 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Memorization of Large Language Models in Logical Reasoning
Oct 30, 2024



Large language models (LLMs) achieve good performance on challenging reasoning benchmarks, yet could also make basic reasoning mistakes. This contrasting behavior is puzzling when it comes to understanding the mechanisms behind LLMs' reasoning capabilities. One hypothesis is that the increasingly high and nearly saturated performance on common reasoning benchmarks could be due to the memorization of similar problems. In this paper, we systematically investigate this hypothesis with a quantitative measurement of memorization in reasoning tasks, using a dynamically generated logical reasoning benchmark based on Knights and Knaves (K&K) puzzles. We found that LLMs could interpolate the training puzzles (achieving near-perfect accuracy) after fine-tuning, yet fail when those puzzles are slightly perturbed, suggesting that the models heavily rely on memorization to solve those training puzzles. On the other hand, we show that while fine-tuning leads to heavy memorization, it also consistently improves generalization performance. In-depth analyses with perturbation tests, cross difficulty-level transferability, probing model internals, and fine-tuning with wrong answers suggest that the LLMs learn to reason on K&K puzzles despite training data memorization. This phenomenon indicates that LLMs exhibit a complex interplay between memorization and genuine reasoning abilities. Finally, our analysis with per-sample memorization score sheds light on how LLMs switch between reasoning and memorization in solving logical puzzles. Our code and data are available at https://memkklogic.github.io.
Differential Privacy on Trust Graphs
Oct 15, 2024We study differential privacy (DP) in a multi-party setting where each party only trusts a (known) subset of the other parties with its data. Specifically, given a trust graph where vertices correspond to parties and neighbors are mutually trusting, we give a DP algorithm for aggregation with a much better privacy-utility trade-off than in the well-studied local model of DP (where each party trusts no other party). We further study a robust variant where each party trusts all but an unknown subset of at most $t$ of its neighbors (where $t$ is a given parameter), and give an algorithm for this setting. We complement our algorithms with lower bounds, and discuss implications of our work to other tasks in private learning and analytics.
On Convex Optimization with Semi-Sensitive Features
Jun 27, 2024We study the differentially private (DP) empirical risk minimization (ERM) problem under the semi-sensitive DP setting where only some features are sensitive. This generalizes the Label DP setting where only the label is sensitive. We give improved upper and lower bounds on the excess risk for DP-ERM. In particular, we show that the error only scales polylogarithmically in terms of the sensitive domain size, improving upon previous results that scale polynomially in the sensitive domain size (Ghazi et al., 2021).
Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Jun 23, 2024



Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
Mind the Privacy Unit! User-Level Differential Privacy for Language Model Fine-Tuning
Jun 20, 2024



Large language models (LLMs) have emerged as powerful tools for tackling complex tasks across diverse domains, but they also raise privacy concerns when fine-tuned on sensitive data due to potential memorization. While differential privacy (DP) offers a promising solution by ensuring models are `almost indistinguishable' with or without any particular privacy unit, current evaluations on LLMs mostly treat each example (text record) as the privacy unit. This leads to uneven user privacy guarantees when contributions per user vary. We therefore study user-level DP motivated by applications where it necessary to ensure uniform privacy protection across users. We present a systematic evaluation of user-level DP for LLM fine-tuning on natural language generation tasks. Focusing on two mechanisms for achieving user-level DP guarantees, Group Privacy and User-wise DP-SGD, we investigate design choices like data selection strategies and parameter tuning for the best privacy-utility tradeoff.
Differentially Private Optimization with Sparse Gradients
Apr 16, 2024

Motivated by applications of large embedding models, we study differentially private (DP) optimization problems under sparsity of individual gradients. We start with new near-optimal bounds for the classic mean estimation problem but with sparse data, improving upon existing algorithms particularly for the high-dimensional regime. Building on this, we obtain pure- and approximate-DP algorithms with almost optimal rates for stochastic convex optimization with sparse gradients; the former represents the first nearly dimension-independent rates for this problem. Finally, we study the approximation of stationary points for the empirical loss in approximate-DP optimization and obtain rates that depend on sparsity instead of dimension, modulo polylogarithmic factors.
How Private is DP-SGD?
Mar 26, 2024



