 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrasound Video Summarization using Deep Reinforcement Learning
May 19, 2020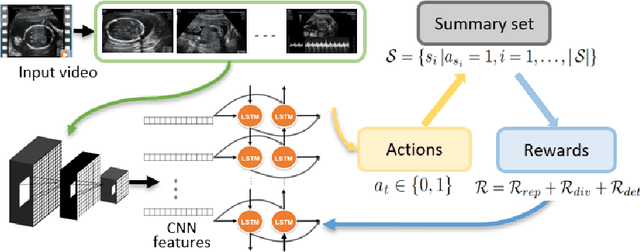
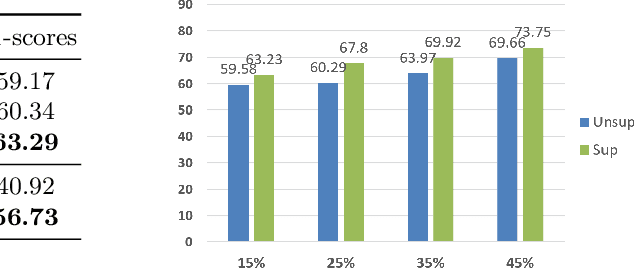
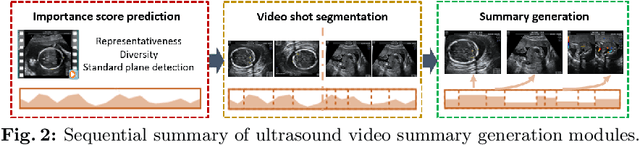
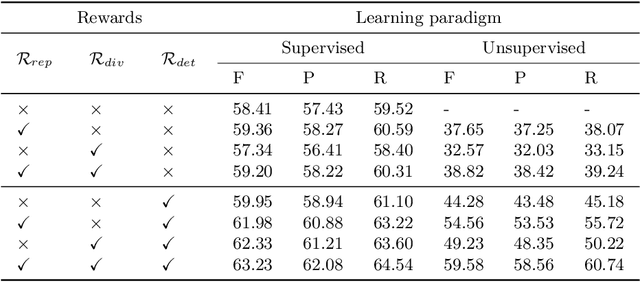
Video is an essential imaging modality for diagnostics, e.g. in ultrasound imaging, for endoscopy, or movement assessment. However, video hasn't received a lot of attention in the medical image analysis community. In the clinical practice, it is challenging to utilise raw diagnostic video data efficiently as video data takes a long time to process, annotate or audit. In this paper we introduce a novel, fully automatic video summarization method that is tailored to the needs of medical video data. Our approach is framed as reinforcement learning problem and produces agents focusing on the preservation of important diagnostic information. We evaluate our method on videos from fetal ultrasound screening, where commonly only a small amount of the recorded data is used diagnostically. We show that our method is superior to alternative video summarization methods and that it preserves essential information required by clinical diagnostic standards.
Correlation of Auroral Dynamics and GNSS Scintillation with an Autoencoder
Oct 04, 2019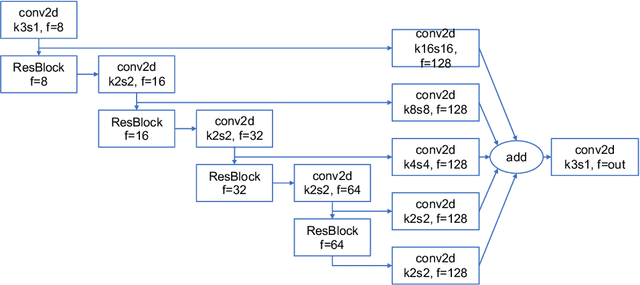

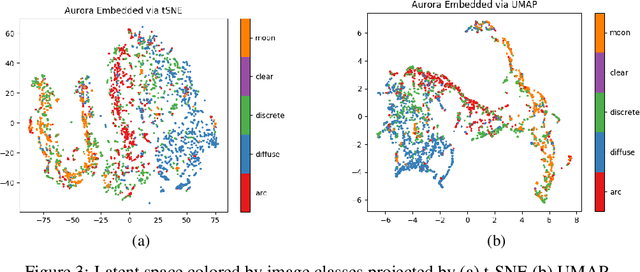
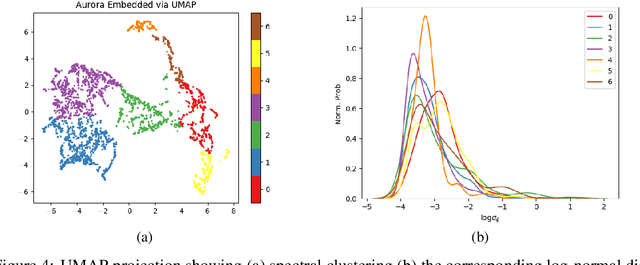
High energy particles originating from solar activity travel along the the Earth's magnetic field and interact with the atmosphere around the higher latitudes. These interactions often manifest as aurora in the form of visible light in the Earth's ionosphere. These interactions also result in irregularities in the electron density, which cause disruptions in the amplitude and phase of the radio signals from the Global Navigation Satellite Systems (GNSS), known as 'scintillation'. In this paper we use a multi-scale residual autoencoder (Res-AE) to show the correlation between specific dynamic structures of the aurora and the magnitude of the GNSS phase scintillations ($\sigma_{\phi}$). Auroral images are encoded in a lower dimensional feature space using the Res-AE, which in turn are clustered with t-SNE and UMAP. Both methods produce similar clusters, and specific clusters demonstrate greater correlations with observed phase scintillations. Our results suggest that specific dynamic structures of auroras are highly correlated with GNSS phase scintillations.
