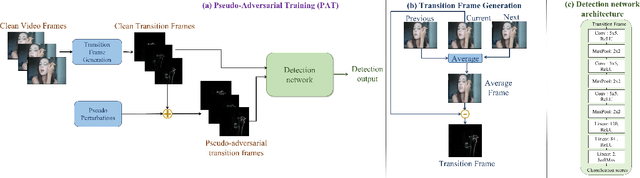
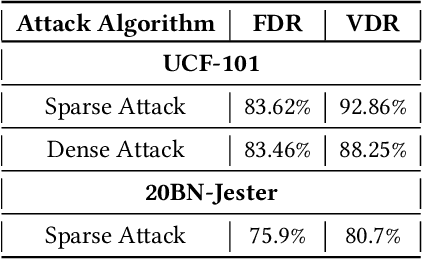

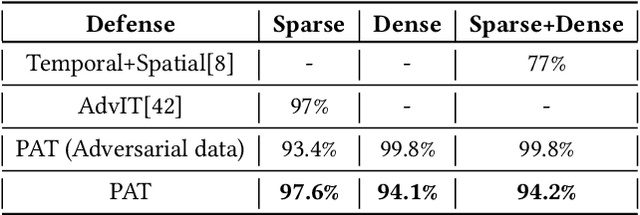
Extensive research has demonstrated that deep neural networks (DNNs) are prone to adversarial attacks. Although various defense mechanisms have been proposed for image classification networks, fewer approaches exist for video-based models that are used in security-sensitive applications like surveillance. In this paper, we propose a novel yet simple algorithm called Pseudo-Adversarial Training (PAT), to detect the adversarial frames in a video without requiring knowledge of the attack. Our approach generates `transition frames' that capture critical deviation from the original frames and eliminate the components insignificant to the detection task. To avoid the necessity of knowing the attack model, we produce `pseudo perturbations' to train our detection network. Adversarial detection is then achieved through the use of the detected frames. Experimental results on UCF-101 and 20BN-Jester datasets show that PAT can detect the adversarial video frames and videos with a high detection rate. We also unveil the potential reasons for the effectiveness of the transition frames and pseudo perturbations through extensive experiments.
