 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Distribution Features with Maximum Testing Power
Oct 28, 2016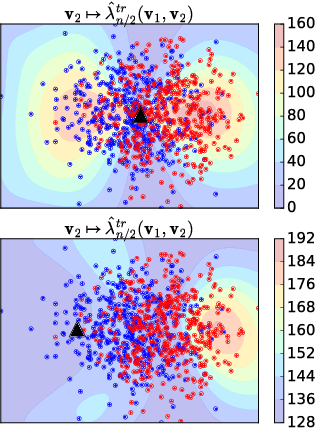
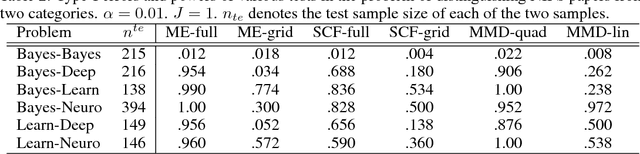
Two semimetrics on probability distributions are proposed, given as the sum of differences of expectations of analytic functions evaluated at spatial or frequency locations (i.e, features). The features are chosen so as to maximize the distinguishability of the distributions, by optimizing a lower bound on test power for a statistical test using these features. The result is a parsimonious and interpretable indication of how and where two distributions differ locally. An empirical estimate of the test power criterion converges with increasing sample size, ensuring the quality of the returned features. In real-world benchmarks on high-dimensional text and image data, linear-time tests using the proposed semimetrics achieve comparable performance to the state-of-the-art quadratic-time maximum mean discrepancy test, while returning human-interpretable features that explain the test results.
Learning Theory for Distribution Regression
Oct 21, 2016
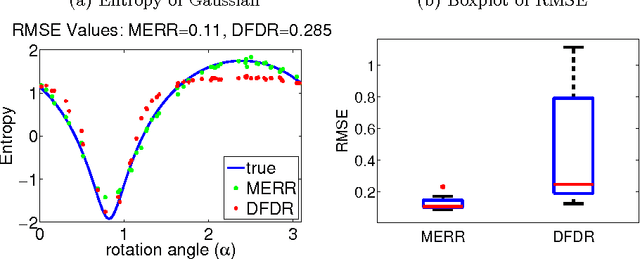

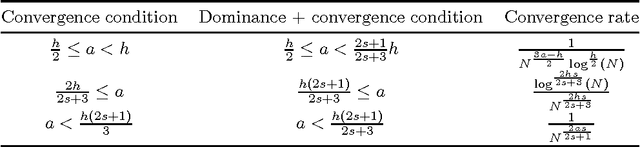
We focus on the distribution regression problem: regressing to vector-valued outputs from probability measures. Many important machine learning and statistical tasks fit into this framework, including multi-instance learning and point estimation problems without analytical solution (such as hyperparameter or entropy estimation). Despite the large number of available heuristics in the literature, the inherent two-stage sampled nature of the problem makes the theoretical analysis quite challenging, since in practice only samples from sampled distributions are observable, and the estimates have to rely on similarities computed between sets of points. To the best of our knowledge, the only existing technique with consistency guarantees for distribution regression requires kernel density estimation as an intermediate step (which often performs poorly in practice), and the domain of the distributions to be compact Euclidean. In this paper, we study a simple, analytically computable, ridge regression-based alternative to distribution regression, where we embed the distributions to a reproducing kernel Hilbert space, and learn the regressor from the embeddings to the outputs. Our main contribution is to prove that this scheme is consistent in the two-stage sampled setup under mild conditions (on separable topological domains enriched with kernels): we present an exact computational-statistical efficiency trade-off analysis showing that our estimator is able to match the one-stage sampled minimax optimal rate [Caponnetto and De Vito, 2007; Steinwart et al., 2009]. This result answers a 17-year-old open question, establishing the consistency of the classical set kernel [Haussler, 1999; Gaertner et. al, 2002] in regression. We also cover consistency for more recent kernels on distributions, including those due to [Christmann and Steinwart, 2010].