Prediction of GNSS Phase Scintillations: A Machine Learning Approach
Oct 03, 2019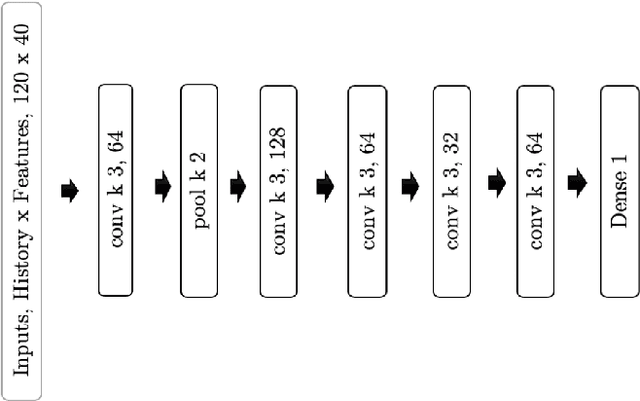
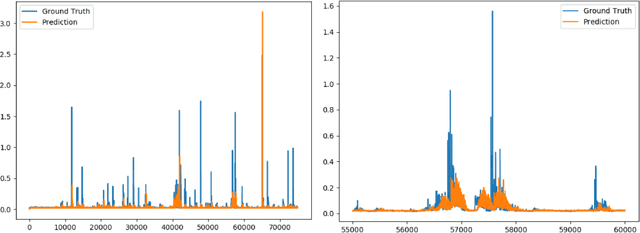
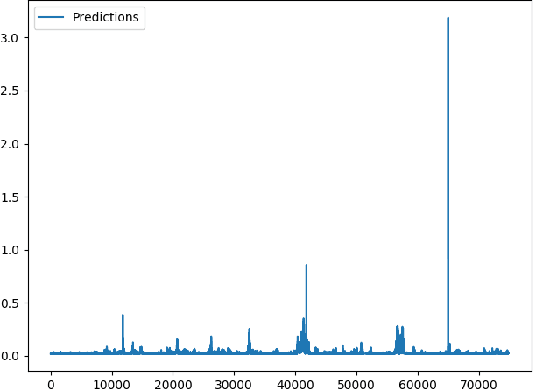
A Global Navigation Satellite System (GNSS) uses a constellation of satellites around the earth for accurate navigation, timing, and positioning. Natural phenomena like space weather introduce irregularities in the Earth's ionosphere, disrupting the propagation of the radio signals that GNSS relies upon. Such disruptions affect both the amplitude and the phase of the propagated waves. No physics-based model currently exists to predict the time and location of these disruptions with sufficient accuracy and at relevant scales. In this paper, we focus on predicting the phase fluctuations of GNSS radio waves, known as phase scintillations. We propose a novel architecture and loss function to predict 1 hour in advance the magnitude of phase scintillations within a time window of plus-minus 5 minutes with state-of-the-art performance.
