 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA linearized framework and a new benchmark for model selection for fine-tuning
Jan 29, 2021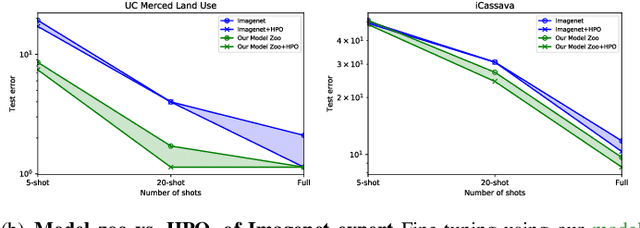

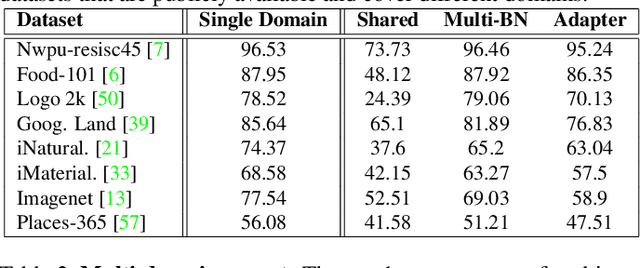
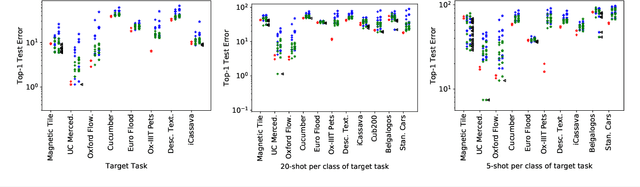
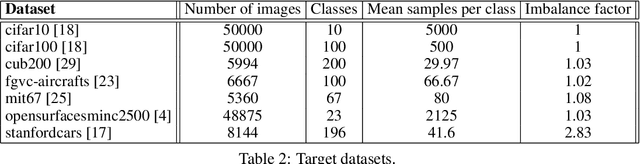
Fine-tuning from a collection of models pre-trained on different domains (a "model zoo") is emerging as a technique to improve test accuracy in the low-data regime. However, model selection, i.e. how to pre-select the right model to fine-tune from a model zoo without performing any training, remains an open topic. We use a linearized framework to approximate fine-tuning, and introduce two new baselines for model selection -- Label-Gradient and Label-Feature Correlation. Since all model selection algorithms in the literature have been tested on different use-cases and never compared directly, we introduce a new comprehensive benchmark for model selection comprising of: i) A model zoo of single and multi-domain models, and ii) Many target tasks. Our benchmark highlights accuracy gain with model zoo compared to fine-tuning Imagenet models. We show our model selection baseline can select optimal models to fine-tune in few selections and has the highest ranking correlation to fine-tuning accuracy compared to existing algorithms.
Revisiting Contrastive Learning for Few-Shot Classification
Jan 26, 2021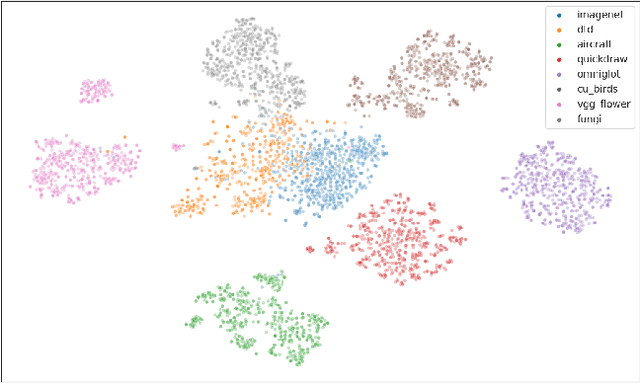
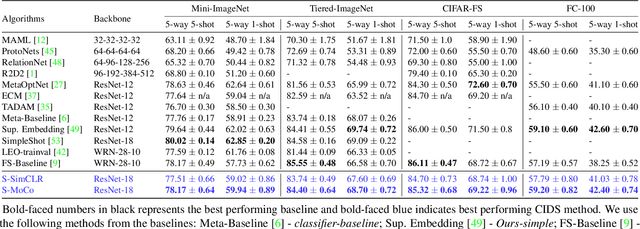
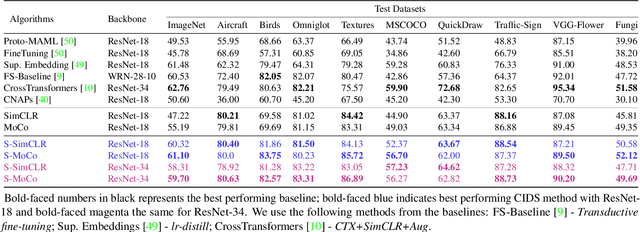
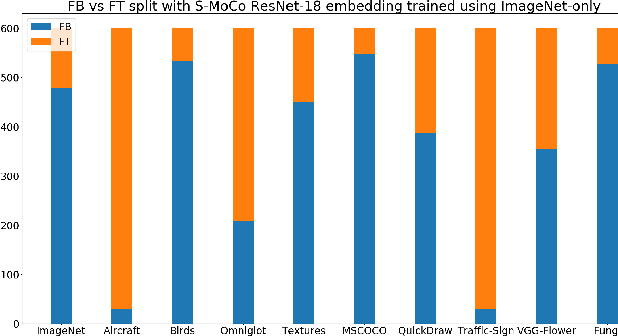
