 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Single Proxy Control for Deterministic Confounding
Aug 08, 2023We consider the problem of causal effect estimation with an unobserved confounder, where we observe a proxy variable that is associated with the confounder. Although Proxy Causal Learning (PCL) uses two proxy variables to recover the true causal effect, we show that a single proxy variable is sufficient for causal estimation if the outcome is generated deterministically, generalizing Control Outcome Calibration Approach (COCA). We propose two kernel-based methods for this setting: the first based on the two-stage regression approach, and the second based on a maximum moment restriction approach. We prove that both approaches can consistently estimate the causal effect, and we empirically demonstrate that we can successfully recover the causal effect on a synthetic dataset.
Nonlinear Meta-Learning Can Guarantee Faster Rates
Jul 20, 2023Many recent theoretical works on \emph{meta-learning} aim to achieve guarantees in leveraging similar representational structures from related tasks towards simplifying a target task. Importantly, the main aim in theory works on the subject is to understand the extent to which convergence rates -- in learning a common representation -- \emph{may scale with the number $N$ of tasks} (as well as the number of samples per task). First steps in this setting demonstrate this property when both the shared representation amongst tasks, and task-specific regression functions, are linear. This linear setting readily reveals the benefits of aggregating tasks, e.g., via averaging arguments. In practice, however, the representation is often highly nonlinear, introducing nontrivial biases in each task that cannot easily be averaged out as in the linear case. In the present work, we derive theoretical guarantees for meta-learning with nonlinear representations. In particular, assuming the shared nonlinearity maps to an infinite-dimensional RKHS, we show that additional biases can be mitigated with careful regularization that leverages the smoothness of task-specific regression functions,
Prediction under Latent Subgroup Shifts with High-Dimensional Observations
Jun 23, 2023


We introduce a new approach to prediction in graphical models with latent-shift adaptation, i.e., where source and target environments differ in the distribution of an unobserved confounding latent variable. Previous work has shown that as long as "concept" and "proxy" variables with appropriate dependence are observed in the source environment, the latent-associated distributional changes can be identified, and target predictions adapted accurately. However, practical estimation methods do not scale well when the observations are complex and high-dimensional, even if the confounding latent is categorical. Here we build upon a recently proposed probabilistic unsupervised learning framework, the recognition-parametrised model (RPM), to recover low-dimensional, discrete latents from image observations. Applied to the problem of latent shifts, our novel form of RPM identifies causal latent structure in the source environment, and adapts properly to predict in the target. We demonstrate results in settings where predictor and proxy are high-dimensional images, a context to which previous methods fail to scale.
MMD-FUSE: Learning and Combining Kernels for Two-Sample Testing Without Data Splitting
Jun 14, 2023We propose novel statistics which maximise the power of a two-sample test based on the Maximum Mean Discrepancy (MMD), by adapting over the set of kernels used in defining it. For finite sets, this reduces to combining (normalised) MMD values under each of these kernels via a weighted soft maximum. Exponential concentration bounds are proved for our proposed statistics under the null and alternative. We further show how these kernels can be chosen in a data-dependent but permutation-independent way, in a well-calibrated test, avoiding data splitting. This technique applies more broadly to general permutation-based MMD testing, and includes the use of deep kernels with features learnt using unsupervised models such as auto-encoders. We highlight the applicability of our MMD-FUSE test on both synthetic low-dimensional and real-world high-dimensional data, and compare its performance in terms of power against current state-of-the-art kernel tests.
Deep Hypothesis Tests Detect Clinically Relevant Subgroup Shifts in Medical Images
Mar 08, 2023



Distribution shifts remain a fundamental problem for the safe application of machine learning systems. If undetected, they may impact the real-world performance of such systems or will at least render original performance claims invalid. In this paper, we focus on the detection of subgroup shifts, a type of distribution shift that can occur when subgroups have a different prevalence during validation compared to the deployment setting. For example, algorithms developed on data from various acquisition settings may be predominantly applied in hospitals with lower quality data acquisition, leading to an inadvertent performance drop. We formulate subgroup shift detection in the framework of statistical hypothesis testing and show that recent state-of-the-art statistical tests can be effectively applied to subgroup shift detection on medical imaging data. We provide synthetic experiments as well as extensive evaluation on clinically meaningful subgroup shifts on histopathology as well as retinal fundus images. We conclude that classifier-based subgroup shift detection tests could be a particularly useful tool for post-market surveillance of deployed ML systems.
Adapting to Latent Subgroup Shifts via Concepts and Proxies
Dec 21, 2022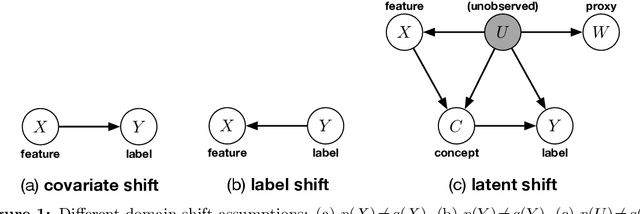