Flexible Conditional Image Generation of Missing Data with Learned Mental Maps
Aug 29, 2019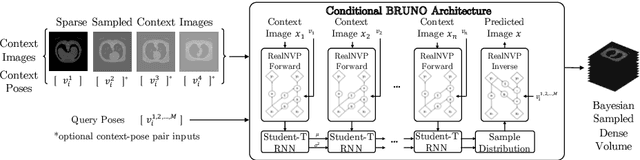
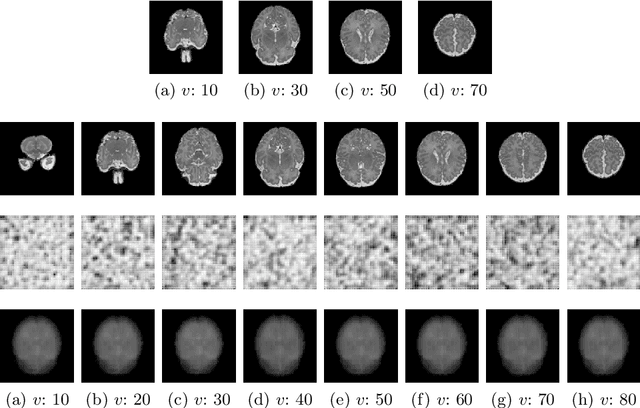
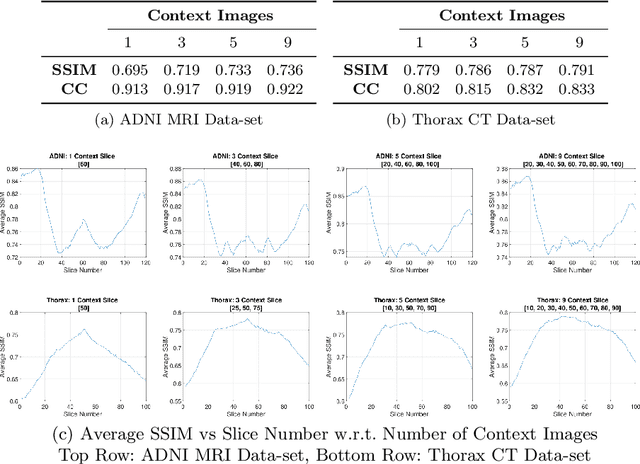
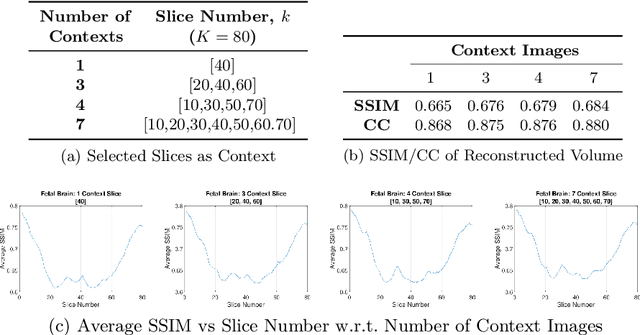
Real-world settings often do not allow acquisition of high-resolution volumetric images for accurate morphological assessment and diagnostic. In clinical practice it is frequently common to acquire only sparse data (e.g. individual slices) for initial diagnostic decision making. Thereby, physicians rely on their prior knowledge (or mental maps) of the human anatomy to extrapolate the underlying 3D information. Accurate mental maps require years of anatomy training, which in the first instance relies on normative learning, i.e. excluding pathology. In this paper, we leverage Bayesian Deep Learning and environment mapping to generate full volumetric anatomy representations from none to a small, sparse set of slices. We evaluate proof of concept implementations based on Generative Query Networks (GQN) and Conditional BRUNO using abdominal CT and brain MRI as well as in a clinical application involving sparse, motion-corrupted MR acquisition for fetal imaging. Our approach allows to reconstruct 3D volumes from 1 to 4 tomographic slices, with a SSIM of 0.7+ and cross-correlation of 0.8+ compared to the 3D ground truth.
Multiple Landmark Detection using Multi-Agent Reinforcement Learning
Jul 22, 2019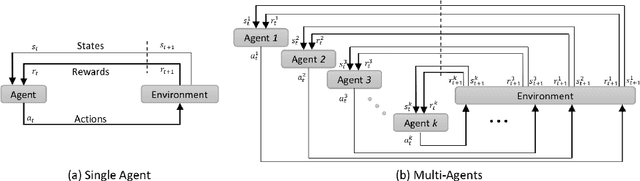

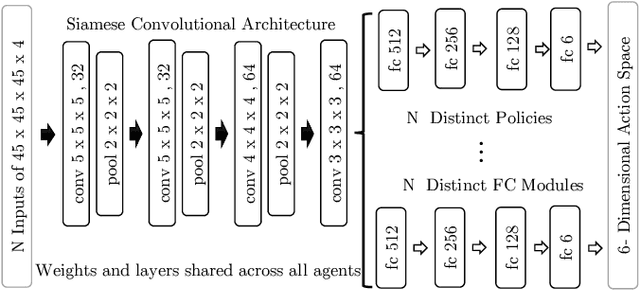

The detection of anatomical landmarks is a vital step for medical image analysis and applications for diagnosis, interpretation and guidance. Manual annotation of landmarks is a tedious process that requires domain-specific expertise and introduces inter-observer variability. This paper proposes a new detection approach for multiple landmarks based on multi-agent reinforcement learning. Our hypothesis is that the position of all anatomical landmarks is interdependent and non-random within the human anatomy, thus finding one landmark can help to deduce the location of others. Using a Deep Q-Network (DQN) architecture we construct an environment and agent with implicit inter-communication such that we can accommodate K agents acting and learning simultaneously, while they attempt to detect K different landmarks. During training the agents collaborate by sharing their accumulated knowledge for a collective gain. We compare our approach with state-of-the-art architectures and achieve significantly better accuracy by reducing the detection error by 50%, while requiring fewer computational resources and time to train compared to the naive approach of training K agents separately.
