 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Model-Agnostic Learning to Meta-Learn
Dec 04, 2020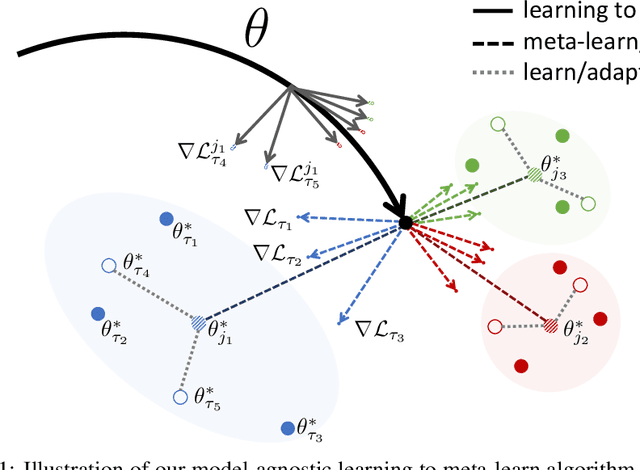
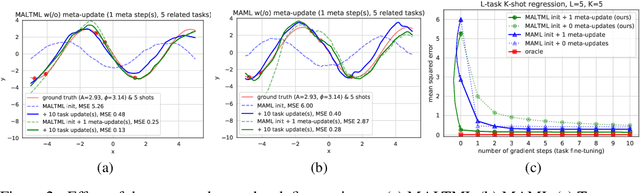
In this paper, we propose a learning algorithm that enables a model to quickly exploit commonalities among related tasks from an unseen task distribution, before quickly adapting to specific tasks from that same distribution. We investigate how learning with different task distributions can first improve adaptability by meta-finetuning on related tasks before improving goal task generalization with finetuning. Synthetic regression experiments validate the intuition that learning to meta-learn improves adaptability and consecutively generalization. The methodology, setup, and hypotheses in this proposal were positively evaluated by peer review before conclusive experiments were carried out.
Self-Supervised Prototypical Transfer Learning for Few-Shot Classification
Jun 19, 2020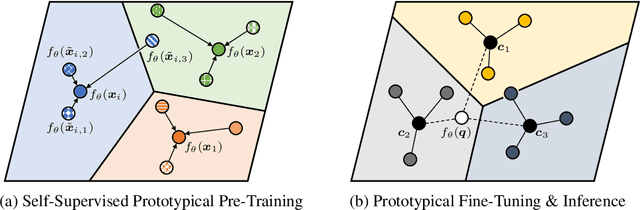
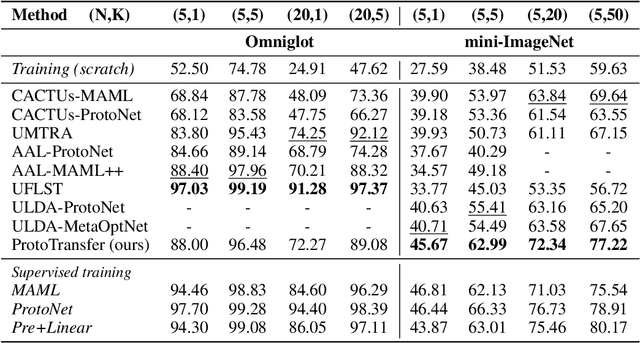
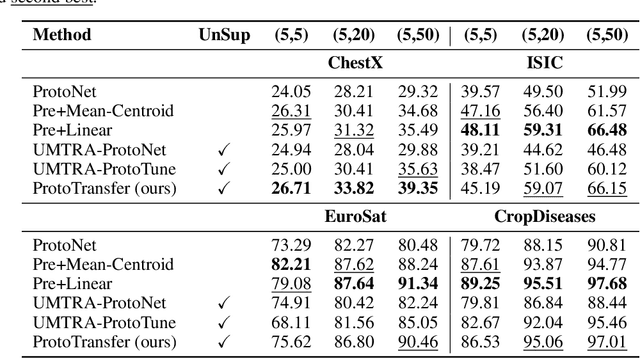
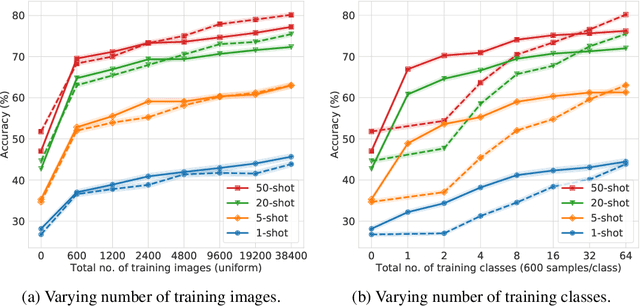
Most approaches in few-shot learning rely on costly annotated data related to the goal task domain during (pre-)training. Recently, unsupervised meta-learning methods have exchanged the annotation requirement for a reduction in few-shot classification performance. Simultaneously, in settings with realistic domain shift, common transfer learning has been shown to outperform supervised meta-learning. Building on these insights and on advances in self-supervised learning, we propose a transfer learning approach which constructs a metric embedding that clusters unlabeled prototypical samples and their augmentations closely together. This pre-trained embedding is a starting point for few-shot classification by summarizing class clusters and fine-tuning. We demonstrate that our self-supervised prototypical transfer learning approach ProtoTransfer outperforms state-of-the-art unsupervised meta-learning methods on few-shot tasks from the mini-ImageNet dataset. In few-shot experiments with domain shift, our approach even has comparable performance to supervised methods, but requires orders of magnitude fewer labels.