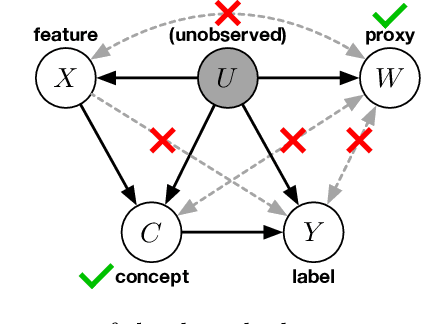
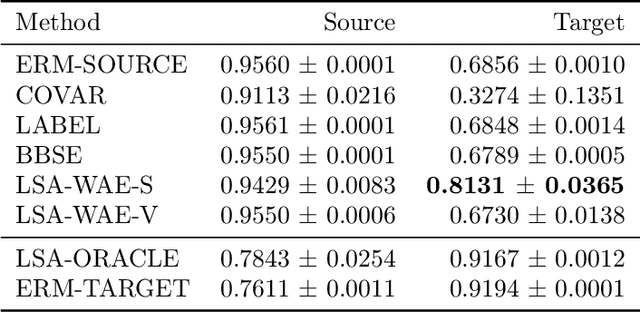
We address the problem of unsupervised domain adaptation when the source domain differs from the target domain because of a shift in the distribution of a latent subgroup. When this subgroup confounds all observed data, neither covariate shift nor label shift assumptions apply. We show that the optimal target predictor can be non-parametrically identified with the help of concept and proxy variables available only in the source domain, and unlabeled data from the target. The identification results are constructive, immediately suggesting an algorithm for estimating the optimal predictor in the target. For continuous observations, when this algorithm becomes impractical, we propose a latent variable model specific to the data generation process at hand. We show how the approach degrades as the size of the shift changes, and verify that it outperforms both covariate and label shift adjustment.
Efficient Conditionally Invariant Representation Learning
Dec 16, 2022



We introduce the Conditional Independence Regression CovariancE (CIRCE), a measure of conditional independence for multivariate continuous-valued variables. CIRCE applies as a regularizer in settings where we wish to learn neural features $\varphi(X)$ of data $X$ to estimate a target $Y$, while being conditionally independent of a distractor $Z$ given $Y$. Both $Z$ and $Y$ are assumed to be continuous-valued but relatively low dimensional, whereas $X$ and its features may be complex and high dimensional. Relevant settings include domain-invariant learning, fairness, and causal learning. The procedure requires just a single ridge regression from $Y$ to kernelized features of $Z$, which can be done in advance. It is then only necessary to enforce independence of $\varphi(X)$ from residuals of this regression, which is possible with attractive estimation properties and consistency guarantees. By contrast, earlier measures of conditional feature dependence require multiple regressions for each step of feature learning, resulting in more severe bias and variance, and greater computational cost. When sufficiently rich features are used, we establish that CIRCE is zero if and only if $\varphi(X) \perp \!\!\! \perp Z \mid Y$. In experiments, we show superior performance to previous methods on challenging benchmarks, including learning conditionally invariant image features.
Controlling Moments with Kernel Stein Discrepancies
Nov 10, 2022



