 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelNet: End-to-End Modeling of Entities & Relations
Nov 16, 2017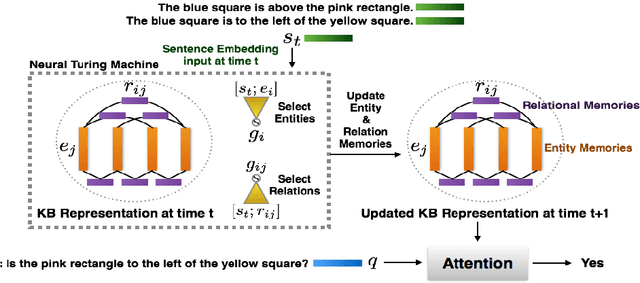
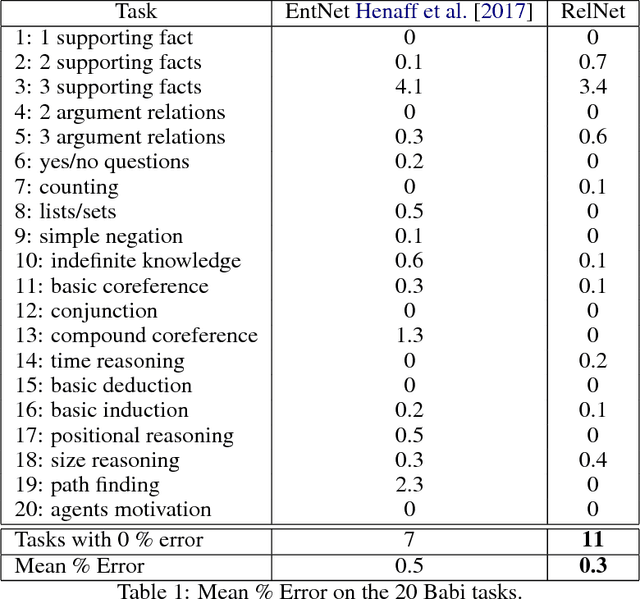
We introduce RelNet: a new model for relational reasoning. RelNet is a memory augmented neural network which models entities as abstract memory slots and is equipped with an additional relational memory which models relations between all memory pairs. The model thus builds an abstract knowledge graph on the entities and relations present in a document which can then be used to answer questions about the document. It is trained end-to-end: only supervision to the model is in the form of correct answers to the questions. We test the model on the 20 bAbI question-answering tasks with 10k examples per task and find that it solves all the tasks with a mean error of 0.3%, achieving 0% error on 11 of the 20 tasks.
Chains of Reasoning over Entities, Relations, and Text using Recurrent Neural Networks
May 01, 2017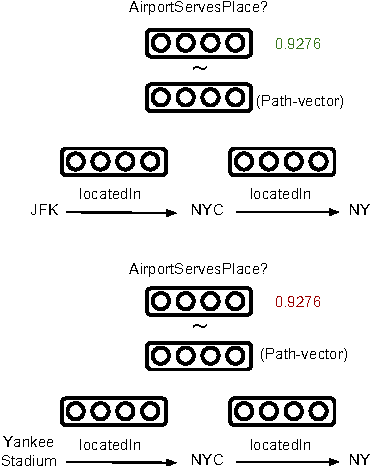
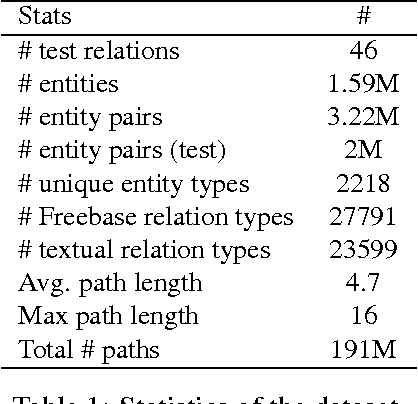
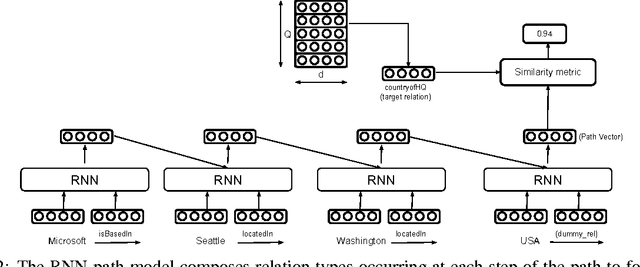
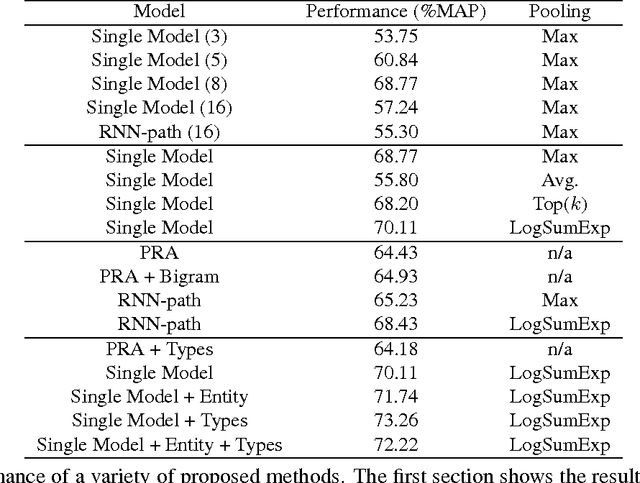
Our goal is to combine the rich multistep inference of symbolic logical reasoning with the generalization capabilities of neural networks. We are particularly interested in complex reasoning about entities and relations in text and large-scale knowledge bases (KBs). Neelakantan et al. (2015) use RNNs to compose the distributed semantics of multi-hop paths in KBs; however for multiple reasons, the approach lacks accuracy and practicality. This paper proposes three significant modeling advances: (1) we learn to jointly reason about relations, entities, and entity-types; (2) we use neural attention modeling to incorporate multiple paths; (3) we learn to share strength