 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicyClusterGCN: Identifying Efficient Clusters for Training Graph Convolutional Networks
Jun 25, 2023



Graph convolutional networks (GCNs) have achieved huge success in several machine learning (ML) tasks on graph-structured data. Recently, several sampling techniques have been proposed for the efficient training of GCNs and to improve the performance of GCNs on ML tasks. Specifically, the subgraph-based sampling approaches such as ClusterGCN and GraphSAINT have achieved state-of-the-art performance on the node classification tasks. These subgraph-based sampling approaches rely on heuristics -- such as graph partitioning via edge cuts -- to identify clusters that are then treated as minibatches during GCN training. In this work, we hypothesize that rather than relying on such heuristics, one can learn a reinforcement learning (RL) policy to compute efficient clusters that lead to effective GCN performance. To that end, we propose PolicyClusterGCN, an online RL framework that can identify good clusters for GCN training. We develop a novel Markov Decision Process (MDP) formulation that allows the policy network to predict ``importance" weights on the edges which are then utilized by a clustering algorithm (Graclus) to compute the clusters. We train the policy network using a standard policy gradient algorithm where the rewards are computed from the classification accuracies while training GCN using clusters given by the policy. Experiments on six real-world datasets and several synthetic datasets show that PolicyClusterGCN outperforms existing state-of-the-art models on node classification task.
GAN-MPC: Training Model Predictive Controllers with Parameterized Cost Functions using Demonstrations from Non-identical Experts
Jun 07, 2023



Model predictive control (MPC) is a popular approach for trajectory optimization in practical robotics applications. MPC policies can optimize trajectory parameters under kinodynamic and safety constraints and provide guarantees on safety, optimality, generalizability, interpretability, and explainability. However, some behaviors are complex and it is difficult to hand-craft an MPC objective function. A special class of MPC policies called Learnable-MPC addresses this difficulty using imitation learning from expert demonstrations. However, they require the demonstrator and the imitator agents to be identical which is hard to satisfy in many real world applications of robotics. In this paper, we address the practical problem of training Learnable-MPC policies when the demonstrator and the imitator do not share the same dynamics and their state spaces may have a partial overlap. We propose a novel approach that uses a generative adversarial network (GAN) to minimize the Jensen-Shannon divergence between the state-trajectory distributions of the demonstrator and the imitator. We evaluate our approach on a variety of simulated robotics tasks of DeepMind Control suite and demonstrate the efficacy of our approach at learning the demonstrator's behavior without having to copy their actions.
Clustering Indices based Automatic Classification Model Selection
May 23, 2023



Classification model selection is a process of identifying a suitable model class for a given classification task on a dataset. Traditionally, model selection is based on cross-validation, meta-learning, and user preferences, which are often time-consuming and resource-intensive. The performance of any machine learning classification task depends on the choice of the model class, the learning algorithm, and the dataset's characteristics. Our work proposes a novel method for automatic classification model selection from a set of candidate model classes by determining the empirical model-fitness for a dataset based only on its clustering indices. Clustering Indices measure the ability of a clustering algorithm to induce good quality neighborhoods with similar data characteristics. We propose a regression task for a given model class, where the clustering indices of a given dataset form the features and the dependent variable represents the expected classification performance. We compute the dataset clustering indices and directly predict the expected classification performance using the learned regressor for each candidate model class to recommend a suitable model class for dataset classification. We evaluate our model selection method through cross-validation with 60 publicly available binary class datasets and show that our top3 model recommendation is accurate for over 45 of 60 datasets. We also propose an end-to-end Automated ML system for data classification based on our model selection method. We evaluate our end-to-end system against popular commercial and noncommercial Automated ML systems using a different collection of 25 public domain binary class datasets. We show that the proposed system outperforms other methods with an excellent average rank of 1.68.
Bi-level Latent Variable Model for Sample-Efficient Multi-Agent Reinforcement Learning
Apr 12, 2023



Despite their potential in real-world applications, multi-agent reinforcement learning (MARL) algorithms often suffer from high sample complexity. To address this issue, we present a novel model-based MARL algorithm, BiLL (Bi-Level Latent Variable Model-based Learning), that learns a bi-level latent variable model from high-dimensional inputs. At the top level, the model learns latent representations of the global state, which encode global information relevant to behavior learning. At the bottom level, it learns latent representations for each agent, given the global latent representations from the top level. The model generates latent trajectories to use for policy learning. We evaluate our algorithm on complex multi-agent tasks in the challenging SMAC and Flatland environments. Our algorithm outperforms state-of-the-art model-free and model-based baselines in sample efficiency, including on two extremely challenging Super Hard SMAC maps.
Are Models Trained on Indian Legal Data Fair?
Mar 14, 2023