* Final version appeared at JMLR, with supplement. Code: https://bitbucket.org/szzoli/ite/. arXiv admin note: text overlap with arXiv:1402.1754
An Adaptive Test of Independence with Analytic Kernel Embeddings
Oct 15, 2016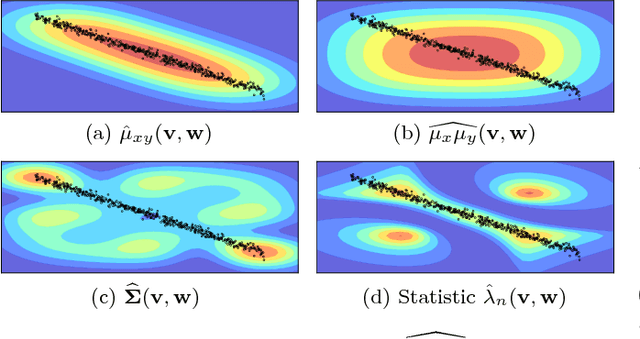
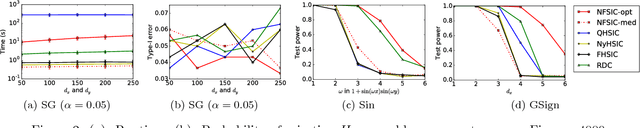

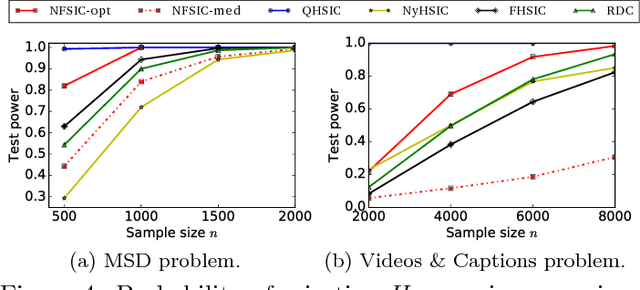
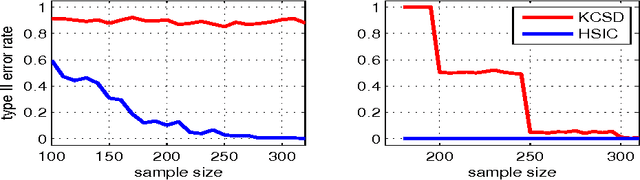
A new computationally efficient dependence measure, and an adaptive statistical test of independence, are proposed. The dependence measure is the difference between analytic embeddings of the joint distribution and the product of the marginals, evaluated at a finite set of locations (features). These features are chosen so as to maximize a lower bound on the test power, resulting in a test that is data-efficient, and that runs in linear time (with respect to the sample size n). The optimized features can be interpreted as evidence to reject the null hypothesis, indicating regions in the joint domain where the joint distribution and the product of the marginals differ most. Consistency of the independence test is established, for an appropriate choice of features. In real-world benchmarks, independence tests using the optimized features perform comparably to the state-of-the-art quadratic-time HSIC test, and outperform competing O(n) and O(n log n) tests.
Recovery of non-linear cause-effect relationships from linearly mixed neuroimaging data
Sep 30, 2016
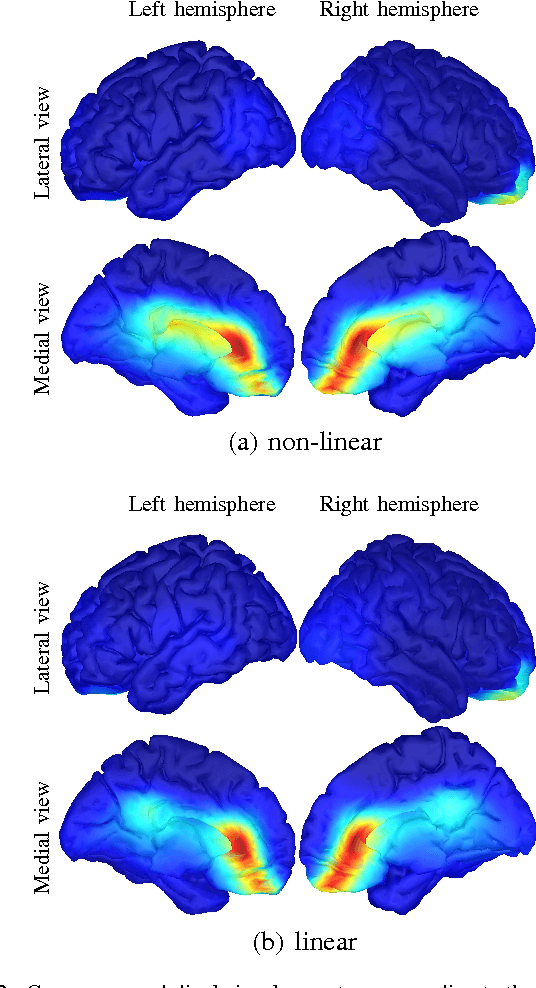
Causal inference concerns the identification of cause-effect relationships between variables. However, often only linear combinations of variables constitute meaningful causal variables. For example, recovering the signal of a cortical source from electroencephalography requires a well-tuned combination of signals recorded at multiple electrodes. We recently introduced the MERLiN (Mixture Effect Recovery in Linear Networks) algorithm that is able to recover, from an observed linear mixture, a causal variable that is a linear effect of another given variable. Here we relax the assumption of this cause-effect relationship being linear and present an extended algorithm that can pick up non-linear cause-effect relationships. Thus, the main contribution is an algorithm (and ready to use code) that has broader applicability and allows for a richer model class. Furthermore, a comparative analysis indicates that the assumption of linear cause-effect relationships is not restrictive in analysing electroencephalographic data.