Instance discrimination based contrastive learning has emerged as a leading approach for self-supervised learning of visual representations. Yet, its generalization to novel tasks remains elusive when compared to representations learned with supervision, especially in the few-shot setting. We demonstrate how one can incorporate supervision in the instance discrimination based contrastive self-supervised learning framework to learn representations that generalize better to novel tasks. We call our approach CIDS (Contrastive Instance Discrimination with Supervision). CIDS performs favorably compared to existing algorithms on popular few-shot benchmarks like Mini-ImageNet or Tiered-ImageNet. We also propose a novel model selection algorithm that can be used in conjunction with a universal embedding trained using CIDS to outperform state-of-the-art algorithms on the challenging Meta-Dataset benchmark.
Exponential Moving Average Normalization for Self-supervised and Semi-supervised Learning
Jan 21, 2021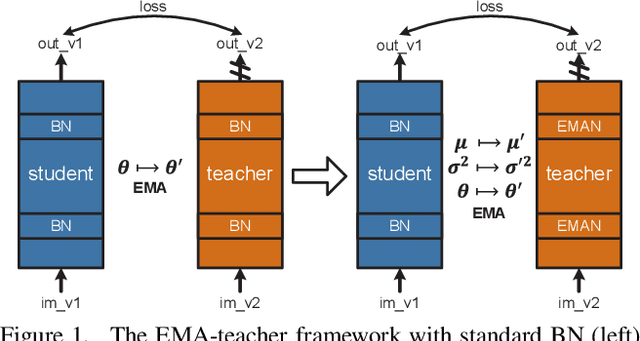
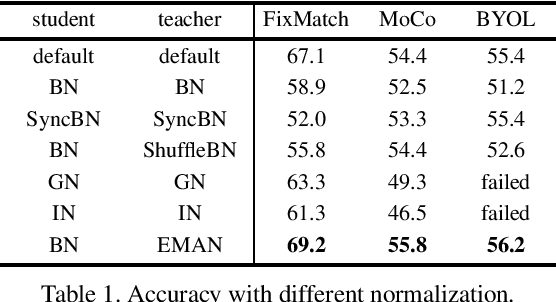
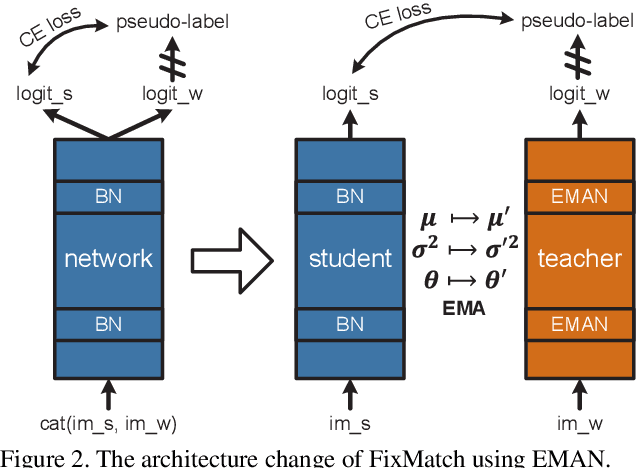
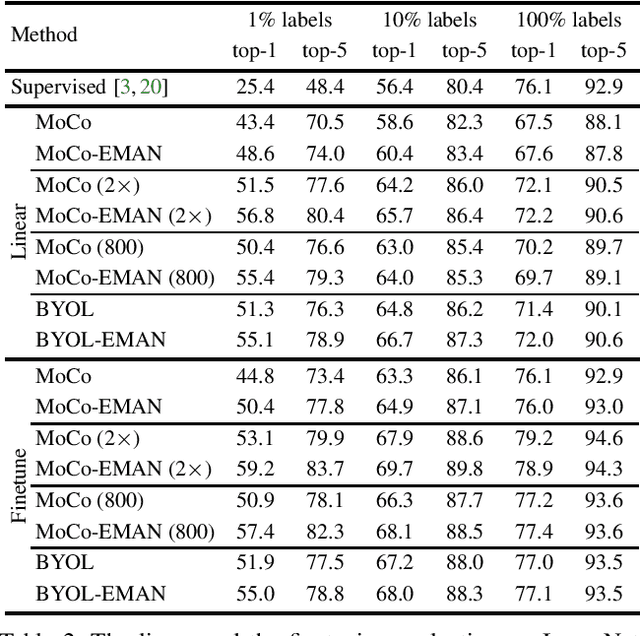
We present a plug-in replacement for batch normalization (BN) called exponential moving average normalization (EMAN), which improves the performance of existing student-teacher based self- and semi-supervised learning techniques. Unlike the standard BN, where the statistics are computed within each batch, EMAN, used in the teacher, updates its statistics by exponential moving average from the BN statistics of the student. This