 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerge to Mix: Mixing Datasets via Model Merging
May 21, 2025Mixing datasets for fine-tuning large models (LMs) has become critical for maximizing performance on downstream tasks. However, composing effective dataset mixtures typically relies on heuristics and trial-and-error, often requiring multiple fine-tuning runs to achieve the desired outcome. We propose a novel method, $\textit{Merge to Mix}$, that accelerates composing dataset mixtures through model merging. Model merging is a recent technique that combines the abilities of multiple individually fine-tuned LMs into a single LM by using a few simple arithmetic operations. Our key insight is that merging models individually fine-tuned on each dataset in a mixture can effectively serve as a surrogate for a model fine-tuned on the entire mixture. Merge to Mix leverages this insight to accelerate selecting dataset mixtures without requiring full fine-tuning on each candidate mixture. Our experiments demonstrate that Merge to Mix surpasses state-of-the-art methods in dataset selection for fine-tuning LMs.
Forward Learning with Top-Down Feedback: Empirical and Analytical Characterization
Feb 10, 2023



"Forward-only" algorithms, which train neural networks while avoiding a backward pass, have recently gained attention as a way of solving the biologically unrealistic aspects of backpropagation. Here, we first discuss the similarities between two "forward-only" algorithms, the Forward-Forward and PEPITA frameworks, and demonstrate that PEPITA is equivalent to a Forward-Forward with top-down feedback connections. Then, we focus on PEPITA to address compelling challenges related to the "forward-only" rules, which include providing an analytical understanding of their dynamics and reducing the gap between their performance and that of backpropagation. We propose a theoretical analysis of the dynamics of PEPITA. In particular, we show that PEPITA is well-approximated by an "adaptive-feedback-alignment" algorithm and we analytically track its performance during learning in a prototype high-dimensional setting. Finally, we develop a strategy to apply the weight mirroring algorithm on "forward-only" algorithms with top-down feedback and we show how it impacts PEPITA's accuracy and convergence rate.
To Which Out-Of-Distribution Object Orientations Are DNNs Capable of Generalizing?
Sep 28, 2021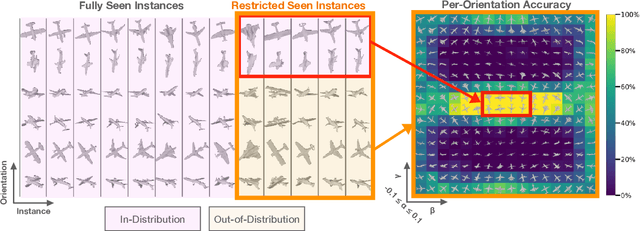
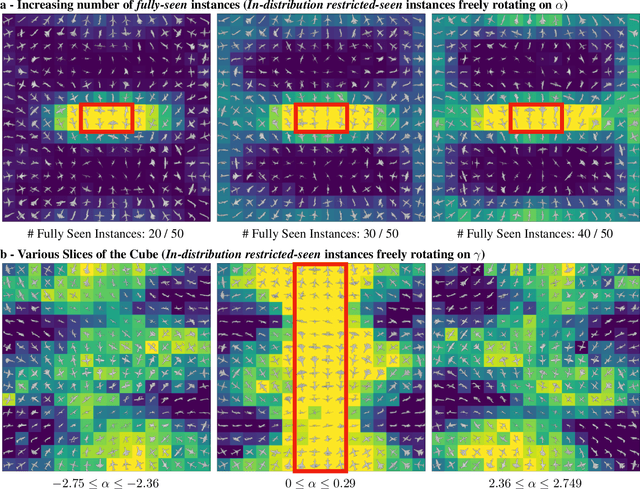

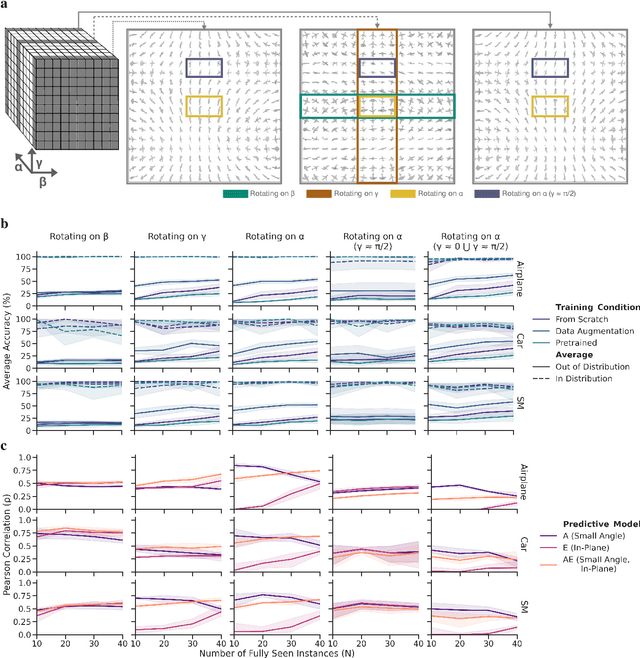
The capability of Deep Neural Networks (DNNs) to recognize objects in orientations outside the distribution of the training data, ie. out-of-distribution (OoD) orientations, is not well understood. For humans, behavioral studies showed that recognition accuracy varies across OoD orientations, where generalization is much better for some orientations than for others. In contrast, for DNNs, it remains unknown how generalization abilities are distributed among OoD orientations. In this paper, we investigate the limitations of DNNs' generalization capacities by systematically inspecting patterns of success and failure of DNNs across OoD orientations. We use an intuitive and controlled, yet challenging learning paradigm, in which some instances of an object category are seen at only a few geometrically restricted orientations, while other instances are seen at all orientations. The effect of data diversity is also investigated by increasing the number of instances seen at all orientations in the training set. We present a comprehensive analysis of DNNs' generalization abilities and limitations for representative architectures (ResNet, Inception, DenseNet and CORnet). Our results reveal an intriguing pattern -- DNNs are only capable of generalizing to instances of objects that appear like 2D, ie. in-plane, rotations of in-distribution orientations.