 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeMantic AnsweR Type prediction task at ISWC 2020 Semantic Web Challenge
Dec 01, 2020

Each year the International Semantic Web Conference accepts a set of Semantic Web Challenges to establish competitions that will advance the state of the art solutions in any given problem domain. The SeMantic AnsweR Type prediction task (SMART) was part of ISWC 2020 challenges. Question type and answer type prediction can play a key role in knowledge base question answering systems providing insights that are helpful to generate correct queries or rank the answer candidates. More concretely, given a question in natural language, the task of SMART challenge is, to predict the answer type using a target ontology (e.g., DBpedia or Wikidata).
NABU $\mathrm{-}$ Multilingual Graph-based Neural RDF Verbalizer
Sep 21, 2020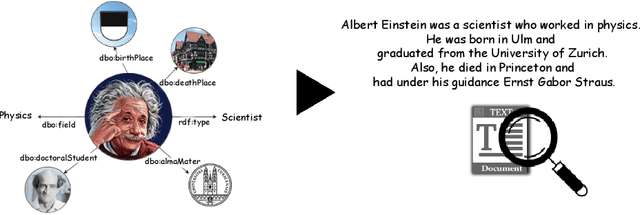
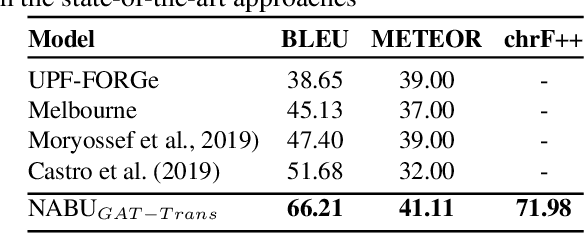
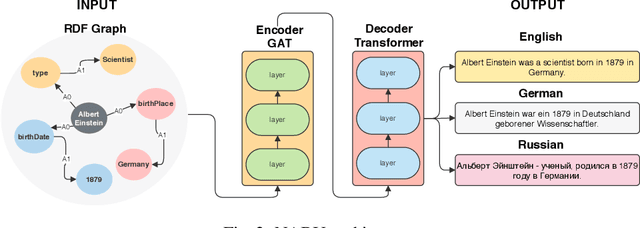
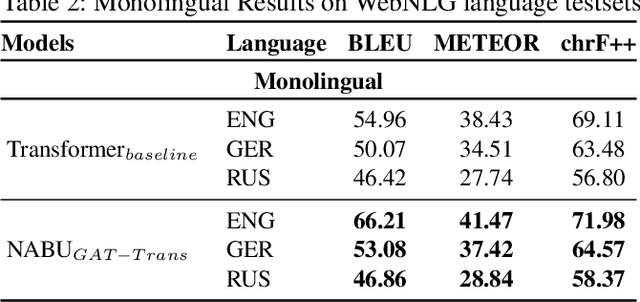
The RDF-to-text task has recently gained substantial attention due to continuous growth of Linked Data. In contrast to traditional pipeline models, recent studies have focused on neural models, which are now able to convert a set of RDF triples into text in an end-to-end style with promising results. However, English is the only language widely targeted. We address this research gap by presenting NABU, a multilingual graph-based neural model that verbalizes RDF data to German, Russian, and English. NABU is based on an encoder-decoder architecture, uses an encoder inspired by Graph Attention Networks and a Transformer as decoder. Our approach relies on the fact that knowledge graphs are language-agnostic and they hence can be used to generate multilingual text. We evaluate NABU in monolingual and multilingual settings on standard benchmarking WebNLG datasets. Our results show that NABU outperforms state-of-the-art approaches on English with 66.21 BLEU, and achieves consistent results across all languages on the multilingual scenario with 56.04 BLEU.