design reduces the intrinsic cross-sample dependency of BN and enhance the generalization of the teacher. EMAN improves strong baselines for self-supervised learning by 4-6/1-2 points and semi-supervised learning by about 7/2 points, when 1%/10% supervised labels are available on ImageNet. These improvements are consistent across methods, network architectures, training duration, and datasets, demonstrating the general effectiveness of this technique.
Estimating informativeness of samples with Smooth Unique Information
Jan 17, 2021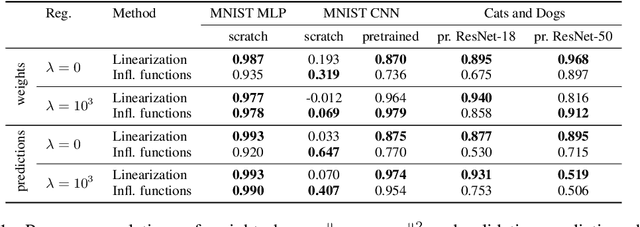

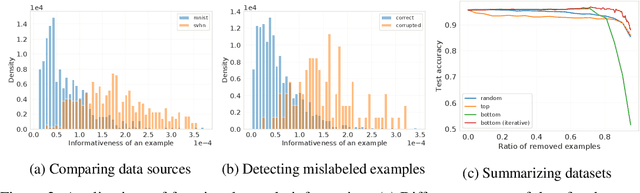
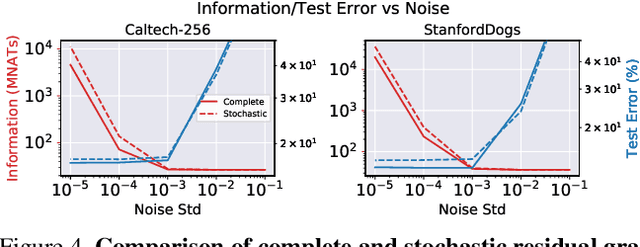
We define a notion of information that an individual sample provides to the training of a neural network, and we specialize it to measure both how much a sample informs the final weights and how much it informs the function computed by the weights. Though related, we show that these quantities have a qualitatively different behavior. We give efficient approximations of these quantities using a linearized network and demonstrate empirically that the approximation is accurate for real-world architectures, such as pre-trained ResNets. We apply these measures to several problems, such as dataset summarization, analysis of under-sampled classes, comparison of informativeness of different data sources, and detection of adversarial and corrupted examples. Our work generalizes existing frameworks but enjoys better computational properties for heavily over-parametrized models, which makes it possible to apply it to real-world networks.