FedNS: Improving Federated Learning for collaborative image classification on mobile clients
Jan 20, 2021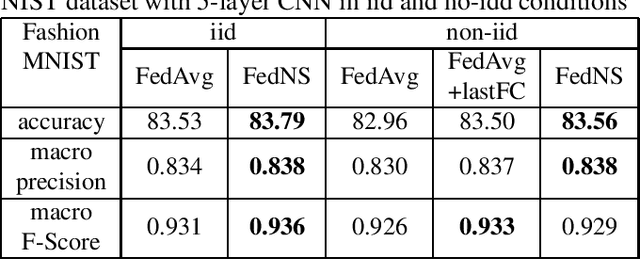
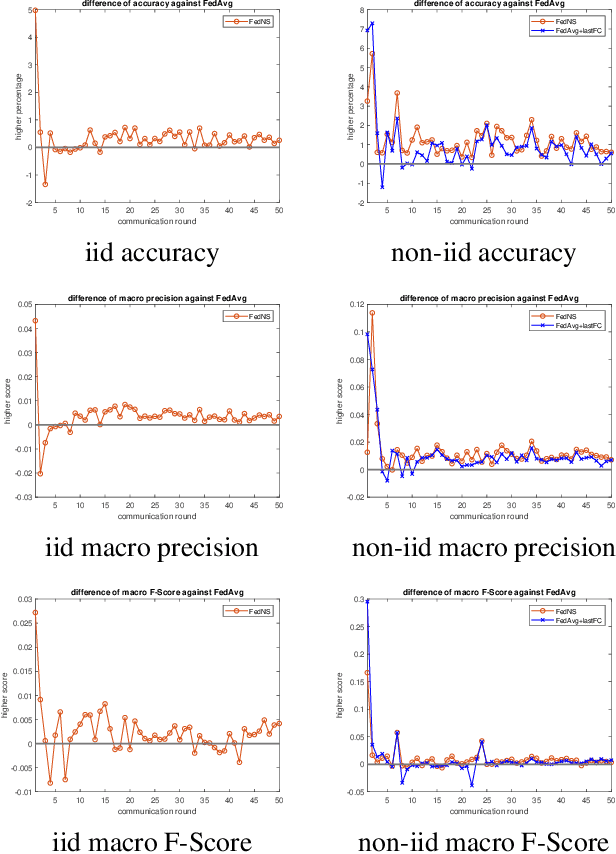
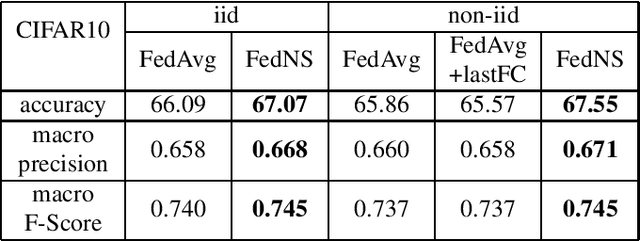
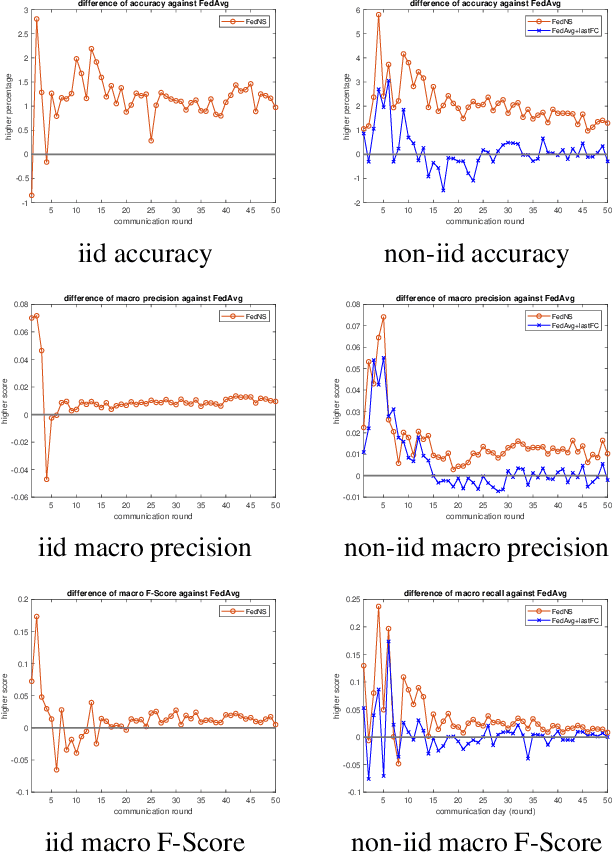
Federated Learning (FL) is a paradigm that aims to support loosely connected clients in learning a global model collaboratively with the help of a centralized server. The most popular FL algorithm is Federated Averaging (FedAvg), which is based on taking weighted average of the client models, with the weights determined largely based on dataset sizes at the clients. In this paper, we propose a new approach, termed Federated Node Selection (FedNS), for the server's global model aggregation in the FL setting. FedNS filters and re-weights the clients' models at the node/kernel level, hence leading to a potentially better global model by fusing the best components of the clients. Using collaborative image classification as an example, we show with experiments from multiple datasets and networks that FedNS can consistently achieve improved performance over FedAvg.