Quantifying the deviation of a probability distribution is challenging when the target distribution is defined by a density with an intractable normalizing constant. The kernel Stein discrepancy (KSD) was proposed to address this problem and has been applied to various tasks including diagnosing approximate MCMC samplers and goodness-of-fit testing for unnormalized statistical models. This article investigates a convergence control property of the diffusion kernel Stein discrepancy (DKSD), an instance of the KSD proposed by Barp et al. (2019). We extend the result of Gorham and Mackey (2017), which showed that the KSD controls the bounded-Lipschitz metric, to functions of polynomial growth. Specifically, we prove that the DKSD controls the integral probability metric defined by a class of pseudo-Lipschitz functions, a polynomial generalization of Lipschitz functions. We also provide practical sufficient conditions on the reproducing kernel for the stated property to hold. In particular, we show that the DKSD detects non-convergence in moments with an appropriate kernel.
Maximum Likelihood Learning of Energy-Based Models for Simulation-Based Inference
Oct 26, 2022We introduce two synthetic likelihood methods for Simulation-Based Inference (SBI), to conduct either amortized or targeted inference from experimental observations when a high-fidelity simulator is available. Both methods learn a conditional energy-based model (EBM) of the likelihood using synthetic data generated by the simulator, conditioned on parameters drawn from a proposal distribution. The learned likelihood can then be combined with any prior to obtain a posterior estimate, from which samples can be drawn using MCMC. Our methods uniquely combine a flexible Energy-Based Model and the minimization of a KL loss: this is in contrast to other synthetic likelihood methods, which either rely on normalizing flows, or minimize score-based objectives; choices that come with known pitfalls. Our first method, Amortized Unnormalized Neural Likelihood Estimation (AUNLE), introduces a tilting trick during training that allows to significantly lower the computational cost of inference by enabling the use of efficient MCMC techniques. Our second method, Sequential UNLE (SUNLE), employs a robust doubly intractable approach in order to re-use simulation data and improve posterior accuracy on a specific dataset. We demonstrate the properties of both methods on a range of synthetic datasets, and apply them to a neuroscience model of the pyloric network in the crab Cancer Borealis, matching the performance of other synthetic likelihood methods at a fraction of the simulation budget.
A kernel Stein test of goodness of fit for sequential models
Oct 19, 2022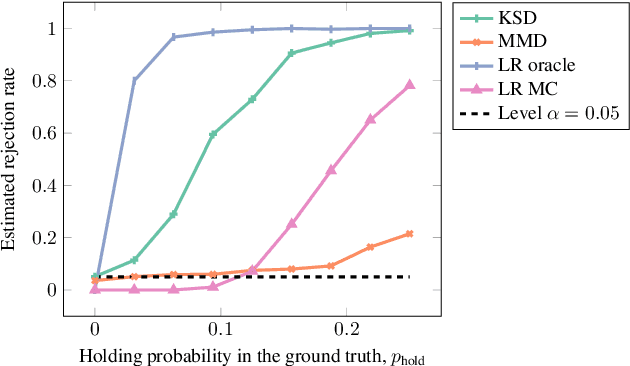
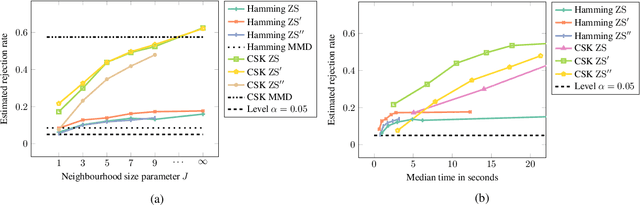
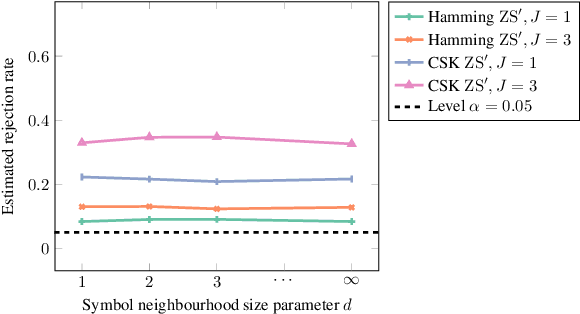
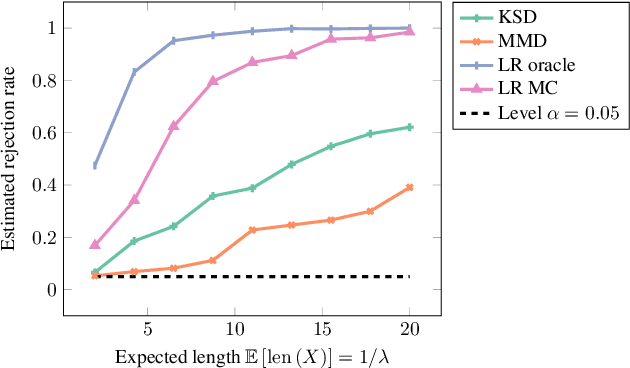
We propose a goodness-of-fit measure for probability densities modelling observations with varying dimensionality, such as text documents of differing lengths or variable-length sequences. The proposed measure is an instance of the kernel Stein discrepancy (KSD), which has been used to construct goodness-of-fit tests for unnormalised densities. Existing KSDs require the model to be defined on a fixed-dimension space. As our major contributions, we extend the KSD to the variable dimension setting by identifying appropriate Stein operators, and propose a novel KSD goodness-of-fit test. As with the previous variants, the proposed KSD does not require the density to be normalised, allowing the evaluation of a large class of models. Our test is shown to perform well in practice on discrete sequential data benchmarks.