Mixed-Privacy Forgetting in Deep Networks
Dec 24, 2020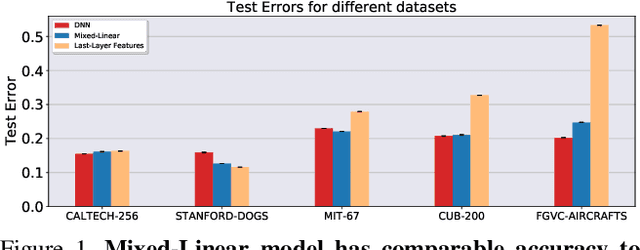
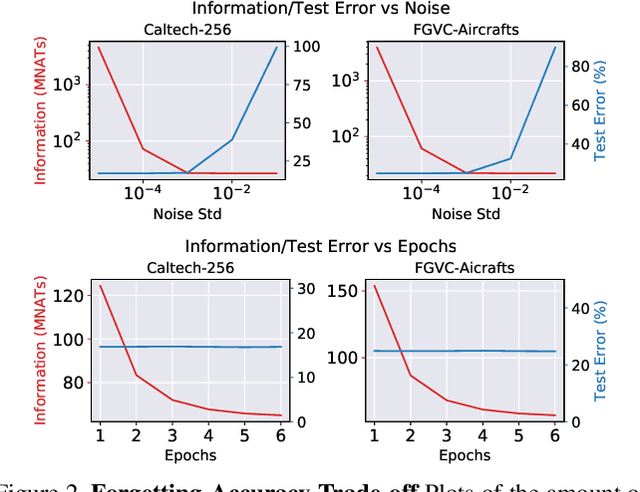
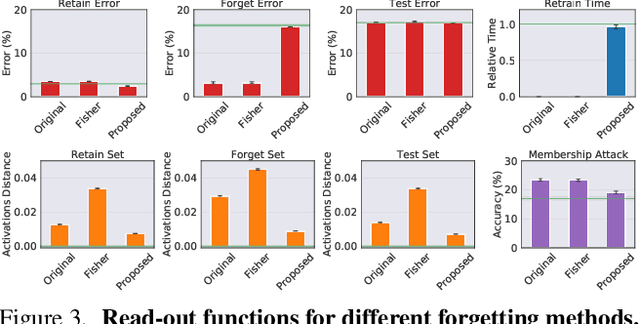
We show that the influence of a subset of the training samples can be removed -- or "forgotten" -- from the weights of a network trained on large-scale image classification tasks, and we provide strong computable bounds on the amount of remaining information after forgetting. Inspired by real-world applications of forgetting techniques, we introduce a novel notion of forgetting in mixed-privacy setting, where we know that a "core" subset of the training samples does not need to be forgotten. While this variation of the problem is conceptually simple, we show that working in this setting significantly improves the accuracy and guarantees of forgetting methods applied to vision classification tasks. Moreover, our method allows efficient removal of all information contained in non-core data by simply setting to zero a subset of the weights with minimal loss in performance. We achieve these results by replacing a standard deep network with a suitable linear approximation. With opportune changes to the network architecture and training procedure, we show that such linear approximation achieves comparable performance to the original network and that the forgetting problem becomes quadratic and can be solved efficiently even for large models. Unlike previous forgetting methods on deep networks, ours can achieve close to the state-of-the-art accuracy on large scale vision tasks. In particular, we show that our method allows forgetting without having to trade off the model accuracy.