in a single RNN that represents logical composition across all relations. On a largescale Freebase+ClueWeb prediction task, we achieve 25% error reduction, and a 53% error reduction on sparse relations due to shared strength. On chains of reasoning in WordNet we reduce error in mean quantile by 84% versus previous state-of-the-art. The code and data are available at https://rajarshd.github.io/ChainsofReasoning
Learning a Natural Language Interface with Neural Programmer
Mar 02, 2017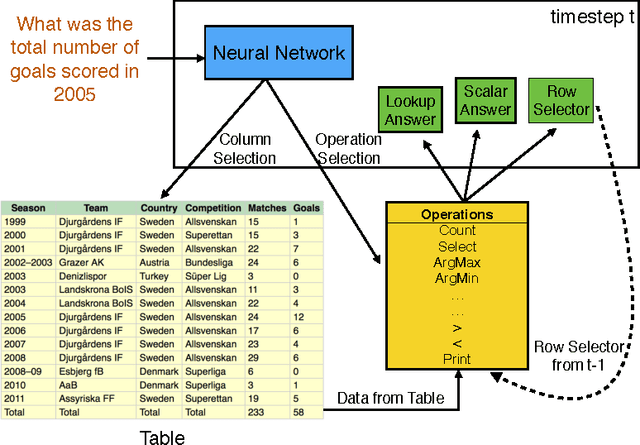
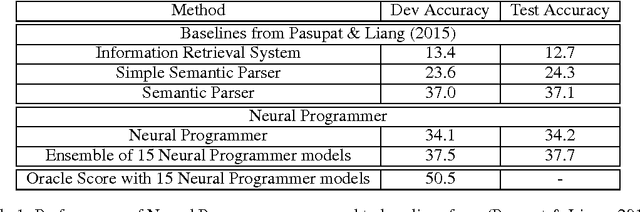

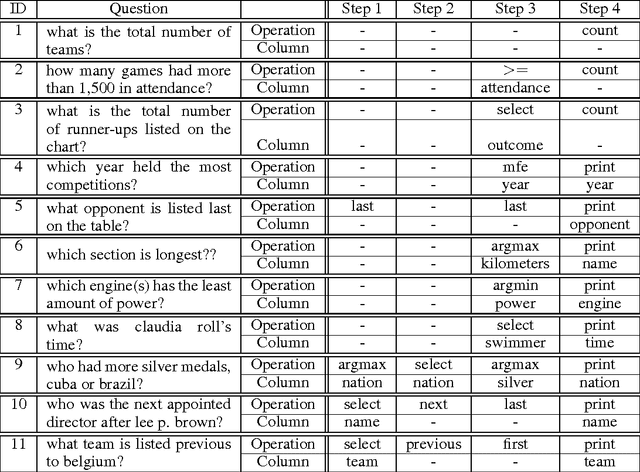
Learning a natural language interface for database tables is a challenging task that involves deep language understanding and multi-step reasoning. The task is often approached by mapping natural language queries to logical forms or programs that provide the desired response when executed on the database. To our knowledge, this paper presents the first weakly supervised, end-to-end neural network model to induce such programs on a real-world dataset. We enhance the objective function of Neural Programmer, a neural network with built-in discrete operations, and apply it on WikiTableQuestions, a natural language question-answering dataset. The model is trained end-to-end with weak supervision of question-answer pairs, and does not require domain-specific grammars, rules, or annotations that are key elements in previous approaches to program induction. The main experimental result in this paper is that a single Neural Programmer model achieves 34.2% accuracy using only 10,000 examples with weak supervision. An ensemble of 15 models, with a trivial combination technique, achieves 37.7% accuracy, which is competitive to the current state-of-the-art accuracy of 37.1% obtained by a traditional natural language semantic parser.
