 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeprecating Benchmarks: Criteria and Framework
Jul 08, 2025
As frontier artificial intelligence (AI) models rapidly advance, benchmarks are integral to comparing different models and measuring their progress in different task-specific domains. However, there is a lack of guidance on when and how benchmarks should be deprecated once they cease to effectively perform their purpose. This risks benchmark scores over-valuing model capabilities, or worse, obscuring capabilities and safety-washing. Based on a review of benchmarking practices, we propose criteria to decide when to fully or partially deprecate benchmarks, and a framework for deprecating benchmarks. Our work aims to advance the state of benchmarking towards rigorous and quality evaluations, especially for frontier models, and our recommendations are aimed to benefit benchmark developers, benchmark users, AI governance actors (across governments, academia, and industry panels), and policy makers.
Risk Sources and Risk Management Measures in Support of Standards for General-Purpose AI Systems
Oct 30, 2024



There is an urgent need to identify both short and long-term risks from newly emerging types of Artificial Intelligence (AI), as well as available risk management measures. In response, and to support global efforts in regulating AI and writing safety standards, we compile an extensive catalog of risk sources and risk management measures for general-purpose AI (GPAI) systems, complete with descriptions and supporting examples where relevant. This work involves identifying technical, operational, and societal risks across model development, training, and deployment stages, as well as surveying established and experimental methods for managing these risks. To the best of our knowledge, this paper is the first of its kind to provide extensive documentation of both GPAI risk sources and risk management measures that are descriptive, self-contained and neutral with respect to any existing regulatory framework. This work intends to help AI providers, standards experts, researchers, policymakers, and regulators in identifying and mitigating systemic risks from GPAI systems. For this reason, the catalog is released under a public domain license for ease of direct use by stakeholders in AI governance and standards.
In2Core: Leveraging Influence Functions for Coreset Selection in Instruction Finetuning of Large Language Models
Aug 07, 2024Despite advancements, fine-tuning Large Language Models (LLMs) remains costly due to the extensive parameter count and substantial data requirements for model generalization. Accessibility to computing resources remains a barrier for the open-source community. To address this challenge, we propose the In2Core algorithm, which selects a coreset by analyzing the correlation between training and evaluation samples with a trained model. Notably, we assess the model's internal gradients to estimate this relationship, aiming to rank the contribution of each training point. To enhance efficiency, we propose an optimization to compute influence functions with a reduced number of layers while achieving similar accuracy. By applying our algorithm to instruction fine-tuning data of LLMs, we can achieve similar performance with just 50% of the training data. Meantime, using influence functions to analyze model coverage to certain testing samples could provide a reliable and interpretable signal on the training set's coverage of those test points.
Applying Multilingual Models to Question Answering (QA)
Dec 04, 2022



We study the performance of monolingual and multilingual language models on the task of question-answering (QA) on three diverse languages: English, Finnish and Japanese. We develop models for the tasks of (1) determining if a question is answerable given the context and (2) identifying the answer texts within the context using IOB tagging. Furthermore, we attempt to evaluate the effectiveness of a pre-trained multilingual encoder (Multilingual BERT) on cross-language zero-shot learning for both the answerability and IOB sequence classifiers.
Understanding How Model Size Affects Few-shot Instruction Prompting
Dec 04, 2022


Large Language Models are affected by the phenomena of memorizing and forgetting their training data. But how do these vary by model size? We work towards this question by investigating how the model size affects the model's ability to discriminate a word's meaning in a given context. We introduce a dataset called DeltaWords, which evaluates a model's ability to follow instructions to select a sentence which replaces the target word with its antonym. We show a weak inverse scaling trend, where task accuracy degrades as model size increase, under extremely few-shot prompting regimes. We show that increasing the number of examples tend to disproportionately benefit larger models than smaller models.
Truth Serum: Poisoning Machine Learning Models to Reveal Their Secrets
Mar 31, 2022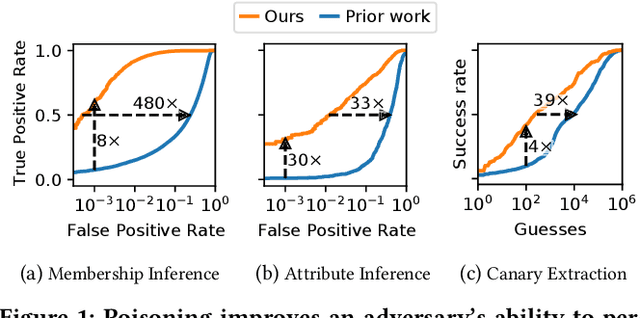
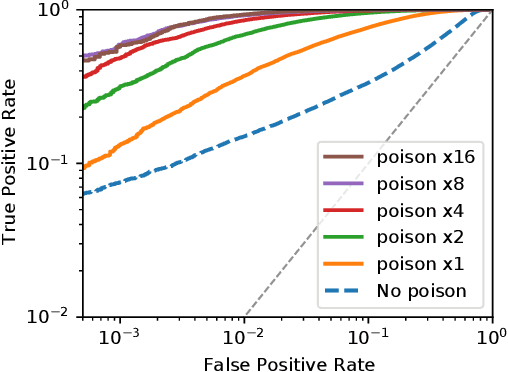
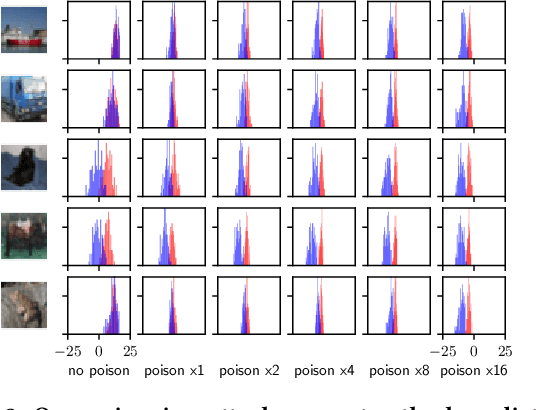
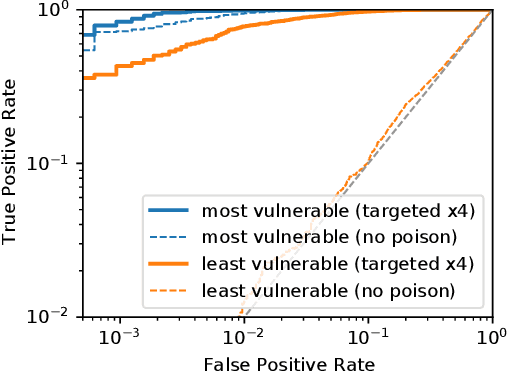
We introduce a new class of attacks on machine learning models. We show that an adversary who can poison a training dataset can cause models trained on this dataset to leak significant private details of training points belonging to other parties. Our active inference attacks connect two independent lines of work targeting the integrity and privacy of machine learning training data. Our attacks are effective across membership inference, attribute inference, and data extraction. For example, our targeted attacks can poison <0.1% of the training dataset to boost the performance of inference attacks by 1 to 2 orders of magnitude. Further, an adversary who controls a significant fraction of the training data (e.g., 50%) can launch untargeted attacks that enable 8x more precise inference on all other users' otherwise-private data points. Our results cast doubts on the relevance of cryptographic privacy guarantees in multiparty computation protocols for machine learning, if parties can arbitrarily select their share of training data.