* arXiv admin note: text overlap with arXiv:1512.01255
MERLiN: Mixture Effect Recovery in Linear Networks
Sep 27, 2016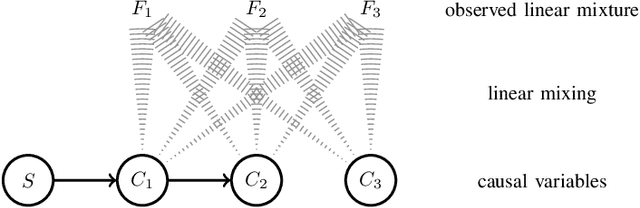
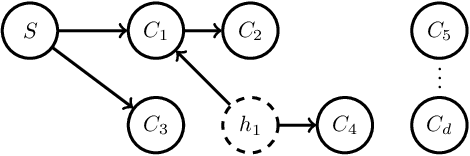
Causal inference concerns the identification of cause-effect relationships between variables, e.g. establishing whether a stimulus affects activity in a certain brain region. The observed variables themselves often do not constitute meaningful causal variables, however, and linear combinations need to be considered. In electroencephalographic studies, for example, one is not interested in establishing cause-effect relationships between electrode signals (the observed variables), but rather between cortical signals (the causal variables) which can be recovered as linear combinations of electrode signals. We introduce MERLiN (Mixture Effect Recovery in Linear Networks), a family of causal inference algorithms that implement a novel means of constructing causal variables from non-causal variables. We demonstrate through application to EEG data how the basic MERLiN algorithm can be extended for application to different (neuroimaging) data modalities. Given an observed linear mixture, the algorithms can recover a causal variable that is a linear effect of another given variable. That is, MERLiN allows us to recover a cortical signal that is affected by activity in a certain brain region, while not being a direct effect of the stimulus. The Python/Matlab implementation for all presented algorithms is available on https://github.com/sweichwald/MERLiN
A Kernel Test of Goodness of Fit
Sep 27, 2016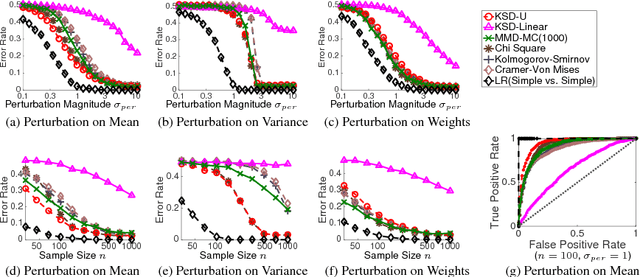
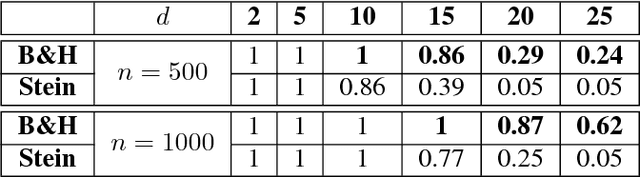
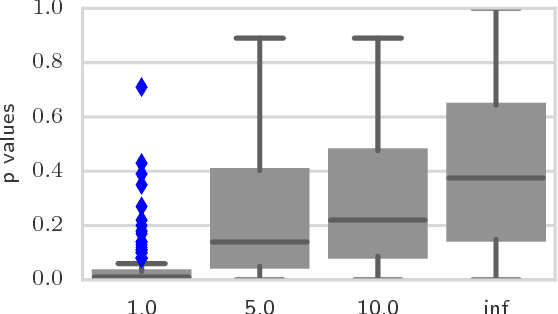
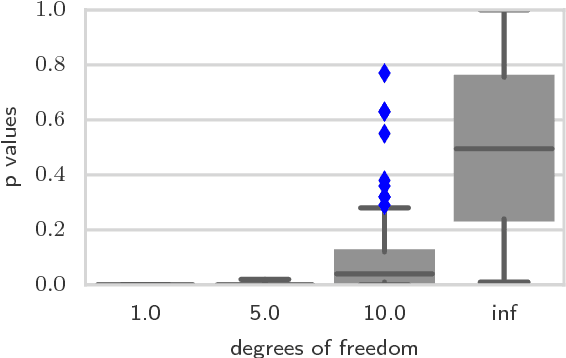
We propose a nonparametric statistical test for goodness-of-fit: given a set of samples, the test determines how likely it is that these were generated from a target density function. The measure of goodness-of-fit is a divergence constructed via Stein's method using functions from a Reproducing Kernel Hilbert Space. Our test statistic is based on an empirical estimate of this divergence, taking the form of a V-statistic in terms of the log gradients of the target density and the kernel. We derive a statistical test, both for i.i.d. and non-i.i.d. samples, where we estimate the null distribution quantiles using a wild bootstrap procedure. We apply our test to quantifying convergence of approximate Markov Chain Monte Carlo methods, statistical model criticism, and evaluating quality of fit vs model complexity in nonparametric density estimation.