Deep Segmentation and Registration in X-Ray Angiography Video
Aug 03, 2018
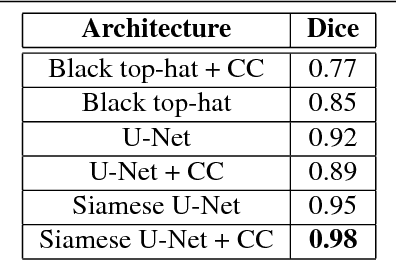
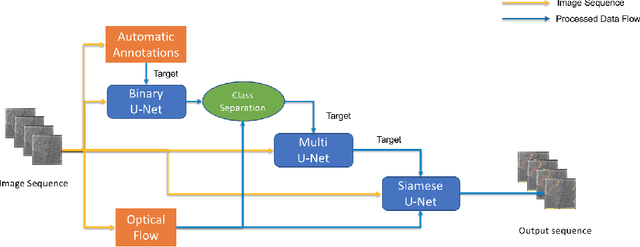

In interventional radiology, short video sequences of vein structure in motion are captured in order to help medical personnel identify vascular issues or plan intervention. Semantic segmentation can greatly improve the usefulness of these videos by indicating exact position of vessels and instruments, thus reducing the ambiguity. We propose a real-time segmentation method for these tasks, based on U-Net network trained in a Siamese architecture from automatically generated annotations. We make use of noisy low level binary segmentation and optical flow to generate multi class annotations that are successively improved in a multistage segmentation approach. We significantly improve the performance of a state of the art U-Net at the processing speeds of 90fps.
The RNN-ELM Classifier
Sep 25, 2016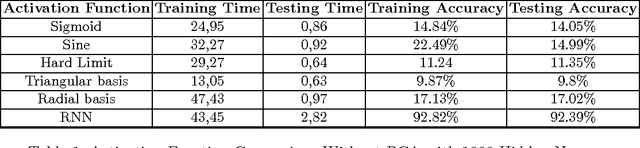
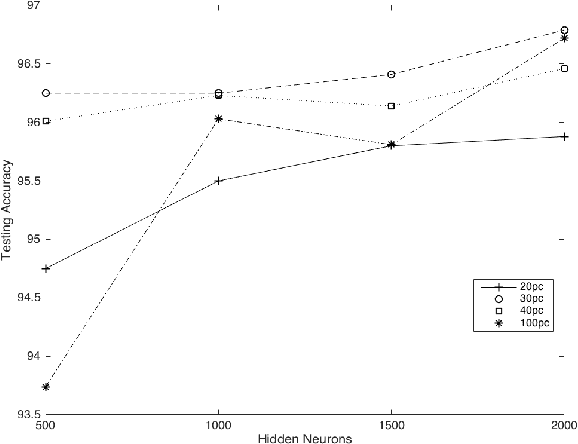
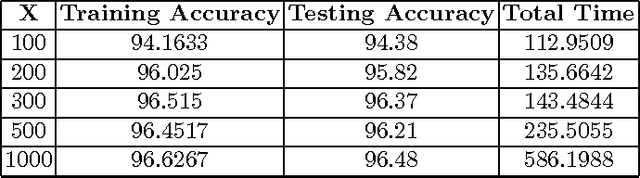
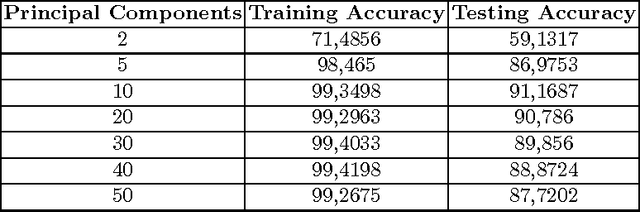
In this paper we examine learning methods combining the Random Neural Network, a biologically inspired neural network and the Extreme Learning Machine that achieve state of the art classification performance while requiring much shorter training time. The Random Neural Network is a integrate and fire computational model of a neural network whose mathematical structure permits the efficient analysis of large ensembles of neurons. An activation function is derived from the RNN and used in an Extreme Learning Machine. We compare the performance of this combination against the ELM with various activation functions, we reduce the input dimensionality via PCA and compare its performance vs. autoencoder based versions of the RNN-ELM.