LQF: Linear Quadratic Fine-Tuning
Dec 21, 2020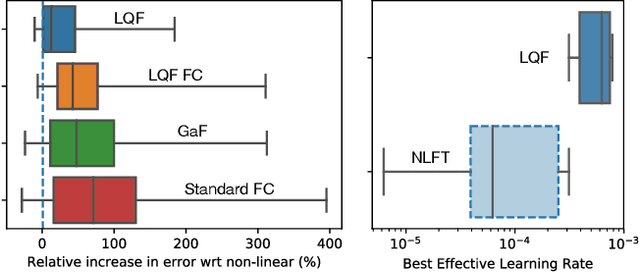
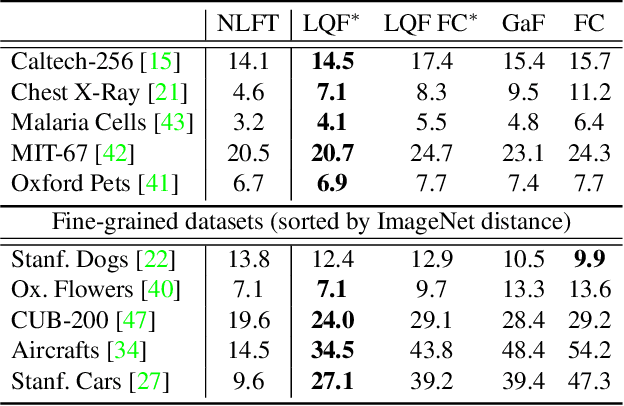
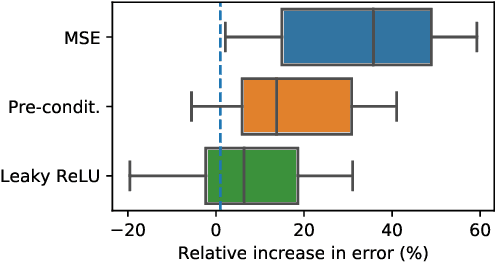
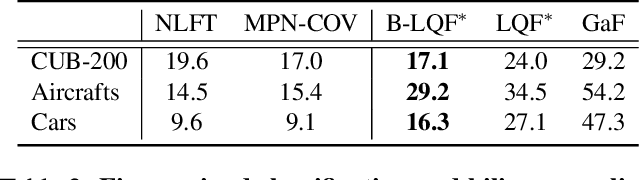
Classifiers that are linear in their parameters, and trained by optimizing a convex loss function, have predictable behavior with respect to changes in the training data, initial conditions, and optimization. Such desirable properties are absent in deep neural networks (DNNs), typically trained by non-linear fine-tuning of a pre-trained model. Previous attempts to linearize DNNs have led to interesting theoretical insights, but have not impacted the practice due to the substantial performance gap compared to standard non-linear optimization. We present the first method for linearizing a pre-trained model that achieves comparable performance to non-linear fine-tuning on most of real-world image classification tasks tested, thus enjoying the interpretability of linear models without incurring punishing losses in performance. LQF consists of simple modifications to the architecture, loss function and optimization typically used for classification: Leaky-ReLU instead of ReLU, mean squared loss instead of cross-entropy, and pre-conditioning using Kronecker factorization. None of these changes in isolation is sufficient to approach the performance of non-linear fine-tuning. When used in combination, they allow us to reach comparable performance, and even superior in the low-data regime, while enjoying the simplicity, robustness and interpretability of linear-quadratic optimization.