Revealing Secrets in SPARQL Session Level
Sep 13, 2020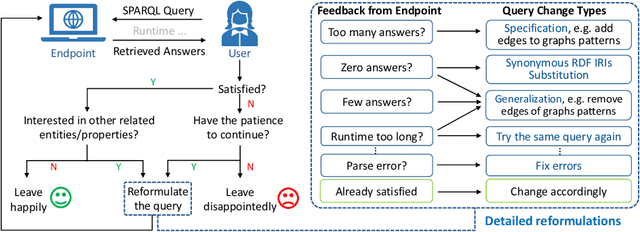
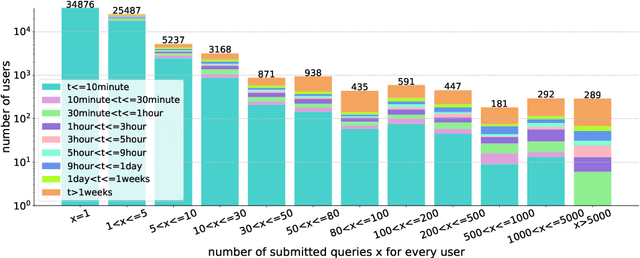
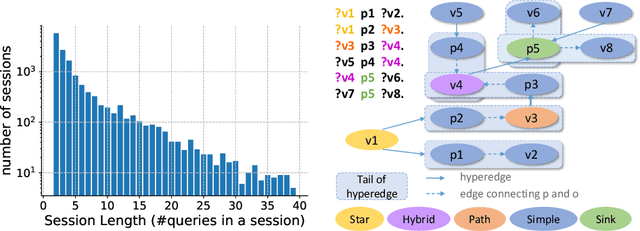
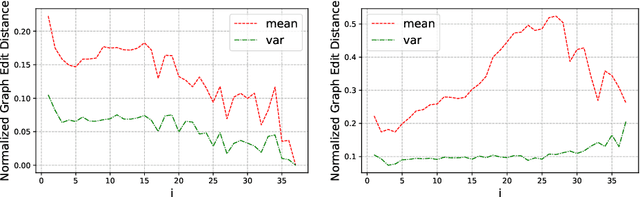
Based on Semantic Web technologies, knowledge graphs help users to discover information of interest by using live SPARQL services. Answer-seekers often examine intermediate results iteratively and modify SPARQL queries repeatedly in a search session. In this context, understanding user behaviors is critical for effective intention prediction and query optimization. However, these behaviors have not yet been researched systematically at the SPARQL session level. This paper reveals the secrets of session-level user search behaviors by conducting a comprehensive investigation over massive real-world SPARQL query logs. In particular, we thoroughly assess query changes made by users w.r.t. structural and data-driven features of SPARQL queries. To illustrate the potentiality of our findings, we employ a proof-of-concept model to predict user intentions, i.e., future directions of the given session, and give reformulation suggestions based on the predicted intention. We hope the results presented here will help to devise efficient SPARQL caching, auto-completion, query suggestion, approximation, and relaxation techniques in the future.