Revisiting Few-Shot Learning for Facial Expression Recognition
Dec 11, 2019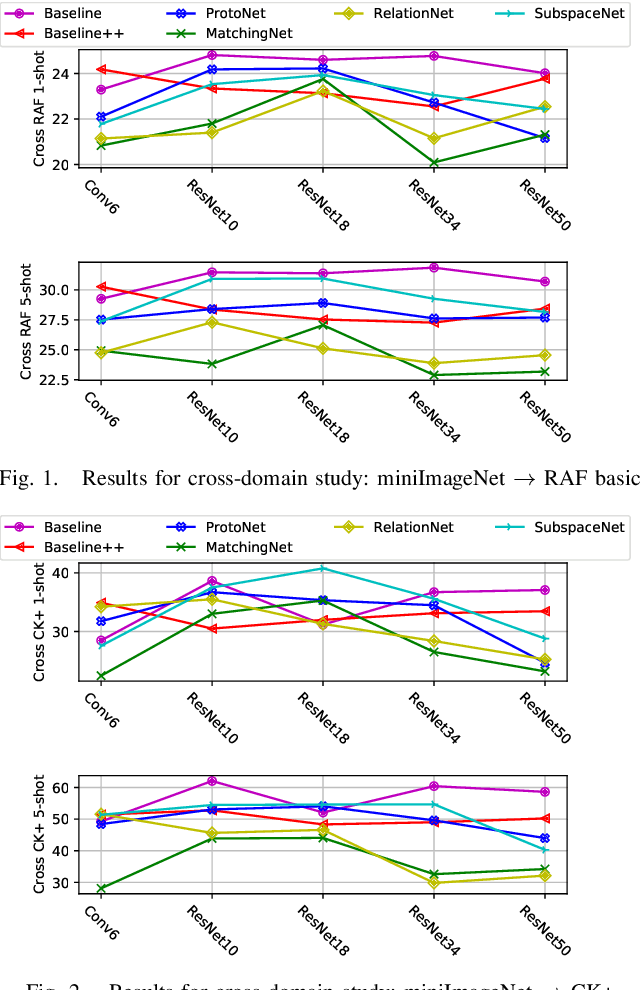
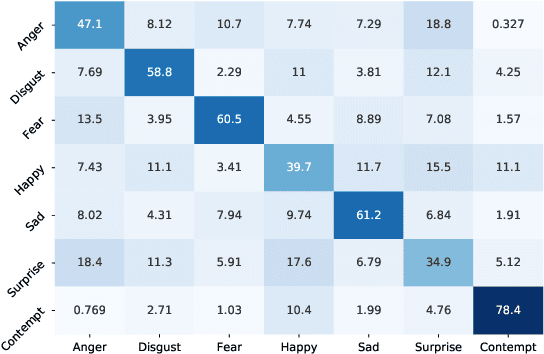
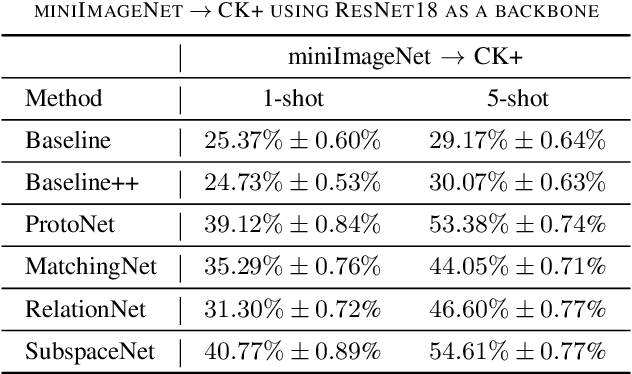
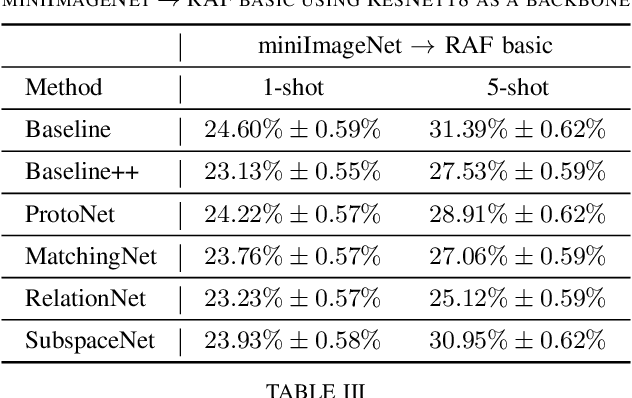
Most of the existing deep neural nets on automatic facial expression recognition focus on a set of predefined emotion classes, where the amount of training data has the biggest impact on performance. However, in the standard setting over-parameterised neural networks are not amenable for learning from few samples as they can quickly over-fit. In addition, these approaches do not have such a strong generalisation ability to identify a new category, where the data of each category is too limited and significant variations exist in the expression within the same semantic category. We embrace these challenges and formulate the problem as a low-shot learning, where once the base classifier is deployed, it must rapidly adapt to recognise novel classes using a few samples. In this paper, we revisit and compare existing few-shot learning methods for the low-shot facial expression recognition in terms of their generalisation ability via episode-training. In particular, we extend our analysis on the cross-domain generalisation, where training and test tasks are not drawn from the same distribution. We demonstrate the efficacy of low-shot learning methods through extensive experiments.