A Wild Bootstrap for Degenerate Kernel Tests
Sep 27, 2016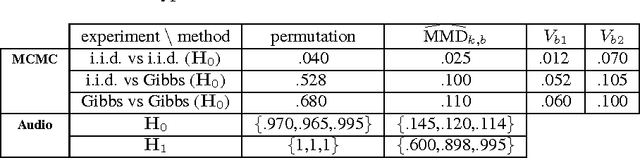
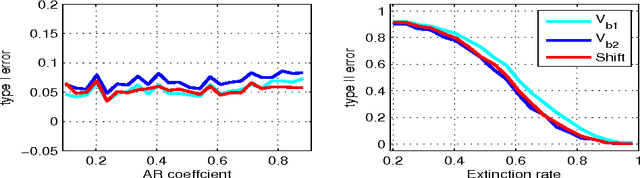
A wild bootstrap method for nonparametric hypothesis tests based on kernel distribution embeddings is proposed. This bootstrap method is used to construct provably consistent tests that apply to random processes, for which the naive permutation-based bootstrap fails. It applies to a large group of kernel tests based on V-statistics, which are degenerate under the null hypothesis, and non-degenerate elsewhere. To illustrate this approach, we construct a two-sample test, an instantaneous independence test and a multiple lag independence test for time series. In experiments, the wild bootstrap gives strong performance on synthetic examples, on audio data, and in performance benchmarking for the Gibbs sampler.
GP-select: Accelerating EM using adaptive subspace preselection
Jul 17, 2016We propose a nonparametric procedure to achieve fast inference in generative graphical models when the number of latent states is very large. The approach is based on iterative latent variable preselection, where we alternate between learning a 'selection function' to reveal the relevant latent variables, and use this to obtain a compact approximation of the posterior distribution for EM; this can make inference possible where the number of possible latent states is e.g. exponential in the number of latent variables, whereas an exact approach would be computationally unfeasible. We learn the selection function entirely from the observed data and current EM state via Gaussian process regression. This is by contrast with earlier approaches, where selection functions were manually-designed for each problem setting. We show that our approach performs as well as these bespoke selection functions on a wide variety of inference problems: in particular, for the challenging case of a hierarchical model for object localization with occlusion, we achieve results that match a customized state-of-the-art selection method, at a far lower computational cost.