Convolutional Complex Knowledge Graph Embeddings
Aug 10, 2020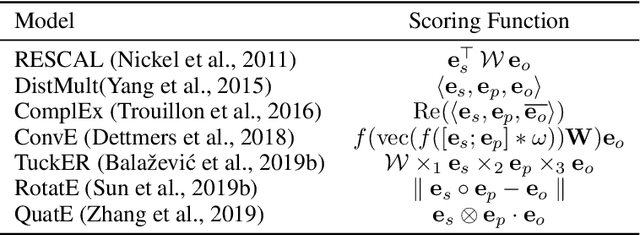
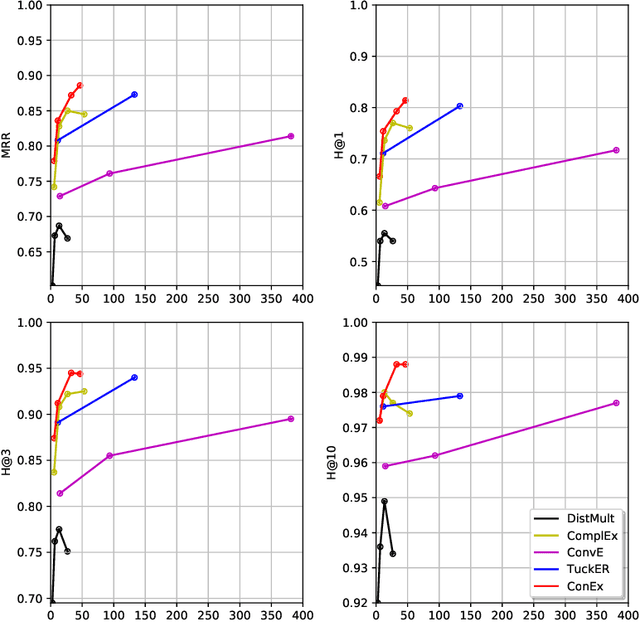

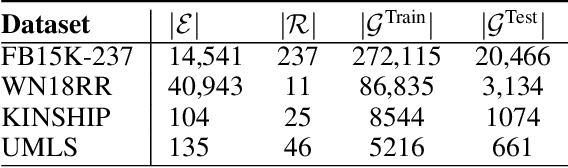
In this paper, we study the problem of learning continuous vector representations of knowledge graphs for predicting missing links. We present a new approach called ConEx, which infers missing links by leveraging the composition of a 2D convolution with a Hermitian inner product of complex-valued embedding vectors. We evaluate ConEx against state-of-the-art approaches on the WN18RR, FB15K-237, KINSHIP and UMLS benchmark datasets. Our experimental results show that ConEx achieves a performance superior to that of state-of-the-art approaches such as RotatE, QuatE and TuckER on the link prediction task on all datasets while requiring at least 8 times fewer parameters. We ensure the reproducibility of our results by providing an open-source implementation which includes the training, evaluation scripts along with pre-trained models at https://github.com/conex-kge/ConEx.
Knowledge Graphs
Mar 28, 2020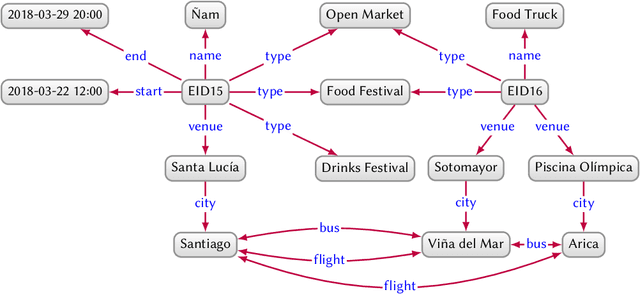
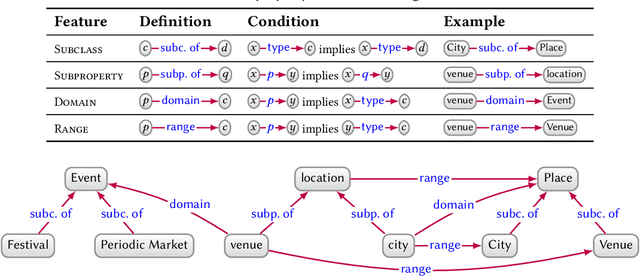
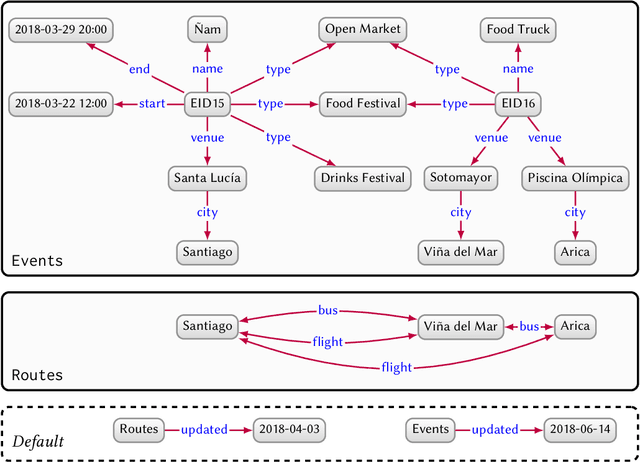
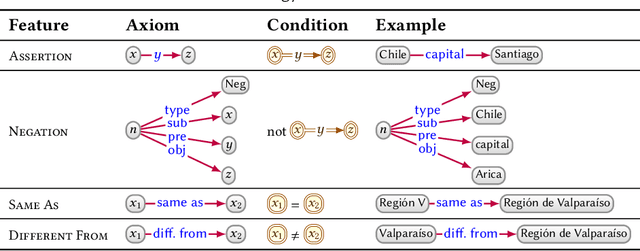
In this paper we provide a comprehensive introduction to knowledge graphs, which have recently garnered significant attention from both industry and academia in scenarios that require exploiting diverse, dynamic, large-scale collections of data. After a general introduction, we motivate and contrast various graph-based data models and query languages that are used for knowledge graphs. We discuss the roles of schema, identity, and context in knowledge graphs. We explain how knowledge can be represented and extracted using a combination of deductive and inductive techniques. We summarise methods for the creation, enrichment, quality assessment, refinement, and publication of knowledge graphs. We provide an overview of prominent open knowledge graphs and enterprise knowledge graphs, their applications, and how they use the aforementioned techniques. We conclude with high-level future research directions for knowledge graphs.