Recent advances and applications of language technology and artificial intelligence have enabled much success across multiple domains like law, medical and mental health. AI-based Language Models, like Judgement Prediction, have recently been proposed for the legal sector. However, these models are strife with encoded social biases picked up from the training data. While bias and fairness have been studied across NLP, most studies primarily locate themselves within a Western context. In this work, we present an initial investigation of fairness from the Indian perspective in the legal domain. We highlight the propagation of learnt algorithmic biases in the bail prediction task for models trained on Hindi legal documents. We evaluate the fairness gap using demographic parity and show that a decision tree model trained for the bail prediction task has an overall fairness disparity of 0.237 between input features associated with Hindus and Muslims. Additionally, we highlight the need for further research and studies in the avenues of fairness/bias in applying AI in the legal sector with a specific focus on the Indian context.
Physics-Informed Model-Based Reinforcement Learning
Dec 12, 2022We apply reinforcement learning (RL) to robotics. One of the drawbacks of traditional RL algorithms has been their poor sample efficiency. One approach to improve the sample efficiency is model-based RL. In our model-based RL algorithm, we learn a model of the environment, use it to generate imaginary trajectories and backpropagate through them to update the policy, exploiting the differentiability of the model. Intuitively, learning more accurate models should lead to better performance. Recently, there has been growing interest in developing better deep neural network based dynamics models for physical systems, through better inductive biases. We focus on robotic systems undergoing rigid body motion. We compare two versions of our model-based RL algorithm, one which uses a standard deep neural network based dynamics model and the other which uses a much more accurate, physics-informed neural network based dynamics model. We show that, in model-based RL, model accuracy mainly matters in environments that are sensitive to initial conditions. In these environments, the physics-informed version of our algorithm achieves significantly better average-return and sample efficiency. In environments that are not sensitive to initial conditions, both versions of our algorithm achieve similar average-return, while the physics-informed version achieves better sample efficiency. We measure the sensitivity to initial conditions using the finite-time maximal Lyapunov exponent. We also show that, in challenging environments, where we need a lot of samples to learn, physics-informed model-based RL can achieve better average-return than state-of-the-art model-free RL algorithms such as Soft Actor-Critic, by generating accurate imaginary data.
ReGrAt: Regularization in Graphs using Attention to handle class imbalance
Nov 27, 2022



Node classification is an important task to solve in graph-based learning. Even though a lot of work has been done in this field, imbalance is neglected. Real-world data is not perfect, and is imbalanced in representations most of the times. Apart from text and images, data can be represented using graphs, and thus addressing the imbalance in graphs has become of paramount importance. In the context of node classification, one class has less examples than others. Changing data composition is a popular way to address the imbalance in node classification. This is done by resampling the data to balance the dataset. However, that can sometimes lead to loss of information or add noise to the dataset. Therefore, in this work, we implicitly solve the problem by changing the model loss. Specifically, we study how attention networks can help tackle imbalance. Moreover, we observe that using a regularizer to assign larger weights to minority nodes helps to mitigate this imbalance. We achieve State of the Art results than the existing methods on several standard citation benchmark datasets.
GrabQC: Graph based Query Contextualization for automated ICD coding
Jul 14, 2022Automated medical coding is a process of codifying clinical notes to appropriate diagnosis and procedure codes automatically from the standard taxonomies such as ICD (International Classification of Diseases) and CPT (Current Procedure Terminology). The manual coding process involves the identification of entities from the clinical notes followed by querying a commercial or non-commercial medical codes Information Retrieval (IR) system that follows the Centre for Medicare and Medicaid Services (CMS) guidelines. We propose to automate this manual process by automatically constructing a query for the IR system using the entities auto-extracted from the clinical notes. We propose \textbf{GrabQC}, a \textbf{Gra}ph \textbf{b}ased \textbf{Q}uery \textbf{C}ontextualization method that automatically extracts queries from the clinical text, contextualizes the queries using a Graph Neural Network (GNN) model and obtains the ICD Codes using an external IR system. We also propose a method for labelling the dataset for training the model. We perform experiments on two datasets of clinical text in three different setups to assert the effectiveness of our approach. The experimental results show that our proposed method is better than the compared baselines in all three settings.
Multi-Variate Time Series Forecasting on Variable Subsets
Jun 25, 2022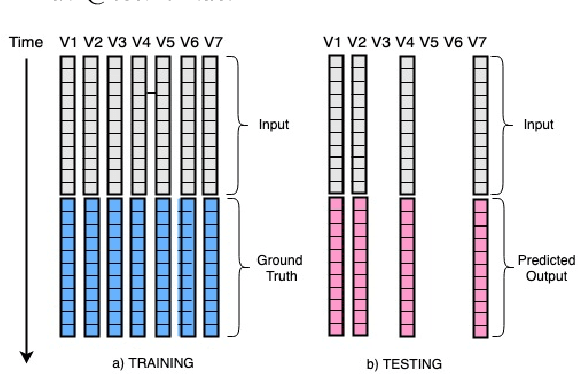
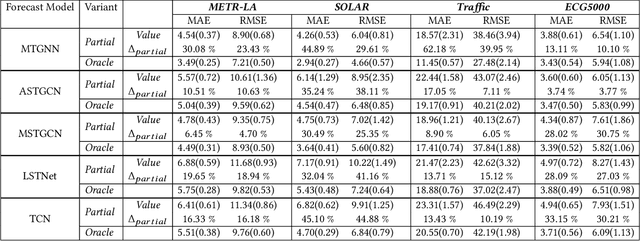
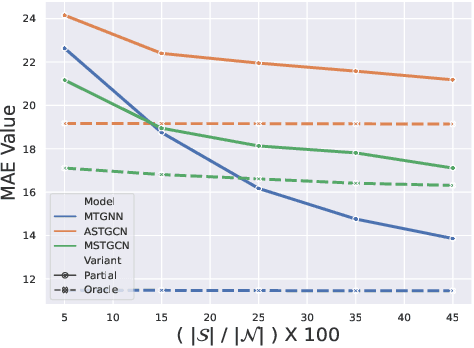