Partial Domain Adaptation Using Selective Representation Learning For Class-Weight Computation
Jan 06, 2021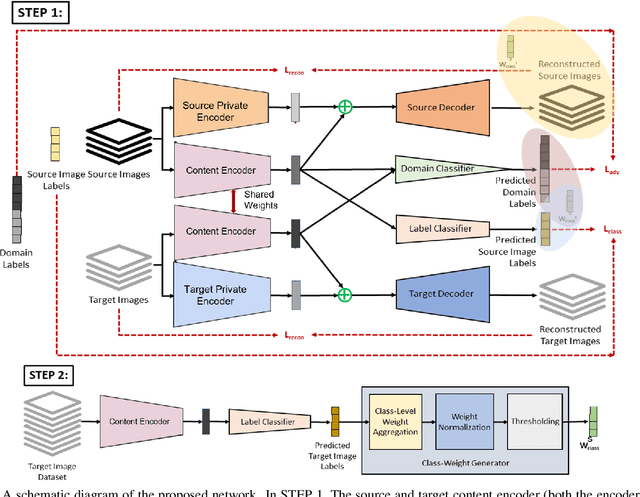
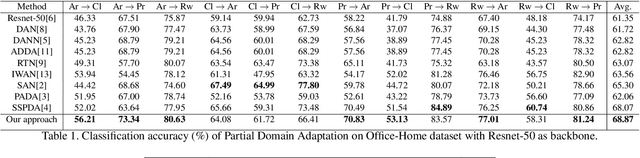
The generalization power of deep-learning models is dependent on rich-labelled data. This supervision using large-scaled annotated information is restrictive in most real-world scenarios where data collection and their annotation involve huge cost. Various domain adaptation techniques exist in literature that bridge this distribution discrepancy. However, a majority of these models require the label sets of both the domains to be identical. To tackle a more practical and challenging scenario, we formulate the problem statement from a partial domain adaptation perspective, where the source label set is a super set of the target label set. Driven by the motivation that image styles are private to each domain, in this work, we develop a method that identifies outlier classes exclusively from image content information and train a label classifier exclusively on class-content from source images. Additionally, elimination of negative transfer of samples from classes private to the source domain is achieved by transforming the soft class-level weights into two clusters, 0 (outlier source classes) and 1 (shared classes) by maximizing the between-cluster variance between them.
AdvFoolGen: Creating Persistent Troubles for Deep Classifiers
Jul 20, 2020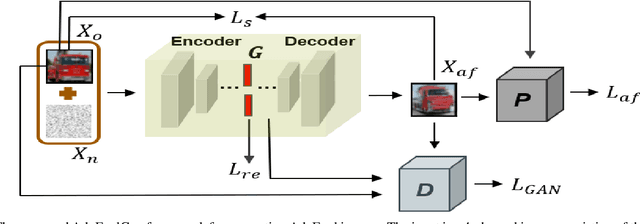
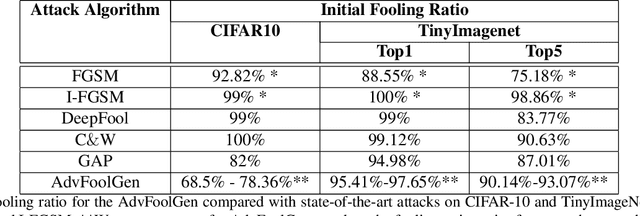

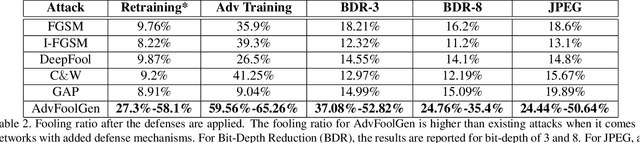
Researches have shown that deep neural networks are vulnerable to malicious attacks, where adversarial images are created to trick a network into misclassification even if the images may give rise to totally different labels by human eyes. To make deep networks more robust to such attacks, many defense mechanisms have been proposed in the literature, some of which are quite effective for guarding against typical attacks. In this paper, we present a new black-box attack termed AdvFoolGen, which can generate attacking images from the same feature space as that of the natural images, so as to keep baffling the network even though state-of-the-art defense mechanisms have been applied. We systematically evaluate our model by comparing with well-established attack algorithms. Through experiments, we demonstrate the effectiveness and robustness of our attack in the face of state-of-the-art defense techniques and unveil the potential reasons for its effectiveness through principled analysis. As such, AdvFoolGen contributes to understanding the vulnerability of deep networks from a new perspective and may, in turn, help in developing and evaluating new defense mechanisms.