A Physical Embedding Model for Knowledge Graphs
Jan 21, 2020
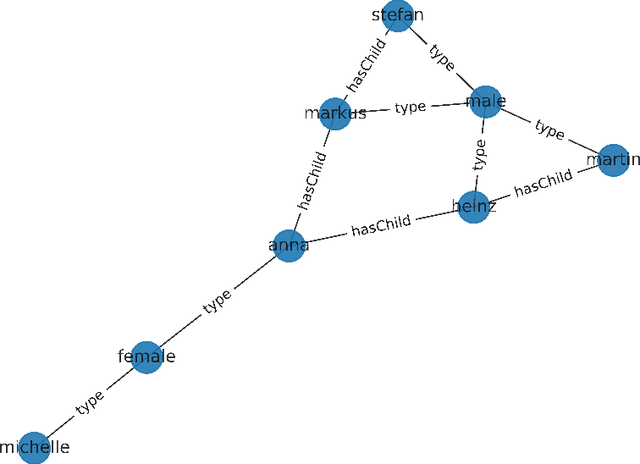
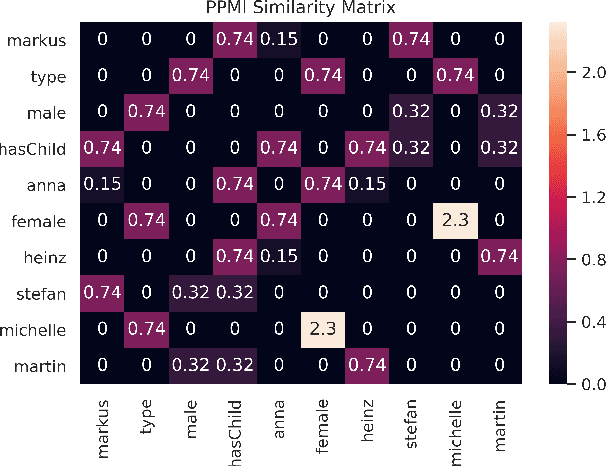
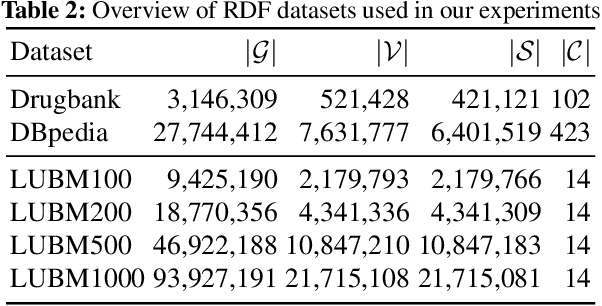
Knowledge graph embedding methods learn continuous vector representations for entities in knowledge graphs and have been used successfully in a large number of applications. We present a novel and scalable paradigm for the computation of knowledge graph embeddings, which we dub PYKE . Our approach combines a physical model based on Hooke's law and its inverse with ideas from simulated annealing to compute embeddings for knowledge graphs efficiently. We prove that PYKE achieves a linear space complexity. While the time complexity for the initialization of our approach is quadratic, the time complexity of each of its iterations is linear in the size of the input knowledge graph. Hence, PYKE's overall runtime is close to linear. Consequently, our approach easily scales up to knowledge graphs containing millions of triples. We evaluate our approach against six state-of-the-art embedding approaches on the DrugBank and DBpedia datasets in two series of experiments. The first series shows that the cluster purity achieved by PYKE is up to 26% (absolute) better than that of the state of art. In addition, PYKE is more than 22 times faster than existing embedding solutions in the best case. The results of our second series of experiments show that PYKE is up to 23% (absolute) better than the state of art on the task of type prediction while maintaining its superior scalability. Our implementation and results are open-source and are available at http://github.com/dice-group/PYKE.