We formulate a new inference task in the domain of multivariate time series forecasting (MTSF), called Variable Subset Forecast (VSF), where only a small subset of the variables is available during inference. Variables are absent during inference because of long-term data loss (eg. sensor failures) or high -> low-resource domain shift between train / test. To the best of our knowledge, robustness of MTSF models in presence of such failures, has not been studied in the literature. Through extensive evaluation, we first show that the performance of state of the art methods degrade significantly in the VSF setting. We propose a non-parametric, wrapper technique that can be applied on top any existing forecast models. Through systematic experiments across 4 datasets and 5 forecast models, we show that our technique is able to recover close to 95\% performance of the models even when only 15\% of the original variables are present.
Matching options to tasks using Option-Indexed Hierarchical Reinforcement Learning
Jun 12, 2022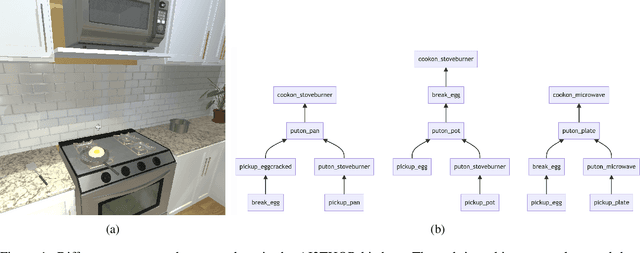
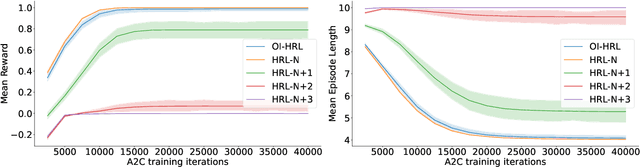
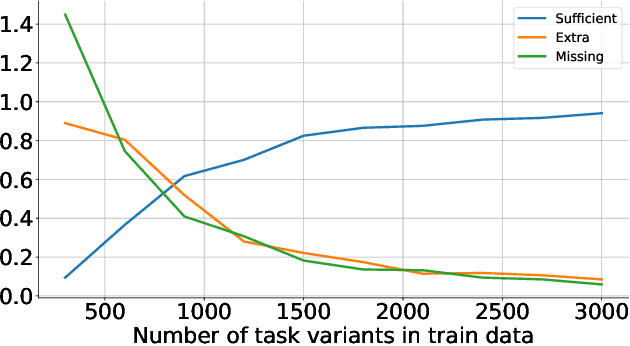
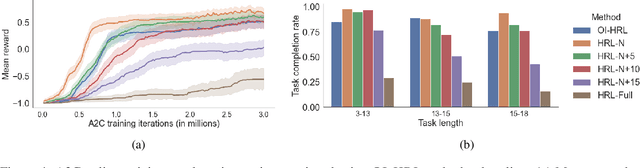
The options framework in Hierarchical Reinforcement Learning breaks down overall goals into a combination of options or simpler tasks and associated policies, allowing for abstraction in the action space. Ideally, these options can be reused across different higher-level goals; indeed, such reuse is necessary to realize the vision of a continual learning agent that can effectively leverage its prior experience. Previous approaches have only proposed limited forms of transfer of prelearned options to new task settings. We propose a novel option indexing approach to hierarchical learning (OI-HRL), where we learn an affinity function between options and the items present in the environment. This allows us to effectively reuse a large library of pretrained options, in zero-shot generalization at test time, by restricting goal-directed learning to only those options relevant to the task at hand. We develop a meta-training loop that learns the representations of options and environments over a series of HRL problems, by incorporating feedback about the relevance of retrieved options to the higher-level goal. We evaluate OI-HRL in two simulated settings - the CraftWorld and AI2THOR environments - and show that we achieve performance competitive with oracular baselines, and substantial gains over a baseline that has the entire option pool available for learning the hierarchical policy.