 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum Based Reward Design for Low Emission Traffic Signal Control
May 28, 2026Urban traffic congestion is a growing global issue contributing significantly to long commute times and environmental pollution. Traditional traffic signal control systems often fail to adapt to dynamic traffic conditions. Adaptive traffic signal control can improve urban traffic without changing road infrastructure. Deep Reinforcement Learning (DRL) has shown strong performance for this task, but existing delay and queue-based rewards often produce short-sighted or unstable policies. This paper proposes a Momentum-Based Reward Function (MBRF) that encourages vehicles to keep moving rather than penalizing congestion alone. The method is evaluated in SUMO (Simulation of Urban MObility) using standard traffic metrics such as waiting time, queue length, throughput, and CO2 emissions. Results show that the proposed reward produces better throughput-emission trade-offs and more stable learning behavior than delay or queue-based rewards, as well as classical controllers such as Max Pressure and LQF.
Robust and Clinically Reliable EEG Biomarkers: A Cross Population Framework for Generalizable Parkinson's Disease Detection
Apr 27, 2026Developing robust and clinically reliable EEG biomarkers requires evaluation frameworks that explicitly address cross population generalization in multi site settings such as Parkinsons disease (PD) detection. Models trained under i.i.d. assumptions often capture population specific artifacts rather than disease relevant neural structure, leading to poor generalization across clinical cohorts. EEG further amplifies this challenge due to low signal to noise ratio and heterogeneous acquisition conditions. We propose a population aware evaluation framework to assess the robustness and clinical reliability of EEG biomarkers under distribution shift. Using an n gram expansion strategy, we enumerate all cross population train test configurations across five independent cohorts, resulting in 75 directional evaluations. A nested cross validation design with integrated channel selection ensures prospective biomarker identification without population leakage. Results show that cross population transfer is asymmetric and that both accuracy and biomarker stability improve with increasing training population diversity, achieving up to 94.1% accuracy on held out cohorts. A theoretical analysis based on mixture risk optimization and hypothesis space contraction explains these trends, showing that multi population training promotes population robust representations. This work establishes a principled framework for learning robust, generalizable, and clinically reliable EEG biomarkers for multi site biomedical applications.
Bi-cephalic self-attended model to classify Parkinson's disease patients with freezing of gait
Jul 28, 2025Parkinson Disease (PD) often results in motor and cognitive impairments, including gait dysfunction, particularly in patients with freezing of gait (FOG). Current detection methods are either subjective or reliant on specialized gait analysis tools. This study aims to develop an objective, data-driven, and multi-modal classification model to detect gait dysfunction in PD patients using resting-state EEG signals combined with demographic and clinical variables. We utilized a dataset of 124 participants: 42 PD patients with FOG (PDFOG+), 41 without FOG (PDFOG-), and 41 age-matched healthy controls. Features extracted from resting-state EEG and descriptive variables (age, education, disease duration) were used to train a novel Bi-cephalic Self-Attention Model (BiSAM). We tested three modalities: signal-only, descriptive-only, and multi-modal, across different EEG channel subsets (BiSAM-63, -16, -8, and -4). Signal-only and descriptive-only models showed limited performance, achieving a maximum accuracy of 55% and 68%, respectively. In contrast, the multi-modal models significantly outperformed both, with BiSAM-8 and BiSAM-4 achieving the highest classification accuracy of 88%. These results demonstrate the value of integrating EEG with objective descriptive features for robust PDFOG+ detection. This study introduces a multi-modal, attention-based architecture that objectively classifies PDFOG+ using minimal EEG channels and descriptive variables. This approach offers a scalable and efficient alternative to traditional assessments, with potential applications in routine clinical monitoring and early diagnosis of PD-related gait dysfunction.
GPD: Guided Polynomial Diffusion for Motion Planning
Jan 30, 2025



Diffusion-based motion planners are becoming popular due to their well-established performance improvements, stemming from sample diversity and the ease of incorporating new constraints directly during inference. However, a primary limitation of the diffusion process is the requirement for a substantial number of denoising steps, especially when the denoising process is coupled with gradient-based guidance. In this paper, we introduce, diffusion in the parametric space of trajectories, where the parameters are represented as Bernstein coefficients. We show that this representation greatly improves the effectiveness of the cost function guidance and the inference speed. We also introduce a novel stitching algorithm that leverages the diversity in diffusion-generated trajectories to produce collision-free trajectories with just a single cost function-guided model. We demonstrate that our approaches outperform current SOTA diffusion-based motion planners for manipulators and provide an ablation study on key components.
Enhancing Deep Learning based RMT Data Inversion using Gaussian Random Field
Oct 22, 2024Deep learning (DL) methods have emerged as a powerful tool for the inversion of geophysical data. When applied to field data, these models often struggle without additional fine-tuning of the network. This is because they are built on the assumption that the statistical patterns in the training and test datasets are the same. To address this, we propose a DL-based inversion scheme for Radio Magnetotelluric data where the subsurface resistivity models are generated using Gaussian Random Fields (GRF). The network's generalization ability was tested with an out-of-distribution (OOD) dataset comprising a homogeneous background and various rectangular-shaped anomalous bodies. After end-to-end training with the GRF dataset, the pre-trained network successfully identified anomalies in the OOD dataset. Synthetic experiments confirmed that the GRF dataset enhances generalization compared to a homogeneous background OOD dataset. The network accurately recovered structures in a checkerboard resistivity model, and demonstrated robustness to noise, outperforming traditional gradient-based methods. Finally, the developed scheme is tested using exemplary field data from a waste site near Roorkee, India. The proposed scheme enhances generalization in a data-driven supervised learning framework, suggesting a promising direction for OOD generalization in DL methods.