Generalizing to Unseen Entities and Entity Pairs with Row-less Universal Schema
Jan 09, 2017

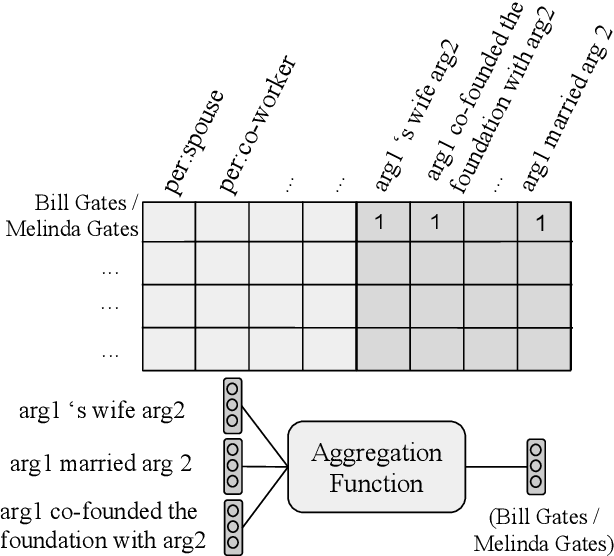
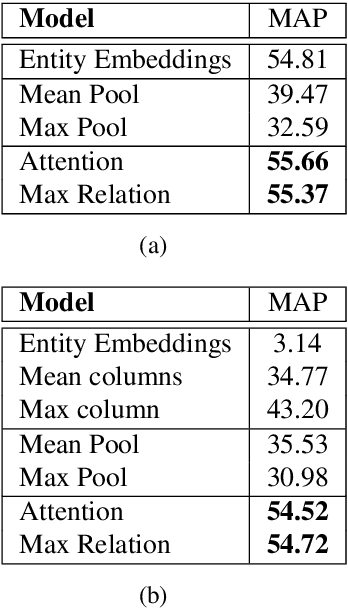
Universal schema predicts the types of entities and relations in a knowledge base (KB) by jointly embedding the union of all available schema types---not only types from multiple structured databases (such as Freebase or Wikipedia infoboxes), but also types expressed as textual patterns from raw text. This prediction is typically modeled as a matrix completion problem, with one type per column, and either one or two entities per row (in the case of entity types or binary relation types, respectively). Factorizing this sparsely observed matrix yields a learned vector embedding for each row and each column. In this paper we explore the problem of making predictions for entities or entity-pairs unseen at training time (and hence without a pre-learned row embedding). We propose an approach having no per-row parameters at all; rather we produce a row vector on the fly using a learned aggregation function of the vectors of the observed columns for that row. We experiment with various aggregation functions, including neural network attention models. Our approach can be understood as a natural language database, in that questions about KB entities are answered by attending to textual or database evidence. In experiments predicting both relations and entity types, we demonstrate that despite having an order of magnitude fewer parameters than traditional universal schema, we can match the accuracy of the traditional model, and more importantly, we can now make predictions about unseen rows with nearly the same accuracy as rows available at training time.
