 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgical Feature-Space Decomposition of LLMs: Why, When and How?
May 17, 2024Low-rank approximations, of the weight and feature space can enhance the performance of deep learning models, whether in terms of improving generalization or reducing the latency of inference. However, there is no clear consensus yet on \emph{how}, \emph{when} and \emph{why} these approximations are helpful for large language models (LLMs). In this work, we empirically study the efficacy of weight and feature space decomposition in transformer-based LLMs. We demonstrate that surgical decomposition not only provides critical insights into the trade-off between compression and language modelling performance, but also sometimes enhances commonsense reasoning performance of LLMs. Our empirical analysis identifies specific network segments that intrinsically exhibit a low-rank structure. Furthermore, we extend our investigation to the implications of low-rank approximations on model bias. Overall, our findings offer a novel perspective on optimizing LLMs, presenting the low-rank approximation not only as a tool for performance enhancements, but also as a means to potentially rectify biases within these models. Our code is available at \href{https://github.com/nyunAI/SFSD-LLM}{GitHub}.
Beyond Uniform Scaling: Exploring Depth Heterogeneity in Neural Architectures
Feb 19, 2024Conventional scaling of neural networks typically involves designing a base network and growing different dimensions like width, depth, etc. of the same by some predefined scaling factors. We introduce an automated scaling approach leveraging second-order loss landscape information. Our method is flexible towards skip connections a mainstay in modern vision transformers. Our training-aware method jointly scales and trains transformers without additional training iterations. Motivated by the hypothesis that not all neurons need uniform depth complexity, our approach embraces depth heterogeneity. Extensive evaluations on DeiT-S with ImageNet100 show a 2.5% accuracy gain and 10% parameter efficiency improvement over conventional scaling. Scaled networks demonstrate superior performance upon training small scale datasets from scratch. We introduce the first intact scaling mechanism for vision transformers, a step towards efficient model scaling.
Faster and Lighter LLMs: A Survey on Current Challenges and Way Forward
Feb 02, 2024


Despite the impressive performance of LLMs, their widespread adoption faces challenges due to substantial computational and memory requirements during inference. Recent advancements in model compression and system-level optimization methods aim to enhance LLM inference. This survey offers an overview of these methods, emphasizing recent developments. Through experiments on LLaMA(/2)-7B, we evaluate various compression techniques, providing practical insights for efficient LLM deployment in a unified setting. The empirical analysis on LLaMA(/2)-7B highlights the effectiveness of these methods. Drawing from survey insights, we identify current limitations and discuss potential future directions to improve LLM inference efficiency. We release the codebase to reproduce the results presented in this paper at https://github.com/nyunAI/Faster-LLM-Survey
Rethinking Compression: Reduced Order Modelling of Latent Features in Large Language Models
Dec 12, 2023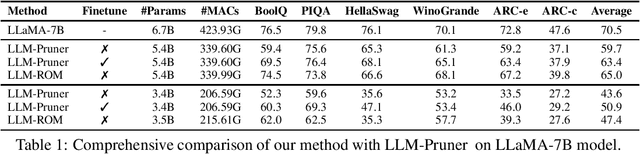

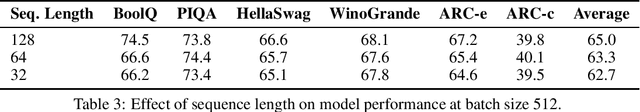
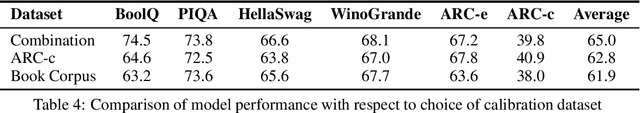
Due to the substantial scale of Large Language Models (LLMs), the direct application of conventional compression methodologies proves impractical. The computational demands associated with even minimal gradient updates present challenges, particularly on consumer-grade hardware. This paper introduces an innovative approach for the parametric and practical compression of LLMs based on reduced order modelling, which entails low-rank decomposition within the feature space and re-parameterization in the weight space. Notably, this compression technique operates in a layer-wise manner, obviating the need for a GPU device and enabling the compression of billion-scale models within stringent constraints of both memory and time. Our method represents a significant advancement in model compression by leveraging matrix decomposition, demonstrating superior efficacy compared to the prevailing state-of-the-art structured pruning method.