EDMP: Ensemble-of-costs-guided Diffusion for Motion Planning
Sep 20, 2023



Classical motion planning for robotic manipulation includes a set of general algorithms that aim to minimize a scene-specific cost of executing a given plan. This approach offers remarkable adaptability, as they can be directly used off-the-shelf for any new scene without needing specific training datasets. However, without a prior understanding of what diverse valid trajectories are and without specially designed cost functions for a given scene, the overall solutions tend to have low success rates. While deep-learning-based algorithms tremendously improve success rates, they are much harder to adopt without specialized training datasets. We propose EDMP, an Ensemble-of-costs-guided Diffusion for Motion Planning that aims to combine the strengths of classical and deep-learning-based motion planning. Our diffusion-based network is trained on a set of diverse kinematically valid trajectories. Like classical planning, for any new scene at the time of inference, we compute scene-specific costs such as "collision cost" and guide the diffusion to generate valid trajectories that satisfy the scene-specific constraints. Further, instead of a single cost function that may be insufficient in capturing diversity across scenes, we use an ensemble of costs to guide the diffusion process, significantly improving the success rate compared to classical planners. EDMP performs comparably with SOTA deep-learning-based methods while retaining the generalization capabilities primarily associated with classical planners.
Accoustate: Auto-annotation of IMU-generated Activity Signatures under Smart Infrastructure
Dec 08, 2021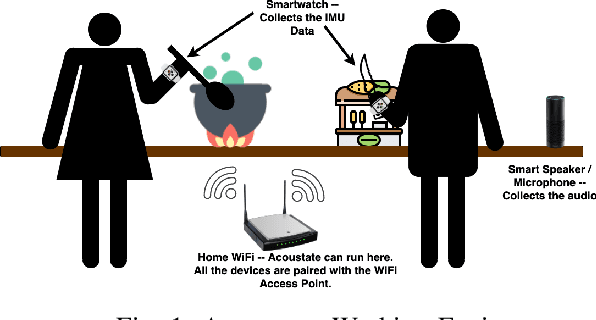
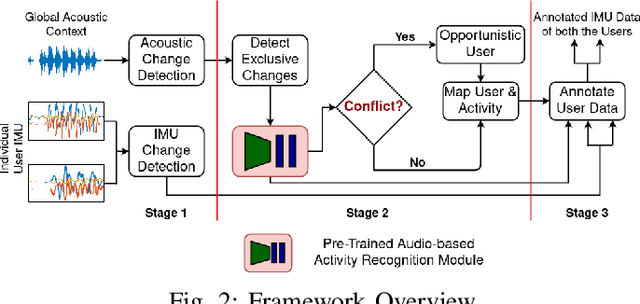
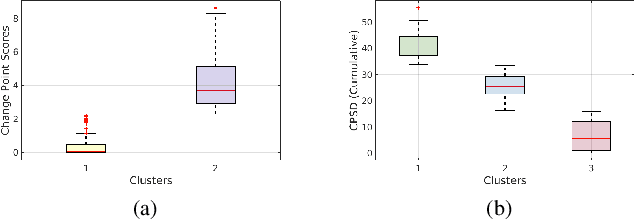
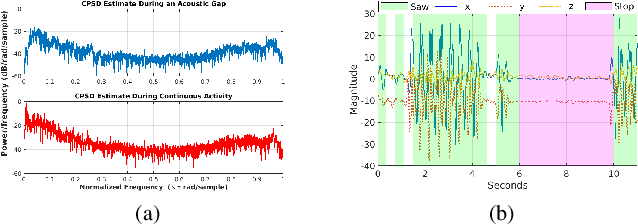
Human activities within smart infrastructures generate a vast amount of IMU data from the wearables worn by individuals. Many existing studies rely on such sensory data for human activity recognition (HAR); however, one of the major bottlenecks is their reliance on pre-annotated or labeled data. Manual human-driven annotations are neither scalable nor efficient, whereas existing auto-annotation techniques heavily depend on video signatures. Still, video-based auto-annotation needs high computation resources and has privacy concerns when the data from a personal space, like a smart-home, is transferred to the cloud. This paper exploits the acoustic signatures generated from human activities to label the wearables' IMU data at the edge, thus mitigating resource requirement and data privacy concerns. We utilize acoustic-based pre-trained HAR models for cross-modal labeling of the IMU data even when two individuals perform simultaneous but different activities under the same environmental context. We observe that non-overlapping acoustic gaps exist with a high probability during the simultaneous activities performed by two individuals in the environment's acoustic context, which helps us resolve the overlapping activity signatures to label them individually. A principled evaluation of the proposed approach on two real-life in-house datasets further augmented to create a dual occupant setup, shows that the framework can correctly annotate a significant volume of unlabeled IMU data from both individuals with an accuracy of $\mathbf{82.59\%}$ ($\mathbf{\pm 17.94\%}$) and $\mathbf{98.32\%}$ ($\mathbf{\pm 3.68\%}$), respectively, for a workshop and a kitchen environment.