Neural Programmer: Inducing Latent Programs with Gradient Descent
Aug 04, 2016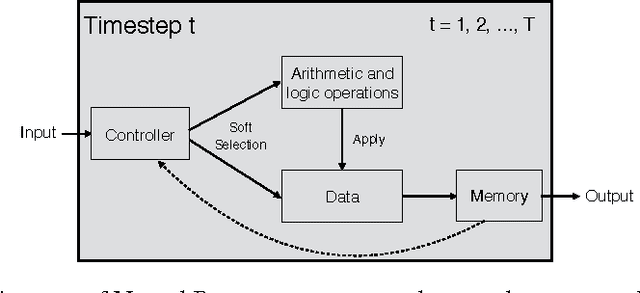

Deep neural networks have achieved impressive supervised classification performance in many tasks including image recognition, speech recognition, and sequence to sequence learning. However, this success has not been translated to applications like question answering that may involve complex arithmetic and logic reasoning. A major limitation of these models is in their inability to learn even simple arithmetic and logic operations. For example, it has been shown that neural networks fail to learn to add two binary numbers reliably. In this work, we propose Neural Programmer, an end-to-end differentiable neural network augmented with a small set of basic arithmetic and logic operations. Neural Programmer can call these augmented operations over several steps, thereby inducing compositional programs that are more complex than the built-in operations. The model learns from a weak supervision signal which is the result of execution of the correct program, hence it does not require expensive annotation of the correct program itself. The decisions of what operations to call, and what data segments to apply to are inferred by Neural Programmer. Such decisions, during training, are done in a differentiable fashion so that the entire network can be trained jointly by gradient descent. We find that training the model is difficult, but it can be greatly improved by adding random noise to the gradient. On a fairly complex synthetic table-comprehension dataset, traditional recurrent networks and attentional models perform poorly while Neural Programmer typically obtains nearly perfect accuracy.
Adding Gradient Noise Improves Learning for Very Deep Networks
Nov 21, 2015

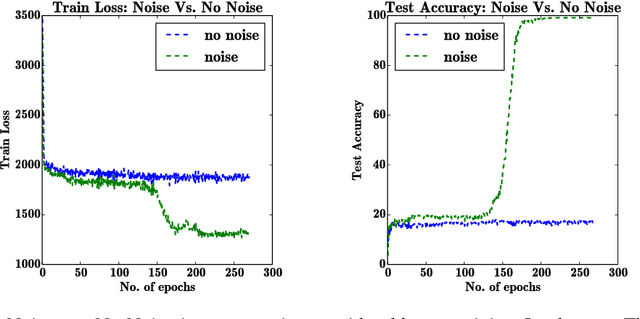
Deep feedforward and recurrent networks have achieved impressive results in many perception and language processing applications. This success is partially attributed to architectural innovations such as convolutional and long short-term memory networks. The main motivation for these architectural innovations is that they capture better domain knowledge, and importantly are easier to optimize than more basic architectures. Recently, more complex architectures such as Neural Turing Machines and Memory Networks have been proposed for tasks including question answering and general computation, creating a new set of optimization challenges. In this paper, we discuss a low-overhead and easy-to-implement technique of adding gradient noise which we find to be surprisingly effective when training these very deep architectures. The technique not only helps to avoid overfitting, but also can result in lower training loss. This method alone allows a fully-connected 20-layer deep network to be trained with standard gradient descent, even starting from a poor initialization. We see consistent improvements for many complex models, including a 72% relative reduction in error rate over a carefully-tuned baseline on a challenging question-answering task, and a doubling of the number of accurate binary multiplication models learned across 7,000 random restarts. We encourage further application of this technique to additional complex modern architectures.
Compositional Vector Space Models for Knowledge Base Completion
May 27, 2015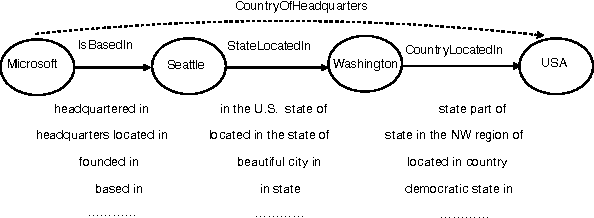

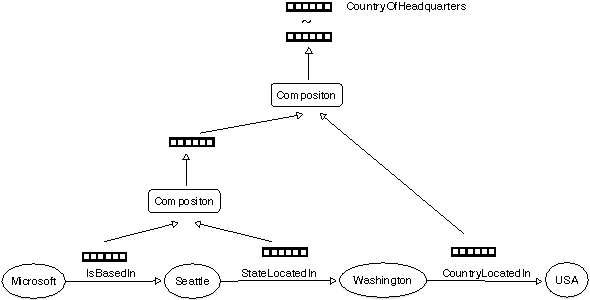

Knowledge base (KB) completion adds new facts to a KB by making inferences from existing facts, for example by inferring with high likelihood nationality(X,Y) from bornIn(X,Y). Most previous methods infer simple one-hop relational synonyms like this, or use as evidence a multi-hop relational path treated as an atomic feature, like bornIn(X,Z) -> containedIn(Z,Y). This paper presents an approach that reasons about conjunctions of multi-hop relations non-atomically, composing the implications of a path using a recursive neural network (RNN) that takes as inputs vector embeddings of the binary relation in the path. Not only does this allow us to generalize to paths unseen at training time, but also, with a single high-capacity RNN, to predict new relation types not seen when the compositional model was trained (zero-shot learning). We assemble a new dataset of over 52M relational triples, and show that our method improves over a traditional classifier by 11%, and a method leveraging pre-trained embeddings by 7%.