One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning
Jun 13, 2023We present Generalized LoRA (GLoRA), an advanced approach for universal parameter-efficient fine-tuning tasks. Enhancing Low-Rank Adaptation (LoRA), GLoRA employs a generalized prompt module to optimize pre-trained model weights and adjust intermediate activations, providing more flexibility and capability across diverse tasks and datasets. Moreover, GLoRA facilitates efficient parameter adaptation by employing a scalable, modular, layer-wise structure search that learns individual adapter of each layer. Originating from a unified mathematical formulation, GLoRA exhibits strong transfer learning, few-shot learning and domain generalization abilities, as it adjusts to new tasks through additional dimensions on weights and activations. Comprehensive experiments demonstrate that GLoRA outperforms all previous methods in natural, specialized, and structured benchmarks, achieving superior accuracy with fewer parameters and computations on various datasets. Furthermore, our structural re-parameterization design ensures that GLoRA incurs no extra inference cost, rendering it a practical solution for resource-limited applications. Code is available at: https://github.com/Arnav0400/ViT-Slim/tree/master/GLoRA.
Patch Gradient Descent: Training Neural Networks on Very Large Images
Jan 31, 2023



Traditional CNN models are trained and tested on relatively low resolution images (<300 px), and cannot be directly operated on large-scale images due to compute and memory constraints. We propose Patch Gradient Descent (PatchGD), an effective learning strategy that allows to train the existing CNN architectures on large-scale images in an end-to-end manner. PatchGD is based on the hypothesis that instead of performing gradient-based updates on an entire image at once, it should be possible to achieve a good solution by performing model updates on only small parts of the image at a time, ensuring that the majority of it is covered over the course of iterations. PatchGD thus extensively enjoys better memory and compute efficiency when training models on large scale images. PatchGD is thoroughly evaluated on two datasets - PANDA and UltraMNIST with ResNet50 and MobileNetV2 models under different memory constraints. Our evaluation clearly shows that PatchGD is much more stable and efficient than the standard gradient-descent method in handling large images, and especially when the compute memory is limited.
On designing light-weight object trackers through network pruning: Use CNNs or transformers?
Nov 24, 2022