A Holistic Natural Language Generation Framework for the Semantic Web
Nov 04, 2019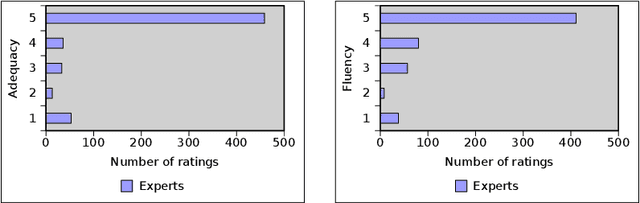
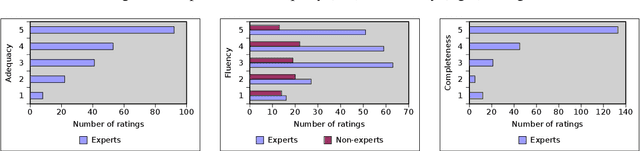
With the ever-growing generation of data for the Semantic Web comes an increasing demand for this data to be made available to non-semantic Web experts. One way of achieving this goal is to translate the languages of the Semantic Web into natural language. We present LD2NL, a framework for verbalizing the three key languages of the Semantic Web, i.e., RDF, OWL, and SPARQL. Our framework is based on a bottom-up approach to verbalization. We evaluated LD2NL in an open survey with 86 persons. Our results suggest that our framework can generate verbalizations that are close to natural languages and that can be easily understood by non-experts. Therewith, it enables non-domain experts to interpret Semantic Web data with more than 91\% of the accuracy of domain experts.
Semantic Web for Machine Translation: Challenges and Directions
Jul 23, 2019A large number of machine translation approaches have recently been developed to facilitate the fluid migration of content across languages. However, the literature suggests that many obstacles must still be dealt with to achieve better automatic translations. One of these obstacles is lexical and syntactic ambiguity. A promising way of overcoming this problem is using Semantic Web technologies. This article is an extended abstract of our systematic review on machine translation approaches that rely on Semantic Web technologies for improving the translation of texts. Overall, we present the challenges and opportunities in the use of Semantic Web technologies in Machine Translation. Moreover, our research suggests that while Semantic Web technologies can enhance the quality of machine translation outputs for various problems, the combination of both is still in its infancy.