Subspace Networks for Few-shot Classification
May 31, 2019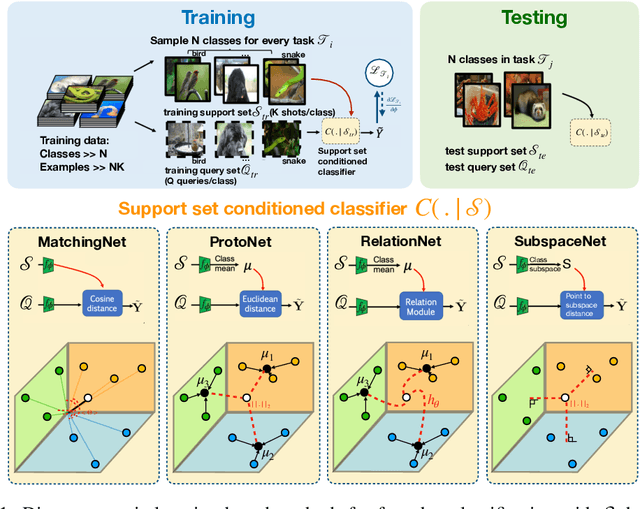

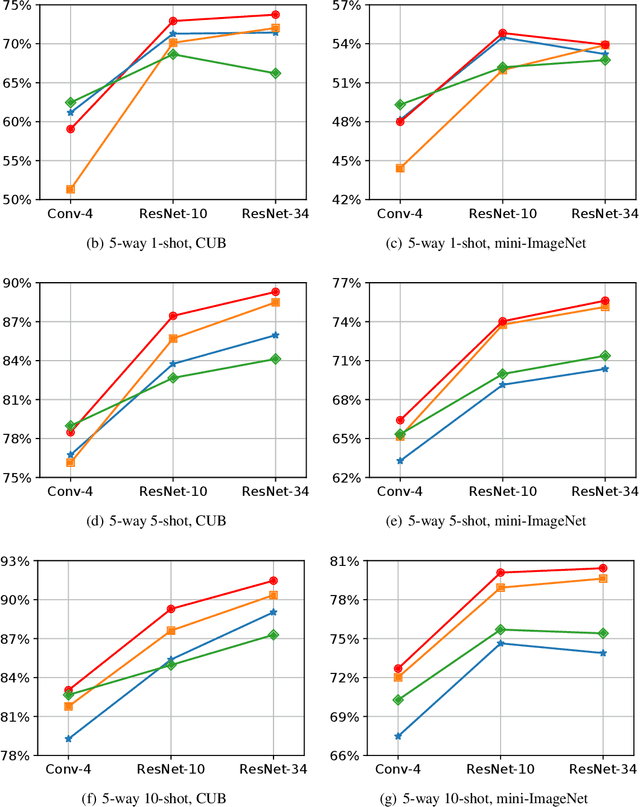

We propose subspace networks for the problem of few-shot classification, where a classifier must generalize to new classes not seen in the training set, given only a small number of examples of each class. Subspace networks learn an embedding space in which classification can be performed by computing distances of embedded points to subspace representations of each class. The class subspaces are spanned by examples belonging to the same class, transformed by a learnable embedding function. Similarly to recent approaches for few-shot learning, subspace networks reflect a simple inductive bias that is beneficial in this limited-data regime and they achieve excellent results. In particular, our proposed method shows consistently better performance than other state-of-the-art few-shot distance-metric learning methods when the embedding function is deep or when training and testing domains are shifted.