Object trackers deployed on low-power devices need to be light-weight, however, most of the current state-of-the-art (SOTA) methods rely on using compute-heavy backbones built using CNNs or transformers. Large sizes of such models do not allow their deployment in low-power conditions and designing compressed variants of large tracking models is of great importance. This paper demonstrates how highly compressed light-weight object trackers can be designed using neural architectural pruning of large CNN and transformer based trackers. Further, a comparative study on architectural choices best suited to design light-weight trackers is provided. A comparison between SOTA trackers using CNNs, transformers as well as the combination of the two is presented to study their stability at various compression ratios. Finally results for extreme pruning scenarios going as low as 1% in some cases are shown to study the limits of network pruning in object tracking. This work provides deeper insights into designing highly efficient trackers from existing SOTA methods.
Dynamic Kernel Selection for Improved Generalization and Memory Efficiency in Meta-learning
Jun 03, 2022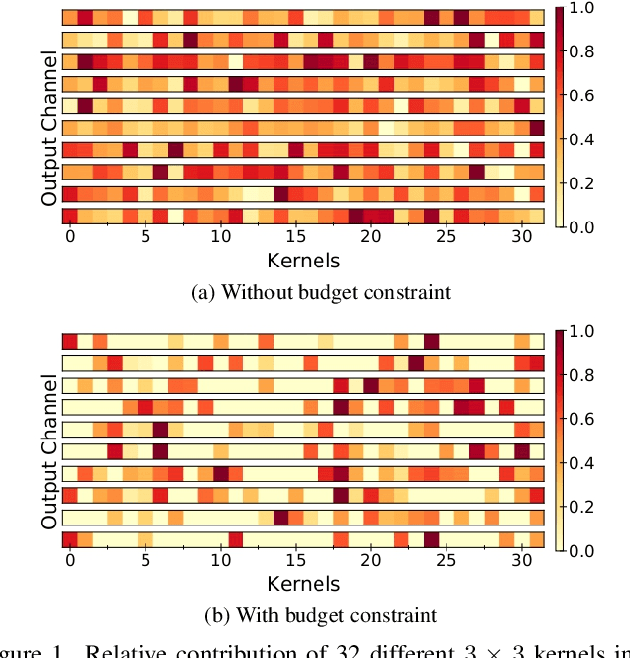
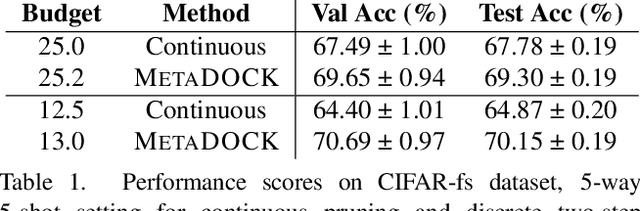
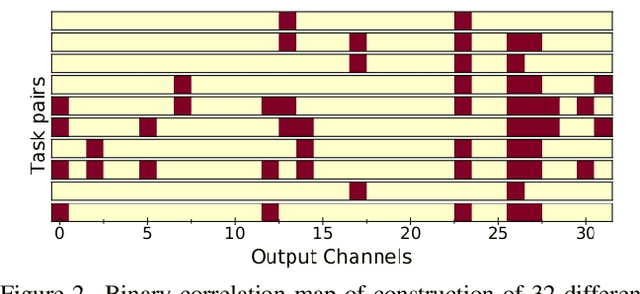
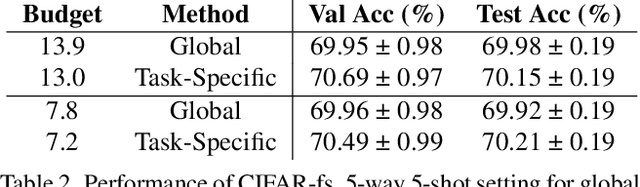
Gradient based meta-learning methods are prone to overfit on the meta-training set, and this behaviour is more prominent with large and complex networks. Moreover, large networks restrict the application of meta-learning models on low-power edge devices. While choosing smaller networks avoid these issues to a certain extent, it affects the overall generalization leading to reduced performance. Clearly, there is an approximately optimal choice of network architecture that is best suited for every meta-learning problem, however, identifying it beforehand is not straightforward. In this paper, we present MetaDOCK, a task-specific dynamic kernel selection strategy for designing compressed CNN models that generalize well on unseen tasks in meta-learning. Our method is based on the hypothesis that for a given set of similar tasks, not all kernels of the network are needed by each individual task. Rather, each task uses only a fraction of the kernels, and the selection of the kernels per task can be learnt dynamically as a part of the inner update steps. MetaDOCK compresses the meta-model as well as the task-specific inner models, thus providing significant reduction in model size for each task, and through constraining the number of active kernels for every task, it implicitly mitigates the issue of meta-overfitting. We show that for the same inference budget, pruned versions of large CNN models obtained using our approach consistently outperform the conventional choices of CNN models. MetaDOCK couples well with popular meta-learning approaches such as iMAML. The efficacy of our method is validated on CIFAR-fs and mini-ImageNet datasets, and we have observed that our approach can provide improvements in model accuracy of up to 2% on standard meta-learning benchmark, while reducing the model size by more than 75%.