Evaluating a Simple Retraining Strategy as a Defense Against Adversarial Attacks
Jul 20, 2020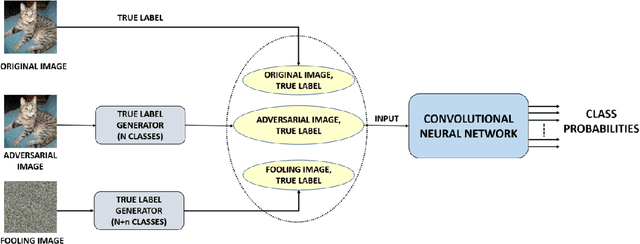
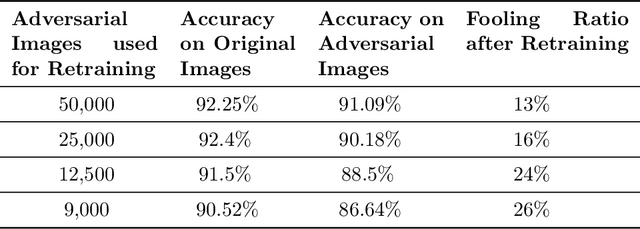
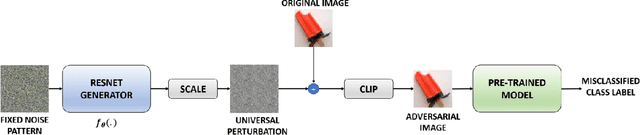

Though deep neural networks (DNNs) have shown superiority over other techniques in major fields like computer vision, natural language processing, robotics, recently, it has been proven that they are vulnerable to adversarial attacks. The addition of a simple, small and almost invisible perturbation to the original input image can be used to fool DNNs into making wrong decisions. With more attack algorithms being designed, a need for defending the neural networks from such attacks arises. Retraining the network with adversarial images is one of the simplest techniques. In this paper, we evaluate the effectiveness of such a retraining strategy in defending against adversarial attacks. We also show how simple algorithms like KNN can be used to determine the labels of the adversarial images needed for retraining. We present the results on two standard datasets namely, CIFAR-10 and TinyImageNet.
Hardware Acceleration of Sparse and Irregular Tensor Computations of ML Models: A Survey and Insights
Jul 02, 2020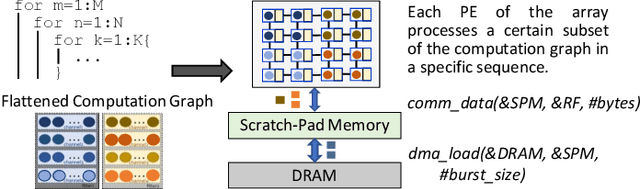


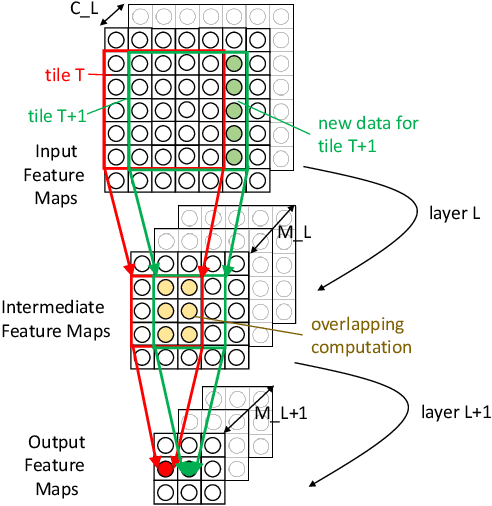
Machine learning (ML) models are widely used in many domains including media processing and generation, computer vision, medical diagnosis, embedded systems, high-performance and scientific computing, and recommendation systems. For efficiently processing these computational- and memory-intensive applications, tensors of these over-parameterized models are compressed by leveraging sparsity, size reduction, and quantization of tensors. Unstructured sparsity and tensors with varying dimensions yield irregular-shaped computation, communication, and memory access patterns; processing them on hardware accelerators in a conventional manner does not inherently leverage acceleration opportunities. This paper provides a comprehensive survey on how to efficiently execute sparse and irregular tensor computations of ML models on hardware accelerators. In particular, it discusses additional enhancement modules in architecture design and software support; categorizes different hardware designs and acceleration techniques and analyzes them in terms of hardware and execution costs; highlights further opportunities in terms of hardware/software/algorithm co-design optimizations and joint optimizations among described hardware and software enhancement modules. The takeaways from this paper include: understanding the key challenges in accelerating sparse, irregular-shaped, and quantized tensors; understanding enhancements in acceleration systems for supporting their efficient computations; analyzing trade-offs in opting for a specific type of design enhancement; understanding how to map and compile models with sparse tensors on the accelerators; understanding recent design trends for efficient accelerations and further opportunities.