Large-Scale Kernel Methods for Independence Testing
Jun 25, 2016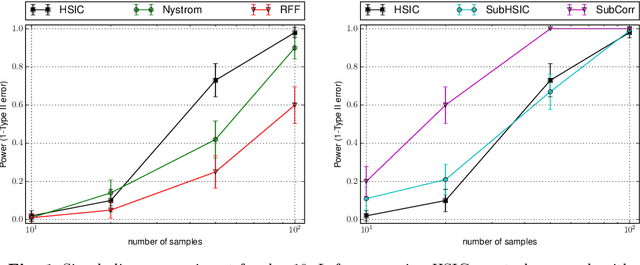
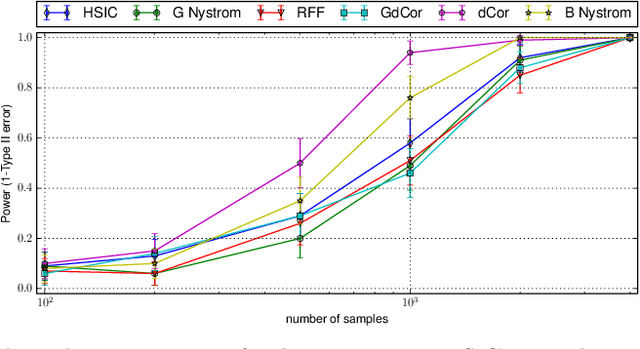
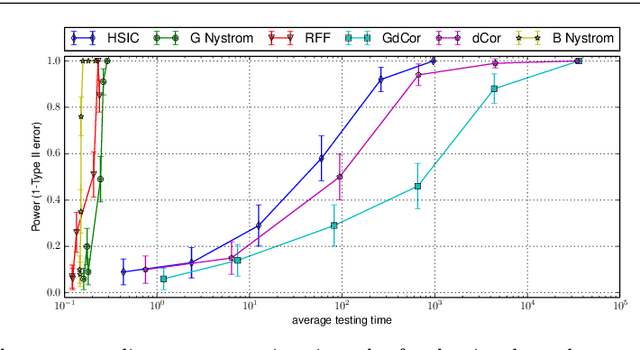
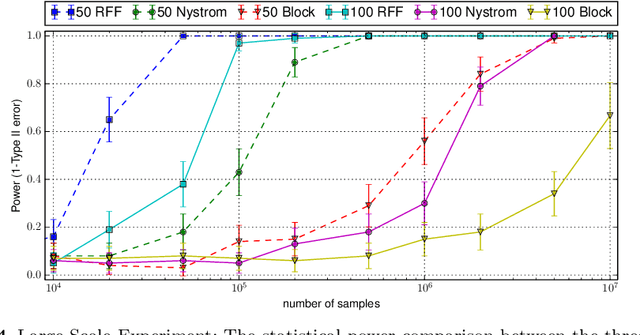
Representations of probability measures in reproducing kernel Hilbert spaces provide a flexible framework for fully nonparametric hypothesis tests of independence, which can capture any type of departure from independence, including nonlinear associations and multivariate interactions. However, these approaches come with an at least quadratic computational cost in the number of observations, which can be prohibitive in many applications. Arguably, it is exactly in such large-scale datasets that capturing any type of dependence is of interest, so striking a favourable tradeoff between computational efficiency and test performance for kernel independence tests would have a direct impact on their applicability in practice. In this contribution, we provide an extensive study of the use of large-scale kernel approximations in the context of independence testing, contrasting block-based, Nystrom and random Fourier feature approaches. Through a variety of synthetic data experiments, it is demonstrated that our novel large scale methods give comparable performance with existing methods whilst using significantly less computation time and memory.
A Kernel Test for Three-Variable Interactions with Random Processes
Mar 08, 2016


We apply a wild bootstrap method to the Lancaster three-variable interaction measure in order to detect factorisation of the joint distribution on three variables forming a stationary random process, for which the existing permutation bootstrap method fails. As in the i.i.d. case, the Lancaster test is found to outperform existing tests in cases for which two independent variables individually have a weak influence on a third, but that when considered jointly the influence is strong. The main contributions of this paper are twofold: first, we prove that the Lancaster statistic satisfies the conditions required to estimate the quantiles of the null distribution using the wild bootstrap; second, the manner in which this is proved is novel, simpler than existing methods, and can further be applied to other statistics.