Inferring Missing Entity Type Instances for Knowledge Base Completion: New Dataset and Methods
Apr 24, 2015
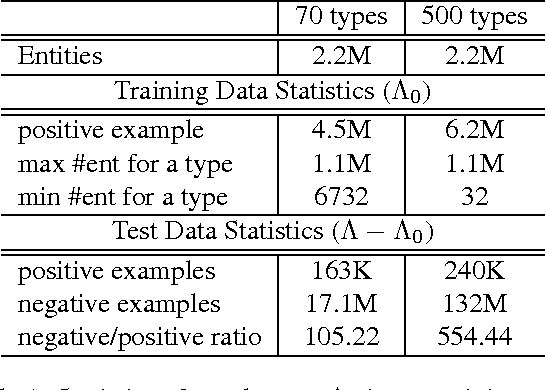


Most of previous work in knowledge base (KB) completion has focused on the problem of relation extraction. In this work, we focus on the task of inferring missing entity type instances in a KB, a fundamental task for KB competition yet receives little attention. Due to the novelty of this task, we construct a large-scale dataset and design an automatic evaluation methodology. Our knowledge base completion method uses information within the existing KB and external information from Wikipedia. We show that individual methods trained with a global objective that considers unobserved cells from both the entity and the type side gives consistently higher quality predictions compared to baseline methods. We also perform manual evaluation on a small subset of the data to verify the effectiveness of our knowledge base completion methods and the correctness of our proposed automatic evaluation method.
Efficient Non-parametric Estimation of Multiple Embeddings per Word in Vector Space
Apr 24, 2015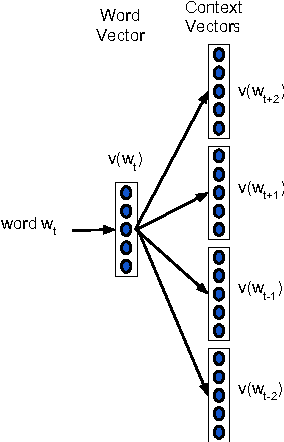
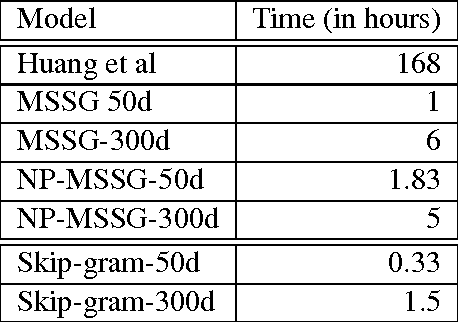
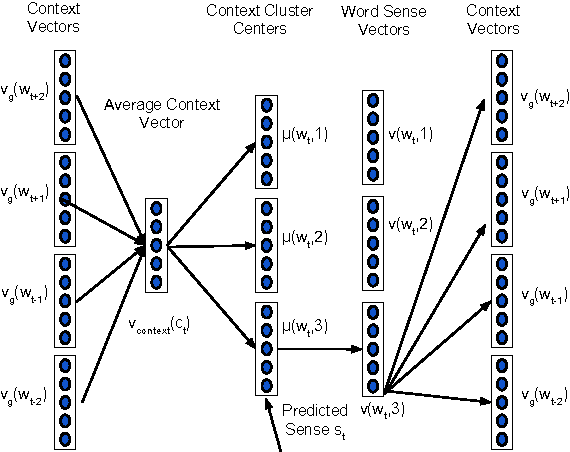
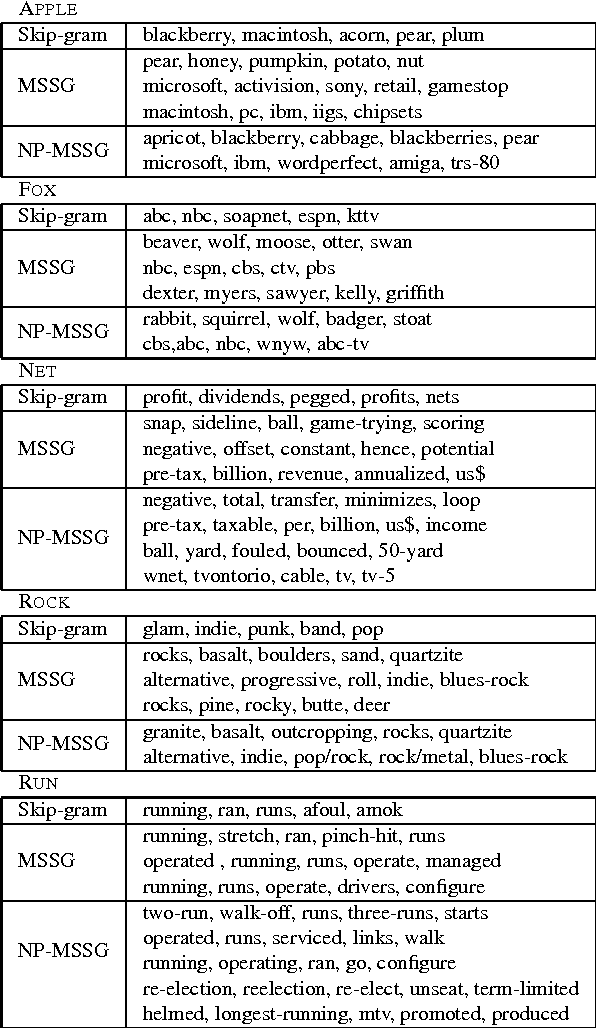