Variational Wasserstein Barycenters for Geometric Clustering
Feb 24, 2020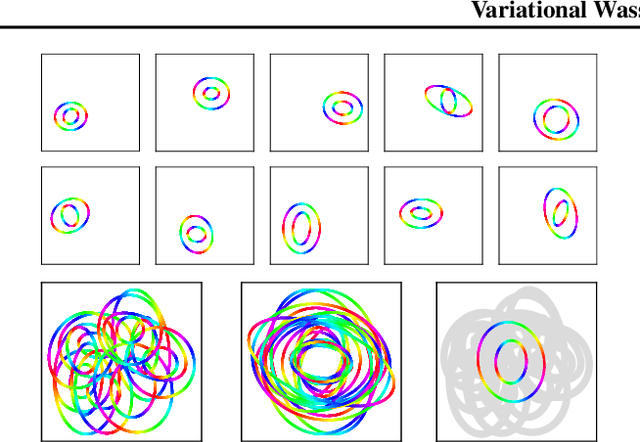
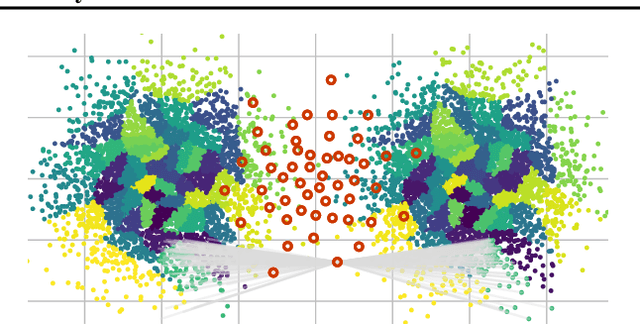
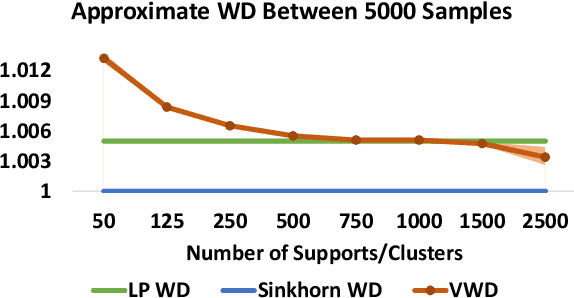
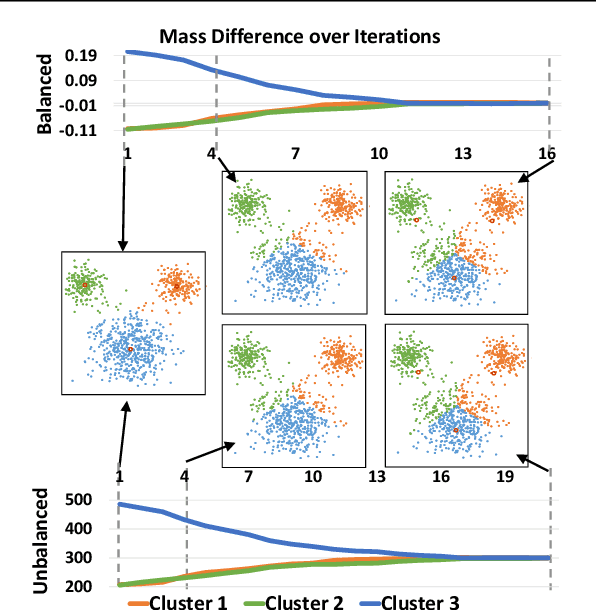
We propose to compute Wasserstein barycenters (WBs) by solving for Monge maps with variational principle. We discuss the metric properties of WBs and explore their connections, especially the connections of Monge WBs, to K-means clustering and co-clustering. We also discuss the feasibility of Monge WBs on unbalanced measures and spherical domains. We propose two new problems -- regularized K-means and Wasserstein barycenter compression. We demonstrate the use of VWBs in solving these clustering-related problems.