We demonstrate a substantial gap between the privacy guarantees of the Adaptive Batch Linear Queries (ABLQ) mechanism under different types of batch sampling: (i) Shuffling, and (ii) Poisson subsampling; the typical analysis of Differentially Private Stochastic Gradient Descent (DP-SGD) follows by interpreting it as a post-processing of ABLQ. While shuffling based DP-SGD is more commonly used in practical implementations, it is neither analytically nor numerically amenable to easy privacy analysis. On the other hand, Poisson subsampling based DP-SGD is challenging to scalably implement, but has a well-understood privacy analysis, with multiple open-source numerically tight privacy accountants available. This has led to a common practice of using shuffling based DP-SGD in practice, but using the privacy analysis for the corresponding Poisson subsampling version. Our result shows that there can be a substantial gap between the privacy analysis when using the two types of batch sampling, and thus advises caution in reporting privacy parameters for DP-SGD.
Training Differentially Private Ad Prediction Models with Semi-Sensitive Features
Jan 26, 2024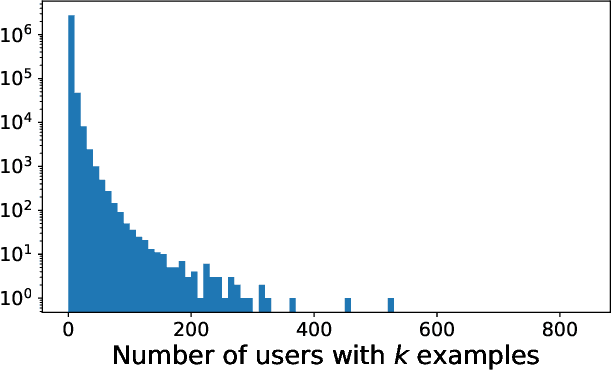
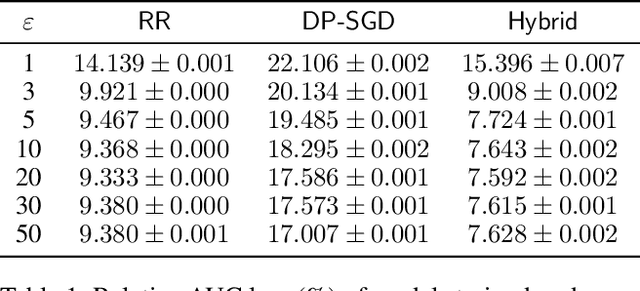
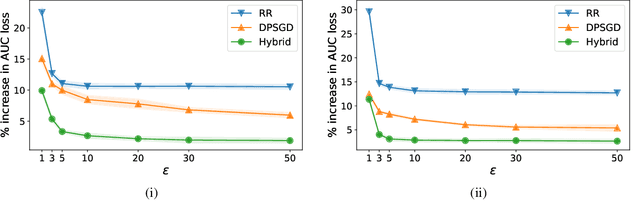
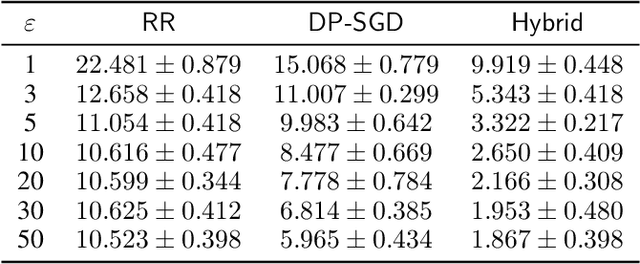
Motivated by problems arising in digital advertising, we introduce the task of training differentially private (DP) machine learning models with semi-sensitive features. In this setting, a subset of the features is known to the attacker (and thus need not be protected) while the remaining features as well as the label are unknown to the attacker and should be protected by the DP guarantee. This task interpolates between training the model with full DP (where the label and all features should be protected) or with label DP (where all the features are considered known, and only the label should be protected). We present a new algorithm for training DP models with semi-sensitive features. Through an empirical evaluation on real ads datasets, we demonstrate that our algorithm surpasses in utility the baselines of (i) DP stochastic gradient descent (DP-SGD) run on all features (known and unknown), and (ii) a label DP algorithm run only on the known features (while discarding the unknown ones).
Optimal Unbiased Randomizers for Regression with Label Differential Privacy
Dec 09, 2023



We propose a new family of label randomizers for training regression models under the constraint of label differential privacy (DP). In particular, we leverage the trade-offs between bias and variance to construct better label randomizers depending on a privately estimated prior distribution over the labels. We demonstrate that these randomizers achieve state-of-the-art privacy-utility trade-offs on several datasets, highlighting the importance of reducing bias when training neural networks with label DP. We also provide theoretical results shedding light on the structural properties of the optimal unbiased randomizers.
Sparsity-Preserving Differentially Private Training of Large Embedding Models
Nov 14, 2023



As the use of large embedding models in recommendation systems and language applications increases, concerns over user data privacy have also risen. DP-SGD, a training algorithm that combines differential privacy with stochastic gradient descent, has been the workhorse in protecting user privacy without compromising model accuracy by much. However, applying DP-SGD naively to embedding models can destroy gradient sparsity, leading to reduced training efficiency. To address this issue, we present two new algorithms, DP-FEST and DP-AdaFEST, that preserve gradient sparsity during private training of large embedding models. Our algorithms achieve substantial reductions ($10^6 \times$) in gradient size, while maintaining comparable levels of accuracy, on benchmark real-world datasets.