There is rising interest in vector-space word embeddings and their use in NLP, especially given recent methods for their fast estimation at very large scale. Nearly all this work, however, assumes a single vector per word type ignoring polysemy and thus jeopardizing their usefulness for downstream tasks. We present an extension to the Skip-gram model that efficiently learns multiple embeddings per word type. It differs from recent related work by jointly performing word sense discrimination and embedding learning, by non-parametrically estimating the number of senses per word type, and by its efficiency and scalability. We present new state-of-the-art results in the word similarity in context task and demonstrate its scalability by training with one machine on a corpus of nearly 1 billion tokens in less than 6 hours.
Learning Dictionaries for Named Entity Recognition using Minimal Supervision
Apr 24, 2015
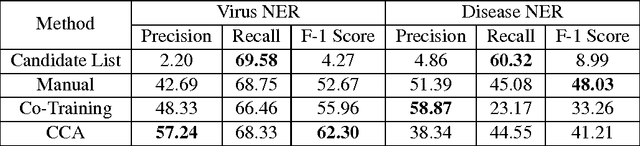
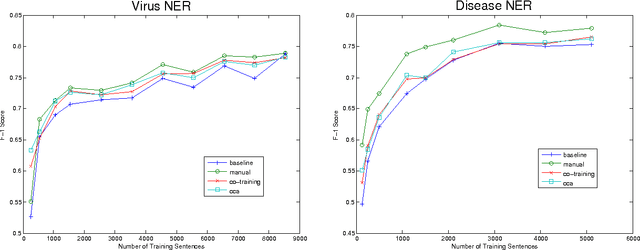
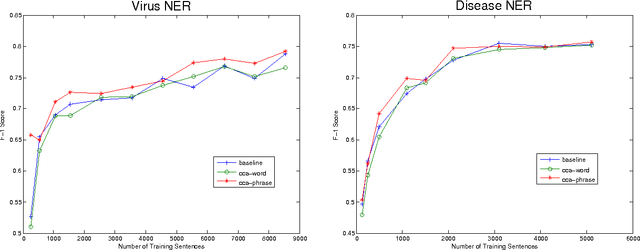
This paper describes an approach for automatic construction of dictionaries for Named Entity Recognition (NER) using large amounts of unlabeled data and a few seed examples. We use Canonical Correlation Analysis (CCA) to obtain lower dimensional embeddings (representations) for candidate phrases and classify these phrases using a small number of labeled examples. Our method achieves 16.5% and 11.3% F-1 score improvement over co-training on disease and virus NER respectively. We also show that by adding candidate phrase embeddings as features in a sequence tagger gives better performance compared to using word embeddings.