Vision Transformer Slimming: Multi-Dimension Searching in Continuous Optimization Space
Jan 03, 2022
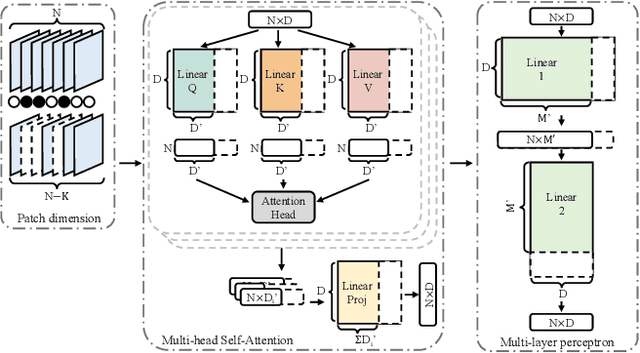
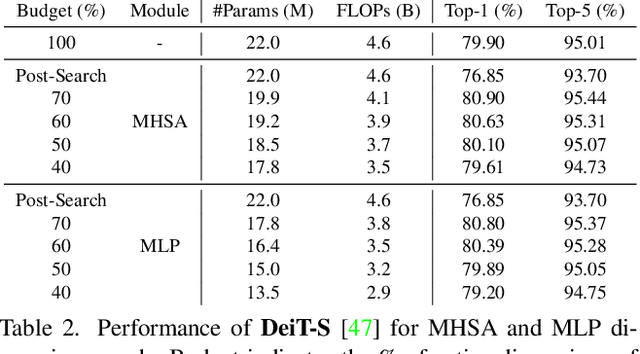
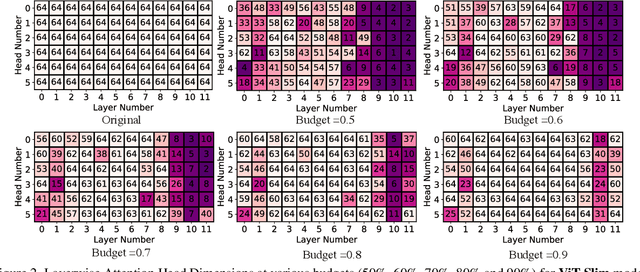
This paper explores the feasibility of finding an optimal sub-model from a vision transformer and introduces a pure vision transformer slimming (ViT-Slim) framework that can search such a sub-structure from the original model end-to-end across multiple dimensions, including the input tokens, MHSA and MLP modules with state-of-the-art performance. Our method is based on a learnable and unified l1 sparsity constraint with pre-defined factors to reflect the global importance in the continuous searching space of different dimensions. The searching process is highly efficient through a single-shot training scheme. For instance, on DeiT-S, ViT-Slim only takes ~43 GPU hours for searching process, and the searched structure is flexible with diverse dimensionalities in different modules. Then, a budget threshold is employed according to the requirements of accuracy-FLOPs trade-off on running devices, and a re-training process is performed to obtain the final models. The extensive experiments show that our ViT-Slim can compress up to 40% of parameters and 40% FLOPs on various vision transformers while increasing the accuracy by ~0.6% on ImageNet. We also demonstrate the advantage of our searched models on several downstream datasets. Our source code will be publicly available.
Transfer Learning Gaussian Anomaly Detection by Fine-Tuning Representations
Aug 09, 2021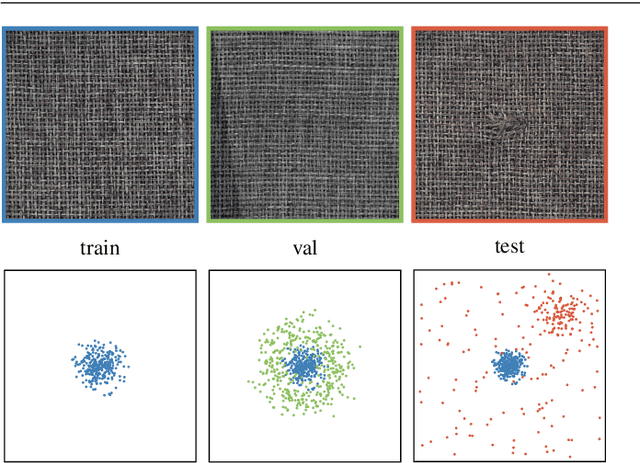
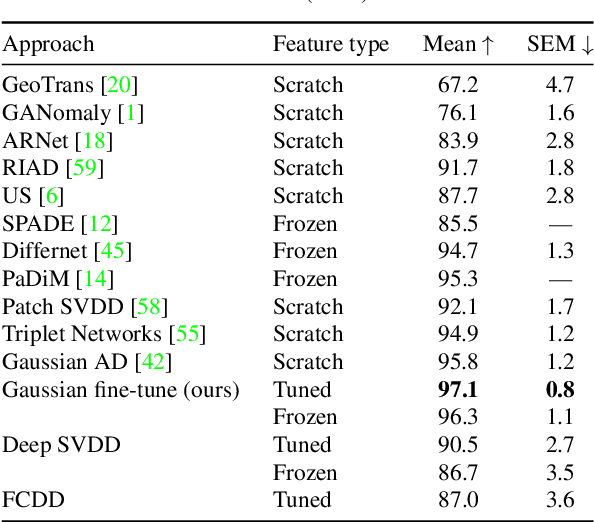


Current state-of-the-art Anomaly Detection (AD) methods exploit the powerful representations yielded by large-scale ImageNet training. However, catastrophic forgetting prevents the successful fine-tuning of pre-trained representations on new datasets in the semi/unsupervised setting, and representations are therefore commonly fixed. In our work, we propose a new method to fine-tune learned representations for AD in a transfer learning setting. Based on the linkage between generative and discriminative modeling, we induce a multivariate Gaussian distribution for the normal class, and use the Mahalanobis distance of normal images to the distribution as training objective. We additionally propose to use augmentations commonly employed for vicinal risk minimization in a validation scheme to detect onset of catastrophic forgetting. Extensive evaluations on the public MVTec AD dataset reveal that a new state of the art is achieved by our method in the AD task while simultaneously achieving AS performance comparable to prior state of the art. Further, ablation studies demonstrate the importance of the induced Gaussian distribution as well as the robustness of the proposed fine-tuning scheme with respect to the choice of augmentations.