Predicting Training Time Without Training
Aug 28, 2020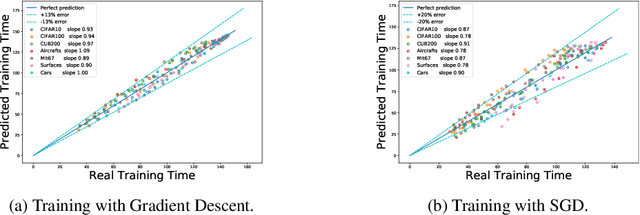
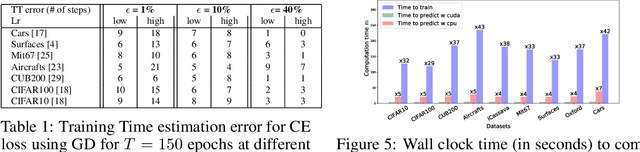
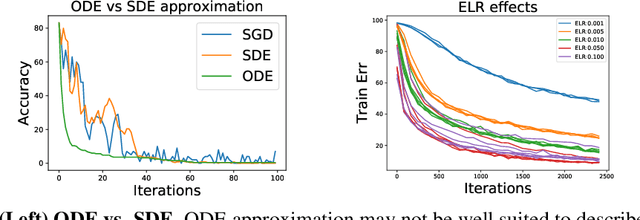
We tackle the problem of predicting the number of optimization steps that a pre-trained deep network needs to converge to a given value of the loss function. To do so, we leverage the fact that the training dynamics of a deep network during fine-tuning are well approximated by those of a linearized model. This allows us to approximate the training loss and accuracy at any point during training by solving a low-dimensional Stochastic Differential Equation (SDE) in function space. Using this result, we are able to predict the time it takes for Stochastic Gradient Descent (SGD) to fine-tune a model to a given loss without having to perform any training. In our experiments, we are able to predict training time of a ResNet within a 20% error margin on a variety of datasets and hyper-parameters, at a 30 to 45-fold reduction in cost compared to actual training. We also discuss how to further reduce the computational and memory cost of our method, and in particular we show that by exploiting the spectral properties of the gradients' matrix it is possible predict training time on a large dataset while processing only a subset of the samples.
Rethinking the Hyperparameters for Fine-tuning
Feb 19, 2020
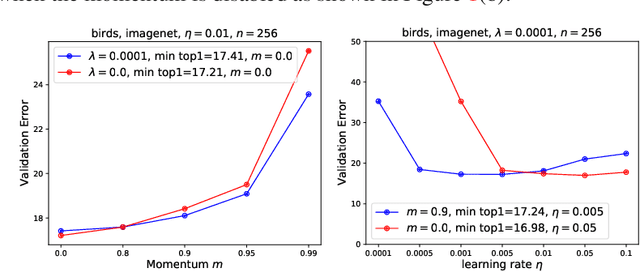
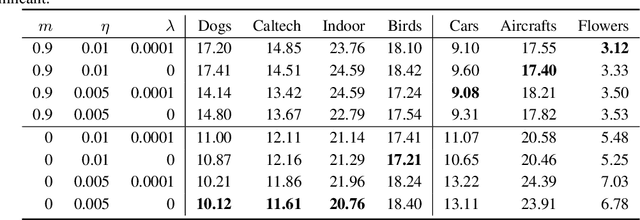
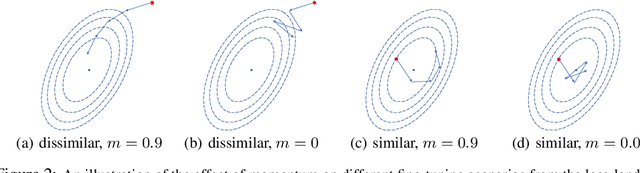
Fine-tuning from pre-trained ImageNet models has become the de-facto standard for various computer vision tasks. Current practices for fine-tuning typically involve selecting an ad-hoc choice of hyperparameters and keeping them fixed to values normally used for training from scratch. This paper re-examines several common practices of setting hyperparameters for fine-tuning. Our findings are based on extensive empirical evaluation for fine-tuning on various transfer learning benchmarks. (1) While prior works have thoroughly investigated learning rate and batch size, momentum for fine-tuning is a relatively unexplored parameter. We find that the value of momentum also affects fine-tuning performance and connect it with previous theoretical findings. (2) Optimal hyperparameters for fine-tuning, in particular, the effective learning rate, are not only dataset dependent but also sensitive to the similarity between the source domain and target domain. This is in contrast to hyperparameters for training from scratch. (3) Reference-based regularization that keeps models close to the initial model does not necessarily apply for "dissimilar" datasets. Our findings challenge common practices of fine-tuning and encourages deep learning practitioners to rethink the hyperparameters for fine-tuning.