Augmenting Neural Machine Translation with Knowledge Graphs
Feb 23, 2019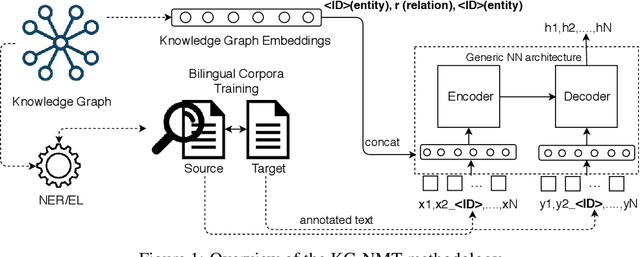
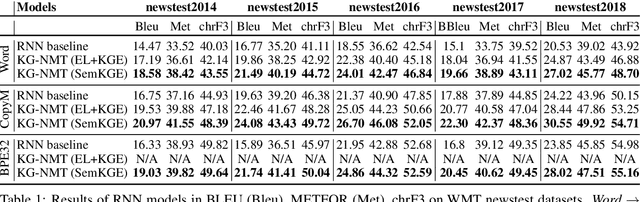
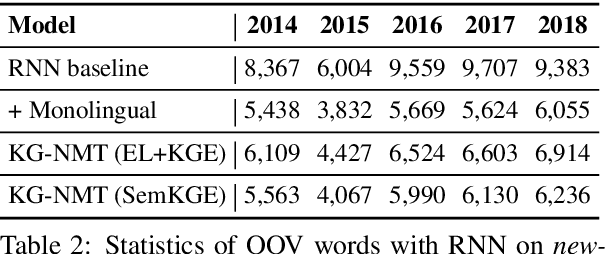
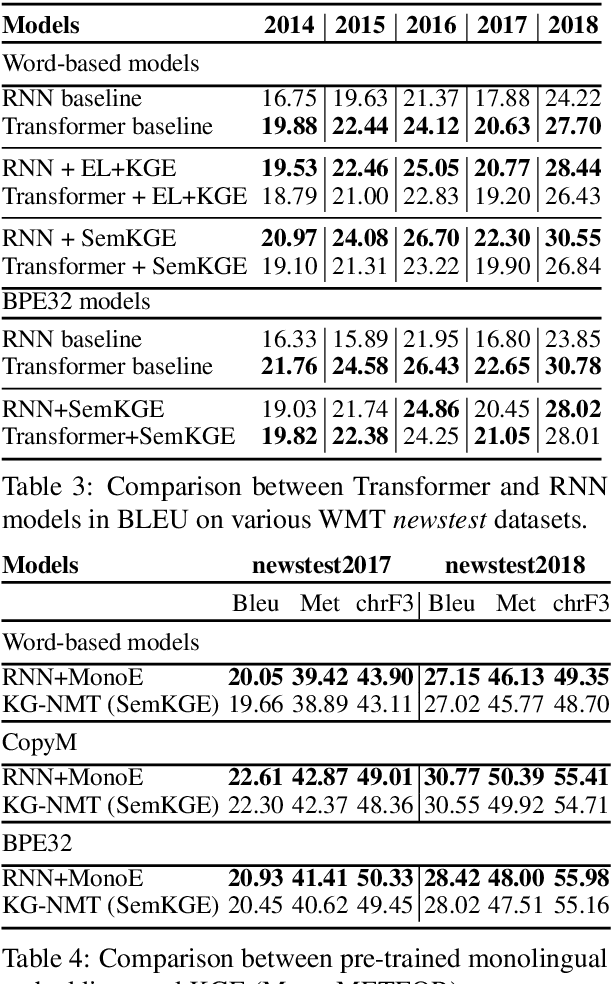
While neural networks have been used extensively to make substantial progress in the machine translation task, they are known for being heavily dependent on the availability of large amounts of training data. Recent efforts have tried to alleviate the data sparsity problem by augmenting the training data using different strategies, such as back-translation. Along with the data scarcity, the out-of-vocabulary words, mostly entities and terminological expressions, pose a difficult challenge to Neural Machine Translation systems. In this paper, we hypothesize that knowledge graphs enhance the semantic feature extraction of neural models, thus optimizing the translation of entities and terminological expressions in texts and consequently leading to a better translation quality. We hence investigate two different strategies for incorporating knowledge graphs into neural models without modifying the neural network architectures. We also examine the effectiveness of our augmentation method to recurrent and non-recurrent (self-attentional) neural architectures. Our knowledge graph augmented neural translation model, dubbed KG-NMT, achieves significant and consistent improvements of +3 BLEU, METEOR and chrF3 on average on the newstest datasets between 2014 and 2018 for WMT English-German translation task.