Continual Universal Object Detection
Feb 13, 2020Object detection has improved significantly in recent years on multiple challenging benchmarks. However, most existing detectors are still domain-specific, where the models are trained and tested on a single domain. When adapting these detectors to new domains, they often suffer from catastrophic forgetting of previous knowledge. In this paper, we propose a continual object detector that can learn sequentially from different domains without forgetting. First, we explore learning the object detector continually in different scenarios across various domains and categories. Learning from the analysis, we propose attentive feature distillation leveraging both bottom-up and top-down attentions to mitigate forgetting. It takes advantage of attention to ignore the noisy background information and feature distillation to provide strong supervision. Finally, for the most challenging scenarios, we propose an adaptive exemplar sampling method to leverage exemplars from previous tasks for less forgetting effectively. The experimental results show the excellent performance of our proposed method in three different scenarios across seven different object detection datasets.
Incremental Learning for Metric-Based Meta-Learners
Feb 11, 2020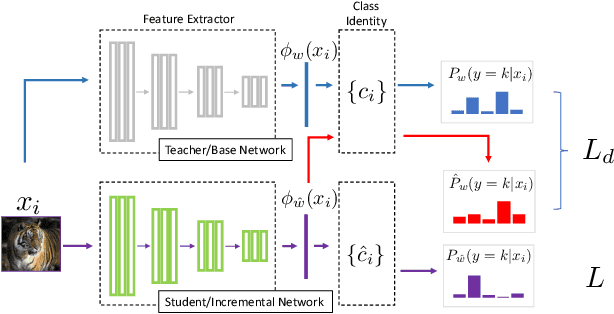
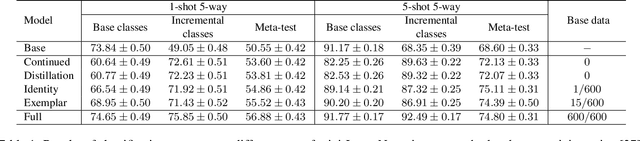
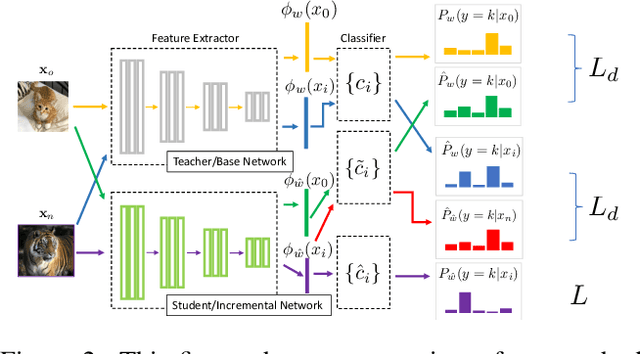

Majority of the modern meta-learning methods for few-shot classification tasks operate in two phases: a meta-training phase where the meta-learner learns a generic representation by solving multiple few-shot tasks sampled from a large dataset and a testing phase, where the meta-learner leverages its learnt internal representation for a specific few-shot task involving classes which were not seen during the meta-training phase. To the best of our knowledge, all such meta-learning methods use a single base dataset for meta-training to sample tasks from and do not adapt the algorithm after meta-training. This strategy may not scale to real-world use-cases where the meta-learner does not potentially have access to the full meta-training dataset from the very beginning and we need to update the meta-learner in an incremental fashion when additional training data becomes available. Through our experimental setup, we develop a notion of incremental learning during the meta-training phase of meta-learning and propose a method which can be used with multiple existing metric-based meta-learning algorithms. Experimental results on benchmark dataset show that our approach performs favorably at test time as compared to training a model with the full meta-training set and incurs negligible amount of catastrophic forgetting