BENGAL: An Automatic Benchmark Generator for Entity Recognition and Linking
Nov 01, 2018
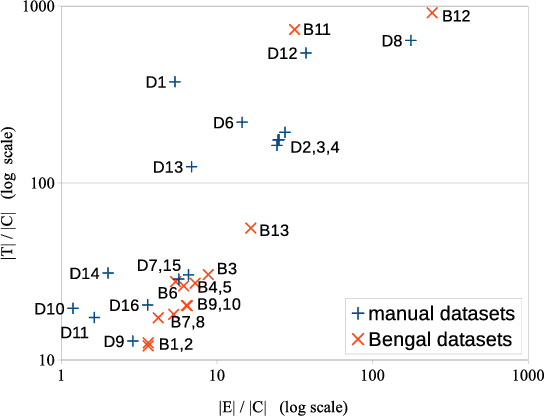
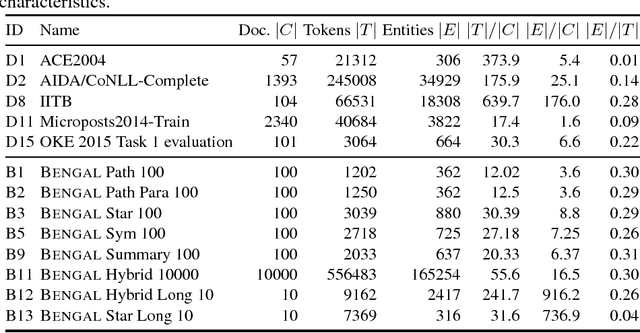
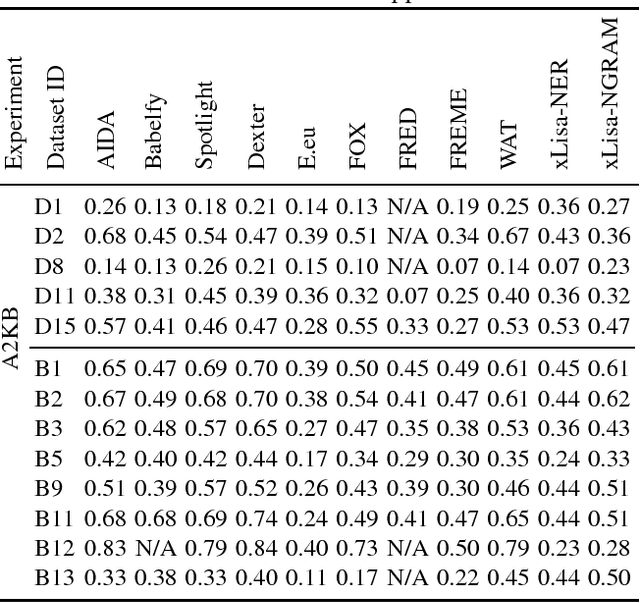
The manual creation of gold standards for named entity recognition and entity linking is time- and resource-intensive. Moreover, recent works show that such gold standards contain a large proportion of mistakes in addition to being difficult to maintain. We hence present BENGAL, a novel automatic generation of such gold standards as a complement to manually created benchmarks. The main advantage of our benchmarks is that they can be readily generated at any time. They are also cost-effective while being guaranteed to be free of annotation errors. We compare the performance of 11 tools on benchmarks in English generated by BENGAL and on 16benchmarks created manually. We show that our approach can be ported easily across languages by presenting results achieved by 4 tools on both Brazilian Portuguese and Spanish. Overall, our results suggest that our automatic benchmark generation approach can create varied benchmarks that have characteristics similar to those of existing benchmarks. Our approach is open-source. Our experimental results are available at http://faturl.com/bengalexpinlg and the code at https://github.com/dice-group/BENGAL.